
SQL Server 2016: Query Designer
- Import Data
- Create a View
Use the Query Designer to build complex queries across multiple tables without writing any code.
SQL Server Management Studio includes the Query Designer to assist in building queries. It is a visual tool that allows you to select the tables and columns you want in your query, as well as any filtering criteria.
No need to write any SQL code — the Query Designer will generate that for you.
Use the Query Designer to Build a Simple Query
We'll now use the Query Designer to build a simple query. If you've been following along in this tutorial , you'd now have a database with three tables — all of which contain data. And because we've established a relationship between these tables , we can now run queries across all three, returning related records.
Open the Query Designer

Open a new query window by clicking on New Query in the toolbar.
Then select Query > Design Query in Editor... from the top menu.
If you can't see the Query option in the top menu, click inside the query window first. This will change the top menu items to be query-related options.
Add the Tables

Here, you select which tables you'd like in your query.
Select all three and click Add .
Click Close to close the dialog box.
Design the Query

You will now see the selected tables, and their relationships, in the Query Designer. Feel free to click and drag them around to provide a better visualization of their relationship with each other.
You can also re-size each pane by clicking its edge and dragging it up or down.
How to Design a Query
In the top pane (the Diagram Pane), click each column that you want to include in the query (whether you want to display it or not). Each column you select in the top pane will automatically appear in the middle pane.
In the middle pane (the Grid Pane or Criteria Pane), use the Output checkbox to indicate which columns will be returned in the results. Use Sort Type to specify the order of the results by a given column. You can use Sort Order to specify which column will be sorted first, second, etc. Use Filter to add filtering criteria to filter the records returned.
The bottom pane (the SQL Pane) dynamically generates the SQL statement that your query produces. This is the statement that will be run when you close the Query Designer and execute the query.
Our Example
In our example, our query will return all albums (along with their genre, artist, and genre) that were released in the last ten years. The criteria to achieve this is >DATEADD(year, - 10, GETDATE()) . The query will sort the results by the release date in descending order.
Here's a close-up of the Criteria Pane:

You can change the order of the columns by clicking and dragging them up or down.
If you're reading this long after this tutorial was written, you might need to adjust the criteria to go back 20 years or more before you get any results.
Alternatively, you could add something a bit more modern to the music collection :)
Make sure you keep this query open in the query window because next, we will save it as a view .
How to Query Date and Time in SQL Server using Datetime and Timestamp
Get the date and time right now (where SQL Server is running):
Find rows between two dates or timestamps:
Find rows created within the last week:
Find events scheduled between one week ago and 3 days from now:
Extracting part of a timestamp and returning an integer:
Extracting part of a timestamp and returning a string (e.g. "February" or "Monday"):
Get the day of the week from a timestamp:
How to convert a timestamp to a unix timestamp:
To calculate the difference between two timestamps, convert them to unix timestamps then subtract:
Note: this simple approach lacks millisecond precision.

8 Ways to Export SQL Results To a Text File
Daniel Calbimonte , 2017-10-06 (first published: 2016-10-26 )
Introduction
This article will show eight ways to export rows from a T-SQL query to a txt file. We will show the following options:
- Shows results to a file in SQL Server Management Studio (SSMS)
- Import/Export Wizard in SSMS
- SSIS Wizard (almost the same than the number 4, but we are using SSDT instead of SSMS to create the package).
Requirements
You need a SQL Server Installed with SSIS and SQL Server Data Tools (SSDT).
Getting Started
Let's look at each of the ways we can export the results of a query.
1. Show results to a file in SSMS
In the first option, we will configure SSMS to display the query results to a txt file. We will use the following script, named myscript.sql:
The result displayed in SQL Server Management Studio (SSMS) is the following:
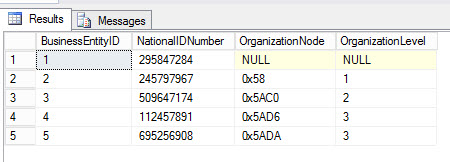
If you want to save the results in a txt file, you can do this in SSMS. Go to Tools>Options :
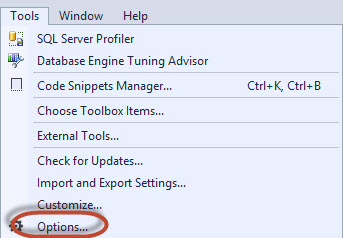
Select the option Result to file:
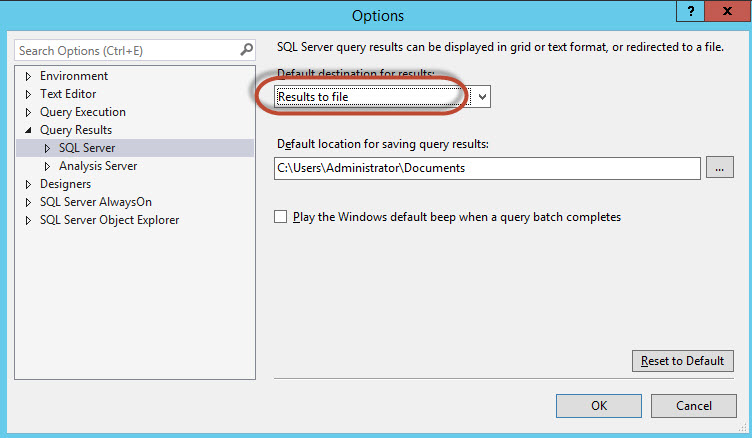
Create a query and execute the query. An option to specify the name and path will be displayed. We will call the results in a file named Results.rpt:
The result saved are the following:
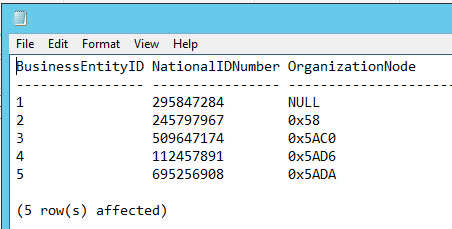
SQLCMD is the SQL Server Command Line utility. You can save the results in a file from here. This option is useful when you are using batch files to automate tasks.
Use the following command in the cmd:
The command used the myquery.sql file created before and the output is store to the file myoutput.txt:
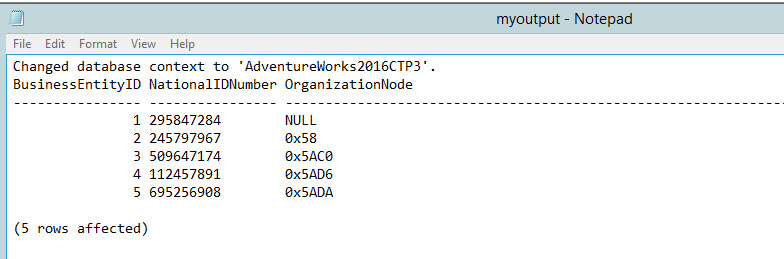
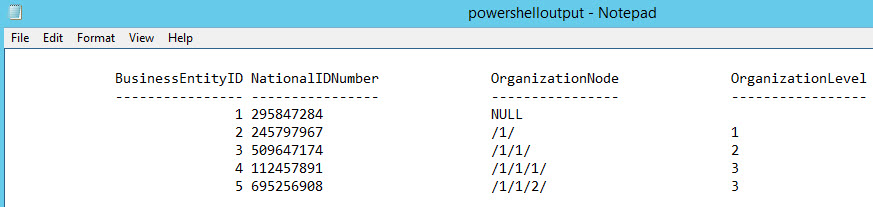
3. PowerShell
PowerShell is an extremely popular command line shell to automate tasks. We can export the SQL Server query results to a txt file by executing the following cmdlets:
Invoke-Sqlcmd will call the script myquery.sql created at the beginning of this article and store the results in a file named powershelloutput.txt. The results will be the following:
4. Import/Export Wizard in SSMS
In SSMS, when you right click a database. There is an option to import or export data. Go to Tasks>Export Data:
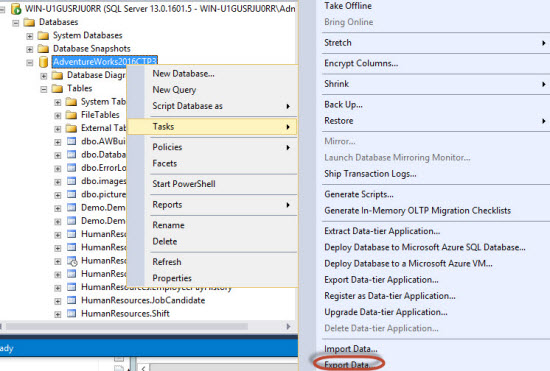
You will open the SQL Server Import and Export wizard:
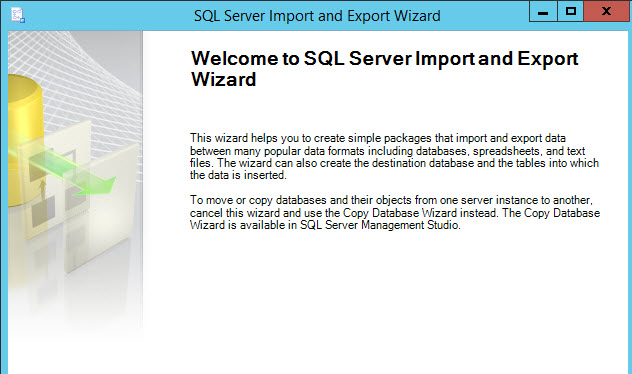
We will export from SQL Server to a Flat file. Select the Microsoft OLE DB Provider as the Data Source:
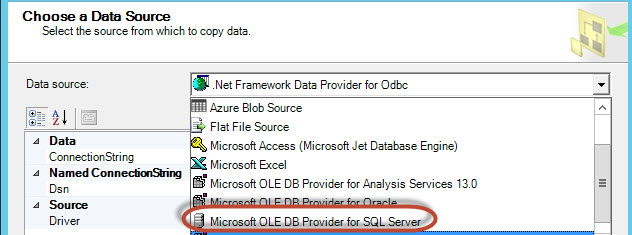
Specify the Server name and the connection information if necessary:
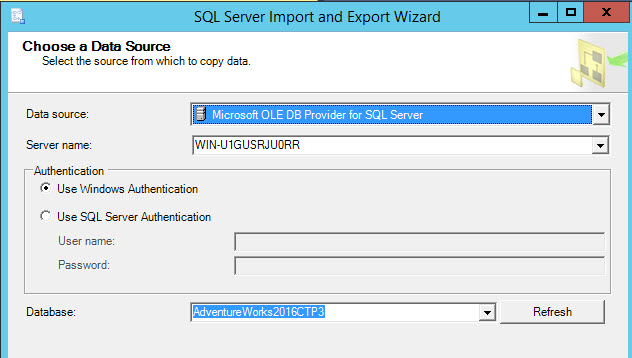
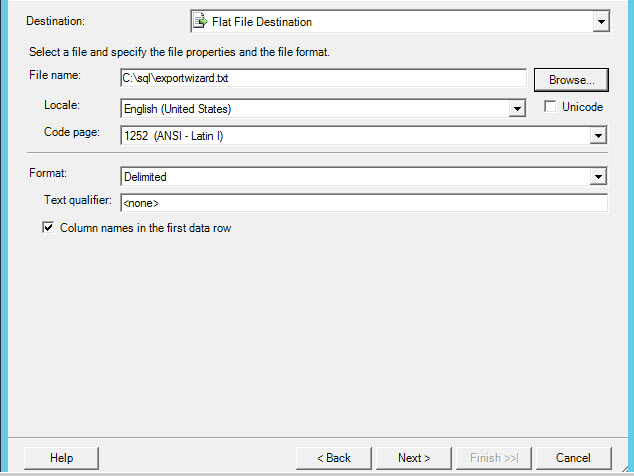
In Destination, select Flat File Destination and press browse to specify the file name and path:
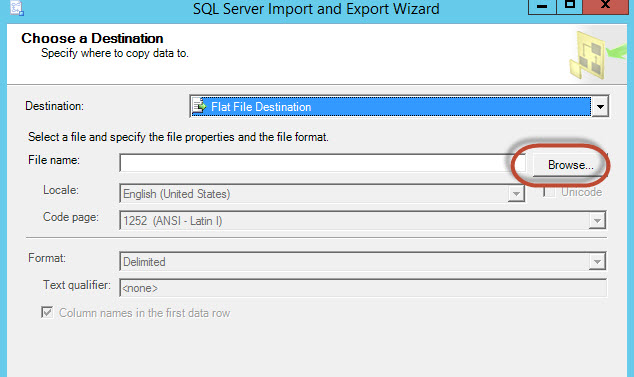
In this example, the flat file name will be exportwizard.txt:
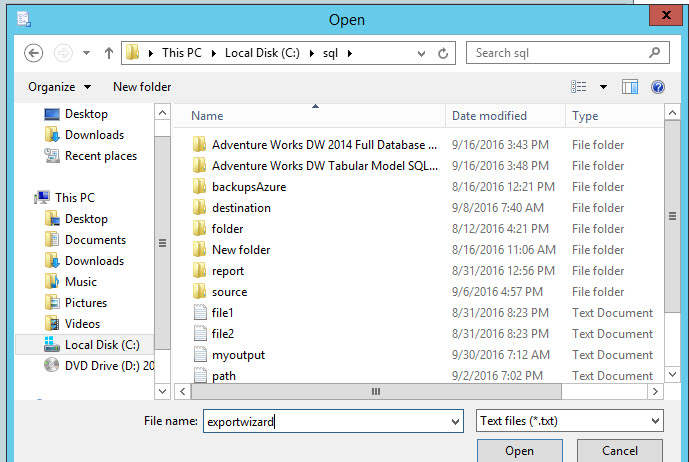
Once that you have the file name and path, press next:
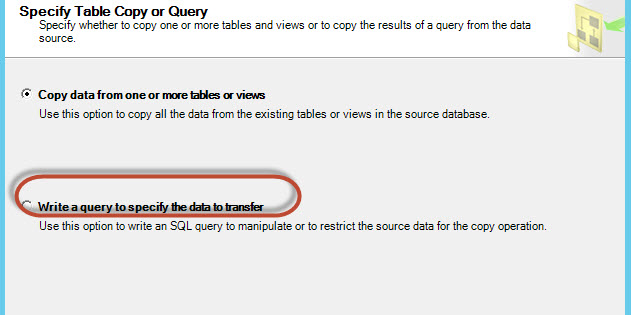
Select the option "Write a query to specify the data to transfer":
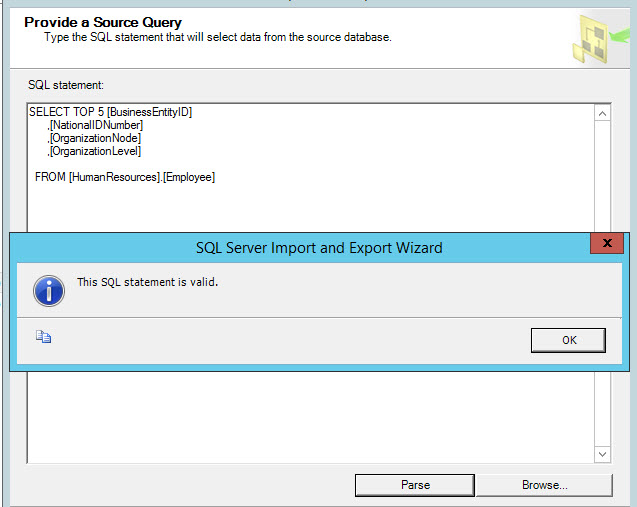
Specify the query of the file myquery.sql (used in other methods) and press parse to verify that the query is OK. A message specifying that the statement is valid should be displayed:
Keep the default values:
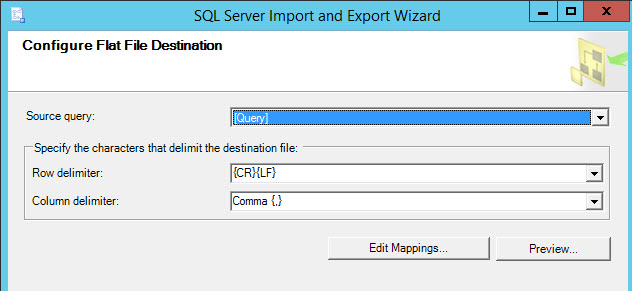
Select Run immediately to export the data immediately:
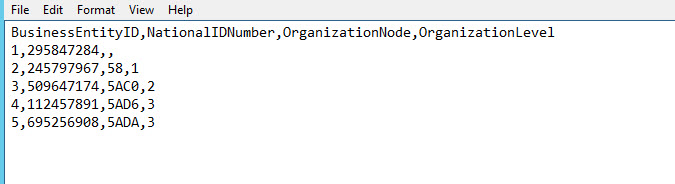
The file created will be similar to this one:
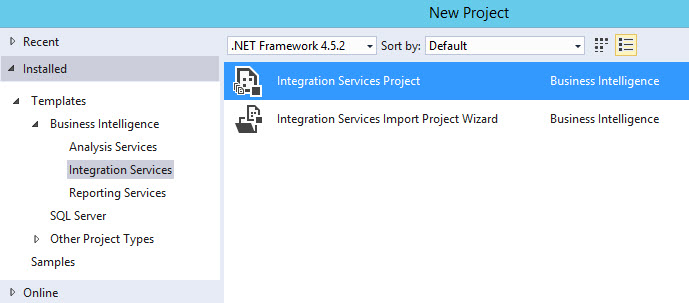
5. SSIS in SSDT
You can also use SSIS in SSDT. This method is similar to the Import/Export Wizard in SSMS, because SSMS calls SSIS to import and export Data.
Go to SSDT and then go to File>New Project and select Integration Services Project:
In Solution Explorer, right click SSIS Packages and select SSIS Import and Export Wizard:
The next steps are the same than in SSMS when we call the Import/Export wizard, but at the end, you do not have the option to run immediately.
To run the package, press Start:
The package will generate a text file with the CSV format.
You can export from SQL Server to a text file using C#. You could also perform a similar task using Visual Basic. In this example, we will use the Script task included in SSDT. This option is very useful if you are writing code and you need to integrate this task to the code.
To do this, in SSDT, drag and drop the Script Task:
Double click Script Task and press the Edit Script button:
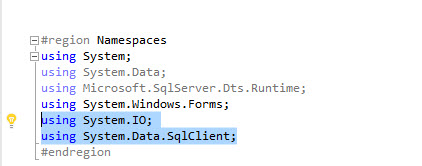
In #region Namespaces add System.IO and Data.SqlClient . Sysem.IO is used to write information to a file (in this scenario a txt file) and Data.SqlClient is used to connect to SQL Server:
In the Script in the region where is says add your code here, add the following code:
The first line is to specify the T-SQL Query:
The second line is to specify the connection information (SQL Server name, database name and Authentication method):
The third line is to specify the text file path:
We will use the SQL Connection and the query and open the connection:
The try structure is used to handle exceptions. The line with "while(reader.Read())" is used to read row by row the results of the SQL Query. myFile.WriteLine will write to the txt file all the information from SQL Server:
"Catch" is used to catch the exception errors. This is used to handle errors. MessageBox.Show will show the error and Dts.TaskResult will show a failure red color if it fails. This code is used when an exception error is generate by the package.
Finally, we will chose the file and SQL Server connection with Reader.Close and myFile.Close:
7. Reporting Services
Another option is to create a Report in SQL Server Reporting Services and save it as CSV. Reporting Services allows you to save reports in PDF, Excel, XML, MHTML, Word, CSV, PowerPoint and TIFF format. If the presentation is important, Reporting Services is the best option.
In SSDT, go to File>New Project and select Report Server Project Wizard:
A Welcome wizard will be displayed. Click next:
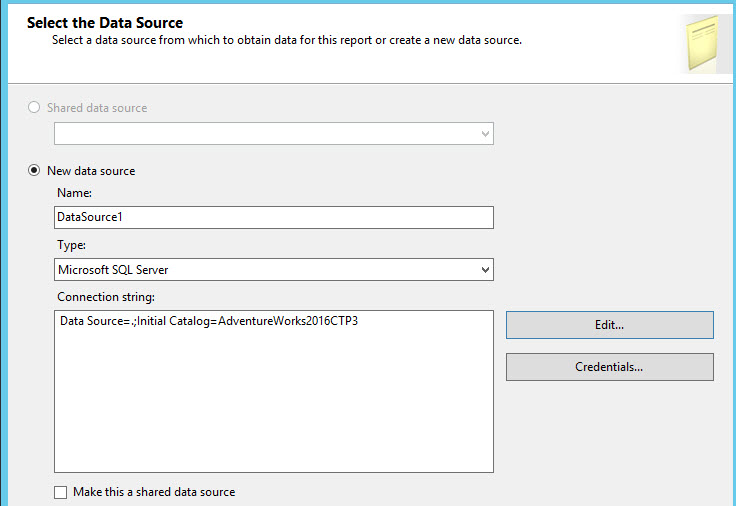
Specify the connection the SQL Server and Database. In this example, we are connecting to the local SQL Server and the AdventureWorks2016CTP3 database:
Specify the query:
Select the Tabular Report Type:
In "Design the table", press Finish:
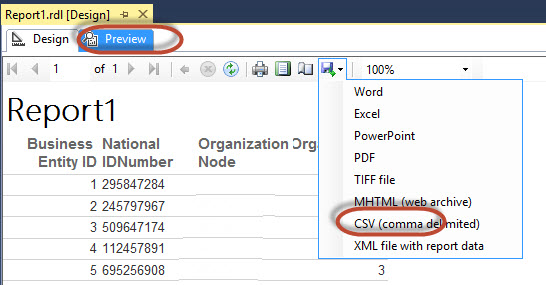
Press Preview and in the Save icon, select CSV (comma delimited) to save the file with the csv extension:
BCP is the Bulk Copy Program that comes with SQL Server. It is used to import data from a data file to SQL Server or from SQL Server to a data file. It is a very fast option. Use it if you have millions of rows and you need to use the command line or if it is easy to call the command line from your program or script.
The following example uses bcp to export the query results to a file named bcp.txt. -T is used to specify that we are using a Trusted Connection (Windows Connection) and -c is used to perform an operation of data type:
Conclusions
There are many other ways to export results. However, these options will inspire you to use other ones.
To resume, here you have some tips about when to use them:
1. SSMS destination to file option - This is the easiest option. Used if you do not need to automate anything and you just one a txt report immediately.
2. SQLCMD - Use it when you have a batch file or if you are using the command line to automate several tasks.
3. PowerShell - Use it when you are automating tasks with PowerShell or when you are using tools to call PowerShell scripts.
4. Import/Export Wizard in SSMS - Use it when you have millions of rows to copy files. It is a very fast option specialized in exporting and importing data from multiple sources.
5. SSIS Wizard (almost the same than the number 4, but we are using SSDT instead of SSMS to create the package). It is similar to 4, but it can be customized and you can create really complex packages integrated with Web services, send mails, PowerShell and more. Use it if you need a complex solution that requires integration between multiple tools.
6. C# - Use it when you have code for other tasks and you need to integrate with other lines of code in C#.
7. SSRS - SSRS is useful to create a nice customized report. Use it when the presentation is important.
8. BCP - It is a very fast option. Use it for large volumes of data.
- SSIS Script Task
- Reporting Services Tutorials
- PowerShell Solutions - Several tips for daily tasks
- myquery.sql
4.67 ( 40 )
Log in or register to rate
You rated this post out of 5. Change rating
Join the discussion and add your comment
Related content
Saving data to various formats, using sql.
- by Additional Articles
You have many options when exporting data from a database. In this article, Phil Factor compares several methods including XML and array-in-array JSON for speed and file size.
3,509 reads
Azure DWH part 16: BCP to import and export data
- by Daniel Calbimonte
- SQLServerCentral.com
In Azure SQL Data Warehouse we can use BCP to export or import the data. In this article, we will show how to do it.
2,070 reads
PowerShell Solutions - Working with files
When we administer a SQL Database, we always have to work with files. This new article shows how to handle them using PowerShell.
3,077 reads
Data Mining Part 37: The Data Mining query transformation task
This new chapter will show you how to work with the SSIS Data Mining Query Transformation Task
2,390 reads
JSON.SQL: A CLR-resident JSON serializer/deserializer for SQL Server
- by Bret Lowery
One CLR function and four CLR procedures for the import/export of JSON data to and from SQL Server are presented, with supporting performance metrics.
4.81 ( 32 )
17,267 reads

Use Microsoft Query to retrieve external data
You can use Microsoft Query to retrieve data from external sources. By using Microsoft Query to retrieve data from your corporate databases and files, you don't have to retype the data that you want to analyze in Excel. You can also refresh your Excel reports and summaries automatically from the original source database whenever the database is updated with new information.
Learn more about Microsoft Query
Using Microsoft Query, you can connect to external data sources, select data from those external sources, import that data into your worksheet, and refresh the data as needed to keep your worksheet data synchronized with the data in the external sources.
Types of databases that you can access You can retrieve data from several types of databases, including Microsoft Office Access, Microsoft SQL Server, and Microsoft SQL Server OLAP Services. You can also retrieve data from Excel workbooks and from text files.
Microsoft Office provides drivers that you can use to retrieve data from the following data sources:
Microsoft SQL Server Analysis Services (OLAP provider)
Microsoft Office Access
Microsoft FoxPro
Microsoft Office Excel
Text file databases
You can use also ODBC drivers or data source drivers from other manufacturers to retrieve information from data sources that are not listed here, including other types of OLAP databases. For information about installing an ODBC driver or data source driver that is not listed here, check the documentation for the database, or contact your database vendor.
Selecting data from a database You retrieve data from a database by creating a query, which is a question that you ask about data stored in an external database. For example, if your data is stored in an Access database, you might want to know the sales figures for a specific product by region. You can retrieve a part of the data by selecting only the data for the product and region that you want to analyze.
With Microsoft Query, you can select the columns of data that you want and import only that data into Excel.
Updating your worksheet in one operation Once you have external data in an Excel workbook, whenever your database changes, you can refresh the data to update your analysis — without having to re-create your summary reports and charts. For example, you can create a monthly sales summary and refresh it every month when the new sales figures come in.
How Microsoft Query uses data sources After you set up a data source for a particular database, you can use it whenever you want to create a query to select and retrieve data from that database — without having to retype all of the connection information. Microsoft Query uses the data source to connect to the external database and to show you what data is available. After you create your query and return the data to Excel, Microsoft Query provides the Excel workbook with both the query and data source information so that you can reconnect to the database when you want to refresh the data.
Using Microsoft Query to import data to import external data into Excel with Microsoft Query, follow these basic steps, each of which is described in more detail in the following sections.
Connect to a data source
What is a data source? A data source is a stored set of information that allows Excel and Microsoft Query to connect to an external database. When you use Microsoft Query to set up a data source, you give the data source a name, and then supply the name and the location of the database or server, the type of database, and your logon and password information. The information also includes the name of an OBDC driver or a data source driver, which is a program that makes connections to a specific type of database.
To set up a data source by using Microsoft Query:
On the Data tab, in the Get External Data group, click From Other Sources , and then click From Microsoft Query .
Do one of the following:
To specify a data source for a database, text file, or Excel workbook, click the Databases tab.
To specify an OLAP cube data source, click the OLAP Cubes tab. This tab is available only if you ran Microsoft Query from Excel.
Double-click <New Data Source> .
Click <New Data Source> , and then click OK .
The Create New Data Source dialog box is displayed.
In step 1, type a name to identify the data source.
In step 2, click a driver for the type of database that you are using as your data source.
If the external database that you want to access is not supported by the ODBC drivers that are installed with Microsoft Query, then you need to obtain and install a Microsoft Office-compatible ODBC driver from a third-party vendor, such as the manufacturer of the database. Contact the database vendor for installation instructions.
OLAP databases do not require ODBC drivers. When you install Microsoft Query, drivers are installed for databases that were created by using Microsoft SQL Server Analysis Services. To connect to other OLAP databases, you need to install a data source driver and client software.
Click Connect , and then provide the information that is needed to connect to your data source. For databases, Excel workbooks, and text files, the information that you provide depends on the type of data source that you selected. You may be asked to supply a logon name, a password, the version of the database that you are using, the database location, or other information specific to the type of database.
Important:
Use strong passwords that combine uppercase and lowercase letters, numbers, and symbols. Weak passwords don't mix these elements. Strong password: Y6dh!et5. Weak password: House27. Passwords should be 8 or more characters in length. A pass phrase that uses 14 or more characters is better.
It is critical that you remember your password. If you forget your password, Microsoft cannot retrieve it. Store the passwords that you write down in a secure place away from the information that they help protect.
After you enter the required information, click OK or Finish to return to the Create New Data Source dialog box.
If your database has tables and you want a particular table to display automatically in the Query Wizard, click the box for step 4, and then click the table that you want.
If you don't want to type your logon name and password when you use the data source, select the Save my user ID and password in the data source definition check box. The saved password is not encrypted. If the check box is unavailable, see your database administrator to determine whether this option can be made available.
Security Note: Avoid saving logon information when connecting to data sources. This information may be stored as plain text, and a malicious user could access the information to compromise the security of the data source.
After you complete these steps, the name of your data source appears in the Choose Data Source dialog box.
Use the Query Wizard to define a query
Use the Query Wizard for most queries The Query Wizard makes it easy to select and bring together data from different tables and fields in your database. Using the Query Wizard, you can select the tables and fields that you want to include. An inner join (a query operation that specifies that rows from two tables are combined based on identical field values) is created automatically when the wizard recognizes a primary key field in one table and a field with the same name in a second table.
You can also use the wizard to sort the result set and to do simple filtering. In the final step of the wizard, you can choose to return the data to Excel, or further refine the query in Microsoft Query. After you create the query, you can run it in either Excel or in Microsoft Query.
To start the Query Wizard, perform the following steps.
In the Choose Data Source dialog box, make sure that the Use the Query Wizard to create/edit queries check box is selected.
Double-click the data source that you want to use.
Click the data source that you want to use, and then click OK .
Work directly in Microsoft Query for other types of queries If you want to create a more complex query than the Query Wizard allows, you can work directly in Microsoft Query. You can use Microsoft Query to view and to change queries that you start creating in the Query Wizard, or you can create new queries without using the wizard. Work directly in Microsoft Query when you want to create queries that do the following:
Select specific data from a field In a large database, you might want to choose some of the data in a field and omit data that you don't need. For example, if you need data for two of the products in a field that contains information for many products, you can use criteria to select data for only the two products that you want.
Retrieve data based on different criteria each time you run the query If you need to create the same Excel report or summary for several areas in the same external data — such as a separate sales report for each region — you can create a parameter query. When you run a parameter query, you are prompted for a value to use as the criterion when the query selects records. For example, a parameter query might prompt you to enter a specific region, and you could reuse this query to create each of your regional sales reports.
Join data in different ways The inner joins that the Query Wizard creates are the most common type of join used in creating queries. Sometimes, however, you want to use a different type of join. For example, if you have a table of product sales information and a table of customer information, an inner join (the type created by the Query Wizard) will prevent the retrieval of customer records for customers who have not made a purchase. Using Microsoft Query, you can join these tables so that all the customer records are retrieved, along with sales data for those customers who have made purchases.
To start Microsoft Query, perform the following steps.
In the Choose Data Source dialog box, make sure that the Use the Query Wizard to create/edit queries check box is clear.
Reusing and sharing queries In both the Query Wizard and Microsoft Query, you can save your queries as a .dqy file that you can modify, reuse, and share. Excel can open .dqy files directly, which allows you or other users to create additional external data ranges from the same query.
To open a saved query from Excel:
On the Data tab, in the Get External Data group, click From Other Sources , and then click From Microsoft Query . The Choose Data Source dialog box is displayed.
In the Choose Data Source dialog box, click the Queries tab.
Double-click the saved query that you want to open. The query is displayed in Microsoft Query.
If you want to open a saved query and Microsoft Query is already open, click the Microsoft Query File menu, and then click Open .
If you double-click a .dqy file, Excel opens, runs the query, and then inserts the results into a new worksheet.
If you want to share an Excel summary or report that is based on external data, you can give other users a workbook that contains an external data range, or you can create a template. A template allows you to save the summary or report without saving the external data so that the file is smaller. The external data is retrieved when a user opens the report template.
Work with the data in Excel
After you create a query in either the Query Wizard or Microsoft Query, you can return the data to an Excel worksheet. The data then becomes an external data range or a PivotTable report that you can format and refresh.
Formatting retrieved data In Excel, you can use tools, such as charts or automatic subtotals, to present and to summarize the data retrieved by Microsoft Query. You can format the data, and your formatting is retained when you refresh the external data. You can use your own column labels instead of the field names, and add row numbers automatically.
Excel can automatically format new data that you type at the end of a range to match the preceding rows. Excel can also automatically copy formulas that have been repeated in the preceding rows and extends them to additional rows.
Note: In order to be extended to new rows in the range, the formats and formulas must appear in at least three of the five preceding rows.
You can turn on this option (or off again) at any time:
Click File > Options > Advanced .
In the Editing options section, select the Extend data range formats and formulas check. To turn off automatic data range formatting again, clear this check box.
Refreshing external data When you refresh external data, you run the query to retrieve any new or changed data that matches your specifications. You can refresh a query in both Microsoft Query and Excel. Excel provides several options for refreshing queries, including refreshing the data whenever you open the workbook and automatically refreshing it at timed intervals. You can continue to work in Excel while data is being refreshed, and you can also check the status while the data is being refreshed. For more information, see Refresh an external data connection in Excel .
Top of Page

Need more help?
Want more options.
Explore subscription benefits, browse training courses, learn how to secure your device, and more.

Microsoft 365 subscription benefits

Microsoft 365 training

Microsoft security

Accessibility center
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.

Ask the Microsoft Community

Microsoft Tech Community

Windows Insiders
Microsoft 365 Insiders
Was this information helpful?
Thank you for your feedback.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Hints (Transact-SQL) - Query
- 26 contributors
Query hints specify that the indicated hints are used in the scope of a query. They affect all operators in the statement. If UNION is involved in the main query, only the last query involving a UNION operation can have the OPTION clause. Query hints are specified as part of the OPTION clause . Error 8622 occurs if one or more query hints cause the Query Optimizer not to generate a valid plan.
Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend only using hints as a last resort for experienced developers and database administrators.
Applies to:
To view Transact-SQL syntax for SQL Server 2014 (12.x) and earlier versions, see Previous versions documentation .
{ HASH | ORDER } GROUP
Specifies that aggregations that the query's GROUP BY or DISTINCT clause describes should use hashing or ordering.
{ MERGE | HASH | CONCAT } UNION
Specifies that all UNION operations are run by merging, hashing, or concatenating UNION sets. If more than one UNION hint is specified, the Query Optimizer selects the least expensive strategy from those hints specified.
{ LOOP | MERGE | HASH } JOIN
Specifies all join operations are performed by LOOP JOIN, MERGE JOIN, or HASH JOIN in the whole query. If you specify more than one join hint, the optimizer selects the least expensive join strategy from the allowed ones.
If you specify a join hint in the same query's FROM clause for a specific table pair, this join hint takes precedence in the joining of the two tables. The query hints, though, must still be honored. The join hint for the pair of tables might only restrict the selection of allowed join methods in the query hint. For more information, see Join Hints (Transact-SQL) .
DISABLE_OPTIMIZED_PLAN_FORCING
Applies to: SQL Server (Starting with SQL Server 2022 (16.x))
Disables Optimized plan forcing for a query.
Optimized plan forcing reduces compilation overhead for repeating forced queries. Once the query execution plan is generated, specific compilation steps are stored for reuse as an optimization replay script. An optimization replay script is stored as part of the compressed showplan XML in Query Store , in a hidden OptimizationReplay attribute.
EXPAND VIEWS
Specifies the indexed views are expanded. Also specifies the Query Optimizer doesn't consider any indexed view as a replacement for any query part. A view is expanded when the view definition replaces the view name in the query text.
This query hint virtually disallows direct use of indexed views and indexes on indexed views in the query plan.
The indexed view remains condensed if there's a direct reference to the view in the query's SELECT part. The view also remains condensed if you specify WITH (NOEXPAND) or WITH (NOEXPAND, INDEX( <index_value> [ , *...n* ] ) ) . For more information about the query hint NOEXPAND, see Using NOEXPAND .
The hint only affects the views in the statements' SELECT part, including those views in INSERT, UPDATE, MERGE, and DELETE statements.
FAST <integer_value>
Specifies that the query is optimized for fast retrieval of the first <integer_value> number of rows. This result is a non-negative integer. After the first <integer_value> number of rows are returned, the query continues execution and produces its full result set.
FORCE ORDER
Specifies that the join order indicated by the query syntax is preserved during query optimization. Using FORCE ORDER doesn't affect possible role reversal behavior of the Query Optimizer.
In a MERGE statement, the source table is accessed before the target table as the default join order, unless the WHEN SOURCE NOT MATCHED clause is specified. Specifying FORCE ORDER preserves this default behavior.
{ FORCE | DISABLE } EXTERNALPUSHDOWN
Force or disable the pushdown of the computation of qualifying expressions in Hadoop. Only applies to queries using PolyBase. Won't push down to Azure storage.
{ FORCE | DISABLE } SCALEOUTEXECUTION
Force or disable scale-out execution of PolyBase queries that are using external tables in SQL Server 2019 Big Data Clusters . This hint is only honored by a query using the master instance of a SQL Big Data Cluster. The scale out occurs across the compute pool of the big data cluster.
Changes the recompilation thresholds for temporary tables, and makes them identical to those for permanent tables. The estimated recompile threshold starts an automatic recompile for the query when the estimated number of indexed column changes have been made to a table by running one of the following statements:
Specifying KEEP PLAN makes sure a query isn't recompiled as frequently when there are multiple updates to a table.
KEEPFIXED PLAN
Forces the Query Optimizer not to recompile a query because of changes in statistics. Specifying KEEPFIXED PLAN makes sure that a query recompiles only if the schema of the underlying tables changes, or if sp_recompile runs against those tables.
IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX
Applies to : SQL Server (starting with SQL Server 2012 (11.x)).
Prevents the query from using a nonclustered memory optimized columnstore index. If the query contains the query hint to avoid the use of the columnstore index, and an index hint to use a columnstore index, the hints are in conflict and the query returns an error.
MAX_GRANT_PERCENT = <numeric_value>
Applies to : SQL Server (starting with SQL Server 2012 (11.x) Service Pack 3, SQL Server 2014 (12.x) Service Pack 2 and Azure SQL Database.
The maximum memory grant size in PERCENT of configured memory limit. The query is guaranteed not to exceed this limit if the query is running in a user defined resource pool. In this case, if the query doesn't have the minimum required memory the system raises an error. If a query is running in the system pool (default), then it gets at minimum the memory required to run. The actual limit can be lower if the Resource Governor setting is lower than the value specified by this hint. Valid values are between 0.0 and 100.0.
The memory grant hint isn't available for index creation or index rebuilding.
MIN_GRANT_PERCENT = <numeric_value>
The minimum memory grant size in PERCENT of configured memory limit. The query is guaranteed to get MAX(required memory, min grant) because at least required memory is needed to start a query. Valid values are between 0.0 and 100.0.
The min_grant_percent memory grant option overrides the sp_configure option (minimum memory per query (KB)) regardless of the size. The memory grant hint isn't available for index creation or index rebuilding.
MAXDOP <integer_value>
Applies to : SQL Server (starting with SQL Server 2008 (10.0.x)) and Azure SQL Database.
Overrides the max degree of parallelism configuration option of sp_configure . Also overrides the Resource Governor for the query specifying this option. The MAXDOP query hint can exceed the value configured with sp_configure . If MAXDOP exceeds the value configured with Resource Governor, the Database Engine uses the Resource Governor MAXDOP value, described in ALTER WORKLOAD GROUP (Transact-SQL) . All semantic rules used with the max degree of parallelism configuration option are applicable when you use the MAXDOP query hint. For more information, see Configure the max degree of parallelism Server Configuration Option .
If MAXDOP is set to zero, then the server chooses the max degree of parallelism.
MAXRECURSION <integer_value>
Specifies the maximum number of recursions allowed for this query. number is a nonnegative integer between 0 and 32,767. When 0 is specified, no limit is applied. If this option isn't specified, the default limit for the server is 100.
When the specified or default number for MAXRECURSION limit is reached during query execution, the query ends and an error returns.
Because of this error, all effects of the statement are rolled back. If the statement is a SELECT statement, partial results or no results might be returned. Any partial results returned might not include all rows on recursion levels beyond the specified maximum recursion level.
For more information, see WITH common_table_expression (Transact-SQL) .
NO_PERFORMANCE_SPOOL
Applies to : SQL Server (starting with SQL Server 2016 (13.x)) and Azure SQL Database.
Prevents a spool operator from being added to query plans (except for the plans when spool is required to guarantee valid update semantics). The spool operator can reduce performance in some scenarios. For example, the spool uses tempdb , and tempdb contention can occur if there are many concurrent queries running with the spool operations.
OPTIMIZE FOR ( @variable_name { UNKNOWN | = <literal_constant> } [ , ...n ] )
Instructs the Query Optimizer to use a particular value for a local variable when the query is compiled and optimized. The value is used only during query optimization, and not during query execution.
@variable_name
The name of a local variable used in a query, to which a value can be assigned for use with the OPTIMIZE FOR query hint.
Specifies that the Query Optimizer uses statistical data instead of the initial value to determine the value for a local variable during query optimization.
<literal_constant>
A literal constant value to be assigned @variable_name for use with the OPTIMIZE FOR query hint. <literal_constant> is used only during query optimization, and not as the value of @variable_name during query execution. <literal_constant> can be of any SQL Server system data type that can be expressed as a literal constant. The data type of <literal_constant> must be implicitly convertible to the data type that @variable_name references in the query.
OPTIMIZE FOR can counteract the optimizer's default parameter detection behavior. Also use OPTIMIZE FOR when you create plan guides. For more information, see Recompile a Stored Procedure .
OPTIMIZE FOR UNKNOWN
Instructs the Query Optimizer to use the average selectivity of the predicate across all column values instead of using the runtime parameter value when the query is compiled and optimized.
If you use OPTIMIZE FOR @variable_name = <literal_constant> and OPTIMIZE FOR UNKNOWN in the same query hint, the Query Optimizer uses the literal_constant specified for a specific value. The Query Optimizer uses UNKNOWN for the rest of the variable values. The values are used only during query optimization, and not during query execution.
PARAMETERIZATION { SIMPLE | FORCED }
Specifies the parameterization rules that the SQL Server Query Optimizer applies to the query when it's compiled.
The PARAMETERIZATION query hint can only be specified inside a plan guide to override the current setting of the PARAMETERIZATION database SET option. It can't be specified directly within a query.
For more information, see Specify Query Parameterization Behavior by Using Plan Guides .
SIMPLE instructs the Query Optimizer to attempt simple parameterization. FORCED instructs the Query Optimizer to attempt forced parameterization. For more information, see Forced Parameterization in the Query Processing Architecture Guide , and Simple Parameterization in the Query Processing Architecture Guide .
QUERYTRACEON <integer_value>
This option lets you enable a plan-affecting trace flag only during single-query compilation. Like other query-level options, you can use it together with plan guides to match the text of a query being executed from any session, and automatically apply a plan-affecting trace flag when this query is being compiled. The QUERYTRACEON option is only supported for Query Optimizer trace flags. For more information, see Trace Flags .
Using this option won't return any error or warning if an unsupported trace flag number is used. If the specified trace flag isn't one that affects a query execution plan, the option is silently ignored.
To use more than one trace flag in a query, specify one QUERYTRACEON hint for each different trace flag number.
Instructs the SQL Server Database Engine to generate a new, temporary plan for the query and immediately discard that plan after the query completes execution. The generated query plan doesn't replace a plan stored in cache when the same query runs without the RECOMPILE hint. Without specifying RECOMPILE, the Database Engine caches query plans and reuses them. When compiling query plans, the RECOMPILE query hint uses the current values of any local variables in the query. If the query is inside a stored procedure, the current values passed to any parameters.
RECOMPILE is a useful alternative to creating a stored procedure. RECOMPILE uses the WITH RECOMPILE clause when only a subset of queries inside the stored procedure, instead of the whole stored procedure, must be recompiled. For more information, see Recompile a Stored Procedure . RECOMPILE is also useful when you create plan guides.
ROBUST PLAN
Forces the Query Optimizer to try a plan that works for the maximum potential row size, possibly at the expense of performance. When the query is processed, intermediate tables and operators might have to store and process rows that are wider than any one of the input rows when the query is processed. The rows might be so wide that, sometimes, the particular operator can't process the row. If rows are that wide, the Database Engine produces an error during query execution. By using ROBUST PLAN, you instruct the Query Optimizer not to consider any query plans that might run into this problem.
If such a plan isn't possible, the Query Optimizer returns an error instead of deferring error detection to query execution. Rows can contain variable-length columns; the Database Engine allows for rows to be defined that have a maximum potential size beyond the ability of the Database Engine to process them. Generally, despite the maximum potential size, an application stores rows that have actual sizes within the limits that the Database Engine can process. If the Database Engine comes across a row that is too long, an execution error is returned.
USE HINT ( ' hint_name ' )
Applies to : SQL Server (starting with SQL Server 2016 (13.x) SP1) and Azure SQL Database.
Provides one or more additional hints to the query processor. The additional hints are specified by a hint name inside single quotation marks .
The following hint names are supported:
'ASSUME_JOIN_PREDICATE_DEPENDS_ON_FILTERS'
Causes SQL Server to generate a query plan using the Simple Containment assumption instead of the default Base Containment assumption for joins, under the Query Optimizer Cardinality Estimation model of SQL Server 2014 (12.x) or newer. This hint name is equivalent to trace flag 9476.
'ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES'
Causes SQL Server to generate a plan using minimum selectivity when estimating AND predicates for filters to account for full correlation. This hint name is equivalent to trace flag 4137 when used with cardinality estimation model of SQL Server 2012 (11.x) and earlier versions, and has similar effect when trace flag 9471 is used with cardinality estimation model of SQL Server 2014 (12.x) or higher.
'ASSUME_FULL_INDEPENDENCE_FOR_FILTER_ESTIMATES'
Causes SQL Server to generate a plan using maximum selectivity when estimating AND predicates for filters to account for full independence. This hint name is the default behavior of the cardinality estimation model of SQL Server 2012 (11.x) and earlier versions, and equivalent to trace flag 9472 when used with cardinality estimation model of SQL Server 2014 (12.x) or higher.
Applies to : Azure SQL Database
'ASSUME_PARTIAL_CORRELATION_FOR_FILTER_ESTIMATES'
Causes SQL Server to generate a plan using most to least selectivity when estimating AND predicates for filters to account for partial correlation. This hint name is the default behavior of the cardinality estimation model of SQL Server 2014 (12.x) or higher.
'DISABLE_BATCH_MODE_ADAPTIVE_JOINS'
Disables batch mode adaptive joins. For more information, see Batch mode Adaptive Joins .
Applies to : SQL Server (starting with SQL Server 2017 (14.x)) and Azure SQL Database
'DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK'
Disables batch mode memory grant feedback. For more information, see Batch mode memory grant feedback .
'DISABLE_DEFERRED_COMPILATION_TV'
Disables table variable deferred compilation. For more information, see Table variable deferred compilation .
Applies to : SQL Server (starting with SQL Server 2019 (15.x)) and Azure SQL Database
'DISABLE_INTERLEAVED_EXECUTION_TVF'
Disables interleaved execution for multi-statement table-valued functions. For more information, see Interleaved execution for multi-statement table-valued functions .
'DISABLE_OPTIMIZED_NESTED_LOOP'
Instructs the query processor not to use a sort operation (batch sort) for optimized nested loop joins when generating a query plan. This hint name is equivalent to trace flag 2340.
'DISABLE_OPTIMIZER_ROWGOAL'
Causes SQL Server to generate a plan that doesn't use row goal modifications with queries that contain these keywords:
- OPTION (FAST N)
This hint name is equivalent to trace flag 4138.
'DISABLE_PARAMETER_SNIFFING'
Instructs Query Optimizer to use average data distribution while compiling a query with one or more parameters. This instruction makes the query plan independent on the parameter value that was first used when the query was compiled. This hint name is equivalent to trace flag 4136 or Database Scoped Configuration setting PARAMETER_SNIFFING = OFF .
'DISABLE_ROW_MODE_MEMORY_GRANT_FEEDBACK'
Disables row mode memory grant feedback. For more information, see Row mode memory grant feedback .
'DISABLE_TSQL_SCALAR_UDF_INLINING'
Disables scalar UDF inlining. For more information, see Scalar UDF Inlining .
'DISALLOW_BATCH_MODE'
Disables batch mode execution. For more information, see Execution modes .
'ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS'
Enables automatically generated quick statistics (histogram amendment) for any leading index column for which cardinality estimation is needed. The histogram used to estimate cardinality will be adjusted at query compile time to account for actual maximum or minimum value of this column. This hint name is equivalent to trace flag 4139.
'ENABLE_QUERY_OPTIMIZER_HOTFIXES'
Enables Query Optimizer hotfixes (changes released in SQL Server Cumulative Updates and Service Packs). This hint name is equivalent to trace flag 4199 or Database Scoped Configuration setting QUERY_OPTIMIZER_HOTFIXES = ON .
'FORCE_DEFAULT_CARDINALITY_ESTIMATION'
Forces the Query Optimizer to use Cardinality Estimation model that corresponds to the current database compatibility level. Use this hint to override Database Scoped Configuration setting LEGACY_CARDINALITY_ESTIMATION = ON or trace flag 9481.
'FORCE_LEGACY_CARDINALITY_ESTIMATION'
Forces the Query Optimizer to use Cardinality Estimation model of SQL Server 2012 (11.x) and earlier versions. This hint name is equivalent to trace flag 9481 or Database Scoped Configuration setting LEGACY_CARDINALITY_ESTIMATION = ON .
'QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_n'
Forces the Query Optimizer behavior at a query level. This behavior happens as if the query was compiled with database compatibility level n , where n is a supported database compatibility level (for example 100, 130, etc.). Refer to sys.dm_exec_valid_use_hints for a list of currently supported values for n .
Applies to : SQL Server (starting with SQL Server 2017 (14.x) CU10) and Azure SQL Database
The QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_n hint doesn't override default or legacy cardinality estimation setting, if it's forced through database scoped configuration, trace flag or another query hint such as QUERYTRACEON. This hint only affects the behavior of the Query Optimizer. It doesn't affect other features of SQL Server that may depend on the database compatibility level , such as the availability of certain database features. To learn more about this hint, see Developer's Choice: Hinting Query Execution model .
'QUERY_PLAN_PROFILE'
Enables lightweight profiling for the query. When a query that contains this new hint finishes, a new Extended Event, query_plan_profile, is fired. This extended event exposes execution statistics and actual execution plan XML similar to the query_post_execution_showplan extended event but only for queries that contains the new hint.
Applies to : SQL Server (starting with SQL Server 2016 (13.x) SP2 CU3 and SQL Server 2017 (14.x) CU11).
If you enable collecting the query_post_execution_showplan extended event, this will add standard profiling infrastructure to every query that is running on the server and therefore can affect overall server performance. If you enable the collection of query_thread_profile extended event to use lightweight profiling infrastructure instead, this will result in much less performance overhead but will still affect overall server performance. If you enable the query_plan_profile extended event, this will only enable the lightweight profiling infrastructure for a query that executed with the query_plan_profile and therefore will not affect other workloads on the server. Use this hint to profile a specific query without affecting other parts of the server workload. To learn more about lightweight profiling, see Query Profiling Infrastructure .
The list of all supported USE HINT names can be queried using the dynamic management view sys.dm_exec_valid_use_hints .
Hint names are case-insensitive.
Some USE HINT hints might conflict with trace flags enabled at the global or session level, or database scoped configuration settings. In this case, the query level hint (USE HINT) always takes precedence. If a USE HINT conflicts with another query hint, or a trace flag enabled at the query level (such as by QUERYTRACEON), SQL Server will generate an error when trying to execute the query.
USE PLAN N' <xml_plan> '
Forces the Query Optimizer to use an existing query plan for a query that is specified by ' <xml_plan> '. USE PLAN can't be specified with INSERT, UPDATE, MERGE, or DELETE statements.
The resulting execution plan forced by this feature will be the same or similar to the plan being forced. Because the resulting plan might not be identical to the plan specified by USE PLAN, the performance of the plans can vary. In rare cases, the performance difference can be significant and negative; in that case, the administrator must remove the forced plan.
TABLE HINT ( <exposed_object_name> [ , <table_hint> [ [, ] ...n ] ] )
Applies the specified table hint to the table or view that corresponds to exposed_object_name . We recommend using a table hint as a query hint only in the context of a plan guide .
<exposed_object_name> can be one of the following references:
When an alias is used for the table or view in the FROM clause of the query, exposed_object_name is the alias.
When an alias isn't used, exposed_object_name is the exact match of the table or view referenced in the FROM clause. For example, if the table or view is referenced using a two-part name, exposed_object_name is the same two-part name.
When you specify exposed_object_name without also specifying a table hint, any indexes you specify in the query as part of a table hint for the object are disregarded. The Query Optimizer then determines index usage. You can use this technique to eliminate the effect of an INDEX table hint when you can't modify the original query. See Example J.
<table_hint>
NOEXPAND [ , INDEX ( <index_value> [ ,...n ] ) | INDEX = ( <index_value> ) ] | INDEX ( <index_value> [ ,...n ] ) | INDEX = ( <index_value> ) | FORCESEEK [( <index_value> ( <index_column_name> [,... ] ) ) ] | FORCESCAN | HOLDLOCK | NOLOCK | NOWAIT | PAGLOCK | READCOMMITTED | READCOMMITTEDLOCK | READPAST | READUNCOMMITTED | REPEATABLEREAD | ROWLOCK | SERIALIZABLE | SNAPSHOT | SPATIAL_WINDOW_MAX_CELLS = <integer_value> | TABLOCK | TABLOCKX | UPDLOCK | XLOCK
Is the table hint to apply to the table or view that corresponds to exposed_object_name as a query hint. For a description of these hints, see Table Hints (Transact-SQL) .
Table hints other than INDEX, FORCESCAN, and FORCESEEK are disallowed as query hints unless the query already has a WITH clause specifying the table hint. For more information, see the Remarks section .
Specifying FORCESEEK with parameters limits the number of plans that can be considered by the Query Optimizer more than when specifying FORCESEEK without parameters. This might cause a "Plan cannot be generated" error to occur in more cases.
Query hints can't be specified in an INSERT statement, except when a SELECT clause is used inside the statement.
Query hints can be specified only in the top-level query, not in subqueries. When a table hint is specified as a query hint, the hint can be specified in the top-level query or in a subquery. However, the value specified for <exposed_object_name> in the TABLE HINT clause must match exactly the exposed name in the query or subquery.
Specify table hints as query hints
We recommend using the INDEX, FORCESCAN, or FORCESEEK table hint as a query hint only in the context of a plan guide . Plan guides are useful when you can't modify the original query, for example, because it's a third-party application. The query hint specified in the plan guide is added to the query before it's compiled and optimized. For ad hoc queries, use the TABLE HINT clause only when testing plan guide statements. For all other ad hoc queries, we recommend specifying these hints only as table hints.
When specified as a query hint, the INDEX, FORCESCAN, and FORCESEEK table hints are valid for the following objects:
- Indexed views
- Common table expressions (the hint must be specified in the SELECT statement whose result set populates the common table expression)
- Dynamic Management Views (DMVs)
- Named subqueries
You can specify INDEX, FORCESCAN, and FORCESEEK table hints as query hints for a query that doesn't have any existing table hints. You can also use them to replace existing INDEX, FORCESCAN, or FORCESEEK hints in the query, respectively.
Table hints other than INDEX, FORCESCAN, and FORCESEEK are disallowed as query hints unless the query already has a WITH clause specifying the table hint. In this case, a matching hint must also be specified as a query hint. Specify the matching hint as a query hint by using TABLE HINT in the OPTION clause. This specification preserves the query's semantics. For example, if the query contains the table hint NOLOCK, the OPTION clause in the @hints parameter of the plan guide must also contain the NOLOCK hint. See Example K.
Specify hints with Query Store hints
You can enforce hints on queries identified through Query Store without making code changes, using the Query Store hints feature. Use the sys.sp_query_store_set_hints stored procedure to apply a hint to a query. See Example N.
A. Use MERGE JOIN
The following example specifies that MERGE JOIN runs the JOIN operation in the query. The example uses the AdventureWorks2022 database.
B. Use OPTIMIZE FOR
The following example instructs the Query Optimizer to use the value 'Seattle' for @city_name and to use the average selectivity of the predicate across all column values for @postal_code when optimizing the query. The example uses the AdventureWorks2022 database.
C. Use MAXRECURSION
MAXRECURSION can be used to prevent a poorly formed recursive common table expression from entering into an infinite loop. The following example intentionally creates an infinite loop and uses the MAXRECURSION hint to limit the number of recursion levels to two. The example uses the AdventureWorks2022 database.
After the coding error is corrected, MAXRECURSION is no longer required.
D. Use MERGE UNION
The following example uses the MERGE UNION query hint. The example uses the AdventureWorks2022 database.
E. Use HASH GROUP and FAST
The following example uses the HASH GROUP and FAST query hints. The example uses the AdventureWorks2022 database.
F. Use MAXDOP
The following example uses the MAXDOP query hint. The example uses the AdventureWorks2022 database.
G. Use INDEX
The following examples use the INDEX hint. The first example specifies a single index. The second example specifies multiple indexes for a single table reference. In both examples, because you apply the INDEX hint on a table that uses an alias, the TABLE HINT clause must also specify the same alias as the exposed object name. The example uses the AdventureWorks2022 database.
H. Use FORCESEEK
The following example uses the FORCESEEK table hint. The TABLE HINT clause must also specify the same two-part name as the exposed object name. Specify the name when you apply the INDEX hint on a table that uses a two-part name. The example uses the AdventureWorks2022 database.
I. Use multiple table hints
The following example applies the INDEX hint to one table and the FORCESEEK hint to another. The example uses the AdventureWorks2022 database.
J. Use TABLE HINT to override an existing table hint
The following example shows how to use the TABLE HINT hint. You can use the hint without specifying a hint to override the INDEX table hint behavior you specify in the FROM clause of the query. The example uses the AdventureWorks2022 database.
K. Specify semantics-affecting table hints
The following example contains two table hints in the query: NOLOCK, which is semantic-affecting, and INDEX, which is non-semantic-affecting. To preserve the semantics of the query, the NOLOCK hint is specified in the OPTIONS clause of the plan guide. Along with the NOLOCK hint, specify the INDEX and FORCESEEK hints and replace the non-semantic-affecting INDEX hint in the query during statement compilation and optimization. The example uses the AdventureWorks2022 database.
The following example shows an alternative method to preserving the semantics of the query and allowing the optimizer to choose an index other than the index specified in the table hint. Allow the optimizer to choose by specifying the NOLOCK hint in the OPTIONS clause. You specify the hint because it's semantic-affecting. Then, specify the TABLE HINT keyword with only a table reference and no INDEX hint. The example uses the AdventureWorks2022 database.
L. Use USE HINT
The following example uses the RECOMPILE and USE HINT query hints. The example uses the AdventureWorks2022 database.
M. Use QUERYTRACEON HINT
The following example uses the QUERYTRACEON query hints. The example uses the AdventureWorks2022 database. You can enable all plan-affecting hotfixes controlled by trace flag 4199 for a particular query using the following query:
You can also use multiple trace flags as in the following query:
N. Use Query Store hints
The Query Store hints feature in Azure SQL Database provides an easy-to-use method for shaping query plans without changing application code.
First, identify the query that has already been executed in the Query Store catalog views, for example:
The following example applies the hint to force the legacy cardinality estimator to query_id 39, identified in Query Store:
The following example applies the hint to enforce a maximum memory grant size in PERCENT of configured memory limit to query_id 39, identified in Query Store:
The following example applies multiple query hints to query_id 39, including RECOMPILE, MAXDOP 1, and the SQL 2012 query optimizer behavior:
Related content
- Hints (Transact-SQL)
- Query Store hints
- Plan guides
- DBCC TRACEON - Trace Flags (Transact-SQL)
Was this page helpful?
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback .
Submit and view feedback for
Additional resources
SQL Server Stored Procedure Tutorial
By: greg robidoux.
A stored procedure is nothing more than prepared SQL code that you save so you can reuse the code over and over again. So if you think about a query that you write over and over again, instead of having to write that query each time you would save it as a stored procedure and then just call the stored procedure to execute the SQL code that you saved as part of the stored procedure.
In addition to running the same SQL code over and over again you also have the ability to pass parameters to the stored procedure, so depending on what the need is the stored procedure can act accordingly based on the parameter values that were passed.
Take a look through each of these topics to learn how to get started with stored procedure development for SQL Server.
You can either use the outline on the left or click on the arrows to the right or below to scroll through each of these topics.
Next >>
Comments for this article.

Download Interview guide PDF
Sql query interview questions, download pdf.
SQL stands for Structured Query Language . Initially, it was named Structured English Query Language (SEQUEL). It is used in relational database management systems to store and manage data (RDMS).
It is a relational database system with standard language. A user can create, read, update, and delete relational databases and tables with it. SQL is the standard database language used by every RDBMS, including MySQL, Informix, Oracle, MS Access, and SQL Server. SQL allows users to query the database using English-like phrases in a variety of ways.
SQL is also distinct from other computer languages because it specifies what the user wants the machine to perform rather than how it should accomplish it. (In more technical terms, SQL is a declarative rather than procedural language.) There are no IF statements in SQL for testing conditions, and no GOTO, DO, or FOR statements for controlling program flow. SQL statements, on the other hand, indicate how a collection of data should be organized, as well as what data should be accessed or added to the database. The DBMS determines the sequence of actions to complete such tasks.
SQL queries are one of the most frequently asked interview questions. You can expect questions ranging from basic SQL queries to complex SQL queries:
- What is Query in SQL?
- Write an SQL query to report all the duplicate emails. You can return the result table in any order.
- Construct a SQL query to provide each player's first login date. You can return the result table in any order.
- Write an SQL query to report all customers who never order anything. You can return the result table in any order.
- Write an SQL query to report the movies with an odd-numbered ID and a description that is not "boring". Return the result table ordered by rating in descending order.
Construct a SQL query to display the names and balances of people who have a balance greater than $10,000. The balance of an account is equal to the sum of the amounts of all transactions involving that account. You can return the result table in any order.
- Write a SQL query that detects managers with at least 5 direct reports from the Employee table.
- Construct an SQL query for the following questions.
So, without any further ado, let us look at the most frequently asked SQL Query Interview Questions and Answers which are categorised into the following:
SQL Query Interview Questions for Freshers
Sql query interview questions for experienced, sql query mcq questions, 1. what is query in sql.
A query is a request for information or data from a database table or set of tables. For example, let us assume that we have a database that stores details about books written by various authors. Now, if we want to know how many books have been written by a particular author, then this question can be referred to as a query that we want to do to the database.
Use cases of SQL:
- SQL is an interactive question language. Users write SQL commands into interactive SQL software to extract information and display them on the screen, making it a useful and simple tool for ad hoc database queries.
- SQL is a database programming language. To access the information in a database, programmers incorporate SQL instructions into their utility packages. This method of database access is used by both user-written packages and database software packages
- SQL is a server/client language. SQL allows personal computer programs to interface with database servers that store shared data through a network. Many well-known enterprise-class apps use this client/server design.
- SQL is a distributed database language. SQL is used in distributed database control systems to help spread data across numerous linked computer structures. Every device's DBMS software program uses SQL to communicate with other systems, issuing requests for information access. Learn More
2. Let us consider the following schema:
Table: person, here, id is the primary key column for this table. email represents the email id of the person. for the sake of simplicity, we assume that the emails will not contain uppercase letters. write an sql query to report all the duplicate emails. you can return the result table in any order., input: person table:, explanation: [email protected] is repeated two times..
- Approach 1:
We can first have all the distinct email ids and their respective counts in our result set. For this, we can use the GROUP BY operator to group the tuples by their email id. We will use the COUNT operator to have the total number of a particular email id in the given table. The query for obtaining this resultant set can be written as:
Now, we query in the above resultant query set to find out all the tuples which have an email id count greater than 1. This can be achieved using the following query:
- Approach 2:
The HAVING clause, which is significantly simpler and more efficient, is a more popular technique to add a condition to a GROUP BY. So, we can first group the tuples by the email ids and then have a condition to check if their count is greater than 1, only then do we include it in our result set. So we may change the solution above to this one.
Approach 3:
We can use the concept of joins to solve this problem. We will self-join the Person table with the condition that their email ids should be the same and their ids should be different. Having done this, we just need to count the number of tuples in our resultant set with distinct email ids. For this, we use the DISTINCT operator. This can be achieved using the following query:
3. Let us consider the following schema:
Table: activity, this table's primary key is (playerid, eventdate). the activities of numerous game participants are depicted in this table. each row indicates a person that logged in and played a particular number of games (perhaps 0) before moving on to another device at a later date. construct a sql query to provide each player's first login date. you can return the result table in any order., input: activity table:.
Explanation:
The player with playerId 1 has two login event dates in the example above. However, because the first login event date is 2021-04-07, we display it. Similarly, the first login event date for the player with playerId 2 is 2021-06-25, and the first login event date for the player with playerId 3 is 2021-07-03.
We can first group the tuples by their player_id. Now, we want the most initial date when the player logged in to the game. For this, we can use the MIN operator and find the initial date on which the player logged in. The query can be written as follows:
We can partition the tuples by the player_id and order them by their event_id such that all the tuples having the same player_id are grouped together. We then number every tuple in each of the groups starting with the number 1. Now, we just have to display the event_date for the tuple having row number 1. For this, we use the ROW_NUMBER operator. The SQL query for it can be written as follows:
We follow a similar kind of approach as used in Approach 2. But instead of using the ROW_NUMBER operator, we can use the FIRST_VALUE operator to find the first event_date. The SQL query for it can be written as follows:
4. Given the following schema:
Table: customers, the primary key column for this table is id. each row in the table represents a customer's id and name., table: orders, the primary key column for this table is id. customerid is a foreign key of the id from the customers table. the id of an order and the id of the customer who placed it are listed in each row of this table. write an sql query to report all customers who never order anything. you can return the result table in any order., input: customers table:, orders table:.
Explanation: Here, the customers Sachin and Ram have placed an order having order id 1 and 2 respectively. Thus, the customers Rajat and Ankit have never placed an order. So, we print their names in the result set.
In this approach, we first try to find the customers who have ordered at least once. After having found this, we find the customers whose customer Id is not present in the previously obtained result set. This gives us the customers who have not placed a single order yet. The SQL query for it can be written as follows
In this approach, we use the concept of JOIN. We will LEFT JOIN the customer table with the order table based on the condition that id of the customer table must be equal to that of the customer id of the order table. Now, in our joined resultant table, we just need to find those customers whose order id is null. The SQL query for this can be written as follows:
Here, we first create aliases of the tables Customers and Orders with the name ‘c’ and ‘o’ respectively. Having done so, we join them with the condition that o.customerId = c.id. At last, we check for the customers whose o.id is null.
5. Given the following schema:
Table: cinema, the primary key for this table is id. each row includes information about a movie's name, genre, and rating. rating is a float with two decimal digits in the range [0, 10]. write an sql query to report the movies with an odd-numbered id and a description that is not "boring". return the result table ordered by rating in descending order., input: cinema table:.
Explanation:
There are three odd-numbered ID movies: 1, 3, and 5. We don't include the movie with ID = 3 in the answer because it's boring. We put the movie with id 5 at the top since it has the highest rating of 9.1.
This question has a bit of ambiguity on purpose. You should ask the interviewer whether we need to check for the description to exactly match “boring” or we need to check if the word “boring” is present in the description. We have provided solutions for both cases.
- Approach 1 (When the description should not be exactly “boring” but can include “boring” as a substring):
In this approach, we use the MOD operator to check whether the id of a movie is odd or not. Now, for all the odd-numbered id movies, we check if its description is not boring. At last, we sort the resultant data according to the descending order of the movie rating. The SQL query for this can be written as follows:
- Approach 2 (When the description should not even contain “boring” as a substring in our resultant answer):
In this approach, we use the LIKE operator to match the description having “boring” as a substring. We then use the NOT operator to eliminate all those results. For the odd-numbered id, we check it similarly as done in the previous approach. Finally, we order the result set according to the descending order of the movie rating. The SQL query for it can be written as follows:
- Software Dev
- Data Science
6. Consider the following schema:
Table: users, the account is the primary key for this table. each row of this table contains the account number of each user in the bank. there will be no two users having the same name in the table., table: transactions, trans_id is the primary key for this table. each row of this table contains all changes made to all accounts. the amount is positive if the user received money and negative if they transferred money. all accounts start with a balance of 0., input: users table:, transactions table:.
- Ram's balance is (8000 + 8000 - 3000) = 11000.
- Tim's balance is 4000.
- Shyam's balance is (7000 + 7000 - 4000) = 10000.
In this approach, we first create aliases of the given two tables' users and transactions. We can natural join the two tables and then group them by their account number. Next, we use the SUM operator to find the balance of each of the accounts after all the transactions have been processed. The SQL query for this can be written as follows:
7. Given the following schema:
Table: employee, all employees, including their managers, are present at the employee table. there is an id for each employee, as well as a column for the manager's id. write a sql query that detects managers with at least 5 direct reports from the employee table..
In this problem, we first find all the manager ids who have more than 5 employees under them. Next, we find all the employees having the manager id present in the previously obtained manager id set.
The SQL query for this can be written as follows:
8. Consider the following table schema:
Construct an sql query to retrieve duplicate records from the employee table., table: salary, now answer the following questions:.
1. Construct an SQL query that retrieves the fname in upper case from the Employee table and uses the ALIAS name as the EmployeeName in the result.
2. Construct an SQL query to find out how many people work in the "HR" department
3. Construct an SQL query to retrieve the first four characters of the ‘lname’ column from the Employee table.
4. Construct a new table with data and structure that are copied from the existing table ‘Employee’ by writing a query. The name of the new table should be ‘SampleTable’.
5. Construct an SQL query to find the names of employees whose first names start with "S".
6. Construct an SQL query to count the number of employees grouped by gender whose dateOfBirth is between 01/03/1975 and 31/12/1976.
7. Construct an SQL query to retrieve all employees who are also managers.
8. Construct an SQL query to retrieve the employee count broken down by department and ordered by department count in ascending manner.
9. Construct an SQL query to retrieve duplicate records from the Employee table.
1. Consider the following Schema:
Table: tree, here, id is the primary key column for this table. id represents the unique identity of a tree node and parent_id represents the unique identity of the parent of the current tree node. the id of a node and the id of its parent node in a tree are both listed in each row of this table. there is always a valid tree in the given structure., every node in the given tree can be categorized into one of the following types:, 1. "leaf": when the tree node is a leaf node, we label it as “leaf”, 2. "root": when the tree node is a root node, we label it as “root”, 3. "inner": when the tree node is an inner node, we label it as “inner”, write a sql query to find and return the type of each of the nodes in the given tree. you can return the result in any order. .

Input: Tree Table
- Because node 1’s parent node is null, and it has child nodes 2 and 3, Node 1 is the root node.
- Because node 2 and node 3 have parent node 1 and child nodes 5 and 4 respectively, Node 2 and node 3 are inner nodes.
- Because nodes 4 and 5 have parent nodes but no child nodes, nodes 4, and 5 are leaf nodes.
Approach 1:
In this approach, we subdivide our problem of categorizing the type of each of the nodes in the tree. We first find all the root nodes and add them to our resultant set with the type “root”. Then, we find all the leaf nodes and add them to our resultant set with the type “leaf”. Similarly, we find all the inner nodes and add them to our resultant set with the type “inner”. Now let us look at the query for finding each of the node types.
- For root nodes:
Here, we check if the parent_id of the node is null, then we assign the type of node as ‘Root’ and include it in our result set.
- For leaf nodes:
Here, we first find all the nodes that have a child node. Next, we check if the current node is present in the set of root nodes. If present, it cannot be a leaf node and we eliminate it from our answer set. We also check that the parent_id of the current node is not null. If both the conditions satisfy then we include it in our answer set.
- For inner nodes:
Here, we first find all the nodes that have a child node. Next, we check if the current node is present in the set of root nodes. If not present, it cannot be an inner node and we eliminate it from our answer set. We also check that the parent_id of the current node is not null. If both the conditions satisfy then we include it in our answer set.
At last, we combine all three resultant sets using the UNION operator. So, the final SQL query is as follows:
In this approach, we use the control statement CASE. This simplifies our query a lot from the previous approach. We first check if a node falls into the category of “Root”. If the node does not satisfy the conditions of a root node, it implies that the node will either be a “Leaf” node or an “Inner” node. Next, we check if the node falls into the category of “Inner” node. If it is not an “Inner” node, there is only one option left, which is the “Leaf” node.
The SQL query for this approach can be written as follows:
In this approach, we follow a similar logic as discussed in the previous approach. However, we will use the IF operator instead of the CASE operator. The SQL query for this approach can be written as follows:
2. Consider the following schema:
Table: seat, the table contains a list of students. every tuple in the table consists of a seat id along with the name of the student. you can assume that the given table is sorted according to the seat id and that the seat ids are in continuous increments. now, the class teacher wants to swap the seat id for alternate students in order to give them a last-minute surprise before the examination. you need to write a query that swaps alternate students' seat id and returns the result. if the number of students is odd, you can leave the seat id for the last student as it is. , for the same input, the output is:.
In this approach, first we count the total number of students. Having done so, we consider the case when the seat id is odd but is not equal to the total number of students. In this case, we simply increment the seat id by 1. Next, we consider the case when the seat id is odd but is equal to the total number of students. In this case, the seat id remains the same. At last, we consider the case when the seat id is even. In this case, we decrement the seat id by 1.
In this approach, we use the ROW_NUMBER operator. We increment the id for the odd-numbered ids by 1 and decrement the even-numbered ids by 1. We then sort the tuples, according to the id values. Next, we assign the row number as the id for the sorted tuples. The SQL query for this approach can be written as follows:
3. Given the following schema:
Id is the primary key column for this table. departmentid is a foreign key of the id from the department table. each row of this table indicates the id, name, and salary of an employee. it also contains the id of their department., table: department, id is the primary key column for this table. each row of this table indicates the id of a department and its name. the executives of an organization are interested in seeing who earns the most money in each department. a high earner in a department is someone who earns one of the department's top three unique salaries. , construct a sql query to identify the high-earning employees in each department. you can return the result table in any order., input: employee table:, department table:.
- Kim has the greatest unique income in the Marketing department - Ram and Saket have the second-highest unique salary.
- Will has the third-highest unique compensation.
In the HR department:
- Divya has the greatest unique income.
- Tim earns the second-highest salary.
- Because there are only two employees, there is no third-highest compensation.
In this approach, let us first assume that all the employees are from the same department. So let us first figure out how we can find the top 3 high-earner employees. This can be done by the following SQL query:
Here, we have created two aliases for the Employee table. For every tuple of the emp1 alias, we compare it with all the distinct salaries to find out how many salaries are less than it. If the number is less than 3, it falls into our answer set.
Next, we need to join the Employee table with the Department table in order to obtain the high-earner employees department-wise. For this, we run the following SQL command:
Here, we join the Employee table and the Department table based on the department ids in both tables. Also, while finding out the high-earner employees for a specific department, we compare the department ids of the employees as well to ensure that they belong to the same department.
In this approach, we use the concept of the DENSE_RANK function in SQL. We use the DENSE_RANK function and not the RANK function since we do not want the ranking number to be skipped. The SQL query using this approach can be written as follows:
Here, we first run a subquery where we partition the tuples by their department and rank them according to the decreasing order of the salaries of the employees. Next, we select those tuples from this set, whose rank is less than 4.
Table: Stadium
Date_visited is the primary key for this table. the visit date, the stadium visit id, and the total number of visitors are listed in each row of this table. no two rows will share the same visit date, and the dates get older as the id gets bigger. construct a sql query to display records that have three or more rows of consecutive ids and a total number of people higher than or equal to 100. return the result table in ascending order by visit date., input: stadium table:.
The four rows with ids 5, 6, 7, and 8 have consecutive ids and each of them has >= 100 people attended. Note that row 8 was included even though the date_visited was not the next day after row 7.
The rows with ids 2 and 3 are not included because we need at least three consecutive ids.
In this approach, we first create three aliases of the given table and cross-join all of them. We filter the tuples such that the number of people in each of the alias’ should be greater than or equal to 100.
The query for this would be
Now, we have to check for the condition of consecutive 3 tuples. For this, we compare the ids of the three aliases to check if they form a possible triplet with consecutive ids. We do this by the following query:
The above query may contain duplicate triplets. So we remove them by using the DISTINCT operator. The final query becomes as follows:
In this approach, we first filter out all the tuples where the number of people is greater than or equal to 100. Next, for every tuple, we check, if there exist 2 other tuples with ids such that the three ids when grouped together form a consecutive triplet. The SQL query for this approach can be written as follows:
Here, id is the id of the employee. company is the name of the company he/she is working in. salary is the salary of the employee Construct a SQL query to determine each company's median salary. If you can solve it without utilising any built-in SQL functions, you'll get bonus points.
In this approach, we have a subquery where we partition the tuples according to the company name and rank the tuples in the increasing order of salary and id. We also find the count of the total number of tuples in each company and then divide it by 2 in order to find the median tuple. After we have this result, we run an outer query to fetch the median salary and the employee id for each of the companies.
Additional Resources
- SQL Programming
- SQL Cheat Sheet
- SQL Commands
- 10 Best SQL Books
- SQL MCQ With Answers
- SQL Server Interview Questions and Answers
- DBMS Interview Questions and Answers
- SQL Joins Interview Questions and Answers
Which of the following are TCL commands?
Which of the following claims about SQL queries is TRUE?
P: Even if there is no GROUP BY clause in a SQL query, it can have a HAVING clause.
Q: If a SQL query has a GROUP BY clause, it can only have a HAVING clause.
R: The SELECT clause must include all attributes used in the GROUP BY clause.
S: The SELECT clause does not have to include all of the attributes used in the GROUP BY clause.
Following is a database table having the name Loan_Records.
What is the result of the SQL query below?
Consider the table employee(employeeId, name, department, salary) and the two queries Q1 , Q2 below. Assuming that department 5 has more than one employee, and we want to find the employees who get higher salaries than anyone in department 5, which one of the statements is TRUE for any arbitrary employee table?
Given the following statements:
P: A check assertion in SQL can always be used to replace a foreign key declaration.
Q: Assume that there is a table “Sample” with the attributes (p, q, r) where the primary key is (p, q). Given the table definition for the table “Sample”, the following table definition also holds true and valid.
Given the following schema:
employees(employeeId, firstName, lastName, hireDate, departmentId, salary)
departments(departmentId, departmentName, managerId, locationId)
For location ID 100, you are required to display the first names and hire dates of all recent hires in their respective departments. You run the following query for it:
Which of the following options is the correct outcome of the above query?
SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:
select * from R where a in (select S.a from S)
Consider the relation account (customer, balance), in which the customer is the primary key and no null values exist. Customers should be ranked in order of decreasing balance. The consumer with the highest balance is placed first. Ties are not broken, but ranks are skipped: if two customers have the same balance, they both get rank 1, and rank 2 is not issued.
Consider these statements about Query1 and Query2.
1. Query1 will produce the same row set as Query2 for some but not all databases.
2. Both Query1 and Query2 are correct implementations of the specification
3. Query1 is a correct implementation of the specification but Query2 is not
4. Neither Query1 nor Query2 is a correct implementation of the specification
5. Assigning rank with a pure relational query takes less time than scanning in decreasing balance order assigning ranks using ODBC.
Which of the following option is correct?
Consider the two relations: “enrolled(student, course)” and “paid(student, amount)”. In the relation enrolled(student, course), the primary key is (student, course) whereas in the relation “paid(student, amount)”, the primary key is a student. You can assume that there are no null values and no foreign keys or integrity constraints. Given the following four queries:
Which of the following statements is the most accurate?
The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
The employee information in a company is stored in the relation:
Employee (name, sex, salary, deptName)
Consider the following SQL query
It returns the names of the departments in which
- Privacy Policy

- Practice Questions
- Programming
- System Design
- Fast Track Courses
- Online Interviewbit Compilers
- Online C Compiler
- Online C++ Compiler
- Online Java Compiler
- Online Javascript Compiler
- Online Python Compiler
- Interview Preparation
- Java Interview Questions
- Sql Interview Questions
- Python Interview Questions
- Javascript Interview Questions
- Angular Interview Questions
- Networking Interview Questions
- Selenium Interview Questions
- Data Structure Interview Questions
- Data Science Interview Questions
- System Design Interview Questions
- Hr Interview Questions
- Html Interview Questions
- C Interview Questions
- Amazon Interview Questions
- Facebook Interview Questions
- Google Interview Questions
- Tcs Interview Questions
- Accenture Interview Questions
- Infosys Interview Questions
- Capgemini Interview Questions
- Wipro Interview Questions
- Cognizant Interview Questions
- Deloitte Interview Questions
- Zoho Interview Questions
- Hcl Interview Questions
- Highest Paying Jobs In India
- Exciting C Projects Ideas With Source Code
- Top Java 8 Features
- Angular Vs React
- 10 Best Data Structures And Algorithms Books
- Best Full Stack Developer Courses
- Best Data Science Courses
- Python Commands List
- Data Scientist Salary
- Maximum Subarray Sum Kadane’s Algorithm
- Python Cheat Sheet
- C++ Cheat Sheet
- Javascript Cheat Sheet
- Git Cheat Sheet
- Java Cheat Sheet
- Data Structure Mcq
- C Programming Mcq
- Javascript Mcq
1 Million +
IMAGES
VIDEO
COMMENTS
A. Use SELECT to retrieve rows and columns. The following example shows three code examples. This first code example returns all rows (no WHERE clause is specified) and all columns (using the *) from the Product table in the AdventureWorks2022 database. SQL. Copy.
Find TOP 10 SQL Server Queries with the largest number of rows affected in the Query Store. This could be useful to check if there are any queries that return large number of rows and probably later investigate if filters could be added to the query. We had one old application that initially used a small table.
This is an exercise for me to get familiar reading, writing queries on SQL Server for my job. Could you please help me out defining query based on the schema and simply explain the logic? Thanks a lot! SQL Server is my DBMS and here are the question. Display ID, First Name, Last Name, and Hits to display all players with more than 2000 career hits.
In its most simple form, the SELECT clause has the following SQL syntax for a Microsoft SQL Server database: SELECT *. FROM <TableName>; This SQL query will select all columns and all rows from the table. For example: SELECT *. FROM [Person].[Person];
Arguments. msg_str Is a character string or Unicode string constant. For more information, see Constants (Transact-SQL). @ local_variable Is a variable of any valid character data type. @local_variable must be char, nchar, varchar, or nvarchar, or it must be able to be implicitly converted to those data types. string_expr
Note: This article was written based on SQL Server 2016 CTP 2.2. Some screens and behaviors may change in the final release. Next Steps. Come back soon to read the next tip with examples of the Query Store usage. Download the latest evaluation version of SQL Server 2016. Read SQL Server 2016 Books Online documentation.
SQL Server 2016: Query Designer. Use the Query Designer to build complex queries across multiple tables without writing any code. SQL Server Management Studio includes the Query Designer to assist in building queries. It is a visual tool that allows you to select the tables and columns you want in your query, as well as any filtering criteria.
How to Query Date and Time in SQL Server using Datetime and Timestamp. Get the date and time right now (where SQL Server is running): select current_timestamp; -- date and time, standard ANSI SQL so compatible across DBs select getdate(); -- date and time, specific to SQL Server select getutcdate(); -- returns UTC timestamp select sysdatetime ...
If you want to save the results in a txt file, you can do this in SSMS. Go to Tools>Options: Select the option Result to file: Create a query and execute the query. An option to specify the name ...
You can use Microsoft Query to retrieve data from external sources. By using Microsoft Query to retrieve data from your corporate databases and files, you don't have to retype the data that you want to analyze in Excel. You can also refresh your Excel reports and summaries automatically from the original source database whenever the database is ...
Applies to: SQL Server Azure SQL Database Azure SQL Managed Instance. Query hints specify that the indicated hints are used in the scope of a query. They affect all operators in the statement. If UNION is involved in the main query, only the last query involving a UNION operation can have the OPTION clause.
Yes, it seems we might need to do combination of UNPIVOT and PIVOT. Try below, It may provide you the exact result as what you expect. Please change your design first. Gender varchar(10) to Gender varchar(50) Try below, ;WITH cte AS(. SELECT *. FROM [User] UNPIVOT([Value] FOR Cols IN ([Name], [Gender])) Unp.
Question: How to Attempt?Write an MSSQL 2016 query to display:The names of all viewers who watch more than one programme along withthe programme names.Your output should contain 2 columns in the below-mentioned order.You can view the database schema by clicking the View Schema tab at thebottom of the query window on the right-hand side of the screen.
1. You need to show the key parts of the schema of your table. Column names don't usually contain spaces; when they do, they must be enclosed in delimiters. The format for a DATE literal is formally DATE '2010-09-10', but different DBMS have other notations that also work. You should specify which DBMS you're using, too.
Write an MSSQL 2016 query to display: The first name (use alias Fname) and the last name (use alias Lname) of all customers that have city 'Texas' in their address. Your output should contain 2 columns in the below-mentioned order. Fname Lname You can view the database schema by clicking the View Schema tab at the bottom of the query window on ...
I want to write a stored procedure for login page: 1. If a user is able to login then it needs to check user table if the user is present it return success and retrieve the data which user has access. 2.If the user is unable to login then it sends failure and writes the username and expired date in audit table.
SQL stands for Structured Query Language. Initially, it was named Structured English Query Language (SEQUEL). It is used in relational database management systems to store and manage data (RDMS). It is a relational database system with standard language. A user can create, read, update, and delete relational databases and tables with it.
Option 1: You asked if you can get the result of query like PRINT which the answer is yes. You have three built-in option to return the result of queries: Check this image and select the option "As Text": Option 2: You can develop extention to SSMS and change change the tab automatically one the query returns result.
This SQL query selects data from the employees table. It retrieves two columns: first_name and last_name. The AS keyword is used to alias the column names as "First Name" and "Last Name", respectively. The aliasing is done for better readability or when column names need to be changed in the output, but not necessarily in the underlying data.
You can look for categories linked to products where the parent category is the fruit category by using multiple joins. Here cc refers to the child category and cp refers to the parent category. We retrieve all products having a child category equal to the products category, and having a parent category to that child category equal to FRUITS:. select * from products p inner join categories cc ...
Display month of sale and number of sales done in that month sorted in descending order of sales. I have used the extract function to extract month from date but it gives month number not the full name of the month
1. Depending on the details you provided, your query should be like below : select count(pro.ProductID) from Product as pro. join SalesOrderDetail as sod. on pro.ProductID = sod.ProductID. where pro.ListPrice > 1000. answered Dec 19, 2019 at 14:22. Amira Bedhiafi.