Case–Control Study
- First Online: 13 December 2023

Cite this chapter

- Noraini Abdul Ghafar 2
431 Accesses
A case–control study is an observational study designed to determine if a risk factor is associated with an outcome of interest (disease or condition). This study design permits the researcher to determine if an exposure is associated with an outcome. First, a group with the outcome of interest (“cases”) is identified. Next, a group similar to cases (“controls”) is selected from the “study base” that yielded the cases but without the outcome of interest. Matching of cases and controls on certain characteristics ensures similarity and increases study efficiency. Historical risk factors in both groups are evaluated to determine whether some RFs occur more frequently in cases than controls. Case–control studies may establish an association between a risk factor and outcome but cannot demonstrate causation because of its retrospective nature. Compared to other study designs, case–control studies are inexpensive, quick, and allow the evaluation of several risk factors. Case–control study designs are useful for studying rare diseases, diseases with long latent periods, and for outbreak investigations. Limitations include selection bias and recall bias. Among the strategies to overcome selection bias include an appropriate sampling method, matching, using a minimum of two control groups, and drawing both cases and controls from the same population. Meanwhile, recall bias could be minimized by blinding.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Lewallen S, Courtright P. Epidemiology in practice: case-control studies. Community Eye Health. 1998;11(28):57–8. PMID: 17492047; PMCID: PMC1706071
CAS PubMed PubMed Central Google Scholar
dos Santos Silva I. 1999. Chapter 9: case control studies in cancer epidemiology: principles and methods ISBN-13 978–92–832-0405-3.
Google Scholar
Breslow NE. Statistics in epidemiology: the case-control study. J Am Stat Assoc. 1996;91(433):14–28. https://doi.org/10.1080/01621459.1996.10476660 . PMID: 12155399
Article CAS PubMed Google Scholar
Setia MS. Methodology series module 2: case control studies. Indian J Dermatol. 2016;61:146–51.
Article PubMed PubMed Central Google Scholar
Mitra AK. Investigating the types of epidemiologic studies. In: Epidemiology for dummies. 1st ed. Hoboken, New Jersey, United States: Wiley; 2023.
Critchley J. Epidemiology for the uninitiated, 5th ed. J Epidemiol Community Health. 2004;58
Wacholder S, McLaughlin JK, Silverman DT, Mandel JS. Selection of controls in case-control studies. I Principles Am J Epidemiol. 1992;135(9):1019–28. https://doi.org/10.1093/oxfordjournals.aje.a116396 . PMID: 1595688
Hennessy S, Bilker WB, Berlin JA, Strom BL. Factors influencing the optimal control-to-case ratio in matched case-control studies. Am J Epidemiol. 1999;149(2):195–7. https://doi.org/10.1093/oxfordjournals.aje.a009786 . Erratum in: Am J Epidemiol 1999 Mar 1;149(5):489. PMID: 9921965
Sedgwick P. Case-control studies: advantages and disadvantages. BMJ. 2014;3(348):f7707. https://doi.org/10.1136/bmj.f7707 . PMID: 31419845
Article Google Scholar
Sedgwick P. Nested case-control studies: advantages and disadvantages. BMJ (online). 2014;348:g1532. https://doi.org/10.1136/bmj.g1532 .
Sedgwick P. Nested case-control studies. BMJ. 2010;(340):c2582. https://doi.org/10.1136/bmj.c2582 . PMID: 20484347
Ernster. Nested case control studies. Prev Med. 1994;23:587–90.
Langholz B, Clayton D. Sampling strategies in nested case-control studies. Environ Health Perspect. 1994;102 Suppl 8(Suppl 8):47–51. https://doi.org/10.1289/ehp.94102s847 . PMID: 7851330; PMCID: PMC1566552
Tan MM, Ho WK, Yoon SY, Mariapun S, Hasan SN, Lee DS, Hassan T, Lee SY, Phuah SY, Sivanandan K, Ng PP, Rajaram N, Jaganathan M, Jamaris S, Islam T, Rahmat K, Fadzli F, Vijayananthan A, Rajadurai P, See MH, Thong MK, Mohd Taib NA, Yip CH, Teo SH. A case-control study of breast cancer risk factors in 7,663 women in Malaysia. PLoS One. 2018;13(9):e0203469. https://doi.org/10.1371/journal.pone.0203469 . PMID: 30216346; PMCID: PMC6138391
Article CAS PubMed PubMed Central Google Scholar
Ganesh B, Sushama S, Monika S, Suvarna P. A case-control study of risk factors for lung cancer in Mumbai. India Asian Pac J Cancer Prev. 2011;12(2):357–62. PMID: 21545194
CAS PubMed Google Scholar
Xi C, Luo M, Wang T, Wang Y, Wang S, Guo L, Lu C. Association between maternal lifestyle factors and low birth weight in preterm and term births: a case-control study. Reprod Health. 2020;17(1):93. https://doi.org/10.1186/s12978-020-00932-9 .
Shimeles E, Enquselassie F, Aseffa A, Tilahun M, Mekonen A, Wondimagegn G, Hailu T. Risk factors for tuberculosis: a case-control study in Addis Ababa, Ethiopia. PLoS One. 2019;14(4):e0214235. https://doi.org/10.1371/journal.pone.0214235 . PMID: 30939169; PMCID: PMC6445425
Kalra A. The odds ratio: principles and applications. J Pract Cardiovasc Sci. 2016;2:49–51.
Szumilas M. Explaining odds ratios. J Can Acad Child Adolesc Psychiatry. 2010;19(3):227–9. Erratum in: J Can Acad Child Adolesc Psychiatry. 2015 Winter;24(1):58. PMID: 20842279; PMCID: PMC2938757
PubMed PubMed Central Google Scholar
Mann CJ. Observational research methods. Research design II: cohort, cross sectional, and case-control studies. Emerg Med J. 2003;20:54–60.
Song JW, Chung KC. Observational studies: cohort and case-control studies. Plast Reconstr Surg. 2010;126(6):2234–42. https://doi.org/10.1097/PRS.0b013e3181f44abc . PMID: 20697313; PMCID: PMC2998589
Download references
Author information
Authors and affiliations.
School of Health Sciences, Universiti Sains Malaysia (Health Campus), Kubang Kerian, Kelantan, Malaysia
Noraini Abdul Ghafar
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Noraini Abdul Ghafar .
Editor information
Editors and affiliations.
Department of Epidemiology and Biostatistics, Jackson State University, Jackson, MS, USA
Amal K. Mitra
Rights and permissions
Reprints and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Ghafar, N.A. (2024). Case–Control Study. In: Mitra, A.K. (eds) Statistical Approaches for Epidemiology. Springer, Cham. https://doi.org/10.1007/978-3-031-41784-9_3
Download citation
DOI : https://doi.org/10.1007/978-3-031-41784-9_3
Published : 13 December 2023
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-41783-2
Online ISBN : 978-3-031-41784-9
eBook Packages : Medicine Medicine (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Study Design 101: Case Control Study
- Case Report
- Case Control Study
- Cohort Study
- Randomized Controlled Trial
- Practice Guideline
- Systematic Review
- Meta-Analysis
- Helpful Formulas
- Finding Specific Study Types
A study that compares patients who have a disease or outcome of interest (cases) with patients who do not have the disease or outcome (controls), and looks back retrospectively to compare how frequently the exposure to a risk factor is present in each group to determine the relationship between the risk factor and the disease.
Case control studies are observational because no intervention is attempted and no attempt is made to alter the course of the disease. The goal is to retrospectively determine the exposure to the risk factor of interest from each of the two groups of individuals: cases and controls. These studies are designed to estimate odds.
Case control studies are also known as "retrospective studies" and "case-referent studies."
- Good for studying rare conditions or diseases
- Less time needed to conduct the study because the condition or disease has already occurred
- Lets you simultaneously look at multiple risk factors
- Useful as initial studies to establish an association
- Can answer questions that could not be answered through other study designs
Disadvantages
- Retrospective studies have more problems with data quality because they rely on memory and people with a condition will be more motivated to recall risk factors (also called recall bias).
- Not good for evaluating diagnostic tests because it's already clear that the cases have the condition and the controls do not
- It can be difficult to find a suitable control group
Design pitfalls to look out for
Care should be taken to avoid confounding, which arises when an exposure and an outcome are both strongly associated with a third variable. Controls should be subjects who might have been cases in the study but are selected independent of the exposure. Cases and controls should also not be "over-matched."
Is the control group appropriate for the population? Does the study use matching or pairing appropriately to avoid the effects of a confounding variable? Does it use appropriate inclusion and exclusion criteria?
Fictitious Example
There is a suspicion that zinc oxide, the white non-absorbent sunscreen traditionally worn by lifeguards is more effective at preventing sunburns that lead to skin cancer than absorbent sunscreen lotions. A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure. The study involved comparing a group of former lifeguards that had developed cancer on their cheeks and noses (cases) to a group of lifeguards without this type of cancer (controls) and assess their prior exposure to zinc oxide or absorbent sunscreen lotions.
This study would be retrospective in that the former lifeguards would be asked to recall which type of sunscreen they used on their face and approximately how often. This could be either a matched or unmatched study, but efforts would need to be made to ensure that the former lifeguards are of the same average age, and lifeguarded for a similar number of seasons and amount of time per season.
Real-life Examples
Boubekri, M., Cheung, I., Reid, K., Wang, C., & Zee, P. (2014). Impact of windows and daylight exposure on overall health and sleep quality of office workers: a case-control pilot study. Journal of Clinical Sleep Medicine : JCSM : Official Publication of the American Academy of Sleep Medicine, 10 (6), 603-611. https://doi.org/10.5664/jcsm.3780
This pilot study explored the impact of exposure to daylight on the health of office workers (measuring well-being and sleep quality subjectively, and light exposure, activity level and sleep-wake patterns via actigraphy). Individuals with windows in their workplaces had more light exposure, longer sleep duration, and more physical activity. They also reported a better scores in the areas of vitality and role limitations due to physical problems, better sleep quality and less sleep disturbances.
Togha, M., Razeghi Jahromi, S., Ghorbani, Z., Martami, F., & Seifishahpar, M. (2018). Serum Vitamin D Status in a Group of Migraine Patients Compared With Healthy Controls: A Case-Control Study. Headache, 58 (10), 1530-1540. https://doi.org/10.1111/head.13423
This case-control study compared serum vitamin D levels in individuals who experience migraine headaches with their matched controls. Studied over a period of thirty days, individuals with higher levels of serum Vitamin D was associated with lower odds of migraine headache.
Related Formulas
- Odds ratio in an unmatched study
- Odds ratio in a matched study
Related Terms
A patient with the disease or outcome of interest.
Confounding
When an exposure and an outcome are both strongly associated with a third variable.
A patient who does not have the disease or outcome.
Matched Design
Each case is matched individually with a control according to certain characteristics such as age and gender. It is important to remember that the concordant pairs (pairs in which the case and control are either both exposed or both not exposed) tell us nothing about the risk of exposure separately for cases or controls.
Observed Assignment
The method of assignment of individuals to study and control groups in observational studies when the investigator does not intervene to perform the assignment.
Unmatched Design
The controls are a sample from a suitable non-affected population.
Now test yourself!
1. Case Control Studies are prospective in that they follow the cases and controls over time and observe what occurs.
a) True b) False
2. Which of the following is an advantage of Case Control Studies?
a) They can simultaneously look at multiple risk factors. b) They are useful to initially establish an association between a risk factor and a disease or outcome. c) They take less time to complete because the condition or disease has already occurred. d) b and c only e) a, b, and c
Evidence Pyramid - Navigation
- Meta- Analysis
- Case Reports
- << Previous: Case Report
- Next: Cohort Study >>

- Last Updated: Sep 25, 2023 10:59 AM
- URL: https://guides.himmelfarb.gwu.edu/studydesign101

- Himmelfarb Intranet
- Privacy Notice
- Terms of Use
- GW is committed to digital accessibility. If you experience a barrier that affects your ability to access content on this page, let us know via the Accessibility Feedback Form .
- Himmelfarb Health Sciences Library
- 2300 Eye St., NW, Washington, DC 20037
- Phone: (202) 994-2850
- [email protected]
- https://himmelfarb.gwu.edu
- En español – ExME
- Em português – EME
Case-control and Cohort studies: A brief overview
Posted on 6th December 2017 by Saul Crandon

Introduction
Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence . These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as randomised controlled trials, they can provide strong evidence if designed appropriately.
Case-control studies
Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups. See Figure 1 for a pictorial representation of a case-control study design. This can suggest associations between the risk factor and development of the disease in question, although no definitive causality can be drawn. The main outcome measure in case-control studies is odds ratio (OR) .
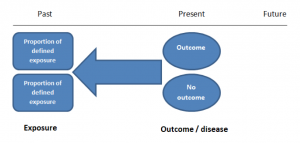
Figure 1. Case-control study design.
Cases should be selected based on objective inclusion and exclusion criteria from a reliable source such as a disease registry. An inherent issue with selecting cases is that a certain proportion of those with the disease would not have a formal diagnosis, may not present for medical care, may be misdiagnosed or may have died before getting a diagnosis. Regardless of how the cases are selected, they should be representative of the broader disease population that you are investigating to ensure generalisability.
Case-control studies should include two groups that are identical EXCEPT for their outcome / disease status.
As such, controls should also be selected carefully. It is possible to match controls to the cases selected on the basis of various factors (e.g. age, sex) to ensure these do not confound the study results. It may even increase statistical power and study precision by choosing up to three or four controls per case (2).
Case-controls can provide fast results and they are cheaper to perform than most other studies. The fact that the analysis is retrospective, allows rare diseases or diseases with long latency periods to be investigated. Furthermore, you can assess multiple exposures to get a better understanding of possible risk factors for the defined outcome / disease.
Nevertheless, as case-controls are retrospective, they are more prone to bias. One of the main examples is recall bias. Often case-control studies require the participants to self-report their exposure to a certain factor. Recall bias is the systematic difference in how the two groups may recall past events e.g. in a study investigating stillbirth, a mother who experienced this may recall the possible contributing factors a lot more vividly than a mother who had a healthy birth.
A summary of the pros and cons of case-control studies are provided in Table 1.
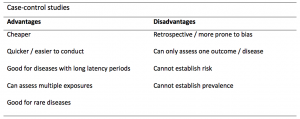
Table 1. Advantages and disadvantages of case-control studies.
Cohort studies
Cohort studies can be retrospective or prospective. Retrospective cohort studies are NOT the same as case-control studies.
In retrospective cohort studies, the exposure and outcomes have already happened. They are usually conducted on data that already exists (from prospective studies) and the exposures are defined before looking at the existing outcome data to see whether exposure to a risk factor is associated with a statistically significant difference in the outcome development rate.
Prospective cohort studies are more common. People are recruited into cohort studies regardless of their exposure or outcome status. This is one of their important strengths. People are often recruited because of their geographical area or occupation, for example, and researchers can then measure and analyse a range of exposures and outcomes.
The study then follows these participants for a defined period to assess the proportion that develop the outcome/disease of interest. See Figure 2 for a pictorial representation of a cohort study design. Therefore, cohort studies are good for assessing prognosis, risk factors and harm. The outcome measure in cohort studies is usually a risk ratio / relative risk (RR).
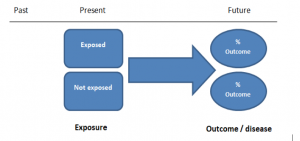
Figure 2. Cohort study design.
Cohort studies should include two groups that are identical EXCEPT for their exposure status.
As a result, both exposed and unexposed groups should be recruited from the same source population. Another important consideration is attrition. If a significant number of participants are not followed up (lost, death, dropped out) then this may impact the validity of the study. Not only does it decrease the study’s power, but there may be attrition bias – a significant difference between the groups of those that did not complete the study.
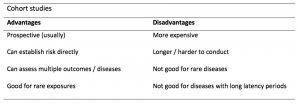
Cohort studies can assess a range of outcomes allowing an exposure to be rigorously assessed for its impact in developing disease. Additionally, they are good for rare exposures, e.g. contact with a chemical radiation blast.
Whilst cohort studies are useful, they can be expensive and time-consuming, especially if a long follow-up period is chosen or the disease itself is rare or has a long latency.
A summary of the pros and cons of cohort studies are provided in Table 2.
The Strengthening of Reporting of Observational Studies in Epidemiology Statement (STROBE)
STROBE provides a checklist of important steps for conducting these types of studies, as well as acting as best-practice reporting guidelines (3). Both case-control and cohort studies are observational, with varying advantages and disadvantages. However, the most important factor to the quality of evidence these studies provide, is their methodological quality.
- Song, J. and Chung, K. Observational Studies: Cohort and Case-Control Studies . Plastic and Reconstructive Surgery.  2010 Dec;126(6):2234-2242.
- Ury HK. Efficiency of case-control studies with multiple controls per case: Continuous or dichotomous data . Biometrics . 1975 Sep;31(3):643–649.
- von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP; STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies.  Lancet 2007 Oct;370(9596):1453-14577. PMID: 18064739.

Saul Crandon
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on Case-control and Cohort studies: A brief overview

Very well presented, excellent clarifications. Has put me right back into class, literally!

Very clear and informative! Thank you.

very informative article.

Thank you for the easy to understand blog in cohort studies. I want to follow a group of people with and without a disease to see what health outcomes occurs to them in future such as hospitalisations, diagnoses, procedures etc, as I have many health outcomes to consider, my questions is how to make sure these outcomes has not occurred before the “exposure disease”. As, in cohort studies we are looking at incidence (new) cases, so if an outcome have occurred before the exposure, I can leave them out of the analysis. But because I am not looking at a single outcome which can be checked easily and if happened before exposure can be left out. I have EHR data, so all the exposure and outcome have occurred. my aim is to check the rates of different health outcomes between the exposed)dementia) and unexposed(non-dementia) individuals.

Very helpful information

Thanks for making this subject student friendly and easier to understand. A great help.

Thanks a lot. It really helped me to understand the topic. I am taking epidemiology class this winter, and your paper really saved me.
Happy new year.

Wow its amazing n simple way of briefing ,which i was enjoyed to learn this.its very easy n quick to pick ideas .. Thanks n stay connected

Saul you absolute melt! Really good work man

am a student of public health. This information is simple and well presented to the point. Thank you so much.

very helpful information provided here

really thanks for wonderful information because i doing my bachelor degree research by survival model

Quite informative thank you so much for the info please continue posting. An mph student with Africa university Zimbabwe.

Thank you this was so helpful amazing

Apreciated the information provided above.

So clear and perfect. The language is simple and superb.I am recommending this to all budding epidemiology students. Thanks a lot.

Great to hear, thank you AJ!

I have recently completed an investigational study where evidence of phlebitis was determined in a control cohort by data mining from electronic medical records. We then introduced an intervention in an attempt to reduce incidence of phlebitis in a second cohort. Again, results were determined by data mining. This was an expedited study, so there subjects were enrolled in a specific cohort based on date(s) of the drug infused. How do I define this study? Thanks so much.

thanks for the information and knowledge about observational studies. am a masters student in public health/epidemilogy of the faculty of medicines and pharmaceutical sciences , University of Dschang. this information is very explicit and straight to the point

Very much helpful
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Expertise-based Randomized Controlled Trials
This blog summarizes the concepts of Expertise-based randomized controlled trials with a focus on the advantages and challenges associated with this type of study.

An introduction to different types of study design
Conducting successful research requires choosing the appropriate study design. This article describes the most common types of designs conducted by researchers.
Case-Control Studies

Introduction
Cohort studies have an intuitive logic to them, but they can be very problematic when one is investigating outcomes that only occur in a small fraction of exposed and unexposed individuals. They can also be problematic when it is expensive or very difficult to obtain exposure information from a cohort. In these situations a case-control design offers an alternative that is much more efficient. The goal of a case-control study is the same as that of cohort studies, i.e., to estimate the magnitude of association between an exposure and an outcome. However, case-control studies employ a different sampling strategy that gives them greater efficiency.
Learning Objectives
After completing this module, the student will be able to:
- Define and explain the distinguishing features of a case-control study
- Describe and identify the types of epidemiologic questions that can be addressed by case-control studies
- Define what is meant by the term "source population"
- Describe the purpose of controls in a case-control study
- Describe differences between hospital-based and population-based case-control studies
- Describe the principles of valid control selection
- Explain the importance of using specific diagnostic criteria and explicit case definitions in case-control studies
- Estimate and interpret the odds ratio from a case-control study
- Identify the potential strengths and limitations of case-control studies
Overview of Case-Control Design
In the module entitled Overview of Analytic Studies it was noted that Rothman describes the case-control strategy as follows:
"Case-control studies are best understood by considering as the starting point a source population , which represents a hypothetical study population in which a cohort study might have been conducted. The source population is the population that gives rise to the cases included in the study. If a cohort study were undertaken, we would define the exposed and unexposed cohorts (or several cohorts) and from these populations obtain denominators for the incidence rates or risks that would be calculated for each cohort. We would then identify the number of cases occurring in each cohort and calculate the risk or incidence rate for each. In a case-control study the same cases are identified and classified as to whether they belong to the exposed or unexposed cohort. Instead of obtaining the denominators for the rates or risks, however, a control group is sampled from the entire source population that gives rise to the cases. Individuals in the control group are then classified into exposed and unexposed categories. The purpose of the control group is to determine the relative size of the exposed and unexposed components of the source population. Because the control group is used to estimate the distribution of exposure in the source population, the cardinal requirement of control selection is that the controls be sampled independently of exposure status."
To illustrate this consider the following hypothetical scenario in which the source population is the state of Massachusetts. Diseased individuals are red, and non-diseased individuals are blue. Exposed individuals are indicated by a whitish midsection. Note the following aspects of the depicted scenario:
- The disease is rare.
- There is a fairly large number of exposed individuals in the state, but most of these are not diseased.
If we somehow had exposure and outcome information on all of the subjects in the source population and looked at the association using a cohort design, we might find the data summarized in the contingency table below.
In this hypothetical example, we have data on all 6,000,000 people in the source population, and we could compute the probability of disease (i.e., the risk or incidence) in both the exposed group and the non-exposed group, because we have the denominators for both the exposed and non-exposed groups.
The table above summarizes all of the necessary information regarding exposure and outcome status for the population and enables us to compute a risk ratio as a measure of the strength of the association. Intuitively, we compute the probability of disease (the risk) in each exposure group and then compute the risk ratio as follows:
The problem , of course, is that we usually don't have the resources to get the data on all subjects in the population. If we took a random sample of even 5-10% of the population, we would have few diseased people in our sample, certainly not enough to produce a reasonably precise measure of association. Moreover, we would expend an inordinate amount of effort and money collecting exposure and outcome data on a large number of people who would not develop the outcome.
We need a method that allows us to retain all the people in the numerator of disease frequency (diseased people or "cases") but allows us to collect information from only a small proportion of the people that make up the denominator (population, or "controls"), most of whom do not have the disease of interest. The case-control design allows us to accomplish this. We identify and collect exposure information on all the cases, but identify and collect exposure information on only a sample of the population. Once we have the exposure information, we can assign subjects to the numerator and denominator of the exposed and unexposed groups. This is what Rothman means when he says,
"The purpose of the control group is to determine the relative size of the exposed and unexposed components of the source population."
In the above example, we would have identified all 1,300 cases, determined their exposure status, and ended up categorizing 700 as exposed and 600 as unexposed. We might have ransomly sampled 6,000 members of the population (instead of 6 million) in order to determine the exposure distribution in the total population. If our sampling method was random, we would expect that about 1,000 would be exposed and 5,000 unexposed (the same ratio as in the overall population). We calculate a similar measure as the risk ratio above, but substituting in the denominator a sample of the population ("controls") instead of the whole population:
Note that when we take a sample of the population, we no longer have a measure of disease frequency, because the denominator no longer represents the population. Therefore, we can no longer compute the probability or rate of disease incidence in each exposure group. We also can't calculate a risk or rate difference measure for the same reason. However, as we have seen, we can compute the relative probability of disease in the exposed vs. unexposed group. The term generally used for this measure is an odds ratio , described in more detail later in the module.
Consequently, when the outcome is uncommon, as in this case, the risk ratio can be estimated much more efficiently by using a case-control design. One would focus first on finding an adequate number of cases in order to determine the ratio of exposed to unexposed cases. Then, one only needs to take a sample of the population in order to estimate the relative size of the exposed and unexposed components of the source population. Note that if one can identify all of the cases that were reported to a registry or other database within a defined period of time, then it is possible to compute an estimate of the incidence of disease if the size of the population is known from census data. While this is conceptually possible, it is rarely done, and we will not discuss it further in this course.

A Nested Case-Control Study
Suppose a prospective cohort study were conducted among almost 90,000 women for the purpose of studying the determinants of cancer and cardiovascular disease. After enrollment, the women provide baseline information on a host of exposures, and they also provide baseline blood and urine samples that are frozen for possible future use. The women are then followed, and, after about eight years, the investigators want to test the hypothesis that past exposure to pesticides such as DDT is a risk factor for breast cancer. Eight years have passed since the beginning of the study, and 1.439 women in the cohort have developed breast cancer. Since they froze blood samples at baseline, they have the option of analyzing all of the blood samples in order to ascertain exposure to DDT at the beginning of the study before any cancers occurred. The problem is that there are almost 90,000 women and it would cost $20 to analyze each of the blood samples. If the investigators could have analyzed all 90,000 samples this is what they would have found the results in the table below.
Table of Breast Cancer Occurrence Among Women With or Without DDT Exposure
If they had been able to afford analyzing all of the baseline blood specimens in order to categorize the women as having had DDT exposure or not, they would have found a risk ratio = 1.87 (95% confidence interval: 1.66-2.10). The problem is that this would have cost almost $1.8 million, and the investigators did not have the funding to do this.
While 1,439 breast cancers is a disturbing number, it is only 1.6% of the entire cohort, so the outcome is relatively rare, and it is costing a lot of money to analyze the blood specimens obtained from all of the non-diseased women. There is, however, another more efficient alternative, i.e., to use a case-control sampling strategy. One could analyze all of the blood samples from women who had developed breast cancer, but only a sample of the whole cohort in order to estimate the exposure distribution in the population that produced the cases.
If one were to analyze the blood samples of 2,878 of the non-diseased women (twice as many as the number of cases), one would obtain results that would look something like those in the next table.
Odds of Exposure: 360/1079 in the cases versus 432/2,446 in the non-diseased controls.
Totals Samples analyzed = 1,438+2,878 = 4,316
Total Cost = 4,316 x $20 = $86,320
With this approach a similar estimate of risk was obtained after analyzing blood samples from only a small sample of the entire population at a fraction of the cost with hardly any loss in precision. In essence, a case-control strategy was used, but it was conducted within the context of a prospective cohort study. This is referred to as a case-control study "nested" within a cohort study.
Rothman states that one should look upon all case-control studies as being "nested" within a cohort. In other words the cohort represents the source population that gave rise to the cases. With a case-control sampling strategy one simply takes a sample of the population in order to obtain an estimate of the exposure distribution within the population that gave rise to the cases. Obviously, this is a much more efficient design.
It is important to note that, unlike cohort studies, case-control studies do not follow subjects through time. Cases are enrolled at the time they develop disease and controls are enrolled at the same time. The exposure status of each is determined, but they are not followed into the future for further development of disease.
As with cohort studies, case-control studies can be prospective or retrospective. At the start of the study, all cases might have already occurred and then this would be a retrospective case-control study. Alternatively, none of the cases might have already occurred, and new cases will be enrolled prospectively. Epidemiologists generally prefer the prospective approach because it has fewer biases, but it is more expensive and sometimes not possible. When conducted prospectively, or when nested in a prospective cohort study, it is straightforward to select controls from the population at risk. However, in retrospective case-control studies, it can be difficult to select from the population at risk, and controls are then selected from those in the population who didn't develop disease. Using only the non-diseased to select controls as opposed to the whole population means the denominator is not really a measure of disease frequency, but when the disease is rare , the odds ratio using the non-diseased will be very similar to the estimate obtained when the entire population is used to sample for controls. This phenomenon is known as the r are-disease assumption . When case-control studies were first developed, most were conducted retrospectively, and it is sometimes assumed that the rare-disease assumption applies to all case-control studies. However, it actually only applies to those case-control studies in which controls are sampled only from the non-diseased rather than the whole population.
The difference between sampling from the whole population and only the non-diseased is that the whole population contains people both with and without the disease of interest. This means that a sampling strategy that uses the whole population as its source must allow for the fact that people who develop the disease of interest can be selected as controls. Students often have a difficult time with this concept. It is helpful to remember that it seems natural that the population denominator includes people who develop the disease in a cohort study. If a case-control study is a more efficient way to obtain the information from a cohort study, then perhaps it is not so strange that the denominator in a case-control study also can include people who develop the disease. This topic is covered in more detail in EP813 Intermediate Epidemiology.
Retrospective and Prospective Case-Control Studies
Students usually think of case-control studies as being only retrospective, since the investigators enroll subjects who have developed the outcome of interest. However, case-control studies, like cohort studies, can be either retrospective or prospective. In a prospective case-control study, the investigator still enrolls based on outcome status, but the investigator must wait to the cases to occur.
When is a Case-Control Study Desirable?
Given the greater efficiency of case-control studies, they are particularly advantageous in the following situations:
- When the disease or outcome being studied is rare.
- When the disease or outcome has a long induction and latent period (i.e., a long time between exposure and the eventual causal manifestation of disease).
- When exposure data is difficult or expensive to obtain.
- When the study population is dynamic.
- When little is known about the risk factors for the disease, case-control studies provide a way of testing associations with multiple potential risk factors. (This isn't really a unique advantage to case-control studies, however, since cohort studies can also assess multiple exposures.)
Another advantage of their greater efficiency, of course, is that they are less time-consuming and much less costly than prospective cohort studies.
The DES Case-Control Study
A classic example of the efficiency of the case-control approach is the study (Herbst et al.: N. Engl. J. Med. Herbst et al. (1971;284:878-81) that linked in-utero exposure to diethylstilbesterol (DES) with subsequent development of vaginal cancer 15-22 years later. In the late 1960s, physicians at MGH identified a very unusual cancer cluster. Eight young woman between the ages of 15-22 were found to have cancer of the vagina, an uncommon cancer even in elderly women. The cluster of cases in young women was initially reported as a case series, but there were no strong hypotheses about the cause.
In retrospect, the cause was in-utero exposure to DES. After World War II, DES started being prescribed for women who were having troubles with a pregnancy -- if there were signs suggesting the possibility of a miscarriage, DES was frequently prescribed. It has been estimated that between 1945-1950 DES was prescribed for about 20% of all pregnancies in the Boston area. Thus, the unborn fetus was exposed to DES in utero, and in a very small percentage of cases this resulted in development of vaginal cancer when the child was 15-22 years old (a very long latent period). There were several reasons why a case-control study was the only feasible way to identify this association: the disease was extremely rare (even in subjects who had been exposed to DES), there was a very long latent period between exposure and development of disease, and initially they had no idea what was responsible, so there were many possible exposures to consider.
In this situation, a case-control study was the only reasonable approach to identify the causative agent. Given how uncommon the outcome was, even a large prospective study would have been unlikely to have more than one or two cases, even after 15-20 years of follow-up. Similarly, a retrospective cohort study might have been successful in enrolling a large number of subjects, but the outcome of interest was so uncommon that few, if any, subjects would have had it. In contrast, a case-control study was conducted in which eight known cases and 32 age-matched controls provided information on many potential exposures. This strategy ultimately allowed the investigators to identify a highly significant association between the mother's treatment with DES during pregnancy and the eventual development of adenocarcinoma of the vagina in their daughters (in-utero at the time of exposure) 15 to 22 years later.
For more information see the DES Fact Sheet from the National Cancer Institute.
An excellent summary of this landmark study and the long-range effects of DES can be found in a Perspective article in the New England Journal of Medicine. A cohort of both mothers who took DES and their children (daughters and sons) was later formed to look for more common outcomes. Members of the faculty at BUSPH are on the team of investigators that follow this cohort for a variety of outcomes, particularly reproductive consequences and other cancers.
Selecting & Defining Cases and Controls
The "case" definition.
Careful thought should be given to the case definition to be used. If the definition is too broad or vague, it is easier to capture people with the outcome of interest, but a loose case definition will also capture people who do not have the disease. On the other hand, an overly restrictive case definition is employed, fewer cases will be captured, and the sample size may be limited. Investigators frequently wrestle with this problem during outbreak investigations. Initially, they will often use a somewhat broad definition in order to identify potential cases. However, as an outbreak investigation progresses, there is a tendency to narrow the case definition to make it more precise and specific, for example by requiring confirmation of the diagnosis by laboratory testing. In general, investigators conducting case-control studies should thoughtfully construct a definition that is as clear and specific as possible without being overly restrictive.
Investigators studying chronic diseases generally prefer newly diagnosed cases, because they tend to be more motivated to participate, may remember relevant exposures more accurately, and because it avoids complicating factors related to selection of longer duration (i.e., prevalent) cases. However, it is sometimes impossible to have an adequate sample size if only recent cases are enrolled.
Sources of Cases
Typical sources for cases include:
- Patient rosters at medical facilities
- Death certificates
- Disease registries (e.g., cancer or birth defect registries; the SEER Program [Surveillance, Epidemiology and End Results] is a federally funded program that identifies newly diagnosed cases of cancer in population-based registries across the US )
- Cross-sectional surveys (e.g., NHANES, the National Health and Nutrition Examination Survey)
Selection of the Controls
As noted above, it is always useful to think of a case-control study as being nested within some sort of a cohort, i.e., a source population that produced the cases that were identified and enrolled. In view of this there are two key principles that should be followed in selecting controls:
- The comparison group ("controls") should be representative of the source population that produced the cases.
- The "controls" must be sampled in a way that is independent of the exposure, meaning that their selection should not be more (or less) likely if they have the exposure of interest.
If either of these principles are not adhered to, selection bias can result (as discussed in detail in the module on Bias).
Note that in the earlier example of a case-control study conducted in the Massachusetts population, we specified that our sampling method was random so that exposed and unexposed members of the population had an equal chance of being selected. Therefore, we would expect that about 1,000 would be exposed and 5,000 unexposed (the same ratio as in the whole population), and came up with an odds ratio that was same as the hypothetical risk ratio we would have had if we had collected exposure information from the whole population of six million:
What if we had instead been more likely to sample those who were exposed, so that we instead found 1,500 exposed and 4,500 unexposed among the 6,000 controls? Then the odds ratio would have been:
This odds ratio is biased because it differs from the true odds ratio. In this case, the bias stemmed from the fact that we violated the second principle in selection of controls. Depending on which category is over or under-sampled, this type of bias can result in either an underestimate or an overestimate of the true association.
A hypothetical case-control study was conducted to determine whether lower socioeconomic status (the exposure) is associated with a higher risk of cervical cancer (the outcome). The "cases" consisted of 250 women with cervical cancer who were referred to Massachusetts General Hospital for treatment for cervical cancer. They were referred from all over the state. The cases were asked a series of questions relating to socioeconomic status (household income, employment, education, etc.). The investigators identified control subjects by going door-to-door in the community around MGH from 9:00 AM to 5:00 PM. Many residents are not home, but they persist and eventually enroll enough controls. The problem is that the controls were selected by a different mechanism than the cases, AND the selection mechanism may have tended to select individuals of different socioeconomic status, since women who were at home may have been somewhat more likely to be unemployed. In other words, the controls were more likely to be enrolled (selected) if they had the exposure of interest (lower socioeconomic status).

Sources for "Controls"
Population controls:.
A population-based case-control study is one in which the cases come from a precisely defined population, such as a fixed geographic area, and the controls are sampled directly from the same population. In this situation cases might be identified from a state cancer registry, for example, and the comparison group would logically be selected at random from the same source population. Population controls can be identified from voter registration lists, tax rolls, drivers license lists, and telephone directories or by "random digit dialing". Population controls may also be more difficult to obtain, however, because of lack of interest in participating, and there may be recall bias, since population controls are generally healthy and may remember past exposures less accurately.
Example of a Population-based Case-Control Study: Rollison et al. reported on a "Population-based Case-Control Study of Diabetes and Breast Cancer Risk in Hispanic and Non-Hispanic White Women Living in US Southwestern States". (ALink to the article - Citation: Am J Epidemiol 2008;167:447–456).
"Briefly, a population-based case-control study of breast cancer was conducted in Colorado, New Mexico, Utah, and selected counties of Arizona. For investigation of differences in the breast cancer risk profiles of non-Hispanic Whites and Hispanics, sampling was stratified by race/ethnicity, and only women who self-reported their race as non-Hispanic White, Hispanic, or American Indian were eligible, with the exception of American Indian women living on reservations. Women diagnosed with histologically confirmed breast cancer between October 1999 and May 2004 (International Classification of Diseases for Oncology codes C50.0–C50.6 and C50.8–C50.9) were identified as cases through population-based cancer registries in each state."
"Population-based controls were frequency-matched to cases in 5-year age groups. In New Mexico and Utah, control participants under age 65 years were randomly selected from driver's license lists; in Arizona and Colorado, controls were randomly selected from commercial mailing lists, since driver's license lists were unavailable. In all states, women aged 65 years or older were randomly selected from the lists of the Centers for Medicare and Medicaid Services (Social Security lists). Of all women contacted, 68 percent of cases and 42 percent of controls participated in the study."
"Odds ratios and 95% confidence intervals were calculated using logistic regression, adjusting for age, body mass index at age 15 years, and parity. Having any type of diabetes was not associated with breast cancer overall (odds ratio = 0.94, 95% confidence interval: 0.78, 1.12). Type 2 diabetes was observed among 19% of Hispanics and 9% of non-Hispanic Whites but was not associated with breast cancer in either group."
In this example, it is clear that the controls were selected from the source population (principle 1), but less clear that they were enrolled independent of exposure status (principle 2), both because drivers' licenses were used for selection and because the participation rate among controls was low. These factors would only matter if they impacted on the estimate of the proportion of the population who had diabetes.
Hospital or Clinic Controls:

- They have diseases that are unrelated to the exposure being studied. For example, for a study examining the association between smoking and lung cancer, it would not be appropriate to include patients with cardiovascular disease as control, since smoking is a risk factor for cardiovascular disease. To include such patients as controls would result in an underestimate of the true association.
- Second, control patients in the comparison should have diseases with similar referral patterns as the cases, in order to minimize selection bias. For example, if the cases are women with cervical cancer who have been referred from all over the state, it would be inappropriate to use controls consisting of women with diabetes who had been referred primarily from local health centers in the immediate vicinity of the hospital. Similarly, it would be inappropriate to use patients from the emergency room, because the selection of a hospital for an emergency is different than for cancer, and this difference might be related to the exposure of interest.
The advantages of using controls who are patients from the same facility are:
- They are easier to identify
- They are more likely to participate than general population controls.
- They minimize selection bias because they generally come from the same source population (provided referral patterns are similar).
- Recall bias would be minimized, because they are sick, but with a different diagnosis.
Example: Several years ago the vascular surgeons at Boston Medical Center wanted to study risk factors for severe atherosclerosis of the lower extremities. The cases were patients who were referred to the hospital for elective surgery to bypass severe atherosclerotic blockages in the arteries to the legs. The controls consisted of patients who were admitted to the same hospital for elective joint replacement of the hip or knee. The patients undergoing joint replacement were similar in age and they also were following the same referral pathways. In other words, they met the "would" criterion: if one of the joint replacement surgery patients had developed severe atherosclerosis in their leg arteries, they would have been referred to the same hospital.
Friend, Neighbor, Spouse, and Relative Controls:
Occasionally investigators will ask cases to nominate controls who are in one of these categories, because they have similar characteristics, such as genotype, socioeconomic status, or environment, i.e., factors that can cause confounding, but are hard to measure and adjust for. By matching cases and controls on these factors, confounding by these factors will be controlled. However, one must be careful that the controls satisfy the two fundamental principles. Often, they do not.
How Many Controls?
Since case-control studies are often used for uncommon outcomes, investigators often have a limited number of cases but a plentiful supply of potential controls. In this situation the statistical power of the study can be increased somewhat by enrolling more controls than cases. However, the additional power that is achieved diminishes as the ratio of controls to cases increases, and ratios greater than 4:1 have little additional impact on power. Consequently, if it is time-consuming or expensive to collect data on controls, the ratio of controls to cases should be no more than 4:1. However, if the data on controls is easily obtained, there is no reason to limit the number of controls.
Methods of Control Sampling
There are three strategies for selecting controls that are best explained by considering the nested case-control study described on page 3 of this module:
- Survivor sampling: This is the most common method. Controls consist of individuals from the source population who do not have the outcome of interest.
- Case-base sampling (also known as "case-cohort" sampling): Controls are selected from the population at risk at the beginning of the follow-up period in the cohort study within which the case-control study was nested.
- Risk Set Sampling: In the nested case-control study a control would be selected from the population at risk at the point in time when a case was diagnosed.
The Rare Outcome Assumption
It is often said that an odds ratio provides a good estimate of the risk ratio only when the outcome of interest is rare, but this is only true when survivor sampling is used. With case-base sampling or risk set sampling, the odds ratio will provide a good estimate of the risk ratio regardless of the frequency of the outcome, because the controls will provide an accurate estimate of the distribution in the source population (i.e., not just in non-diseased people).
More on Selection Bias
Always consider the source population for case-control studies, i.e. the "population" that generated the cases. The cases are always identified and enrolled by some method or a set of procedures or circumstances. For example, cases with a certain disease might be referred to a particular tertiary hospital for specialized treatment. Alternatively, if there is a database or a disease registry for a geographic area, cases might be selected at random from the database. The key to avoiding selection bias is to select the controls by a similar, if not identical, mechanism in order to ensure that the controls provide an accurate representation of the exposure status of the source population.
Example 1: In the first example above, in which cases were randomly selected from a geographically defined database, the source population is also defined geographically, so it would make sense to select population controls by some random method. In contrast, if one enrolled controls from a particular hospital within the geographic area, one would have to at least consider whether the controls were inherently more or less likely to have the exposure of interest. If so, they would not provide an accurate estimate of the exposure distribution of the source population, and selection bias would result.
Example 2: In the second example above, the source population was defined by the patterns of referral to a particular hospital for a particular disease. In order for the controls to be representative of the "population" that produced those cases, the controls should be selected by a similar mechanism, e.g., by contacting the referring health care providers and asking them to provide the names of potential controls. By this mechanism, one can ensure that the controls are representative of the source population, because if they had had the disease of interest they would have been just as likely as the cases to have been included in the case group (thus fulfilling the "would" criterion).
Example 3: A food handler at a delicatessen who is infected with hepatitis A virus is responsible for an outbreak of hepatitis which is largely confined to the surrounding community from which most of the customers come. Many (but not all) of the infected cases are identified by passive and active surveillance. How should controls be selected? In this situation, one might guess that the likelihood of people going to the delicatessen would be heavily influenced by their proximity to it, and this would to a large extent define the source population. In a case-control study undertaken to identify the source, the delicatessen is one of the exposures being tested. Consequently, even if the cases were reported to the state-wide surveillance system, it would not be appropriate to randomly select controls from the state, the county, or even the town where the delicatessen is located. In other words, the "would" criterion doesn't work here, because anyone in the state with clinical hepatitis would end up in the surveillance system, but someone who lived far from the deli would have a much lower likelihood of having the exposure. A better approach would be to select controls who were matched to the cases by neighborhood, age, and gender. These controls would have similar access to go to the deli if they chose to, and they would therefore be more representative of the source population.
Analysis of Case-Control Studies
The computation and interpretation of the odds ratio in a case-control study has already been discussed in the modules on Overview of Analytic Studies and Measures of Association. Additionally, one can compute the confidence interval for the odds ratio, and statistical significance can also be evaluated by using a chi-square test (or a Fisher's Exact Test if the sample size is small) to compute a p-value. These calculations can be done using the Case-Control worksheet in the Excel file called EpiTools.XLS.

Advantages and Disadvantages of Case-Control Studies
Advantages:
- They are efficient for rare diseases or diseases with a long latency period between exposure and disease manifestation.
- They are less costly and less time-consuming; they are advantageous when exposure data is expensive or hard to obtain.
- They are advantageous when studying dynamic populations in which follow-up is difficult.
Disadvantages:
- They are subject to selection bias.
- They are inefficient for rare exposures.
- Information on exposure is subject to observation bias.
- They generally do not allow calculation of incidence (absolute risk).
- - Google Chrome
Intended for healthcare professionals
- Access provided by Google Indexer
- My email alerts
- BMA member login
- Username * Password * Forgot your log in details? Need to activate BMA Member Log In Log in via OpenAthens Log in via your institution
Search form
- Advanced search
- Search responses
- Search blogs
- Nested case-control...
Nested case-control studies: advantages and disadvantages
- Related content
- Peer review
- Philip Sedgwick , reader in medical statistics and medical education 1
- 1 Centre for Medical and Healthcare Education, St George’s, University of London, London, UK
- p.sedgwick{at}sgul.ac.uk
Researchers investigated whether antipsychotic drugs were associated with venous thromboembolism. A population based nested case-control study design was used. Data were taken from the UK QResearch primary care database consisting of 7 267 673 patients. Cases were adult patients with a first ever record of venous thromboembolism between 1 January 1996 and 1 July 2007. For each case, up to four controls were identified, matched by age, calendar time, sex, and practice. Exposure to antipsychotic drugs was assessed on the basis of prescriptions on, or during the 24 months before, the index date. 1
There were 25 532 eligible cases (15 975 with deep vein thrombosis and 9557 with pulmonary embolism) and 89 491 matched controls. The primary outcome was the odds ratios for venous thromboembolism associated with antipsychotic drugs adjusted for comorbidity and concomitant drug exposure. When adjusted using logistic regression to control for potential confounding, prescription of antipsychotic drugs in the previous 24 months was significantly associated with an increased occurrence of venous thromboembolism compared with non-use (odds ratio 1.32, 95% confidence interval 1.23 to 1.42). The researchers concluded that prescription of antipsychotic drugs was associated with venous thromboembolism in a large primary care population.
Which of the following statements, if any, are true?
a) The nested case-control study is a retrospective design
b) The study design minimised selection bias compared with a case-control study
c) Recall bias was minimised compared with a case-control study
d) Causality could be inferred from the association between prescription of antipsychotic drugs and venous thromboembolism
Statements a , b , and c are true, whereas d is false.
The aim of the study was to investigate whether prescription of antipsychotic drugs was associated with venous thromboembolism. A nested case-control study design was used. The study design was an observational one that incorporated the concept of the traditional case-control study within an established cohort. This design overcomes some of the disadvantages associated with case-control studies, 2 while incorporating some of the advantages of cohort studies. 3 4
Data for the study above were extracted from the UK QResearch primary care database, a computerised register of anonymised longitudinal medical records for patients registered at more than 500 UK general practices. Patient data were recorded prospectively, the database having been updated regularly as patients visited their GP. Cases were all adult patients in the register with a first ever record of venous thromboembolism between 1 January 1996 and 1 July 2007. There were 25 532 cases in total. For each case, up to four controls were identified from the register, matched by age, calendar time, sex, and practice. In total, 89 491 matched controls were obtained. Data relating to prescriptions for antipsychotic drugs on, or during the 24 months before, the index date were extracted for the cases and controls. The index date was the date in the register when venous thromboembolism was recorded for the case. The cases and controls were compared to ascertain whether exposure to prescription of antipsychotic drugs was more common in one group than in the other. Despite the data for the cases and controls being collected prospectively, the nested case-control study is described as retrospective ( a is true) because it involved looking back at events that had already taken place and been recorded in the register.
Selection bias is of particular concern in the traditional case-control study. Described in a previous question, 5 selection bias is the systematic difference between the study participants and the population they are meant to represent with respect to their characteristics, including demographics and morbidity. Cases and controls are often selected through convenience sampling. Cases are typically recruited from hospitals or general practices because they are convenient and easily accessible to researchers. Controls are often recruited from the same hospital clinics or general practices as the cases. Therefore, the selected cases may not be representative of the population of all cases. Equally, the controls might not be representative of otherwise healthy members of the population. The above nested case-control study was population based, with the QResearch primary care database incorporating a large proportion of the UK population. The cases and controls were selected from the database and therefore should be more representative of the population than those in a traditional case-control study. Hence, selection bias was minimised by using the nested case-control study design ( b is true).
The traditional case-control study involves participants recalling information about past exposure to risk factors after identification as a case or control. The study design is prone to recall bias, as described in a previous question. 6 Recall bias is the systematic difference between cases and controls in the accuracy of information recalled. Recall bias will exist if participants have selective preconceptions about the association between the disease and past exposure to the risk factor(s). Cases may, for example, recall information more accurately than controls, possibly because of an association with the disease or outcome. Although in the study above the cases and controls were identified retrospectively, the data for the QResearch primary care database were collected prospectively. Therefore, there was no reason for any systematic differences between groups of study participants in the accuracy of the information collected. Therefore, recall bias was minimised compared with a traditional case-control study ( c is true).
Not all of the patient records in the UK QResearch primary care database were used to explore the association between prescription of antipsychotic drugs and development of venous thromboembolism. A nested case-control study was used instead, with cases and controls matched on age, calendar time, sex, and practice. This was because it was statistically more efficient to control for the effects of age, calendar time, sex, and practice by matching cases and controls on these variables at the design stage, rather than controlling for their potential confounding effects when the data were analysed. The matching variables were considered to be important factors that could potentially confound the association between prescription of antipsychotic drugs and venous thromboembolism, but they were not of interest as potential risk factors in themselves. Matching in case-control studies has been described in a previous question. 7
Unlike a traditional case-control study, the data in the example above were recorded prospectively. Therefore, it was possible to determine whether prescription of antipsychotic drugs preceded the occurrence of venous thromboembolism. Nonetheless, only association, and not causation, can be inferred from the results of the above nested case-control study ( d is false)—that is, those people who were exposed to prescribed antipsychotic drugs were more likely to have developed venous thromboembolism. This is because the observed association between prescribed antipsychotic drugs and occurrence of venous thromboembolism may have been due to confounding. In particular, it was not possible to measure and then control for, through statistical analysis, all factors that may have affected the occurrence of venous thromboembolism.
The example above is typical of a nested case-control study; the health records for a group of patients that have already been collected and stored in an electronic database are used to explore the association between one or more risk factors and a disease or condition. The management of such databases means it is possible for a variety of studies to be undertaken, each investigating the risk factors associated with different diseases or outcomes. Nested case-control studies are therefore relatively inexpensive to perform. However, the major disadvantage of nested case-control studies is that not all pertinent risk factors are likely to have been recorded. Furthermore, because many different healthcare professionals will be involved in patient care, risk factors and outcome(s) will probably not have been measured with the same accuracy and consistency throughout. It may also be problematic if the diagnosis of the disease or outcome changes with time.
Cite this as: BMJ 2014;348:g1532
Competing interests: None declared.
- ↵ Parker C, Coupland C, Hippisley-Cox J. Antipsychotic drugs and risk of venous thromboembolism: nested case-control study. BMJ 2010 ; 341 : c4245 . OpenUrl Abstract / FREE Full Text
- ↵ Sedgwick P. Case-control studies: advantages and disadvantages. BMJ 2014 ; 348 : f7707 . OpenUrl CrossRef
- ↵ Sedgwick P. Prospective cohort studies: advantages and disadvantages. BMJ 2013 ; 347 : f6726 . OpenUrl FREE Full Text
- ↵ Sedgwick P. Retrospective cohort studies: advantages and disadvantages. BMJ 2014 ; 348 : g1072 . OpenUrl FREE Full Text
- ↵ Sedgwick P. Selection bias versus allocation bias. BMJ 2013 ; 346 : f3345 . OpenUrl FREE Full Text
- ↵ Sedgwick P. What is recall bias? BMJ 2012 ; 344 : e3519 . OpenUrl FREE Full Text
- ↵ Sedgwick P. Why match in case-control studies? BMJ 2012 ; 344 : e691 . OpenUrl FREE Full Text
IMAGES
VIDEO
COMMENTS
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes.[1] ... the investigator can include unequal numbers of cases with controls such as 2:1 or 4:1 to increase the power of the study. Disadvantages and Limitations.
Disadvantages of case-control studies. Case-control studies, similarly to observational studies, run a high risk of research biases. They are particularly susceptible to observer bias, recall bias, and interviewer bias. In the case of very rare exposures of the outcome studied, attempting to conduct a case-control study can be very time ...
Advantages and Disadvantages of Case-Control Studies. They are efficient for rare diseases or diseases with a long latency period between exposure and disease manifestation. They are less costly and less time-consuming; they are advantageous when exposure data is expensive or hard to obtain. They are advantageous when studying dynamic ...
Case-control studies are one of the major observational study designs for performing clinical research. The advantages of these study designs over other study designs are that they are relatively quick to perform, economical, and easy to design and implement. Case-control studies are particularly appropriate for studying disease outbreaks, rare diseases, or outcomes of interest. This article ...
In a case-control study the researcher identifies a case group and a control group, with and without the outcome of interest. Such a study design is called observational because the researcher does not control the assignment of a subject to one of the groups, unlike in a planned experimental study. In a.
2.5 Advantages and Disadvantages of Case-Control Studies. Case-control studies are typically rapid, inexpensive, and simple to conduct. Samples of cases and controls are frequently taken from sources like an existing database of patient health records. Additionally, case-control studies are particularly well suited for researching the ...
A case-control study can help provide extra insight on data that has already been collected. A case-control study is a way of carrying out a medical investigation to confirm or indicate what is ...
Disadvantages. Retrospective studies have more problems with data quality because they rely on memory and people with a condition will be more motivated to recall risk factors (also called recall bias). ... A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure. The study ...
Case-control studies. Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups.
A case-control study (also known as a case-referent study) is a type of observational study in which two existing groups differing in outcome are identified and compared on the basis of some supposed causal attribute. It is designed to help determine if an exposure is associated with an outcome (i.e., disease or condition of interest).
Case-control studies are the most efficient design for rare diseases and require a much smaller study sample than cohort studies. Additionally, investigators can avoid the ... Disadvantages of case-control studies Case-control studies do not yield an estimate of rate or risk, as the denominator of these measures is not defined. ...
In the module entitled Overview of Analytic Studies it was noted that Rothman describes the case-control strategy as follows: "Case-control studies are best understood by considering as the starting point a source population, which represents a hypothetical study population in which a cohort study might have been conducted.The source population is the population that gives rise to the cases ...
Case-control studies: advantages and disadvantages. Researchers investigated the risk factors associated with the development of pulmonary tuberculosis in Russia. A case-control study was performed in the city of Samara, 700 miles south east of Moscow. Cases were 334 consecutive adults diagnosed as having culture confirmed pulmonary ...
Case-control studies are one of the major observational study designs for performing clinical research. The advantages of these study designs over other study designs are that they are relatively quick to perform, economical, and easy to design and implement. Case-control studies are particularly appropriate for studying disease outbreaks, rare ...
a) The nested case-control study is a retrospective design. b) The study design minimised selection bias compared with a case-control study. c) Recall bias was minimised compared with a case-control study. d) Causality could be inferred from the association between prescription of antipsychotic drugs and venous thromboembolism.
Key points. 1. Case-control studies are easier to conduct than cohort studies. 2. They suffer from bias, especially selection bias. 3. Case-control studies do not give the prevalence or the incidence of the condition of interest.
Matched case-control study designs are commonly implemented in the field of public health. While matching is intended to eliminate confounding, the main potential benefit of matching in case-control studies is a gain in efficiency. Methods for analyzing matched case-control studies have focused on utilizing conditional logistic regression ...