- Skip to primary navigation
- Skip to main content
Open Computer Vision Library

Your 2024 Guide to the Top 6 Computer Vision Problems
bharat February 14, 2024 Leave a Comment AI Careers Tags: common computer vision problems computer vision computer vision problems deep learning

Introduction
Computer Vision is a recent subset of Artificial Intelligence that has seen a huge surge in demand in recent years. We can owe this to the incredible computing power we have today and the vast availability of data. We’ve all used a Computer Vision application in some form or another in our daily lives, say the face unlock on our mobile devices or even the filters we use in Instagram and Snapchat. But with such awesome capabilities, there are numerous factors constraining its implementation. In this read, we discuss the common Computer Vision problems , why they arise, and how they can be tackled.
Table of Contents Introduction Why do problems arise in Computer Vision? Common Computer Vision Problems Conclusion
Why do problems arise in Computer Vision?
When working with Computer Vision systems, they pose many technical problems that could arise, for instance, the inherent complexity of interpreting visual data. Overcoming such issues can help develop robust and adaptable vision systems. In this section, we’ll delve into why computer vision problems arise.
Visual Data Diversity
The diversity in visual representation , say illumination, perspective, or occlusion in objects, poses a big challenge. These variations need to be overcome to eliminate any visual discrepancies.
Dimensional Complexity
With every image composed of millions of pixels, dimensional complexity becomes another barrier one needs to cross. This could be done by adopting different techniques and methodologies.
Dataset Integrity
The integrity of visual data could be breached in the form of compression anomalies or sensor noise. The balance between noise reduction and preservation of features needs to be achieved.
Internal Class Variations
Then, there is variability within the same classes. What does that mean? Well, the diversity of object categories poses a challenge for algorithms to identify unifying characteristics amongst a ton of variations. This requires distilling the quintessential attributes that define a category while disregarding superficial differences.
Real-time Decision Making
Real-time processing can be aggravating. This comes into play when making decisions for autonomous navigation or interactive augmented realities needing optimal performance of computational frameworks and algorithms for swift and accurate analysis.
Perception in Three Dimensions
This is not a problem per se but rather a crucial task which is inferring three dimensionality. This involves extracting three-dimensional insights from two-dimensional images. Here, algorithms must traverse the ambiguity of depth and spatial relationships.
Labeled Dataset Scarcity
The scarcity of annotated data or extensively labeled datasets poses another problem while training state-of-the-art models. This can be overcome using unsupervised and semi-supervised learning. Another reason why a computer vision problem could arise is that vision systems are susceptible to making wrong predictions, which can go unnoticed by researchers. While we are on the topic of labeled datatset scarcity, we must also be familiar with improper labeling . This occurs when a label attached to an object is mislabeled. It can result in inaccurate predictions during model deployment.
Ethical Considerations
Ethical considerations are paramount in Artificial Intelligence, and it is no different in Computer Vision. This could be biases in deep learning models or any discriminatory outcomes. This emphasizes the need for a proper approach to dataset curation or algorithm development.
Multi-modal Implementation
Coming to integrating computer vision into broader technological ecosystems like NLP or Robotics requires not just technical compatibility but also a shared understanding. We’ve only scratched the surface of the causes of different machine vision issues. Now, we will move into the common computer vision problems and their solutions.
Common Computer Vision Problems
When working with deep learning algorithms and models, one tends to run into multiple problems before robust and efficient systems can be brought to life. In this section, we’ll discuss the common computer vision problems one encounters and their solutions.
Inadequate GPU Compute
GPUs or Graphic Processing Units were initially designed for accelerated graphical processing. Nvidia has been at the top of the leaderboard in the GPU scene. So what’s GPU to do with Computer Vision? Well, this past decade has seen a surge in demand for GPUs to accelerate machine learning and deep learning training.
Finding the right GPU can be a daunting task. Big GPUs come at a premium price, and if you are thinking of moving to the cloud, it sees frequent shortages. GPUs need to be optimized since most of us do not have access to clusters of machines.
Memory is one of the most crucial aspects when choosing the proper GPU. Low vRAM (Low memory GPUs) can severely hinder the progress of big computer vision and deep learning projects.
Another way around this memory conundrum is GPU utilization. GPU utilization is the percentage of graphics card used at a particular point in time.
So, what are some of the causes of poor GPU utilization?
- Some vision applications may need large amounts of memory bandwidth, meaning the GPU may have a long wait time for the data to be transferred to or from the memory. This can be sorted by leveraging memory access patterns.
- A few computational tasks can be less intensive, meaning the GPU may not be used to the fullest. This could be conditional logic or other operations which are not apt for parallel processing.
- Another issue is the CPU not being able to supply data fast to the GPU, resulting in GPU idling. By using asynchronous data transferring, this can be fixed.
- Some operations like memory allocation or explicit synchronization can stop the GPU altogether and cause it to idle, which is, again, poor GPU utilization.
- Another cause of poor GPU utilization is inefficient parallelization of threads where the workload is not evenly distributed across all the cores of the GPU.
We need to effectively monitor and control the GPU utilization as it can significantly better the model’s performance. This can be made possible using tools like NVIDIA System Management Interface that offers real-time data on multiple aspects of the GPU, like memory consumption, power usage, and temperature. Let us look at how we can leverage these tools to better optimize GPU usage.
- Batch size adjustments: Larger batch sizes would consume more memory but can also improve overall throughput. One step to boost GPU utilization is modifying the batch size while training the model. The batch size can be modified by testing various batch sizes and help us strike the right balance between memory usage and performance.
- Mixed precision training: Another solution to enhance the efficiency of the GPU is mixed precision training. It uses lower-precision data types when performing calculations on Tensor Cores. This method not only reduces computation time and memory demands but does not compromise on accuracy.
- Distributed Training: Another way around high GPU usage can be distributing the workload across multiple GPUs. By leveraging frameworks like MirroredStrategy from TensorFlow or DistributedDataParallel from PyTorch, the implementation of distributed training approaches can be simplified.
Two standard series of GPUs are the RTX and the GTX series, where RTX is the newer, more powerful graphics card while the GTX is the older series. Before investing in any of them, it is essential to research on them. A few factors to note when choosing the right GPU include analyzing the project requirements and the memory needed for the computations. A good starting point is to have at least 8GB of video RAM for seamless deep learning model training.

GeForce RTX 20-Series
If you are on a budget, then there are alternatives like Google Colab or Azure that offer free access to GPUs for a limited time period. So you can complete your vision projects without needing to invest in a GPU.
As seen, hardware issues like GPUs are pretty common when training models, but there are loads of ways one can work their way around it.
Poor Data Distribution and Quality
The quality of the dataset being fed into your vision model is essential. Every change made to the annotations must translate to better performance in the project. Rectifying all these inaccuracies can drastically improve the overall accuracy of the production models and drastically improve the quality of the labels and annotations.
Poor quality data within image or video datasets can pose a big problem to researchers. Another issue can be not having access to quality data, which will cause us to be unable to produce the desired output.
Although there are AI-assisted automation tools for labeling data, improving the quality of these datasets can be time-consuming. Add that to having thousands of images and videos in a dataset and looking through each of them on a granular level; looking for inaccuracies can be a painstaking task.
Suboptimal data distribution can significantly undermine the performance and generalization capabilities of these models. Let us look at some causes of poor data distribution or errors and their solutions.
Mislabeled Images
Mislabeled images occur when there exists a conflict between the assigned categorical or continuous label and the actual visual content depicted within the image. This could stem from human error during
- Manual annotation processes
- Algorithmic misclassifications in automated labeling systems, or
- Ambiguous visual representations susceptible to subjective interpretations
If mislabeled images exist within training datasets, it can lead to incorrect feature-label associations within the learning algorithms. This could cause degradation in model accuracy and a diminished capacity for the model to generalize from the training data to novel, unseen datasets.
To overcome mislabeled images
- We can implement rigorous dataset auditing protocols
- Leverage consensus labeling through multiple annotators to ensure label accuracy
- Implement advanced machine learning algorithms that can identify and correct mislabeled instances through iterative refinement processes
Missing Labels
Another issue one can face is when a subset of images within a dataset does not have any labels. This could be due to
- oversight in the annotation process
- the prohibitive scale of manual labeling efforts, or
- failures in automated detection algorithms to identify relevant features within the images
Missing labels can create biased training processes when a portion of a dataset is void of labels. Here, deep learning models are exposed to an incomplete representation of the data distribution, resulting in models performing poorly when applied to unlabeled data.
By leveraging semi-supervised learning techniques, we can eliminate missing labels. By utilizing both labeled and unlabeled data in model training, we can enhance the model’s exposure to the underlying data distribution. Also, by deploying more efficient detection algorithms, we can reduce the incidence of missing labels.
Unbalanced Data
Unbalanced data can take the form of certain classes that are significantly more prevalent than others, resulting in the disproportionate representation of classes.
Much like missing labels, unbalanced training on unbalanced datasets can lead to the development of biases by machine learning models towards the more frequently represented classes. This can drastically affect the model’s ability to accurately recognize and classify instances of underrepresented classes and can severely limit its applicability in scenarios requiring equitable performance across various classes.
Unbalanced data can be counteracted through techniques like
- Oversampling of minority classes
- Undersampling of majority classes
- Synthetic data generation via techniques such as Generative Adversarial Networks (GANs), or
- Implementation of custom loss functions
It is paramount that we address any complex challenges associated with poor data distribution or lack thereof, as it can lead to inefficient model performance or biases. One can develop robust, accurate, and fair computer vision models by incorporating advanced algorithmic strategies and continuous model evaluation.
Bad Combination of Augmentations
A huge limiting factor while training deep learning models is the lack of large-scale labeled datasets. This is where Data Augmentation comes into the picture.
What is Data Augmentation? Data augmentation is the process of using image processing-based algorithms to distort data within certain limits and increase the number of available data points. It aids not only in increasing the data size but also in the model generalization for images it has not seen before. By leveraging Data Augmentation, we can limit data issues to some extent. A few data augmentation techniques include
- Image Shifts
- Horizontal Flips
- Translation
- Vertical Flips
- Gaussian noise
Data augmentation is done to generate a synthetic dataset, which is more vast than the original dataset. If the model encounters any issues in production, then augmenting the images to create a more extensive dataset will help generalize it in a better way.

Augmented Images
Let us explore some of the reasons why bad combinations of augmentations in computer vision occur based on tasks.
Excessive Rotation
Excessive rotation can pose a problem for the model to learn the correct orientation of objects. This can mainly be seen with tasks like object detection when the objects are typically found in standard orientations (e.g., street signs) or some orientations are unrealistic.
Heavy Noise
Excessive addition of noise to images can be counterproductive for tasks that require recognizing subtle differences between classes, for instance, the classification of species in biology. The noise can conceal essential features.
Random Cropping
Random cropping can lead to the removal of some essential parts of the image that are critical for correct classification or detection. For instance, randomly cropping parts of medical images might remove pathological features critical for diagnosis.
Excessive Brightness
Making extreme adjustments to brightness or contrast can alter the appearance of critical diagnostic features, leading to misinterpretation made by the model.
Aggressive Distortion
Suppose we are to apply aggressive geometric distortions (like extreme skewing or warping) aggressively. In that case, it can significantly alter the appearance of text in images, making it difficult for models to recognize the characters accurately in optical character recognition (OCR) tasks.
Color Jittering
Color jittering is another issue one can come across when dealing with data augmentation. For any task where the key distinguishing feature is color, excessive modifications to color, like brightness, contrast, or saturation, can distort the natural color distribution of the objects and mislead the model.
Avoiding such excessive augmentations needs a good understanding of the needs and limitations of the models. Let us explore some standard guidelines to help avoid bad augmentation practices.
Understand the Task and Data
First, we need to understand what the task is at hand, for instance, if it is classification or detection, and also the nature of the images. Then, we need to pick the apt form of augmentation. It is also good to understand the characteristics of your dataset . If your dataset includes images from various orientations, excessive rotation might not be necessary.
Use of Appropriate Augmentation Libraries
Try utilizing libraries like Albumentations, imgaug, or TensorFlow’s and PyTorch’s built-in augmentation functionalities . They offer extensive control over the augmentation process, allowing us to specify the degree of augmentation that is applied.
Implement Conditional Augmentation

Dynamically adjust the intensity of augmentations based on the model’s performance or during different training phases.
Augmentation Parameters Fine-tuning
Find the right balance that improves model robustness without distorting the data beyond recognition. This can be achieved by carefully tuning the parameters.
Make incremental changes, start with minor augmentations, and gradually increase their intensity, monitoring the impact on model performance.
Optimize Augmentation Pipelines
Any multiple augmentations in a pipeline must be optimized. We must also ensure that combining any augmentations does not lead to unrealistic images.
Use random parameters within reasonable bounds to ensure diversity without extreme distortion.
Validation and Experimentation
Regularly validate the model on a non-augmented validation set to ensure that augmentations are improving the model’s ability to generalize rather than memorize noise.
Experiment with different augmentation strategies in parallel to compare their impact on model performance.
As seen above, a ton of issues arise when dealing with data augmentation, like excessive brightness, color jittering, or heavy noise. But by leveraging techniques like cropping, image shifts, horizontal flips, and Gaussian noise, we can curb bad combinations of augmentations.
Inadequate Model Architecture Selection
Selecting an inadequate model architecture is another common computer vision problem that can be attributed to many factors. They affect the overall performance, efficiency, and applicability of the model for specific computational tasks.
Let us discuss some of the common causes of poor model architecture selection.

Deep Neural Network Model Architecture Selection
Lack of Domain Understanding
A common issue is the lack of knowledge of the problem space or the requirements for the task. Diverse architectures require proficiency across different fields. For instance, Convolutional Neural Networks (CNNs) are essential for image data, whereas Recurrent Neural Networks (RNNs) are needed for sequential data. Having a superficial understanding of the task nuances can lead to the selection of an architecture that is not aligned with the task requirements.
Computational Limitations
We must always keep in mind the computational resources we have available. Models that require high computational power and memory cannot be viable for deployment. This could lead to the selection of simpler and less efficient models.
Data Constraints
Choosing the right architecture heavily depends on the volume and integrity of available data . Intricate models require voluminous datasets of high-quality, labeled data for effective training. In scenarios that have data paucity, noise, imbalance, or a model with greater sophistication might not yield superior performance and could cause overfitting.
Limited Familiarity with Architectural Paradigms
A lot of novel architectures and models are emerging with the huge strides made in deep learning. However, researchers default to utilizing models they are familiar with, which may not be optimal for their desired outcomes. One must always be updated with the latest contributions in the realm of deep learning and computer vision to analyze the advantages and limitations of the new architectures.
Task Complexity Underestimation
Another cause for poor architecture selection is failing to accurately assess the complexity of the task . This may result in adopting simpler models that lack the ability to capture the essential features within the data. This can be attributed to incomplete or not conducting a comprehensive exploratory data analysis or not fully acknowledging the data’s subtleties and variances.
Overlooking Deployment Constraints
The deployment environment has a significant influence on the architecture selection process. For real-time applications or deployment on devices with limited processing capabilities (e.g., smartphones, IoT devices), architectures optimized for memory and computation efficiency are necessary.
Managing these poor architectural selections requires being updated on the latest architectures, as well as a thorough understanding of the problem domain and data characteristics and a careful consideration of the pragmatic constraints associated with model deployment and functionality.
Now that we’ve explored the possible causes for inadequate model architecture let us see how to avoid them.
Balanced Model
Two common challenges one could face are having an overfitting model , which is too complex and overfits the data, or having an underfitting model , which is too simple and fails to infer patterns from the data. We can leverage techniques like regularization or cross-validation to optimize the models’ performance to avoid overfitting or underfitting.
Understanding Model Limitations
Next, we need to be well aware of the limitations and assumptions of the different algorithms and models. Different models have different strengths and weaknesses. They all require different conditions or properties of the data for optimal performance. For instance, some models are sensitive noise or outliers, some are more viable for different tasks like detection, segmentation, or classification. We must know the theory and logic behind every model and check if the data fulfills the desired conditions.
Curbing Data Leakage
Data leakage occurs when information from the test dataset is used to train the model. This can result in biased estimates of the model’s accuracy and performance. A good rule of thumb is to split the data into training and test datasets before moving to any of the steps like preprocessing or feature engineering. One can also avoid using features that are influenced by the target variable.
Continual Assessment
A common misunderstanding is when researchers assume that deployment is the last stage of the project. We need to continually monitor, analyze, and improve on the deployed models. The accuracy of vision models can decline over time as they generalize based on a subset of data. Additionally, they can struggle to adapt to complex user inputs. These reasons further emphasize the need to monitor models post-deployment.
A few steps for continual assessment and improvement include
- Implementation of a robust monitoring system
- Gathering user feedback
- Leveraging the right tools for optimal monitoring
- Refer real-world scenarios
- Addressing underlying issues by analyzing the root cause of loss of model efficiency or accuracy
Much like other computer vision problems, one must be diligent in selecting the right model architecture by assessing the computing resources one has at his disposal, the data constraints, possessing good domain expertise, and finding the optimal model that is not overfitting or underfitting. Following all these steps will curb poor selections in model architecture.

Incorrect Hyperparameter Tuning
Before we delve into the reasons behind poor hyperparameter tuning and its solutions, let us look at what it is.
What is Hyperparameter?
Hyperparameters are the configurations of the model where the model does not learn from the data but rather from the inputs provided before training. They provide a pathway for the learning process and affect how the model behaves during training and prediction. Learning rate, batch size, and number of layers are a few instances of hyperparameters. They can be set based on the computational resources, the complexity of the task and also the characteristics of the datasets.
Incorrect hyperparameter tuning in deep learning can adversely affect model performance, training efficiency, and generalization ability. Hyperparameters are configurations external to the model that cannot be directly learned from the data. Hyperparameters are critical to the performance of the trained model and the behavior of the training algorithm. Here are some of the downsides of incorrect hyperparameter tuning.
Overfitting or Underfitting
If hyperparameters are not tuned correctly, a model may capture noise in training data as a legitimate pattern. Examples include too many layers or neurons without appropriate regularization or too high a capacity.
Underfitting , on the other hand, can result when the model is too simple to capture the underlying structure of the data due to incorrect tuning. Alternatively, the training process might halt before the model has learned enough from the data due to a low model capacity or a low learning rate.

Underfitting & Overfitting
Poor Generalization
Incorrectly tuned hyperparameters can lead to a model that performs well on the training data but poorly on unseen data. This indicates that the model has not generalized well, which is often a result of overfitting.
Inefficient Training
A number of hyperparameters control the efficiency of the training process, including batch size and learning rate. If these parameters are not adjusted appropriately, the model will take much longer to train, requiring more computational resources than necessary. If the learning rate is too small, convergence might be slowed down, but if it is too large, the training process may oscillate or diverge.
Difficulty in Convergence
An incorrect setting of the hyperparameters can make convergence difficult. For example, an excessively high learning rate can cause the model’s loss to fluctuate rather than decrease steadily.
Resource Wastage
It takes considerable computational power and time to train deep learning models. Incorrect hyperparameter tuning can lead to a number of unnecessary training runs.
Model Instability
In some cases, hyperparameter configurations can lead to model instability, where small changes in the data or initialization of the model can lead to large variations in performance.
The use of systematic hyperparameter optimization strategies is crucial to mitigate these issues.
It is crucial to finetune these hyperparameters as they significantly affect the performance and the accuracy of the model.
Let us explore some of the common hyperparameter optimization methods.
- Learning Rate: To prevent underfitting or overfitting, finding an optimal learning rate is crucial in order to prevent the model from updating its parameters too fast or too slowly during training.
- Batch Size: During model training, batch size determines how many samples are processed during each iteration. This influences the training dynamics, memory requirements, and generalization capability of the model. The batch size should be selected in accordance with the computational resources and the characteristics of the dataset on which the model will be trained.
- Network Architecture: Network architecture outlines the blueprint of a neural network, detailing the arrangement and connection of its layers. This includes specifying the total number of layers, identifying the variety of layers (like convolutional, pooling, or fully connected layers), and how they’re set up. The choice of network architecture is crucial and should be tailored to the task’s complexity and the computational resources at hand.
- Kernel Size: In the realm of convolutional neural networks (CNNs), kernel size is pivotal as it defines the scope of the receptive field for extracting features. This choice influences how well the model can discern detailed and spatial information. Adjusting the kernel size is a balancing act to ensure the model effectively captures both local and broader features.
- Dropout Rate: Dropout is a strategy to prevent overfitting by randomly omitting a proportion of the neural network’s units during the training phase. The dropout rate is the likelihood of each unit being omitted. By doing this, it pushes the network to learn more generalized features and lessens its reliance on any single unit.
- Activation Functions: These functions bring non-linearity into the neural network, deciding the output for each node. Popular options include ReLU (Rectified Linear Unit), sigmoid, and tanh. The selection of an activation function is critical as it influences the network’s ability to learn complex patterns and affects the stability of its training.
- Data Augmentation Techniques: Techniques like rotation, scaling, and flipping are used to introduce more diversity to the training data, enhancing its range. Adjusting hyperparameters related to data augmentation, such as the range of rotation angles, scaling factors, and the probability of flipping, can fine-tune the augmentation process. This, in turn, aids the model in generalizing better to new, unseen data.

Data Augmentation
- Optimization Algorithm: The selection of an optimization algorithm affects how quickly and smoothly the model learns during training. Popular algorithms include stochastic gradient descent (SGD), ADAM, and RMSprop. Adjusting hyperparameters associated with these algorithms, such as momentum, learning rate decay, and weight decay, plays a significant role in optimizing the training dynamics.
Unrealistic Project Timelines
This is rather a broader topic that affects all fields of study and does not pertain only to Computer Vision and Deep Learning. It not only affects our psychological state of mind but also destroys our morale . One main reason could be the individual setting up unrealistic deadlines, often not able to gauge the time or effort needed to complete the project or task at hand. As mentioned earlier, this can lead to low morale or lowering one’s self-esteem.
Now, bringing our attention to the realm of Computer Vision, deadlines could range from time taken for collecting the data to deploying models. How do we tackle this? Let us look at a few steps we can take not only to keep us on time but also to deploy robust and accurate vision systems.
Define your Goals
Before we get into the nitty gritty of a Computer Vision project, we need to have a clear understanding of what we wish to achieve through it. This means identifying and defining the end goal, objectives, and milestones. This also needs to be communicated to the concerned team, which could be our colleagues, clients, and sponsors. This will eliminate any unrealistic timelines or misalignments.
Once we set our objectives, we come to our second step, planning, and prioritizations . This involves understanding and visualizing our workflow, leveraging the appropriate tools, cost estimations, and timelines, and analyzing the available resources, be they hardware or software. We must allocate them optimally, curbing any dependencies or risks and eradicating any assumptions that may affect the project.

Once we’ve got our workflow down, we begin the implementation and testing phase, where we code, debug, and validate the inferences made. One must remember the best practices of model development, documentation, code review, and framework testing. This could involve the appropriate usage of tools and libraries like OpenCV, PyTorch, TensorFlow, or Keras to facilitate the models to perform the tasks we trained them for, which could be segmentation, detection, or classification, model evaluation and the accuracy of the models.
This brings us to our final step, project review . We make inferences from the results, analyze the feedback, and make improvements to them. We also need to check how aligned it is with the suggestions given by sponsors or users and make iterations, if any.
Keeping up with project deadlines can be a daunting task at first, but with more experience and the right mindset, we’ll have better time management and greater success in every upcoming project.
We’ve come to the end of this fun read. We’ve covered the six most common computer vision problems one encounters on their journey, ranging from the inadequacies of GPU computing all the way to incorrect hyperparameter tuning. We’ve comprehensively delved into their causes and how they can all be overcome by leveraging different methods and techniques. More fun reads in the realm of Artificial Intelligence , Deep Learning , and Computer Vision are coming your way. See you guys in the next one!
Related Posts

August 16, 2023 Leave a Comment

August 23, 2023 Leave a Comment

August 30, 2023 Leave a Comment
Become a Member
Stay up to date on OpenCV and Computer Vision news
Free Courses
- TensorFlow & Keras Bootcamp
- OpenCV Bootcamp
- Python for Beginners
- Mastering OpenCV with Python
- Fundamentals of CV & IP
- Deep Learning with PyTorch
- Deep Learning with TensorFlow & Keras
- Computer Vision & Deep Learning Applications
- Mastering Generative AI for Art
Partnership
- Intel, OpenCV’s Platinum Member
- Gold Membership
- Development Partnership
General Link
Subscribe and Start Your Free Crash Course
Stay up to date on OpenCV and Computer Vision news and our new course offerings
- We hate SPAM and promise to keep your email address safe.
Join the waitlist to receive a 20% discount
Courses are (a little) oversubscribed and we apologize for your enrollment delay. As an apology, you will receive a 20% discount on all waitlist course purchases. Current wait time will be sent to you in the confirmation email. Thank you!
Guide to Computer Vision: Why It Matters and How It Helps Solve Problems

This post was written to enable the beginner developer community, especially those new to computer vision and computer science. NVIDIA recognizes that solving and benefiting the world’s visual computing challenges through computer vision and artificial intelligence requires all of us. NVIDIA is excited to partner and dedicate this post to the Black Women in Artificial Intelligence .
Computer vision’s real world use and reach is growing and its applications in turn are challenging and changing its meaning. Computer vision, which has been in some form of its present existence for decades, is becoming an increasingly common phrase littered in conversation, across the world and across industries: computer vision systems, computer vision software, computer vision hardware, computer vision development, computer vision pipelines, computer vision technology.
What is computer vision?
There is more to the term and field of computer vision than meets the eye, both literally and figuratively. Computer vision is also referred to as vision AI and traditional image processing in specific non-AI instances, and machine vision in manufacturing and industrial use cases.
Simply put, computer vision enables devices, including laptops, smartphones, self-driving cars, robots, drones, satellites, and x-ray machines to perceive, process, analyze, and interpret data in digital images and video.
In other words, computer vision fundamentally intakes image data or image datasets as inputs, including both still images and moving frames of a video, either recorded or from a live camera feed. Computer vision enables devices to have and use human-like vision capabilities just like our human vision system. In human vision, your eyes perceive the physical world around you as different reflections of light in real-time.
Similarly, computer vision devices perceive pixels of images and videos, detecting patterns and interpreting image inputs that can be used for further analysis or decision making. In this sense, computer vision “sees” just like human vision and uses intelligence and compute power to process input visual data to output meaningful insights, like a robot detecting and avoiding an obstacle in its path.
Different computer vision tasks mimic the human vision system, performing, automating, and enhancing functions similar to the human vision system.
How does computer vision relate to other forms of AI?
Computer vision is helping to teach and master seeing, just like conversational AI is helping teach and master the sense of sound through speech, in applications of recognizing, translating, and verbalizing text: the words we use to define and describe the physical world around us.
Similarly, computer vision helps teach and master the sense of sight through digital image and video. More broadly, the term computer vision can also be used to describe how device sensors, typically cameras, perceive and work as vision systems in applications of detecting, tracking and recognizing objects or patterns in images.
Multimodal conversational AI combines the capabilities of conversational AI with computer vision in multimedia conferencing applications, such as NVIDIA Maxine .
Computer vision can also be used broadly to describe how other types of sensors like light detection and ranging (LiDAR) and radio detection and ranging (RADAR) perceive the physical world. In self-driving cars, computer vision is used to describe how LiDAR and RADAR sensors work, often together and in-tandem with cameras to recognize and classify people, objects, and debris.
What are some common tasks?
While computer vision tasks cover a wide breadth of perception capabilities and the list continues to grow, the latest techniques support and help solve use cases involving detection, classification, segmentation, and image synthesis.
Detection tasks locate, and sometimes track, where an object exists in an image. For example, in healthcare for digital pathology, detection could involve identifying cancer cells through medical imaging. In robotics, software developers are using object detection to avoid obstacles on the factory floor.
Classification techniques determine what object exists within the visual data. For example, in manufacturing, an object recognition system classifies different types of bottles to package. In agriculture, farmers are using classification to identify weeds among their crops.
Segmentation tasks classify pixels belonging to a certain category, either individually by pixel (semantic image segmentation) or by assigning multiple object types of the same class as individual instances (instance image segmentation). For example, a self-driving car segments parts of a road scene as drivable and non-drivable space.
Image synthesis techniques create synthetic data by morphing existing digital images to contain desired content. Generative adversarial networks (GANs), such as EditGAN , enable generating synthetic visual information from text descriptions and existing images of landscapes and people. Using synthetic data to compliment and simulate real data is an emerging computer vision use case in logistics using vision AI for applications like smart inventory control.
What are the different types of computer vision?
To understand the different domains within computer vision, it is important to understand the techniques on which computer vision tasks are based. Most computer vision techniques begin with a model, or mathematical algorithm, that performs a specific elementary operation, task, or combination. While we classify traditional image processing and AI-based computer vision algorithms separately, most computer vision systems rely on a combination depending on the use case, complexity, and performance required.
Traditional computer vision
Traditional, non-deep learning-based computer vision can refer to both computer vision and image processing techniques.
In traditional computer vision, a specific set of instructions perform a specific task, like detecting corners or edges in an image to identify windows in an image of a building.
On the other hand, image processing performs a specific manipulation of an image that can be then used for further processing with a vision algorithm. For instance, you may want to smooth or compress an image’s pixels for display or reduce its overall size. This can be likened to bending the light that enters the eye to adjust focus or viewing field. Other examples of image processing include adjusting, converting, rescaling, and warping an input image.
AI-based computer vision
AI-based computer vision or vision AI relies on algorithms that have been trained on visual data to accomplish a specific task, as opposed to programmed, hard-coded instructions like that of image processing.
The detection, classification, segmentation, and synthesis tasks mentioned earlier typically are AI-based computer vision algorithms because of the accuracy and robustness that can be achieved. In many instances, AI-based computer vision algorithms can outperform traditional algorithms in terms of these two performance metrics.
AI-based computer vision algorithms mimic the human vision system more closely by learning from and adapting to visual data inputs, making them the computer vision models of choice in most cases. That being said, AI-based computer vision algorithms require large amounts of data and the quality of that data directly drives the quality of the model’s output. But, the performance outweighs the cost.
AI-based neural networks teach themselves, depending on the data the algorithm was trained on. AI-based computer vision is like learning from experience and making predictions based on context apart from explicit direction. The learning process is akin to when your eye sees an unfamiliar object and the brain tries to learn what it is and stores it for future predictions.
Machine learning compared to deep learning in AI-based computer vision
Machine learning computer vision is a type of AI-based computer vision. AI-based computer vision based on machine learning has artificial neural networks or layers, similar to that seen in the human brain, to connect and transmit signals about the visual data ingested. In machine learning, computer vision neural networks have separate and distinct layers, explicitly-defined connections between the layers, and predefined directions for visual data transmission.
Deep learning-based computer vision models are a subset of machine learning-based computer vision. The “deep” in deep learning derives its name from the depth or number of the layers in the neural network. Typically, a neural network with three or more layers is considered deep.
AI-based computer vision based on deep learning is trained on volumes of data. It is not uncommon to see hundreds of thousands and millions of digital images used to train and develop deep neural network models. For more information, see What’s the difference Between Artificial Intelligence, Machine Learning, and Deep Learning? .
Get started developing computer vision
Now that we have covered the fundamentals of computer vision, we encourage you to get started developing computer vision. We recommend that beginners get started with the Vision Programming Interface (VPI) Computer Vision and Image Processing Library for non-AI algorithms or one of the TAO Toolkit fully-operational, ready-to-use, pretrained AI models .
To see how NVIDIA enables the end-to-end computer vision workflow, see the Computer Vision Solutions page. NVIDIA provides models plus computer vision and image-processing tools. We also provide AI-based software application frameworks for training visual data, testing and evaluation of image datasets, deployment and execution, and scaling.
To help enable emerging computer vision developers everywhere, NVIDIA is curating a series of paths to mastery to chart and nurture next-generation leaders. Stay tuned for the upcoming release of the computer vision path to mastery to self-pace your learning journey and showcase your #NVCV progress on social media.
Related resources
- DLI course: Deep Learning for Industrial Inspection
- GTC session: The Visionaries: A Cross-Industry Exploration of Computer Vision
- GTC session: Vision AI Demystified
- GTC session: Boost your Vision AI Application with Vision Transformer
- NGC Containers: MATLAB
- Webinar: Transforming Warehouse Operation Management Using Computer Vision and Digital Twins
About the Authors

Related posts

Explainer: What Is Computer Vision?

The Future of Computer Vision

AI Startup Aims To Redefine How People Interact with Technology

AI Reinvents the Filmmaking Process

CSIRO Powers Bionic Vision Research with New GPU-Accelerated Supercomputer
Revolutionizing Graph Analytics: Next-Gen Architecture with NVIDIA cuGraph Acceleration

Efficient CUDA Debugging: Memory Initialization and Thread Synchronization with NVIDIA Compute Sanitizer

Analyzing the Security of Machine Learning Research Code

Comparing Solutions for Boosting Data Center Redundancy
Validating nvidia drive sim radar models.
Suggestions or feedback?
MIT News | Massachusetts Institute of Technology
- Machine learning
- Social justice
- Black holes
- Classes and programs
Departments
- Aeronautics and Astronautics
- Brain and Cognitive Sciences
- Architecture
- Political Science
- Mechanical Engineering
Centers, Labs, & Programs
- Abdul Latif Jameel Poverty Action Lab (J-PAL)
- Picower Institute for Learning and Memory
- Lincoln Laboratory
- School of Architecture + Planning
- School of Engineering
- School of Humanities, Arts, and Social Sciences
- Sloan School of Management
- School of Science
- MIT Schwarzman College of Computing
When computer vision works more like a brain, it sees more like people do
Press contact :.

Previous image Next image
From cameras to self-driving cars, many of today’s technologies depend on artificial intelligence to extract meaning from visual information. Today’s AI technology has artificial neural networks at its core, and most of the time we can trust these AI computer vision systems to see things the way we do — but sometimes they falter. According to MIT and IBM research scientists, one way to improve computer vision is to instruct the artificial neural networks that they rely on to deliberately mimic the way the brain’s biological neural network processes visual images.
Researchers led by MIT Professor James DiCarlo , the director of MIT’s Quest for Intelligence and member of the MIT-IBM Watson AI Lab, have made a computer vision model more robust by training it to work like a part of the brain that humans and other primates rely on for object recognition. This May, at the International Conference on Learning Representations, the team reported that when they trained an artificial neural network using neural activity patterns in the brain’s inferior temporal (IT) cortex, the artificial neural network was more robustly able to identify objects in images than a model that lacked that neural training. And the model’s interpretations of images more closely matched what humans saw, even when images included minor distortions that made the task more difficult.
Comparing neural circuits
Many of the artificial neural networks used for computer vision already resemble the multilayered brain circuits that process visual information in humans and other primates. Like the brain, they use neuron-like units that work together to process information. As they are trained for a particular task, these layered components collectively and progressively process the visual information to complete the task — determining, for example, that an image depicts a bear or a car or a tree.
DiCarlo and others previously found that when such deep-learning computer vision systems establish efficient ways to solve visual problems, they end up with artificial circuits that work similarly to the neural circuits that process visual information in our own brains. That is, they turn out to be surprisingly good scientific models of the neural mechanisms underlying primate and human vision.
That resemblance is helping neuroscientists deepen their understanding of the brain. By demonstrating ways visual information can be processed to make sense of images, computational models suggest hypotheses about how the brain might accomplish the same task. As developers continue to refine computer vision models, neuroscientists have found new ideas to explore in their own work.
“As vision systems get better at performing in the real world, some of them turn out to be more human-like in their internal processing. That’s useful from an understanding-biology point of view,” says DiCarlo, who is also a professor of brain and cognitive sciences and an investigator at the McGovern Institute for Brain Research.
Engineering a more brain-like AI
While their potential is promising, computer vision systems are not yet perfect models of human vision. DiCarlo suspected one way to improve computer vision may be to incorporate specific brain-like features into these models.
To test this idea, he and his collaborators built a computer vision model using neural data previously collected from vision-processing neurons in the monkey IT cortex — a key part of the primate ventral visual pathway involved in the recognition of objects — while the animals viewed various images. More specifically, Joel Dapello, a Harvard University graduate student and former MIT-IBM Watson AI Lab intern; and Kohitij Kar, assistant professor and Canada Research Chair (Visual Neuroscience) at York University and visiting scientist at MIT; in collaboration with David Cox, IBM Research’s vice president for AI models and IBM director of the MIT-IBM Watson AI Lab; and other researchers at IBM Research and MIT asked an artificial neural network to emulate the behavior of these primate vision-processing neurons while the network learned to identify objects in a standard computer vision task.
“In effect, we said to the network, ‘please solve this standard computer vision task, but please also make the function of one of your inside simulated “neural” layers be as similar as possible to the function of the corresponding biological neural layer,’” DiCarlo explains. “We asked it to do both of those things as best it could.” This forced the artificial neural circuits to find a different way to process visual information than the standard, computer vision approach, he says.
After training the artificial model with biological data, DiCarlo’s team compared its activity to a similarly-sized neural network model trained without neural data, using the standard approach for computer vision. They found that the new, biologically informed model IT layer was — as instructed — a better match for IT neural data. That is, for every image tested, the population of artificial IT neurons in the model responded more similarly to the corresponding population of biological IT neurons.
The researchers also found that the model IT was also a better match to IT neural data collected from another monkey, even though the model had never seen data from that animal, and even when that comparison was evaluated on that monkey’s IT responses to new images. This indicated that the team’s new, “neurally aligned” computer model may be an improved model of the neurobiological function of the primate IT cortex — an interesting finding, given that it was previously unknown whether the amount of neural data that can be currently collected from the primate visual system is capable of directly guiding model development.
With their new computer model in hand, the team asked whether the “IT neural alignment” procedure also leads to any changes in the overall behavioral performance of the model. Indeed, they found that the neurally-aligned model was more human-like in its behavior — it tended to succeed in correctly categorizing objects in images for which humans also succeed, and it tended to fail when humans also fail.
Adversarial attacks
The team also found that the neurally aligned model was more resistant to “adversarial attacks” that developers use to test computer vision and AI systems. In computer vision, adversarial attacks introduce small distortions into images that are meant to mislead an artificial neural network.
“Say that you have an image that the model identifies as a cat. Because you have the knowledge of the internal workings of the model, you can then design very small changes in the image so that the model suddenly thinks it’s no longer a cat,” DiCarlo explains.
These minor distortions don’t typically fool humans, but computer vision models struggle with these alterations. A person who looks at the subtly distorted cat still reliably and robustly reports that it’s a cat. But standard computer vision models are more likely to mistake the cat for a dog, or even a tree.
“There must be some internal differences in the way our brains process images that lead to our vision being more resistant to those kinds of attacks,” DiCarlo says. And indeed, the team found that when they made their model more neurally aligned, it became more robust, correctly identifying more images in the face of adversarial attacks. The model could still be fooled by stronger “attacks,” but so can people, DiCarlo says. His team is now exploring the limits of adversarial robustness in humans.
A few years ago, DiCarlo’s team found they could also improve a model’s resistance to adversarial attacks by designing the first layer of the artificial network to emulate the early visual processing layer in the brain. One key next step is to combine such approaches — making new models that are simultaneously neurally aligned at multiple visual processing layers.
The new work is further evidence that an exchange of ideas between neuroscience and computer science can drive progress in both fields. “Everybody gets something out of the exciting virtuous cycle between natural/biological intelligence and artificial intelligence,” DiCarlo says. “In this case, computer vision and AI researchers get new ways to achieve robustness, and neuroscientists and cognitive scientists get more accurate mechanistic models of human vision.”
This work was supported by the MIT-IBM Watson AI Lab, Semiconductor Research Corporation, the U.S. Defense Research Projects Agency, the MIT Shoemaker Fellowship, U.S. Office of Naval Research, the Simons Foundation, and Canada Research Chair Program.
Share this news article on:
Related links.
- Jim DiCarlo
- McGovern Institute for Brain Research
- MIT-IBM Watson AI Lab
- MIT Quest for Intelligence
- Department of Brain and Cognitive Sciences
Related Topics
- Brain and cognitive sciences
- McGovern Institute
- Artificial intelligence
- Computer vision
- Neuroscience
- Computer modeling
- Quest for Intelligence
Related Articles

Neuroscientists find a way to make object-recognition models perform better

Putting vision models to the test

How the brain distinguishes between objects
Previous item Next item
More MIT News
The power of App Inventor: Democratizing possibilities for mobile applications
Read full story →

Using MRI, engineers have found a way to detect light deep in the brain

From steel engineering to ovarian tumor research

A better way to control shape-shifting soft robots

Professor Emeritus David Lanning, nuclear engineer and key contributor to the MIT Reactor, dies at 96

Discovering community and cultural connections
- More news on MIT News homepage →
Massachusetts Institute of Technology 77 Massachusetts Avenue, Cambridge, MA, USA
- Map (opens in new window)
- Events (opens in new window)
- People (opens in new window)
- Careers (opens in new window)
- Accessibility
- Social Media Hub
- MIT on Facebook
- MIT on YouTube
- MIT on Instagram
What Is Computer Vision?

Computer vision is a field of artificial intelligence (AI) that applies machine learning to images and videos to understand media and make decisions about them. With computer vision, we can, in a sense, give vision to software and technology.
How Does Computer Vision Work?
Computer vision programs use a combination of techniques to process raw images and turn them into usable data and insights.
The basis for much computer vision work is 2D images, as shown below. While images may seem like a complex input, we can decompose them into raw numbers. Images are really just a combination of individual pixels and each pixel can be represented by a number (grayscale) or combination of numbers such as (255, 0, 0— RGB ).

Once we’ve translated an image to a set of numbers, a computer vision algorithm applies processing. One way to do this is a classic technique called convolutional neural networks (CNNs) that uses layers to group together the pixels in order to create successively more meaningful representations of the data. A CNN may first translate pixels into lines, which are then combined to form features such as eyes and finally combined to create more complex items such as face shapes.
Why Is Computer Vision Important?
Computer vision has been around since as early as the 1950s and continues to be a popular field of research with many applications. According to the deep learning research group, BitRefine , we should expect the computer vision industry to grow to nearly 50 billion USD in 2022, with 75 percent of the revenue deriving from hardware .
The importance of computer vision comes from the increasing need for computers to be able to understand the human environment. To understand the environment, it helps if computers can see what we do, which means mimicking the sense of human vision. This is especially important as we develop more complex AI systems that are more human-like in their abilities.
On That Note. . . How Do Self-Driving Cars Work?
Computer Vision Examples
Computer vision is often used in everyday life and its applications range from simple to very complex.
Optical character recognition (OCR) was one of the most widespread applications of computer vision. The most well-known case of this today is Google’s Translate , which can take an image of anything — from menus to signboards — and convert it into text that the program then translates into the user’s native language. We can also apply OCR in other use cases such as automated tolling of cars on highways and translating hand-written documents into digital counterparts.
A more recent application, which is still under development and will play a big role in the future of transportation, is object recognition. In object recognition an algorithm takes an input image and searches for a set of objects within the image, drawing boundaries around the object and labelling it. This application is critical in self-driving cars which need to quickly identify its surroundings in order to decide on the best course of action.
Computer Vision Applications
- Facial recognition
- Self-driving cars
- Robotic automation
- Medical anomaly detection
- Sports performance analysis
- Manufacturing fault detection
- Agricultural monitoring
- Plant species classification
- Text parsing
What Are the Risks of Computer Vision?
As with all technology, computer vision is a tool, which means that it can have benefits, but also risks. Computer vision has many applications in everyday life that make it a useful part of modern society but recent concerns have been raised around privacy. The issue that we see most often in the media is around facial recognition. Facial recognition technology uses computer vision to identify specific people in photos and videos. In its lightest form it’s used by companies such as Meta or Google to suggest people to tag in photos, but it can also be used by law enforcement agencies to track suspicious individuals. Some people feel facial recognition violates privacy, especially when private companies may use it to track customers to learn their movements and buying patterns.
Built In’s expert contributor network publishes thoughtful, solutions-oriented stories written by innovative tech professionals. It is the tech industry’s definitive destination for sharing compelling, first-person accounts of problem-solving on the road to innovation.
Great Companies Need Great People. That's Where We Come In.
- Skip to primary navigation
- Skip to main content
- Skip to primary sidebar
- Skip to footer
PyImageSearch
You can master Computer Vision, Deep Learning, and OpenCV - PyImageSearch
Book Examples of Image Search Engines Image Search Engine Basics Tutorials
Announcing “Case Studies: Solving real world problems with computer vision”
by Adrian Rosebrock on June 26, 2014

I have some big news to announce today…
Besides writing a ton of blog posts about computer vision, image processing, and image search engines, I’ve been behind the scenes, working on a second book .
And you may be thinking, hey, didn’t you just finish up Practical Python and OpenCV ?
Yep. I did.
Now, don’t get me wrong. The feedback for Practical Python and OpenCV has been amazing. And it’s done exactly what I thought it would — teach developers, programmers, and students just like you the basics of computer vision in a single weekend .
But now that you know the fundamentals of computer vision and have a solid starting point, it’s time to move on to something more interesting…
Let’s take your knowledge of computer vision and solve some actual, real world problems .
What type of problems?
I’m happy you asked. Read on and I’ll show you.
What does this book cover?
This book covers five main topics related to computer vision in the real world. Check out each one below, along with a screenshot of each.
#1. Face detection in photos and video

By far, the most requested tutorial of all time on this blog has been “How do I find faces in images?” If you’re interested in face detection and finding faces in images and video, then this book is for you.
#2. Object tracking in video
Another common question I get asked is “How can I track objects in video?” In this chapter, I discuss how you can use the color of an object to track its trajectory as it moves in the video.
#3. Handwriting recognition with Histogram of Oriented Gradients (HOG)

This is probably my favorite chapter in the entire Case Studies book, simply because it is so practical and useful .
Imagine you’re at a bar or pub with a group of friends, when all of a sudden a beautiful stranger comes up to you and hands you their phone number written on a napkin.
Do you stuff the napkin in your pocket, hoping you don’t lose it? Do you take out your phone and manually create a new contact?
Well you could. Or. You could take a picture of the phone number and have it automatically recognized and stored safely.
In this chapter of my Case Studies book, you’ll learn how to use the Histogram of Oriented Gradients (HOG) descriptor and Linear Support Vector Machines to classify digits in an image.
#4. Plant classification using color histograms and machine learning

A common use of computer vision is to classify the contents of an image . In order to do this, you need to utilize machine learning. This chapter explores how to extract color histograms using OpenCV and then train a Random Forest Classifier using scikit-learn to classify the species of a flower.
#5. Building an Amazon.com book cover search

Three weeks ago, I went out to have a few beers with my friend Gregory, a hot shot entrepreneur in San Francisco who has been developing a piece of software to instantly recognize and identify book covers — using only an image. Using this piece of software, users could snap a photo of books they were interested in, and then have them automatically added to their cart and shipped to their doorstep — at a substantially cheaper price than your standard Barnes & Noble!
Anyway, I guess Gregory had one too many beers, because guess what?
He clued me in on his secrets.
Gregory begged me not to tell…but I couldn’t resist.
In this chapter you’ll learn how to utilize keypoint extraction and SIFT descriptors to perform keypoint matching.
The end result is a system that can recognize and identify the cover of a book in a snap…of your smartphone!
All of these examples are covered in detail, from front to back, with lots of code.
By the time you finish reading my Case Studies book, you’ll be a pro at solving real world computer vision problems.
So who is this book for?
This book is for people like yourself who have a solid foundation of computer vision and image processing. Ideally, you have already read through Practical Python and OpenCV and have a strong grasp on the basics (if you haven’t had a chance to read Practical Python and OpenCV , definitely pick up a copy ).
I consider my new Case Studies book to be the next logical step in your journey to learn computer vision.
You see, this book focuses on taking the fundamentals of computer vision, and then applying them to solve, actual real-world problems .
So if you’re interested in applying computer vision to solve real world problems, you’ll definitely want to pick up a copy.
Reserve your spot in line to receive early access
If you signup for my newsletter, I’ll be sending out previews of each chapter so you can get see first hand how you can use computer vision techniques to solve real world problems.
But if you simply can’t wait and want to lock-in your spot in line to receive early access to my new Case Studies eBook, just click here .
Sound good?
Sign-up now to receive an exclusive pre-release deal when the book launches.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

About the Author
Hi there, I’m Adrian Rosebrock, PhD. All too often I see developers, students, and researchers wasting their time, studying the wrong things, and generally struggling to get started with Computer Vision, Deep Learning, and OpenCV. I created this website to show you what I believe is the best possible way to get your start.
Previous Article:
Applying deep learning and a RBM to MNIST using Python
Next Article:
Super fast color transfer between images
Comment section.
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.
Similar articles
Saving key event video clips with opencv, opencv gamma correction, opencv eigenfaces for face recognition.

You can learn Computer Vision, Deep Learning, and OpenCV.
Get your FREE 17 page Computer Vision, OpenCV, and Deep Learning Resource Guide PDF. Inside you’ll find our hand-picked tutorials, books, courses, and libraries to help you master CV and DL.
- Deep Learning
- Dlib Library
- Embedded/IoT and Computer Vision
- Face Applications
- Image Processing
- OpenCV Install Guides
- Machine Learning and Computer Vision
- Medical Computer Vision
- Optical Character Recognition (OCR)
- Object Detection
- Object Tracking
- OpenCV Tutorials
- Raspberry Pi
Books & Courses
- PyImageSearch University
- FREE CV, DL, and OpenCV Crash Course
- Practical Python and OpenCV
- Deep Learning for Computer Vision with Python
- PyImageSearch Gurus Course
- Raspberry Pi for Computer Vision
- Get Started
- Privacy Policy
Access the code to this tutorial and all other 500+ tutorials on PyImageSearch
Enter your email address below to learn more about PyImageSearch University (including how you can download the source code to this post):
What's included in PyImageSearch University?
- Easy access to the code, datasets, and pre-trained models for all 500+ tutorials on the PyImageSearch blog
- High-quality, well documented source code with line-by-line explanations (ensuring you know exactly what the code is doing)
- Jupyter Notebooks that are pre-configured to run in Google Colab with a single click
- Run all code examples in your web browser — no dev environment configuration required!
- Support for all major operating systems (Windows, macOS, Linux, and Raspbian)
- Full access to PyImageSearch University courses
- Detailed video tutorials for every lesson
- Certificates of Completion for all courses
- New courses added every month! — stay on top of state-of-the-art trends in computer vision and deep learning
PyImageSearch University is really the best Computer Visions "Masters" Degree that I wish I had when starting out. Being able to access all of Adrian's tutorials in a single indexed page and being able to start playing around with the code without going through the nightmare of setting up everything is just amazing. 10/10 would recommend. Sanyam Bhutani Machine Learning Engineer and 2x Kaggle Master
What Is Computer Vision and How It Works

We perceive and interpret visual information from the world around us automatically. So implementing computer vision might seem like a trivial task. But is it really that easy to artificially model a process that took millions of years to evolve?
Read this post if you want to learn more about what is behind computer vision technology and how ML engineers teach machines to see things.
- What is computer vision?
Computer vision is a field of artificial intelligence and machine learning that studies the technologies and tools that allow for training computers to perceive and interpret visual information from the real world.
‘Seeing’ the world is the easy part: for that, you just need a camera. However, simply connecting a camera to a computer is not enough. The challenging part is to classify and interpret the objects in images and videos, the relationship between them, and the context of what is going on. What we want computers to do is to be able to explain what is in an image, video footage, or real-time video stream.
That means that the computer must effectively solve these three tasks:
- Automatically understand what the objects in the image are and where they are located.
- Categorize these objects and understand the relationships between them.
- Understand the context of the scene.
In other words, a general goal of this field is to ensure that a machine understands an image just as well or better than a human. As you will see later on, this is quite challenging.
How does computer vision work?
In order to make the machine recognize visual objects, it must be trained on hundreds of thousands of examples. For example, you want someone to be able to distinguish between cars and bicycles. How would you describe this task to a human?
Normally, you would say that a bicycle has two wheels, and a machine has four. Or that a bicycle has pedals, and the machine doesn’t. In machine learning, this is called feature engineering .
.png "computer vision problem solving")
However, as you might already notice, this method is far from perfect. Some bicycles have three or four wheels, and some cars have only two. Also, motorcycles and mopeds exist that can be mistaken for bicycles. How will the algorithm classify those?
When you are building more and more complicated systems (for example, facial recognition software) cases of misclassification become more frequent. Simply stating the eye or hair color of every person won’t do: the ML engineer would have to conduct hundreds of measurements like the space between the eyes, space between the eye and the corners of the mouth, etc. to be able to describe a person’s face.
Moreover, the accuracy of such a model would leave much to be desired: change the lighting, face expression, or angle and you have to start the measurements all over again.
Here are several common obstacles to solving computer vision problems.
- Different lighting
For computer vision, it is very important to collect knowledge about the real world that represents objects in different kinds of lighting. A filter might make a ball look blue or yellow while in fact it is still white. A red object under a red lamp becomes almost invisible.
.png "computer vision problem solving")
If the image has a lot of noise, it is hard for computer vision to recognize objects. Noise in computer vision is when individual pixels in the image appear brighter or darker than they should be. For example, videocams that detect violations on the road are much less effective when it is raining or snowing outside.
- Unfamiliar angles
It’s important to have pictures of the object from several angles. Otherwise, a computer won’t be able to recognize it if the angle changes.

- Overlapping
When there is more than one object on the image, they can overlap. This way, some characteristics of the objects might remain hidden, which makes it even more difficult for the machine to recognize them.
- Different types of objects
Things that belong to the same category may look totally different. For example, there are many types of lamps, but the algorithm must successfully recognize both a nightstand lamp and a ceiling lamp.

- Fake similarity
Items from different categories can sometimes look similar. For example, you have probably met people that remind you of a celebrity on photos taken from a certain angle but in real life not so much. Cases of misrecognition are common in CV. For example, samoyed puppies can be easily mistaken for little polar bears in some pictures.
It’s almost impossible to think about all of these cases and prevent them via feature engineering. That is why today, computer vision is almost exclusively dominated by deep artificial neural networks.
Convolutional neural networks are very efficient at extracting features and allow engineers to save time on manual work. VGG-16 and VGG-19 are among the most prominent CNN architectures. It is true that deep learning demands a lot of examples but it is not a problem: approximately 657 billion photos are uploaded to the internet each year!
- Uses of computer vision

Interpreting digital images and videos comes in handy in many fields. Let us look at some of the use cases:
Medical diagnosis. Image classification and pattern detection are widely used to develop software systems that assist doctors with the diagnosis of dangerous diseases such as lung cancer. A group of researchers has trained an AI system to analyze CT scans of oncology patients. The algorithm showed 95% accuracy, while humans – only 65%.
Factory management. It is important to detect defects in the manufacture with maximum accuracy, but this is challenging because it often requires monitoring on a micro-scale. For example, when you need to check the threading of hundreds of thousands of screws. A computer vision system uses real-time data from cameras and applies ML algorithms to analyze the data streams. This way it is easy to find low-quality items.
Retail. Amazon was the first company to open a store that runs without any cashiers or cashier machines. Amazon Go is fitted with hundreds of computer vision cameras. These devices track the items customers put in their shopping carts. Cameras are also able to track if the customer returns the product to the shelf and removes it from the virtual shopping cart. Customers are charged through the Amazon Go app, eliminating any necessity to stay in the line. Cameras also prevent shoplifting and prevent being out of product.
Security systems. Facial recognition is used in enterprises, schools, factories, and, basically, anywhere where security is important. Schools in the United States apply facial recognition technology to identify sex offenders and other criminals and reduce potential threats. Such software can also recognize weapons to prevent acts of violence in schools. Meanwhile, some airlines use face recognition for passenger identification and check-in, saving time and reducing the cost of checking tickets.
Animal conservation. Ecologists benefit from the use of computer vision to get data about the wildlife, including tracking the movements of rare species, their patterns of behavior, etc., without troubling the animals. CV increases the efficiency and accuracy of image review for scientific discoveries.
Self-driving vehicles. By using sensors and cameras, cars have learned to recognize bumpers, trees, poles, and parked vehicles around them. Computer vision enables them to freely move in the environment without human supervision.
Main problems in computer vision

Computer vision aids humans across a variety of different fields. But its possibilities for development are endless. Here are some fields that are yet to be improved and developed.
- Scene understanding
CV is good at finding and identifying objects. However, it experiences difficulties with understanding the context of the scene, especially if it’s non-trivial. Look at this image , for example. What do you think they are doing (don’t look at the URL!)?
You will immediately understand that these are children wearing cardboard boxes on their heads. It is not some sort of postmodern art that tries to expose the meaninglessness of school education. These children are watching a solar eclipse . But if you don’t have this context, you might never understand what’s going on. Artificial intelligence still feels like that in a vast majority of cases. To improve the situation, we would need to invent general artificial intelligence (i.e. AI whose problem-solving capabilities possibilities are more or less equal to that of a human and can be applied universally), but we are very far from doing that .
- Privacy issues
Computer vision has much to do with privacy since the systems for face recognition are being adopted by governments of different countries to promote national security. AI-powered cameras installed in the Moscow metro help catch criminals . Meanwhile, Chinese authorities profile Uyghur individuals (a Muslim ethnic minority) and single them out for tracking and incarceration. When facial recognition is everywhere, everything you do can be subject to policies and shaming. AI ethicists are still to figure out the consequences of omnipresent CV for public wellbeing.
Computer vision is an innovative field that uses the latest machine learning technologies to build software systems that assist humans across different fields. From retail to wildlife conservation, smart algorithms solve the problems of image classification and pattern recognition, sometimes even better than humans.
Want to learn more about technologies? Continue reading our blog and follow us on Twitter , Medium , or DEV for other exciting content.

What is Computer Vision and Machine Vision? A Guide for Beginners

We also filmed a fireside video covering lots of the " Intro to Computer Vision " content.
Computer vision has the potential to revolutionize the world. So far, computer vision has helped humans work toward solving lots of problems, like reducing traffic gridlock and monitoring environmental health .

Historically, in order to do computer vision, you've needed a really strong technical background. That is no longer the case. As the field of computer vision has matured, new layers of abstraction have become available. With help from tools like Roboflow, you can worry less about the engineering details and more on how computer vision can help you solve a specific problem.
After reading this post, you should have a good understanding of computer vision without a strong technical background and you should know the steps needed to solve a computer vision problem.
What is computer vision?
Computer vision is the ability for a computer to see and understand the physical world. With computer vision, computers can learn to identify, recognize, and pinpoint the position of objects.
Consider the following scenario: you want to take a drink from a glass of water. When you have this idea, multiple things happen that require use of visual skills:
- You have to recognize that the thing in front of you is a glass of water.
- You have to know where your arm and the glass are, then move your arm in the direction of the glass.
- You have to recognize when your hand is close enough to properly grab the glass.
- You have to know where your face is, then pick up the glass and move it toward your face.
Computer vision encompasses all of these same processes, but for computers!
Computer vision problems fall into a few different buckets. This is important because different problems are solved with different methods.
What is machine vision?
Machine vision is an application of computer vision in industrial use cases. Machine vision can be used for to detect defects, manage inventory, monitor stages of a production pipeline, ensure workers wear the appropriate PPE in controlled workplace settings, and more.
You will likely hear "machine vision" and "computer vision" used interchangeably, but in many cases people use "machine vision" to refer more specifically to industrial applications of computer vision. You can imagine this the relationship between machine and computer vision like nesting dolls. Machine vision is a more focused subset within computer vision.
Generally, both machine vision and computer vision are concerned with identifying, segmenting, tracking, or classifying features in images, and use the information gathered to perform a function (i.e. to slow down a production pipeline, to notify a manager of an issue, to log an event like a forklift entering a construction site).
What are the different types of computer vision problems?

There are six main types of computer vision problems, four of which are illustrated in the above image and detailed below. Let's talk about each of the main types of computer vision problem types, alongside examples of real-world problems that can be solved by each type of problem. These are:
Image Classification
Categorizing each image into one bucket. For example, if you had a stack of 100 images that each contain either one cat or one dog, then classification means predicting whether the image you hold is of a cat or a dog. In each image, there is only one object you care about labeling – your computer wouldn't identify that two dogs are in an image or that there's a cat and a dog – just that an image belongs in the "dog" bucket or the "cat" bucket.
A real-world example of classification is for security purposes : using video footage and computer vision to detect whether there is a potential intruder in the image. Below we show a different example: a VGG16 model correctly predicts a schoolbus.

Classification and Localization
Categorizing each image into one bucket and identifying where the object of interest is in the frame. For example, if you had a stack of 100 images that contain either one dog or one cat, then your computer would be able to identify whether the image contains a dog or cat and where in the image it is. In each image, there is only one object you care about labeling. In localization, the computer identifies where that object is using something called a bounding box .
A real-world example of classification+localization is scanning and detecting whether there is a leak in a pipeline and, if so, where that leak is. Another example is using computer vision to fight wildfires by detecting smoke and attempting to douse it with water from a drone before the fire gets out of control.
Object Detection
Identifying where an object of interest is, for any object of interest. For example, if you had a stack of 100 images and each is a family photo with pets, then your computer would identify where the humans and the pets were in each image. Images can contain any number of objects; they aren't limited to only one.
A real-world example of object detection is using computer vision to assess cancer by detecting red blood cells, white blood cells, and platelet levels.

Semantic Segmentation
Detecting the set of pixels belonging to a specific class of object. This is like object detection, but object detection places a bounding box around the object, while semantic segmentation tries to more closely identify each object by assigning every pixel into a class. This is a good solution for any computer vision problem that requires something more delicate or specific than a bounding box. The image below is an example of semantic segmentation.
A real-world example might be most medical imaging purposes – it isn't enough to put a bounding box around the heart or a lung, but instead we want to be able to isolate the heart from the lung with a fine boundary. This article is a fantastic deep dive into semantic segmentation and was inspiration for the real-world example mentioned.

Instance Segmentation
Very similar to semantic segmentation but differentiates between objects in the same class. In the image above, there appear to be three people and three bicycles. Semantic segmentation classifies each pixel into a class, so each pixel falls into the "person," "bicycle," or "background" bucket. With instance segmentation , we aim to differentiate between classes of objects (person, bicycle, background) and objects within each class – e.g. tell which pixel belongs to which person and which pixel belongs to which bicycle.
Keypoint Detection
Also called landmark detection, this is an approach that involves identifying certain keypoints or landmarks on an object and tracking that object. On the left side of the image below, notice that the stick-like image of the human is color-coded and important locations (these the the keypoints/landmarks!) are identified with a number. On the right-hand side of the image we notice that each human matches up with a similar stick. In keypoint detection, the computer attempts to identify those landmarks on each human. This article goes in more detail about keypoint detection .

How do I solve computer vision problems?
If you want your computer to help you solve any problem with data, you usually follow a series of steps. The same is true for computer vision problems, except the steps look a little different.

We'll walk through each of these steps, with the goal being that at the end of the process you know the steps needed to solve a computer vision problem as well as a good overview of computer vision.
Collect your data
In order to use data to solve a problem, you must gather data to do it! For computer vision, this data consists of pictures and/or videos. This can be as simple as taking pictures or videos on your phone, then uploading them to a service you can use. Roboflow allows you to easily create your own dataset by uploading directly from your computer. (Fun fact that makes computer vision with videos easier : videos are just pictures strung together in a specific order!)
Label images in your dataset
While the goal is to get computers to see the way we as humans see, computers understand images very differently! Check out this (very pixelated) picture of Abraham Lincoln below. On the left, you just see the picture. In the middle, you see the picture with numbers inside each pixel. Each number represents how light or dark a pixel is – the lighter the pixel, the higher the number. The right image is what the computer sees : the numbers corresponding to the colour of each pixel.
If your goal is to get your computer to understand what dogs look like, then the computer needs you to tell it which pixels correspond to a dog! This is where you label, or annotate, your image . Below is an image from a thermal infrared dataset that is actively being annotated. One bounding box is drawn around the person and a separate bounding box is drawn around the dog. This would be done by a human. (Since this image has more than one object and is using bounding boxes, we know that this image is being used for an object detection task!) These bounding boxes are being added via a tool called Microsoft VoTT , or Visual Object Tagging Tool .
That's not the only tool – you can annotate your images in Roboflow or use other tools like CVAT ( Computer Vision Annotation Tool ) or Roboflow's Upload API itself.
Once you've gathered the data and chosen your tool for labeling it, you start labeling! You should try to label as many images as you can, following best practices for labeling images . If you have more images than you can label, consider active learning strategies for more efficiently labeling images .
Organize your data
Have you worked on a team where multiple people are editing Google Docs – or worse, sending around Microsoft Word files? You and your team might run into similar issues when working with images. Perhaps you've asked your team to also gather images. If you have a lot of images – which is great when a model is being built! – it'll take a lot of time to sort and annotate them. In addition, you probably want to do EDA on your images (exploratory data analysis), like checking for missing values and making sure images were labeled correctly. This step might seem like one you can skip, but it's a vitally important one!
Process the data in your dataset
Before building the model that teaches your computer "how to see," there are some steps you can take that will make your model perform even better.
Image preprocessing includes steps you take to ensure uniformity in your images. If you have some grayscale images and some red/green/blue color images, you might convert them all to grayscale. If images are of different sizes, most models require all images to be of the same size. Splitting your data into training, validation, and testing sets also falls under the umbrella of image preprocessing.

You can also do something called image augmentation . This is a little bit different – it only affects the images that you use to train your model (teach your computer how to see).
Image augmentation makes small changes to your images so that your sample size (number of images) increases and so that your images are likelier to reflect real-world conditions .
For example, you can randomly change the orientation of your image. Say you take a picture of a truck on your phone. If the computer sees that exact image, it might recognize the truck. If the computer saw a similar image of a truck that was taken with someone's hand rotated by a couple of degrees, the computer may have a harder time recognizing the truck. Adding augmentation steps boosts your sample size by making copies of original images and then slightly perturbing them so that your model sees other perspectives.
Train a model based on your data
This is where your computer learns to see! There are many different computer vision models that you can build – including some object detection models and some image classification models . This often requires more expertise in programming and machine learning than we'll cover today.
At Roboflow, we've made available AutoML training to help you get models trained and deployed faster through rapid prototyping and stable deployment options "out-of-the-box." Alternatively, Roboflow has custom model architecture training options for those preferring to train on their own infrastructure, or customize their own model architectures.
Earlier, I used the example of you having a stack of 100 images that each contain either one cat or one dog. All "training" means is that our computer basically goes through those images over and over again, learning what it means for an image to have a dog or a cat in it. Hopefully we have enough images and the computer eventually learns enough so that it can see a picture of a dog it's never seen before, and recognize it as a dog – like my dog, Paddington, below!

There are a lot of different ways in which we can determine how well our computer has learned.
- For image classification problems, your standard classification metrics like accuracy or F1-score should suffice.
- When it comes to object detection , we prefer using mean average precision – and walk through our thought process why!
There are many different models that can be used for image problems, but the most common (and usually best performing!) is the convolutional neural network (CNN). If you choose to use a convolutional neural network, know that there are a lot of judgment calls that go into the model's architecture which will affect your computer's ability to see! Luckily for us, there are lots of pre-specified model architectures that tend to do pretty well for various computer vision problems.
Deploy your model into production
Training the model isn't quite the end – you probably want to use that model in the real world! In many cases the goal is to quickly generate predictions. In computer vision, we call that inference . (That's a little different from what inference means in statistics, but we won't go into that here.)
You might want to deploy your model to an app, so your computer can generate predictions in real time straight from your phone! You might want to deploy to some program on your computer, or to AWS, or to something internal to your team. We've already written in detail about one way to deploy a computer vision model here. If you're at least a little familiar with Python and APIs, this documentation on conducting inference in computer vision might be helpful!
- Inference - Object Detection
- Inference - Classification
- Inference - Instance Segmentation
- Inference - Semantic Segmentation
Display your model in action
You can get your custom applications up and running faster by using Roboflow's Python Package for computer vision , Hosted API, edge deployment , or iOS SDK options .
Want to take it a step further? If you or someone on your team is familiar with augmented reality technology like Google's ARCore or Apple's ARKit, then you can take your deployed model to the next level.
Regardless of what your next steps are, the work doesn't quite finish here! It's pretty well documented that models that work well on the images you give to it may end up working worse over time. ( We read some Google research about this model performance issue and described our takeaways .) However, we hope that you feel like you've achieved the goal we wrote at the beginning of this post:
Thanks for sticking with us this far! Let us know any additional questions or resources by reaching out via email or one of the social media platforms (find the buttons on the left-hand side of the screen) – and if you build anything involving computer vision, we'd love to see what you do!
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems . (Nov 23, 2020). What is Computer Vision and Machine Vision? A Guide for Beginners. Roboflow Blog: https://blog.roboflow.com/intro-to-computer-vision/
Discuss this Post
If you have any questions about this blog post, start a discussion on the Roboflow Forum .
Growth Manager @ Roboflow. Previously solved data science problems across finance, education, politics, and more. Passionate about teaching and empowering others to accomplish more.
Table of Contents
Getting started, what is openpose a guide for beginners., what is opencv a guide for beginners., what is object detection the ultimate guide., how to use labelme: a complete guide, resources to build computer vision applications faster, getting started with roboflow.
Top 4 Computer Vision Challenges & Solutions in 2024
Computer vision (CV) technology is revolutionizing many industries, including healthcare , retail, automotive, etc. As more companies invest in computer vision solutions, the global market is projected to multiply 9 times by 2026 to $2.4 Billion.
However, implementing computer vision in your business can be a challenging and expensive process, and improper preparation can lead to CV and AI project failure . Therefore, business managers need to be careful before initiating computer vision projects.
This article explores 4 challenges that business managers can face while implementing computer vision in their business and how they can overcome them to safeguard their investments and ensure maximum ROI. We also provide some examples in the recommendation sections
1. Poor data quality
You can work with an image data collection service to help you obtain high-quality visual datasets for your computer vision project.
Poor Quality
High-quality labeled and annotated datasets are the foundation of a successful computer vision system. In industries such as healthcare , where computer vision technology is being abundantly used, it is crucial to have high-quality data annotation , and labeling since the repercussions of inaccurate computer vision systems can be significantly damaging. For example, Many tools built to catch Covid-19 failed due to poor data quality.
Recommendations: Working with medical data annotation specialists can help mitigate this issue.
You can check our list of medical data annotation tools to choose the option that best suits your healthcare computer vision project needs.
Lack of training data
Collecting relevant and sufficient data can have various challenges . These challenges can lead to a lack of training data for computer vision systems. For example, gathering medical data is a challenge for data annotators. This is mainly due to the sensitivity and privacy aspects of healthcare data. Most medical images are either of a sensitive nature or are strictly private and are not shared by healthcare professionals and hospitals. Additionally, it is possible that the developers do not have the resources to collect sufficient data.
Recommendations: To ensure that you have adequate data to train your computer vision system, leverage outsourcing or crowdsourcing. This way, the burden of collecting data and ensuring its quality will be transferred to a third-party specialist, and you can focus on developing the computer vision model. You can also work with a video data collection service to obtain high-quality visual datasets for your CV project.
2. Inadequate hardware
Computer vision technology is implemented with a combination of software and hardware. To ensure the system’s effectiveness, a business needs to install high-resolution cameras, sensors, and bots. This hardware can be costly and, if suboptimal or improperly installed, can lead to blind spots and ineffective CV systems.
IoT-enabled sensors are also required in some CV systems; for example, a study presents the use of IoT-enabled flood monitoring sensors.
Recommendations
The following factors can be considered for effective CV hardware installation:
- The cameras are high-definition and provide the required frames per second (FPS) rate
- Cameras and sensors cover all surveillance areas
- The positioning covers all the objects of interest. For example, in a retail store, the camera should cover all the products on the shelf.
- All the devices are properly configured to avoid blind spots.
One good example of improper hardware for CV is Walmart’s shelf-scanning robots. Walmart recalled its shelf-scanning robots and finished the contract with the provider. Even though the CV system in the bots was working fine, the company found that customers might find them strange due to their size, and they found other more efficient ways.

On the other hand, Walmart-owned retail brand Sam’s club mounted new CV-enabled inventory scanning systems, made by Brain Corp, on its already operating autonomous floor cleaning robots. Sam’s club finds them more effective and plans on increasing the investment.
Another example is Noisy student , which is a semi-supervised learning approach developed by Google, that relies on convolutional neural networks (CNN) and 480 million parameters. Processes like these require heavy computer processing power.
Two of the most significant costs to consider before starting your computer vision project are:
- The hardware requirements of the project
- The costs of cloud computing
3. Weak planning for model development
Another challenge can be weak planning for creating the ML model that is deployed for the computer vision system. During the planning stage, executives tend to set overly ambitious targets, which are hard to achieve for the data science team.
Due to this, the business model:
- Does not meet business objectives
- Demands unrealistic computing power
- Becomes too costly
- Delivers insufficient accuracy and performance
To overcome such issues, it is important for business leaders to focus on:
- Creating a strong project plan by analyzing the business’s technological maturity levels
- Create a clear scope of the project with set objectives
- The ability to gather relevant data, purchase labeled datasets or gather synthetic data
- Consider the model training and deployment costs
- Examining existing success stories similar to your business.
4. Time shortage
During the planning phase of a computer vision project, business managers tend to focus overly on the model development stage. They fail to consider the extra time needed for:
- Setup, configuration, and calibration of the hardware, including cameras and sensors
- Collecting, cleaning, and labeling data
- Training and testing of the model
Failure to consider these tasks can create challenges and project delays
A study on companies developing AI models found that a significant number of companies have significantly exceeded the expected time for successful deployment.
Another recent study identified that 99% of computer vision project teams faced significant delays due to a multitude of reasons:
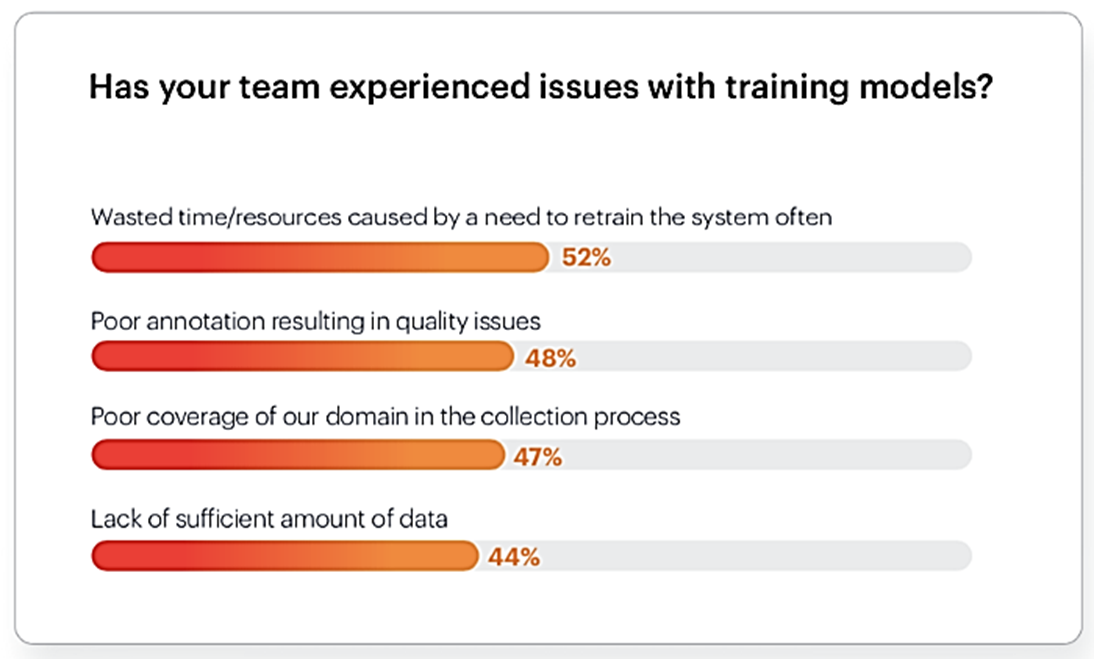
We recommend performing early calculations of each stage of the development process. If the project is time-constraint, then certain tasks, such as algorithm development or data collection, can be outsourced.
You can also check out our sortable and filterable lists of services, vendors, and tools to choose the option that best suits your business needs:
- Data Annotation / Labelling / Tagging / Classification Service
- Video Annotation Tools
- Medical Image Annotation Tools
Further reading
- Computer Vision In-Depth Guide
- Data Annotation: What it is & why does it matter?
- A Guide to Video Annotation Tools and Types
- Top 7 Computer Vision Use Cases in Healthcare
If you have any questions about challenges in computer vision, don’t hesitate to contact us:
Next to Read
Large vision models: examples, 7 use cases & challenges in 2024, computer vision in radiology in 2024: benefits & challenges, top 5 computer vision use cases in automotive in 2024.
Your email address will not be published. All fields are required.
Related research

Top 5 Computer Vision Best Practices in 2024

Top 5 Use Cases of Computer Vision in Retail in 2024
This is where the search bar goes
Solving real-world business problems with computer vision
Applications of CNNs for real-time image classification in the enterprise.

The process of data integration has traditionally been done using structured and semistructured data in batch-oriented use cases. In the last few years, real-time data has become the new frontier for many enterprises, and real-time streaming of unstructured or binary data has been a particularly tough nut to crack. In fact, many enterprises have large volumes of binary data that are not used to their full potential because of the inherent complexity of ingesting and processing such data.
Here are a few examples of how one might work with binary data :

Learn faster. Dig deeper. See farther.
Join the O'Reilly online learning platform. Get a free trial today and find answers on the fly, or master something new and useful.
- Performing speech-to-text recognition of audio files, recognizing individual speakers, and automatically cataloging files with enriched metadata so that audio recorded in interactive voice response systems is indexed and searchable.
- Automatically classifying image files based on the actual content of the image, such as recognizing products, faces, or other objects in the scene.
Of course, there are many other use cases. The good news is that working with binary data does not have to be that complicated. In this post, we’ll show how companies are using advances in computer vision, integrated with modern data ingestion technologies, to solve real-world business problems.
Applications of computer vision and deep learning in enterprise
The enterprise’s interest in machine vision techniques has ramped up sharply in the last few years due to the increased accuracy in competitions such as ImageNet . Computer vision methods have been around for decades, but it takes a certain level of accuracy for some use cases to move beyond the lab into real-world production applications. The advances seen in the ImageNet competition showed the world what was possible, and also harkened the rise of convolutional neural networks as the method of choice in computer vision.
Convolutional neural networks have the ability to learn location invariant features automatically by leveraging a network architecture that learns image features, as opposed to having them hand-engineered (as in traditional engineering). This aspect highlights a key property of deep learning networks—the ability of data scientists to choose the right architecture for the input data type so the network can automatically learn features. All of this is also directly dependent on having enough quality data that is properly labeled and appropriate for the problem at hand.
We’re seeing applications of computer vision across the spectrum of the enterprise:
- Financial Services
- Health care
In insurance, we see companies such as Orbital Insights analyzing satellite imagery to count cars and oil tank levels automatically to predict such things as mall sales and oil production, respectively. We are also seeing insurance companies leveraging computer vision to analyze the damage on assets under policy to better decide whom should be offered coverage.
The automotive industry has embraced computer vision (and deep learning) aggressively in the past five years with applications such as scene analysis, automated lane detection, and automated road sign reading to set speed limits.
The media world is leveraging computer vision to recognize images on social media to identify brands so companies can better position their brands around relevant content. Ebay recently used computer vision to let users visually search for items with photos.
In health care, we see the classic application of detecting disease in MRI scans, where companies like Arterys are now FDA-cleared to use deep learning to model medical imagery data. We’re also seeing this with partnerships, such as the relationship between Google, Nvidia, and Massachusetts General Hospital to leverage deep learning on radiology tasks.
In retail, we see companies interested in analyzing the shopping carts of in-store shoppers to detect items and make recommendations in store about what else they might want to buy. Think of this as a recommendation engine for a brick-and-mortar situation. We also see retailers using even more complex cameras taking more complex pictures (hyper-spectral imagery ) that are modeled with convolutional neural networks.
These are but a few examples of computer vision ideas that are in development or already in production across the Global 2000 enterprise. It seems like this deep learning stuff may be around for awhile.
Beyond convolutional neural networks, the automotive industry has leveraged deep learning and long-short-term memory networks to analyze sensor data to automatically detect other cars and objects around the car. On newer cars, if you try and change lanes on the highway without setting your turn signal, the car will correct you, automatically directing you back into your lane. James Long shared with us this anecdote on how he sees integrated machine learning as a force multiplier, as opposed to job replacement:
My father had auto-steer on his tractor for years. It allowed him to cover more ground and do a better job at higher speed—so maybe 20% more productive. That’s how robots will permeate.
It’s small examples like this that show how latent integrated intelligence in vehicles is slowly making them “progressively automated”—as opposed to the idea that all cars will be self-driving tomorrow. Deep learning is quickly becoming the standard platform for integrating automation and intelligence into the environment around us. We probably won’t turn on a complete self-driving car tomorrow; it will likely be a slow transition, to the point where the system progressively autocorrects more and more aspects of driving, and we just naturally stop wanting to drive manually.
Challenges of production deep learning
Computer vision and deep learning present challenges when going into production. These challenges include:
- Getting enough data of good quality
- Managing executives’ expectations about model performance
- Being pragmatic about how bleeding-edge we really need our network to be
- Planning data ingest, storage, security, and overall infrastructure
- Understanding how machine learning differs from software engineering, to avoid misaligned expectations
Most organizations do not collect enough quality data to produce the model their line of business wants in terms of accuracy (e.g., “Our model has an F1 of .80, but the line of business says the F1 has to be .95 to be financially viable to them”). The computer vision practitioner needs to understand the dynamics of model evaluation and how F1 scores , precision, and recall work in practice. This knowledge will allow the practicing data scientist to better communicate realistic expectations about the model performance to management and not set the project up for failure out of the gate.
Building off the concept of model training, we want to further delineate the training phase of machine learning from the inference phase of machine learning. In training, we are performing a batch-class operation, where we typically make multiple passes over a data set to build up the weights (or “parameters”) on the connections in the neural network model. This operation tends to happen on a single machine (with CPU or GPU, depending on situation) or on a cluster of machines (e.g., Hadoop with Spark). The training process can take anywhere from a few minutes to days to complete, and sometimes we’ll build the model multiple times to get the most accurate model for our input data. Making predictions (“inference”) based on the model produced from the training phase is different in terms of how we manage its execution. Sending a new record to a saved model and getting a prediction (e.g., “classification” or “regression”) output is a transactional class operation. We call this phase out separately in the context of an article on real-time streaming applications, as we want to make sure the reader understands that models are rarely trained inside a streaming system. Most of the time, the model is produced offline based on saved training data and then set up later in a way that a streaming system can make predictions transactionally as data flows into the system.
Another challenge for the enterprise is getting machine learning teams trained correctly to understand how to leverage the latest methods in convolutional network tuning and application. Most education sources are too academic for enterprise practitioners and are meant for a college classroom. While that is a good way to teach grad school students, enterprise software training courses often approach teaching material from a practitioner’s point of view.
Another tip for enterprises is to focus on leveraging good, tried-and-true convolutional architectures from the past few years, as opposed to trying to implement the “hot new ICML paper of the week.” Twitter is great for discovering new papers as they come out, but it can also encourage folks to jump from one hot idea to the next before they can actually leverage real production value from new networks. A pragmatic computer vision approach focuses on using networks that have good results and that are implemented on well-known deep learning libraries, such as deeplearning4j, TensorFlow, Keras, and Theano. Once you have established a baseline convolutional model that performs decently, deploy it to users/applications and then, while they are working against that model, you can try out newer architectures in parallel.
Data ingestion has long been a challenge for the enterprise. While it may seem simple on the surface, getting image data from here to there consistently and stored correctly is more work than it seems. Hurdles include the structure of the data, the rate of data ingest, and the overall infrastructure needs relative to the incoming data. Some marketing literature even uses the term “unstructured data,” which is a misnomer. Image data, and all data, has structure. Data that has no structure is unparseable and therefore unusable in a processing system. Most of the time, what people mean when they say “unstructured data” is that “it doesn’t look like a CSV file or a RDBMS table.” Ingest systems can also involve real-time tagging of images as they are ingested, helping us to understand if we have certain images as soon as they are ingested or serving an image detection system. Beyond ingest, companies should also consider their storage options, parallelization, GPU strategy, model serving, workflow management, and security implications. These factors are largely infrastructure-based but have direct impacts on our ability to take a computer vision model to production, regardless of how accurate the model is.
So often we hear customers talk about a fear of failure of data science projects because there is a large element of “the unknown” involved. Data science and deep learning are exploratory in nature, and it is hard to predict just how accurate a model can be on the front end by the input data we have. Many folks tend to conflate the idea of software engineering being fairly (within reason) deterministic (e.g., “We built a house out of these materials”) and data science having a wider range of outcomes with the same labor (e.g., “We mined for gold as long as the other team, but only found half as much gold on our land”). A best practice is to invest in the best possible infrastructure that builds, secures, and deploys our model in a way that IT can consume, then let the data science team focus on building as many models as possible to find the best one for the task at hand.
In this post, we’ve discussed the concepts of streaming technology and enterprise applications of computer vision. To learn in more detail how to implement convolutional neural networks into enterprise applications, see our post “ Integrating convolutional neural networks into enterprise pplications .” And, to hear more about applied machine learning in the context of streaming data infrastructure, attend our session Real-time image classification: Using convolutional neural networks on real-time streaming data ” at the Strata Data Conference in New York City, Sept. 25-28, 2017 .
For more information on the technologies mentioned in this article, email Josh ( [email protected] ) or Kirit ( [email protected] ).
Get the O’Reilly Radar Trends to Watch newsletter
Tracking need-to-know trends at the intersection of business and technology.
Please read our privacy policy .
Thank you for subscribing.
Minimal Problems in Computer Vision
This page provides a list of papers, software, data, and evaluations for solving minimal problems in computer vision, which is concerned with finding parameters of (geometrical) models from as small (minimal) data sets by solving systems of algebraic equations.
Please send links to papers that should be listed here to Tomas Pajdla ([email protected]) or Zuzana Kukelova ([email protected]).
IMAGES
VIDEO
COMMENTS
Selecting an inadequate model architecture is another common computer vision problem that can be attributed to many factors. They affect the overall performance, efficiency, and applicability of the model for specific computational tasks. Let us discuss some of the common causes of poor model architecture selection.
While computer vision tasks cover a wide breadth of perception capabilities and the list continues to grow, the latest techniques support and help solve use cases involving detection, classification, segmentation, and image synthesis. Detection tasks locate, and sometimes track, where an object exists in an image.
Sep 13, 2017. 3. At least for about a decade now, there have been drastic improvements in the techniques used for solving problems in the domain of computer vision, some of the notable problems ...
The field of computer vision is shifting from statistical methods to deep learning neural network methods. There are still many challenging problems to solve in computer vision. Nevertheless, deep learning methods are achieving state-of-the-art results on some specific problems. It is not just the performance of deep learning models on benchmark problems that is most interesting; it is the ...
A Gentle Introduction to Computer Vision. Computer Vision, often abbreviated as CV, is defined as a field of study that seeks to develop techniques to help computers "see" and understand the content of digital images such as photographs and videos. The problem of computer vision appears simple because it is trivially solved by people, even ...
DiCarlo and others previously found that when such deep-learning computer vision systems establish efficient ways to solve visual problems, they end up with artificial circuits that work similarly to the neural circuits that process visual information in our own brains. That is, they turn out to be surprisingly good scientific models of the ...
Computer vision is a field of artificial intelligence (AI) that applies machine learning to images and videos to understand media and make decisions about them. ... It is the tech industry's definitive destination for sharing compelling, first-person accounts of problem-solving on the road to innovation. Learn More. Great Companies Need Great ...
Machine learning provided a different approach to solving computer vision problems. With machine learning, developers no longer needed to manually code every single rule into their vision applications. Instead they programmed "features," smaller applications that could detect specific patterns in images. They then used a statistical ...
A common use of computer vision is to classify the contents of an image. In order to do this, you need to utilize machine learning. This chapter explores how to extract color histograms using OpenCV and then train a Random Forest Classifier using scikit-learn to classify the species of a flower. #5.
Here are several common obstacles to solving computer vision problems. Different lighting. For computer vision, it is very important to collect knowledge about the real world that represents objects in different kinds of lighting. A filter might make a ball look blue or yellow while in fact it is still white. A red object under a red lamp ...
To solve these problems, they introduced the inception — the layers of CNN architecture. It manages to increase the depth and width of the network while keeping the computing budget constant. The inception layers are repeated multiple times and formed GoogLeNet, a 22-layer deep model. ... They commented in their paper "computer vision is ...
It's the same problem with Computer Vision. To solve the problem, we need to use a lot of pictures of clothing, shoes, and handbags and tell the computer what's that picture is, and then have ...
The same is true for computer vision problems, except the steps look a little different. A seven-step process for solving computer vision problems. We'll walk through each of these steps, with the goal being that at the end of the process you know the steps needed to solve a computer vision problem as well as a good overview of computer vision ...
Two of the most significant costs to consider before starting your computer vision project are: The hardware requirements of the project. The costs of cloud computing. 3. Weak planning for model development. Another challenge can be weak planning for creating the ML model that is deployed for the computer vision system.
Figure 1. Solving regularized inverse problems in vision typically requires using iterative solvers like conjugate gradients. We solve the same type of problems via filtering for a speed-up. In this work, we solve regularized optimization problems of the form. minimize ( ) = + (1) ‖ − ‖2 2 ∗.
Most of the problems we need to solve in vision are ill-posed,in Hadamard's sense that a well-posedproblem must have the following set of properties: ... In many respects, computer vision is an "AI-complete" problem: building general-purpose vision machines would entail, or require, solutions to most of the general goals of artificial ...
Viso Suite provides an extensive set of features to reduce the complexity of computer vision at every step of your development cycle. Here are 5 ways that Viso Suite will use to overcome the challenges: Visual Programming: Use a visual approach to build complex computer vision and deep learning solutions on the fly.
Computer vision syndrome is a type of eye strain that happens when you spend a lot of time using computers, smartphones or other digital devices. Symptoms include dry, irritated eyes, blurry vision and headaches. Treatment focuses on lubricating your eyes, correcting vision errors and adjusting your posture when using digital devices.
The good news is that working with binary data does not have to be that complicated. In this post, we'll show how companies are using advances in computer vision, integrated with modern data ingestion technologies, to solve real-world business problems. Applications of computer vision and deep learning in enterprise
These images are later analyzed and defects can be scored. A person can later go through and triage the most important projects. 9. Detecting parasites on salmon. Salmon ocean-farms are using AI and computer vision to detect parasites on salmon and directing low energy lasers to "zap" the parasites from the salmon.
Polynomial eigenvalue solutions to minimal problems in computer vision: Z. Kukelova, M. Bujnak, T. Pajdla: IEEE Transactions on Pattern Analysis and Machine Intelligence,34(7):1381-1393, 2012 ... Using Sparse Elimination for Solving Minimal Problems in Computer Vision: J. Heikkila: ICCV 2017: 2017 : Resultant: Polynomial Solvers for Saturated ...
This projective framework is crucial to solve large-scale bundle adjustment problem without initialization. Using the real-world BAL dataset, we experimentally demonstrate that our solver achieves state-of-the-art results in terms of speed and accuracy. ... Computer Vision and Pattern Recognition (cs.CV) Cite as: arXiv:2405.05079 [cs.CV] (or ...
Most of the problems QCs excel on frequently occur in multitude of computer vision applications. Thus, QCs have a large, perhaps unprecedented potential in computer vision to challenge scenarios where existing methods would provide only approximate solutions or would not be able to solve problems in reasonable time at all.