
Sentiment analysis, or opinion mining, is the process of analyzing large volumes of text to determine whether it expresses a positive sentiment, a negative sentiment or a neutral sentiment.
Companies now have access to more data about their customers than ever before, presenting both an opportunity and a challenge: analyzing the vast amounts of textual data available and extracting meaningful insights to guide their business decisions.
From emails and tweets to online survey responses, chats with customer service representatives and reviews, the sources available to gauge customer sentiment are seemingly endless. Sentiment analysis systems help companies better understand their customers, deliver stronger customer experiences and improve their brand reputation.
Discover the power of integrating a data lakehouse strategy into your data architecture, including enhancements to scale AI and cost optimization opportunities.
With more ways than ever for people to express their feelings online, organizations need powerful tools to monitor what’s being said about them and their products and services in near real time. As companies adopt sentiment analysis and begin using it to analyze more conversations and interactions, it will become easier to identify customer friction points at every stage of the customer journey.
Deliver more objective results from customer reviews
The latest artificial intelligence (AI) sentiment analysis tools help companies filter reviews and net promoter scores (NPS) for personal bias and get more objective opinions about their brand, products and services. For example, if a customer expresses a negative opinion along with a positive opinion in a review, a human assessing the review might label it negative before reaching the positive words. AI-enhanced sentiment classification helps sort and classify text in an objective manner, so this doesn’t happen, and both sentiments are reflected.
Achieve greater scalability of business intelligence programs
Sentiment analysis enables companies with vast troves of unstructured data to analyze and extract meaningful insights from it quickly and efficiently. With the amount of text generated by customers across digital channels, it’s easy for human teams to get overwhelmed with information. Strong, cloud-based, AI-enhanced customer sentiment analysis tools help organizations deliver business intelligence from their customer data at scale, without expending unnecessary resources.
Perform real-time brand reputation monitoring
Modern enterprises need to respond quickly in a crisis. Opinions expressed on social media, whether true or not, can destroy a brand reputation that took years to build. Robust, AI-enhanced sentiment analysis tools help executives monitor the overall sentiment surrounding their brand so they can spot potential problems and address them swiftly.
Sentiment analysis uses natural language processing (NLP) and machine learning (ML) technologies to train computer software to analyze and interpret text in a way similar to humans. The software uses one of two approaches, rule-based or ML—or a combination of the two known as hybrid. Each approach has its strengths and weaknesses; while a rule-based approach can deliver results in near real-time, ML based approaches are more adaptable and can typically handle more complex scenarios.
Rule-based sentiment analysis
In the rule-based approach, software is trained to classify certain keywords in a block of text based on groups of words, or lexicons, that describe the author’s intent. For example, words in a positive lexicon might include “affordable,” “fast” and “well-made,” while words in a negative lexicon might feature “expensive,” “slow” and “poorly made”. The software then scans the classifier for the words in either the positive or negative lexicon and tallies up a total sentiment score based on the volume of words used and the sentiment score of each category.
Machine learning sentiment analysis
With a machine learning (ML) approach, an algorithm is used to train software to gauge sentiment in a block of text using words that appear in the text as well as the order in which they appear. Developers use sentiment analysis algorithms to teach software how to identify emotion in text similarly to the way humans do. ML models continue to “learn” from the data they are fed, hence the name “machine learning”. Here are a few of the most commonly used classification algorithms:
Linear regression: A statistics algorithm that describes a value (Y) based on a set of features (X).
Naive Bayes: An algorithm that uses Bayes’ theorem to categorize words in a block of text.
Support vector machines: A fast and efficient classification algorithm used to solve two-group classification problems.
Deep learning (DL): Also known as an artificial neural network, deep learning is an advanced machine learning technique that links together multiple algorithms to mimic human brain function.
The hybrid approach
A hybrid approach to text analysis combines both ML and rule-based capabilities to optimize accuracy and speed. While highly accurate, this approach requires more resources, such as time and technical capacity, than the other two.
In addition to the different approaches used to build sentiment analysis tools, there are also different types of sentiment analysis that organizations turn to depending on their needs. The three most popular types, emotion based, fine-grained and aspect-based sentiment analysis (ABSA) all rely on the underlying software’s capacity to gauge something called polarity, the overall feeling that is conveyed by a piece of text.
Generally speaking, a text’s polarity can be described as either positive, negative or neutral, but by categorizing the text even further, for example into subgroups such as “extremely positive” or “extremely negative,” some sentiment analysis models can identify more subtle and complex emotions. The polarity of a text is the most commonly used metric for gauging textual emotion and is expressed by the software as a numerical rating on a scale of one to 100. Zero represents a neutral sentiment and 100 represents the most extreme sentiment.
Here are the three most widely used types of sentiment analysis:
Fine-grained (graded)
Fine-grained, or graded, sentiment analysis is a type of sentiment analysis that groups text into different emotions and the level of emotion being expressed. The emotion is then graded on a scale of zero to 100, similar to the way consumer websites deploy star-ratings to measure customer satisfaction.
Aspect-based (ABSA)
Aspect based sentiment analysis (ABSA) narrows the scope of what’s being examined in a body of text to a singular aspect of a product, service or customer experience a business wishes to analyze. For example, a budget travel app might use ABSA to understand how intuitive a new user interface is or to gauge the effectiveness of a customer service chatbot. ABSA can help organizations better understand how their products are succeeding or falling short of customer expectations.
Emotional detection
Emotional detection sentiment analysis seeks to understand the psychological state of the individual behind a body of text, including their frame of mind when they were writing it and their intentions. It is more complex than either fine-grained or ABSA and is typically used to gain a deeper understanding of a person’s motivation or emotional state. Rather than using polarities, like positive, negative or neutral, emotional detection can identify specific emotions in a body of text such as frustration, indifference, restlessness and shock.
Organizations conduct sentiment analysis for a variety of reasons. Here are some of the most popular use cases.
Support teams use sentiment analysis to deliver more personalized responses to customers that accurately reflect the mood of an interaction. AI-based chatbots that use sentiment analysis can spot problems that need to be escalated quickly and prioritize customers in need of urgent attention. ML algorithms deployed on customer support forums help rank topics by level-of-urgency and can even identify customer feedback that indicates frustration with a particular product or feature. These capabilities help customer support teams process requests faster and more efficiently and improve customer experience.
By using sentiment analysis to conduct social media monitoring brands can better understand what is being said about them online and why. For example, is a new product launch going well? Monitoring sales is one way to know, but will only show stakeholders part of the picture. Using sentiment analysis on customer review sites and social media to identify the emotions being expressed about the product will enable a far deeper understanding of how it is landing with customers.
By turning sentiment analysis tools on the market in general and not just on their own products, organizations can spot trends and identify new opportunities for growth. Maybe a competitor’s new campaign isn’t connecting with its audience the way they expected, or perhaps someone famous has used a product in a social media post increasing demand. Sentiment analysis tools can help spot trends in news articles, online reviews and on social media platforms, and alert decision makers in real time so they can take action.
While sentiment analysis and the technologies underpinning it are growing rapidly, it is still a relatively new field. According to “Sentiment Analysis,” by Liu Bing (2020) the term has only been widely used since 2003. 1 There is still much to be learned and refined, here are some of the most common drawbacks and challenges.
Lack of context
Context is a critical component for understanding what emotion is being expressed in a block of text and one that frequently causes sentiment analysis tools to make mistakes. On a customer survey, for example, a customer might give two answers to the question: “What did you like about our app?” The first answer might be “functionality” and the second, “UX”. If the question being asked was different, for example, “What didn’t you like about our app?” it changes the meaning of the customer’s response without changing the words themselves. To correct this problem, the algorithm would need to be given the original context of the question the customer was responding to, a time-consuming tactic known as pre or post processing.
Use of irony and sarcasm
Regardless of the level or extent of its training, software has a hard time correctly identifying irony and sarcasm in a body of text. This is because often when someone is being sarcastic or ironic it’s conveyed through their tone of voice or facial expression and there is no discernable difference in the words they’re using. For example, when analyzing the phrase, “Awesome, another thousand-dollar parking ticket—just what I need,” a sentiment analysis tool would likely mistake the nature of the emotion being expressed and label it as positive because of the use of the word “awesome”.
Negation is when a negative word is used to convey a reversal of meaning in a sentence. For example, consider the sentence, “I wouldn’t say the shoes were cheap." What’s being expressed, is that the shoes were probably expensive, or at least moderately priced, but a sentiment analysis tool would likely miss this subtlety.
Idiomatic language
Idiomatic language, such as the use of—for example—common English phrases like “Let’s not beat around the bush,” or “Break a leg ,” frequently confounds sentiment analysis tools and the ML algorithms that they’re built on. When human language phrases like the ones above are used on social media channels or in product reviews, sentiment analysis tools will either incorrectly identify them—the “break a leg” example could be incorrectly identified as something painful or sad, for example—or miss them completely.
Organizations who decide they want to deploy sentiment analysis to better understand their customers have two options for how they can go about it: either purchase an existing tool or build one of their own.
Businesses opting to build their own tool typically use an open-source library in a common coding language such as Python or Java. These libraries are useful because their communities are steeped in data science. Still, organizations looking to take this approach will need to make a considerable investment in hiring a team of engineers and data scientists.
Acquiring an existing software as a service (SaaS) sentiment analysis tool requires less initial investment and allows businesses to deploy a pre-trained machine learning model rather than create one from scratch. SaaS sentiment analysis tools can be up and running with just a few simple steps and are a good option for businesses who aren’t ready to make the investment necessary to build their own.
Today’s most effective customer support sentiment analysis solutions use the power of AI and ML to improve customer experiences. IBM watsonx Assistant is a market leading, conversational artificial intelligence platform powered by large language models (LLMs) that enables organizations to build AI-powered voice agents and chatbots that deliver superior automated self-service support to their customers on a simple, easy-to-use interface.
Discover how artificial intelligence leverages computers and machines to mimic the problem-solving and decision-making capabilities of the human mind.
Gain a deeper understanding of machine learning along with important definitions, applications and concerns within businesses today.
Learn about the importance of mitigating bias in sentiment analysis and see how AI is being trained to be more neutral, unbiased and unwavering.
IBM watsonx Assistant helps organizations provide better customer experiences with an AI chatbot that understands the language of the business, connects to existing customer care systems, and deploys anywhere with enterprise security and scalability. watsonx Assistant automates repetitive tasks and uses machine learning to resolve customer support issues quickly and efficiently.
1 “Sentiment Analysis (Second edition)," (link resides outside ibm.com), Liu, Bing, Cambridge University Press, September 23, 2020

What is Sentiment Analysis? A Complete Guide for Beginners

Sentiment analysis lets you analyze the sentiment behind a given piece of text. In this article, we will look at how it works along with a few practical applications.
What is Sentiment Analysis?
Sentiment analysis is a technique through which you can analyze a piece of text to determine the sentiment behind it. It combines machine learning and natural language processing (NLP) to achieve this.
Using basic Sentiment analysis, a program can understand whether the sentiment behind a piece of text is positive, negative, or neutral.
It is a powerful technique in Artificial intelligence that has important business applications.
For example, you can use sentiment analysis to analyze customer feedback. After collecting that feedback through various mediums like Twitter and Facebook, you can run sentiment analysis algorithms on those text snippets to understand your customers' attitude towards your product.
How Sentiment Analysis Works
The simplest implementation of sentiment analysis is using a scored word list.
For example, AFINN is a list of words scored with numbers between minus five and plus five. You can split a piece of text into individual words and compare them with the word list to come up with the final sentiment score.
Let's say we had the phrase, "I love cats, but I am allergic to them".
In the AFINN word list, you can find two words, “love” and “allergic” with their respective scores of +3 and -2. You can ignore the rest of the words (again, this is very basic sentiment analysis).
By combining these two, you get a total score of +1. So you can classify this sentence as mildly positive.
There are complex implementations of sentiment analysis used in the industry today. Those algorithms can provide you with accurate scores for long pieces of text. Besides that, we have reinforcement learning models that keep getting better over time.
For complex models, you can use a combination of NLP and machine learning algorithms. There are three major types of algorithms used in sentiment analysis. Let's take a look at them.
Automated Systems
Automatic approaches to sentiment analysis rely on machine learning models like clustering.
Long pieces of text are fed into the classifier, and it returns the results as negative, neutral, or positive. Automatic systems are composed of two basic processes, which we'll look at now.
Rule-based Systems
Unlike automated models, rule-based approaches are dependent on custom rules to classify data. Popular techniques include tokenization, parsing, stemming, and a few others. You can consider the example we looked at earlier to be a rule-based approach.
A good thing about rule-based systems is the ability to customize them. These algorithms can be tailor-made based on context by developing smarter rules.
Just keep in mind that you will have to regularly maintain these types of rule-based models to ensure consistent and improved results.
Hybrid Systems
Hybrid techniques are the most modern, efficient, and widely-used approach for sentiment analysis. Well-designed hybrid systems can provide the benefits of both automatic and rule-based systems.
Hybrid models enjoy the power of machine learning along with the flexibility of customization. An example of a hybrid model would be a self-updating wordlist based on Word2Vec . You can track these wordlists and update them based on your business needs.
Use Cases for Sentiment Analysis
Analyzing customer feedback.

Customer feedback analysis is the most widespread application of sentiment analysis. Direct customer feedback is gold for businesses, especially startups. Accurate audience targeting is essential for the success of any type of business.
Well-made sentiment analysis algorithms can capture the core market sentiment towards a product.
You can also extend this use case for smaller sub-sections, like analyzing product reviews on your Amazon store. The more customer-driven a company is, the better sentiment analysis can be of service.
Campaign Monitoring

Manipulating voter emotions is a reality now, thanks to the Cambridge Analytica Scandal .
Another use-case of sentiment analysis is a measure of influence. Taking the 2016 US Elections as an example, many polls concluded that Donald Trump was going to lose.
But experts had noted that people were generally disappointed with the current system. They backed their claims with strong evidence through sentiment analysis.
I worked on a tool called Sentiments (Duh!) that monitored the US elections during my time as a Software Engineer at my former company. We noticed trends that pointed out that Mr. Trump was gaining strong traction with voters.
This should be evidence that the right data combined with AI can produce accurate results, even when it goes against popular opinion.
Brand Monitoring

Brand monitoring is another great use-case for sentiment analysis. Companies can use sentiment analysis to check the social media sentiments around their brand from their audience.
KFC is a perfect example of a business that uses sentiment analysis to track, build, and enhance its brand. KFC’s social media campaigns are a great contributing factor to its success. They tailor their marketing campaigns to appeal to the young crowd and to be “present” in social media.
Tools like Brandwatch can tell you if something negative about your brand is going viral. Other brands that use social media to promote a positive brand sentiment include Amazon, Netflix, and Dominoes.
Stock Market Analysis

If you are a trader or an investor, you understand the impact news can have on the stock market. Whenever a major story breaks, it is bound to have a strong positive or negative impact on the stock market.
Sentiment analysis is a powerful tool for traders. You can analyze the market sentiment towards a stock in real-time, usually in a matter of minutes. This can help you plan your long or short positions for a particular stock.
Recently, Moderna announced the completion of phase I of its COVID-19 vaccine clinical trials. This news resulted in a strong rise in the stock price of Moderna.
But today, Moderna’s stock stumbled after losing a patent. Using sentiment analysis, you can analyze these types of news in realtime and use them to influence your trading decisions.
Compliance Monitoring

Regulatory and legal compliance can make or break large organizations. Often, these compliance documents are stashed into large websites like Financial Conduct Authority .
Large organizations spend a good chunk of their budgets on regulatory compliance. In these cases, traditional data analytics cannot offer a complete solution.
Tools like ScrapingHub can help fetch documents from these websites. But companies need intelligent classification to find the right content among millions of web pages.
Sentiment analysis can make compliance monitoring easier and more cost-efficient. It can help build tagging engines, analyze changes over time, and provide a 24/7 watchdog for your organization.
Sentiment analysis is a powerful tool that you can use to solve problems from brand influence to market monitoring. New tools are built around sentiment analysis to help businesses become more efficient.
And by the way, if you love Grammarly, you can go ahead and thank sentiment analysis.
Loved this article? Join my Newsletter and get a summary of my articles and videos every Monday.
Cybersecurity & Machine Learning Engineer. Loves building useful software and teaching people how to do it. More at manishmshiva.com
If you read this far, thank the author to show them you care. Say Thanks
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
siebert / sentiment-roberta-large-english like 104
Siebert - english-language sentiment classification.
This model ("SiEBERT", prefix for "Sentiment in English") is a fine-tuned checkpoint of RoBERTa-large ( Liu et al. 2019 ). It enables reliable binary sentiment analysis for various types of English-language text. For each instance, it predicts either positive (1) or negative (0) sentiment. The model was fine-tuned and evaluated on 15 data sets from diverse text sources to enhance generalization across different types of texts (reviews, tweets, etc.). Consequently, it outperforms models trained on only one type of text (e.g., movie reviews from the popular SST-2 benchmark) when used on new data as shown below.
Predictions on a data set
If you want to predict sentiment for your own data, we provide an example script via Google Colab . You can load your data to a Google Drive and run the script for free on a Colab GPU. Set-up only takes a few minutes. We suggest that you manually label a subset of your data to evaluate performance for your use case. For performance benchmark values across various sentiment analysis contexts, please refer to our paper ( Hartmann et al. 2022 ).
Use in a Hugging Face pipeline
The easiest way to use the model for single predictions is Hugging Face's sentiment analysis pipeline , which only needs a couple lines of code as shown in the following example:
Use for further fine-tuning
The model can also be used as a starting point for further fine-tuning of RoBERTa on your specific data. Please refer to Hugging Face's documentation for further details and example code.
Performance
To evaluate the performance of our general-purpose sentiment analysis model, we set aside an evaluation set from each data set, which was not used for training. On average, our model outperforms a DistilBERT-based model (which is solely fine-tuned on the popular SST-2 data set) by more than 15 percentage points (78.1 vs. 93.2 percent, see table below). As a robustness check, we evaluate the model in a leave-one-out manner (training on 14 data sets, evaluating on the one left out), which decreases model performance by only about 3 percentage points on average and underscores its generalizability. Model performance is given as evaluation set accuracy in percent.
Fine-tuning hyperparameters
- learning_rate = 2e-5
- num_train_epochs = 3.0
- warmump_steps = 500
- weight_decay = 0.01
Other values were left at their defaults as listed here .
Citation and contact
Please cite this paper (Published in the IJRM ) when you use our model. Feel free to reach out to [email protected] with any questions or feedback you may have.
Spaces using siebert/sentiment-roberta-large-english 27
- How We Work
- Infographics
- UI/UX Design Services
- Microsoft Dynamics 365
- Mobile App Development
- AI Software Development
- Web App Development
- Generative AI Development
- Digital Product Development
- Enterprise Mobility
- SaaS Application Development
- Application Integration
- White-label WP Maintenance
- ERP Software Solutions
- Software Testing
- Offshore Development Center
- Let’s Connect
- Augmented Reality
- Internet Of Things
- Artificial Intelligence
- ASP.NET Core
- CodeIgniter
- React Native
- Real Estate
- Social Media
- Taxi Booking
- Travel & Tourism
- Full Stack Developers
- MEAN Stack Developers
- MERN Stack Developers
- Hire PWA Developer
- Hire API Developer
- MS Dynamics 365 Developers
- Android Developers
- iOS Developers
- Swift Developers
- Kotlin Developers
- Flutter Developers
- React Native Developers
- Ionic Developers
- ASP .NET Developers
- Java Developers
- PHP Developers
- Python Developers
- Node.js Developers
- Laravel Developers
- CodeIgniter Developers
- Spring Boot Developers
- React Developers
- Angular Developers
- Vue.js Developer
- Next.js Developers
- Shopify Developers
- WordPress Developers
- Woocommerce Developers

We use cookies and similar technologies that are necessary to operate the website. Additional cookies are used to perform analysis of website usage. please read our Privacy Policy
Sentiment Analysis: Definition, Process, Types, Use Cases, Challenges

Sentiment analysis, also known as opinion mining, is a powerful tool that uses artificial intelligence and natural language processing (NLP) to understand the emotional tone behind a piece of text. It goes beyond simply identifying keywords to analyze the context and intention of the language used.
This blog post serves as a comprehensive guide to sentiment analysis, exploring its various aspects and applications.
Table of Contents
What is Sentiment Analysis?
Sentiment analysis is the process of automatically identifying, classifying, and understanding the emotional tone within a piece of text. It categorizes the sentiment as positive, negative, or neutral. This analysis helps businesses understand the opinions and feelings expressed in various forms of textual data, such as:
- Social media posts and comments
- Online reviews
- Customer service interactions
- Surveys and feedback forms
How does sentiment analysis work?

Sentiment analysis works its magic through a combination of natural language processing (NLP) and machine learning. Here’s a breakdown of the process:
Data Preparation
The first step involves collecting the text data you want to analyze. This could be social media posts, customer reviews, survey responses, or any other form of written text. The data is then pre-processed to clean it up. This might involve removing irrelevant information like punctuation, symbols, and stop words (common words like “the” or “and”).
Feature Engineering
Next, the system extracts features from the text data that will help identify sentiment. These features can include:
- Lexicon-based analysis : This involves using dictionaries of positive and negative words. The system counts the occurrences of these words to gauge the overall sentiment.
- N-grams : These are sequences of words (phrases) that can be indicative of sentiment. For example, “terrible service” suggests negativity.
- Part-of-speech tagging : Identifying the parts of speech (nouns, verbs, adjectives) can help understand the context and sentiment of a sentence.
Machine Learning Algorithms
There are two main approaches to sentiment analysis using machine learning:
Rule-based systems : These are pre-programmed with a set of rules to identify sentiment based on keywords and phrases. While simpler to set up, they may not be as accurate for complex language.
Machine learning models : These models are trained on large datasets of text labeled with sentiment (positive, negative, or neutral). The models learn to identify patterns in language that correlate with sentiment. Common machine learning algorithms used include Support Vector Machines (SVMs) and Naïve Bayes.
Sentiment Classification
Once the features are extracted, the machine learning model classifies the text data into different sentiment categories. This could be a simple positive, negative, and neutral classification, or a more granular scale with varying degrees of sentiment.
Refining the Model
Sentiment analysis is an iterative process. The performance of the model is evaluated on a testing dataset. If the results aren’t accurate enough, the model can be further refined by adjusting the features, training data, or the machine learning algorithm itself.
What are the different types of sentiment analysis?

Businesses use different types of sentiment analysis to understand how their customers feel when interacting with products or services.
1. Fine-Grained Sentiment Analysis
This approach goes beyond a simple positive or negative label and assigns a more nuanced sentiment score on a scale. For example, a score might range from -5 (extremely negative) to +5 (extremely positive). This allows for a more granular understanding of sentiment intensity.
Examples : Analyzing customer reviews to understand varying degrees of satisfaction, gauging audience reaction to marketing campaigns, identifying strongly negative feedback that requires immediate attention.
2. Aspect-Based Sentiment Analysis
This method focuses on understanding sentiment towards specific aspects of a product, service, or topic. For instance, analyzing restaurant reviews to understand sentiment on food quality, service, and ambiance. It involves:
Entity Recognition : Identifying the aspects (e.g., “food”, “service”) being mentioned in the text. Sentiment Classification: Classifying the sentiment towards each identified aspect.
Examples : Analyzing product reviews to identify areas for improvement, understanding customer satisfaction with different features of a service, gauging public opinion on various aspects of a political candidate.
3. Intent-Based Sentiment Analysis
This approach goes beyond just the sentiment itself and tries to understand the underlying intent behind the text. For example, a customer service email might express frustration (negative sentiment) but still have a question requiring a response (informational intent). It involves:
Sentiment Classification : Identifying the overall sentiment of the text. Intent Classification: Classifying the purpose or goal behind the text (e.g., complaint, request for information, praise).
Examples : Classifying customer support tickets to route them appropriately, understanding the reasons behind product returns, identifying potential sales leads from social media interactions.
4. Emotional Detection
This type of sentiment analysis delves into the emotional state conveyed in the text. It goes beyond basic positive or negative sentiment and tries to identify specific emotions like joy, sadness, anger, or fear. This can be helpful in understanding the emotional tone of a conversation or the overall mood of a social media discussion.
Examples : Analyzing customer feedback to identify areas that trigger frustration or disappointment, understanding audience reaction to marketing campaigns on an emotional level, gauging the emotional sentiment in online communities.
Why is Sentiment Analysis Important?
Sentiment analysis is becoming a crucial tool in today’s world, where vast amounts of data are generated through online interactions. It helps us understand the feeling or opinion expressed in a piece of text, whether it’s a social media post, a customer review, or a survey response. Here’s why sentiment analysis is important:
Understanding Customer Needs:
Sentiment analysis allows businesses to analyze customer feedback from various sources like reviews, surveys, and social media. This helps them identify what makes customers happy or unhappy, leading to better products, services, and overall customer experience.
Market Research
By analyzing online conversations about products, brands, and industries, sentiment analysis provides valuable insights for market research. This helps businesses understand what people think about their products compared to competitors, and identify areas for improvement.
Brand Reputation Management
Social media is a powerful tool for brand sentiment. Businesses can leverage sentiment analysis to monitor brand mentions and identify potential crises. By addressing negative feedback quickly, they can protect their reputation and build stronger customer relationships.
Improved Decision Making
Data-driven decision making is essential for businesses. Sentiment analysis helps gather customer insights that can inform product development, marketing strategies, and business goals.
What are sentiment analysis use cases?

Social Media Monitoring
Companies can use sentiment analysis to track brand mentions across social media platforms. This helps them understand how people perceive their brand, identify emerging trends, and address any negative feedback promptly.
Customer Service Enhancement
By analyzing customer reviews and support tickets, businesses can gain insights into customer satisfaction. This helps them identify areas for improvement in their customer service processes and personalize their interactions with clients.
Product Development
Sentiment analysis of product reviews and social media discussions can provide valuable feedback on new features, identify areas for improvement in existing products, and gauge customer interest in potential product launches.
Analyzing online conversations about products, industries, and competitors can reveal valuable market research insights. Businesses can understand customer preferences, identify emerging trends, and make informed decisions about product development and marketing strategies.
Risk Management
Sentiment analysis can be used to identify potential crises by monitoring online sentiment towards a brand or product. Early detection allows businesses to take proactive measures to mitigate negative publicity and protect their reputation.
Political Campaigns
Political campaigns can leverage sentiment analysis to understand public opinion on various issues and tailor their messaging accordingly. This can help them connect better with voters and gain a competitive edge.
What are the approaches to sentiment analysis?
Sentiment analysis tackles the challenge of understanding opinions and emotions from textual data. There are three main approaches to achieve this:
1. Lexicon-Based Approach
This method relies on pre-built dictionaries containing words with sentiment associations. These dictionaries can be positive, negative, or neutral. Sentiment analysis assigns scores to words based on their presence in the dictionary and calculates an overall sentiment for the text.
Pros : Easy to implement, works well for basic sentiment analysis. Cons : Limited accuracy, struggles with sarcasm and negation (“not good”), overlooks context.
2. Machine Learning Approach
This approach leverages the power of machine learning algorithms to identify sentiment patterns. Here’s the workflow:
- Training Data : A large corpus of text data labeled with sentiment (positive, negative, neutral) is used to train the model.
- Feature Engineering : The system extracts features from the text data that are helpful for sentiment identification. This could include word n-grams (sequences of words), part-of-speech tags, and lexicon scores.
- Model Training : The machine learning model, like Naive Bayes or Support Vector Machines (SVMs), learns to recognize sentiment patterns in the training data.
- Sentiment Classification : Once trained, the model can classify new, unseen text data into sentiment categories.
Pros : Highly accurate for complex language, adaptable to specific domains with custom training data. Cons : Requires expertise and computational resources for training, ongoing maintenance to ensure accuracy.
3. Hybrid Approach
This approach combines the strengths of both lexicon-based and machine learning methods. It leverages pre-built sentiment lexicons while also using machine learning models to capture more nuanced sentiment and context.
Pros : Combines the strengths of both lexicon-based and machine learning approaches, offering more robust sentiment analysis. Cons : More complex to implement and maintain than the other two approaches.
What are the challenges in sentiment analysis?
Sentiment analysis, despite its advancements, isn’t without its challenges. Here are some key hurdles that sentiment analysis models need to overcome:
1. Context Dependence
The meaning and sentiment of a word can change depending on the context in which it’s used. For instance, “the movie was bad” is clearly negative, but “that exam was bad…but I passed!” uses “bad” in a positive light. Sentiment analysis models need to consider the surrounding text to understand the true sentiment.
2. Sarcasm and Negation
People often use sarcasm and negation to express themselves, which can confuse sentiment analysis tools. For example, saying “great job” with a sarcastic tone is actually negative. Similarly, “not bad” can be interpreted as positive or neutral depending on the context. Sentiment analysis models need to be able to detect and account for these complexities.
3. Multilingual Sentiment Analysis
Sentiment analysis often focuses on English, but understanding sentiment across different languages presents additional challenges. Languages have varying grammatical structures, slang terms, and cultural references that can impact sentiment interpretation.
4. Emojis and Non-Verbal Cues
Text analysis often overlooks emojis and other non-verbal cues that can convey emotions. A smiley face emoji can completely change the sentiment of a sentence. Sentiment analysis models are being developed to integrate these nonverbal cues for a more complete understanding.
5. Bias and Training Data
Sentiment analysis models are trained on large datasets of text labeled with sentiment. If the training data is biased, the model itself can inherit those biases and produce skewed results. It’s crucial to ensure balanced and representative training data for accurate sentiment analysis.
6. Limited Scope
Sentiment analysis primarily focuses on written text. It doesn’t take into account other factors that can influence sentiment, like facial expressions, tone of voice, or body language, which can provide a more complete picture of someone’s feelings.
Sentiment analysis plays a pivotal role in understanding public opinion, shaping business strategies, and improving customer experiences. By leveraging advanced NLP techniques and machine learning algorithms, organizations, including AI software development companies , can gain valuable insights from textual data to drive informed decision-making and improve overall sentiment towards their brand, products, and services. However, addressing challenges such as contextual ambiguity, data bias, and domain specificity remains crucial for the continued advancement of sentiment analysis technologies.
We are here
Our team is always eager to know what you are looking for. Drop them a Hi!
Select Country Aruba Afghanistan Angola Albania Andorra United Arab Emirates Argentina Armenia American Samoa Antigua and Barbuda Australia Austria Azerbaijan Burundi Belgium Benin Burkina Faso Bangladesh Bulgaria Bahrain Bahamas Bosnia and Herzegovina Belarus Belize Bermuda Bolivia, Plurinational State of Brazil Barbados Brunei Darussalam Bhutan Botswana Central African Republic Canada Switzerland Chile China Côte d’Ivoire Cameroon Congo, the Democratic Republic of the Congo Cook Islands Colombia Comoros Cape Verde Costa Rica Cuba Cayman Islands Cyprus Czech Republic Germany Djibouti Dominica Denmark Dominican Republic Algeria Ecuador Egypt Eritrea Spain Estonia Ethiopia Finland Fiji France Micronesia, Federated States of Gabon United Kingdom Georgia Ghana Guinea Gambia Guinea-Bissau Equatorial Guinea Greece Grenada Guatemala Guam Guyana Hong Kong Honduras Croatia Haiti Hungary Indonesia India Ireland Iran, Islamic Republic of Iraq Iceland Israel Italy Jamaica Jordan Japan Kazakhstan Kenya Kyrgyzstan Cambodia Kiribati Saint Kitts and Nevis Korea, Republic of Kuwait Lao People’s Democratic Republic Lebanon Liberia Libya Saint Lucia Liechtenstein Sri Lanka Lesotho Lithuania Luxembourg Latvia Morocco Monaco Moldova, Republic of Madagascar Maldives Mexico Marshall Islands Macedonia, the former Yugoslav Republic of Mali Malta Myanmar Montenegro Mongolia Mozambique Mauritania Mauritius Malawi Malaysia Namibia Niger Nigeria Nicaragua Netherlands Norway Nepal Nauru New Zealand Oman Pakistan Panama Peru Philippines Palau Papua New Guinea Poland Puerto Rico Korea, Democratic People’s Republic of Portugal Paraguay Palestine, State of Qatar Romania Russian Federation Rwanda Saudi Arabia Sudan Senegal Singapore Solomon Islands Sierra Leone El Salvador San Marino Somalia Serbia Sao Tome and Principe Suriname Slovakia Slovenia Sweden Swaziland Seychelles Syrian Arab Republic Chad Togo Thailand Tajikistan Turkmenistan Timor-Leste Tonga Trinidad and Tobago Tunisia Turkey Tuvalu Taiwan, Province of China Tanzania, United Republic of Uganda Ukraine Uruguay United States Uzbekistan Saint Vincent and the Grenadines Venezuela, Bolivarian Republic of Virgin Islands, U.S. Viet Nam Vanuatu Samoa Yemen South Africa Zambia Zimbabwe
100% confidential and secure

Pranjal Mehta
Pranjal Mehta is the Managing Director of Zealous System, a leading software solutions provider. Having 10+ years of experience and clientele across the globe, he is always curious to stay ahead in the market by inculcating latest technologies and trends in Zealous.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
A Complete Guide to Sentiment Analysis
“That movie was a colossal disaster… I absolutely hated it! Waste of time and money #skipit”
“Have you seen the new season of XYZ? It is so good!”
“You should really check out this new app, it’s awesome! And it makes your life so convenient.”
By reading these comments, can you figure out what the emotions behind them are?
They may seem obvious to you because we, as humans, are capable of discerning the complex emotional sentiments behind the text.
Not only have we been educated to understand the meanings, intentions, and grammar behind each of these particular sentences, but we’ve also personally felt many of these emotions before and, from our own experiences, can conjure up the deeper meaning behind these words.
Moreover, we’re also extremely familiar with the real-world objects that the text is referring to.
This doesn’t apply to machines, but they do have other ways of determining positive and negative sentiments! How do they do this, exactly? By using sentiment analysis. In this article, we will discuss how a computer can decipher emotions by using sentiment analysis methods, and what the implications of this can be. If you want to skip ahead to a certain section, simply use the clickable menu:
- What is sentiment analysis?
- How does sentiment analysis work?
- Sentiment analysis use cases
- Machine learning and sentiment analysis
- Advantages of sentiment analysis
- Disadvantages of sentiment analysis
- Key takeaways and next steps
1. What is sentiment analysis?
With computers getting smarter and smarter, surely they’re able to decipher and discern between the wide range of different human emotions, right?
Wrong—while they are intelligent machines, computers can neither see nor feel any emotions, with the only input they receive being in the form of zeros and ones—or what’s more commonly known as binary code.
However, on the other hand, computers excel at the one thing that humans struggle with: processing large amounts of data quickly and effectively. So, theoretically, if we could teach machines how to identify the sentiments behind the plain text, we could analyze and evaluate the emotional response to a certain product by analyzing hundreds of thousands of reviews or tweets.
This would, in turn, provide companies with invaluable feedback and help them tailor their next product to better suit the market’s needs. So, what kind of process is this? Sentiment analysis!
Sentiment analysis, also known as opinion mining , is the process of determining the emotions behind a piece of text. Sentiment analysis aims to categorize the given text as positive, negative, or neutral.
Furthermore, it then identifies and quantifies subjective information about those texts with the help of:
- natural language processing (NLP)
- text analysis
- computational linguistics
- machine learning
2. How does sentiment analysis work?
There are two main methods for sentiment analysis: machine learning and lexicon-based.
The machine learning method leverages human-labeled data to train the text classifier, making it a supervised learning method.
The lexicon-based approach breaks down a sentence into words and scores each word’s semantic orientation based on a dictionary. It then adds up the various scores to arrive at a conclusion.
In this example, we will look at how sentiment analysis works using a simple lexicon-based approach. We’ll take the following comment as our test data:
Step 1: Cleaning
The initial step is to remove special characters and numbers from the text. In our example, we’ll remove the exclamation marks and commas from the comment above.
That movie was a colossal disaster I absolutely hated it Waste of time and money skipit
Step 2: Tokenization
Tokenization is the process of breaking down a text into smaller chunks called tokens, which are either individual words or short sentences.
Breaking down a paragraph into sentences is known as sentence tokenization , and breaking down a sentence into words is known as word tokenization .
[ ‘That’, ‘movie’, ‘was’, ‘a’, ‘colossal’, ‘disaster’, ‘I’, ‘absolutely’, ‘hated’, ‘it’, ‘Waste’, ‘of’, ‘time’, ‘and’, ‘money’, ‘skipit’ ]
Step 3: Part-of-speech (POS) tagging
Part-of-speech tagging is the process of tagging each word with its grammatical group, categorizing it as either a noun, pronoun, adjective, or adverb—depending on its context.
This transforms each token into a tuple of the form (word, tag). POS tagging is used to preserve the context of a word.
[ (‘That’, ‘DT’),
(‘movie’, ‘NN’),
(‘was’, ‘VBD’),
(‘a’, ‘DT’)
(‘colossal’, ‘JJ’),
(‘disaster’, ‘NN’),
(‘I’, ‘PRP’),
(‘absolutely’, ‘RB’),
(‘hated’, ‘VBD’),
(‘it’, ‘PRP’),
(‘Waste’, ‘NN’) ,
(‘of’, ‘IN’),
(‘time’, ‘NN’),
(‘and’, ‘CC’),
(‘money’, ‘NN’),
(‘skipit’, ‘NN’) ]
Step 4: Removing stop words
Stop words are words like ‘have,’ ‘but,’ ‘we,’ ‘he,’ ‘into,’ ‘just,’ and so on. These words carry information of little value, andare generally considered noise, so they are removed from the data.
[ ‘movie’, ‘colossal’, ‘disaster’, ‘absolutely’, ‘hated’, Waste’, ‘time’, ‘money’, ‘skipit’ ]
Step 5: Stemming
Stemming is a process of linguistic normalization which removes the suffix of each of these words and reduces them to their base word. For example, loved is reduced to love, wasted is reduced to waste. Here, hated is reduced to hate.
[ ‘movie’, ‘colossal’, ‘disaster’, ‘absolutely’, ‘hate’, ‘Waste’, ‘time’, ‘money’, ‘skipit’ ]
Step 6: Final Analysis
In a lexicon-based approach, the remaining words are compared against the sentiment libraries, and the scores obtained for each token are added or averaged.
Sentiment libraries are a list of predefined words and phrases which are manually scored by humans. For example, ‘worst’ is scored -3, and ‘amazing’ is scored +3.
With a basic dictionary, our example comment will be turned into:
movie= 0, colossal= 0, disaster= -2, absolutely=0, hate=-2, waste= -1, time= 0, money= 0, skipit= 0
This makes the overall score of the comment -5 , classifying the comment as negative.
3. Sentiment analysis use cases
Sentiment analysis is used to swiftly glean insights from enormous amounts of text data, with its applications ranging from politics, finance, retail, hospitality, and healthcare. For instance, consider its usefulness in the following scenarios:
- Brand reputation management: Sentiment analysis allows you to track all the online chatter about your brand and spot potential PR disasters before they become major concerns.
- Voice of the customer: The “voice of the customer” refers to the feedback and opinions you get from your clients all over the world. You can improve your product and meet your clients’ needs with the help of this feedback and sentiment analysis.
- Voice of the employee: Employee satisfaction can be measured for your company by analyzing reviews on sites like Glassdoor, allowing you to determine how to improve the work environment you have created.
- Market research: You can analyze and monitor internet reviews of your products and those of your competitors to see how the public differentiates between them, helping you glean indispensable feedback and refine your products and marketing strategies accordingly. Furthermore, sentiment analysis in market research can also anticipate future trends and thus have a first-mover advantage.
Other applications for sentiment analysis could include:
- Customer support
- Social media monitoring
- Voice assistants & chatbots
- Election polls
- Customer experience about a product
- Stock market sentiment and market movement
- Analyzing movie reviews
4. Machine learning and sentiment analysis
Sentiment analysis tasks are typically treated as classification problems in the machine learning approach.
Data analysts use historical textual data—which is manually labeled as positive, negative, or neutral—as the training set. They then complete feature extraction on this labeled dataset, using this initial data to train the model to recognize the relevant patterns. Next, they can accurately predict the sentiment of a fresh piece of text using our trained model.
Naive Bayes, logistic regression, support vector machines, and neural networks are some of the classification algorithms commonly used in sentiment analysis tasks. The high accuracy of prediction is one of the key advantages of the machine learning approach.
5. Advantages of sentiment analysis
Considering large amounts of data on the internet are entirely unstructured, data analysts need a way to evaluate this data.
With regards to sentiment analysis, data analysts want to extract and identify emotions, attitudes, and opinions from our sample sets. Reading and assigning a rating to a large number of reviews, tweets, and comments is not an easy task, but with the help of sentiment analysis, this can be accomplished quickly.
Another unparalleled feature of sentiment analysis is its ability to quickly analyze data such as new product launches or new policy proposals in real time. Thus, sentiment analysis can be a cost-effective and efficient way to gauge and accordingly manage public opinion.
6. Disadvantages of sentiment analysis
Sentiment analysis, as fascinating as it is, is not without its flaws.
Human language is nuanced and often far from straightforward. Machines might struggle to identify the emotions behind an individual piece of text despite their extensive grasp of past data. Some situations where sentiment analysis might fail are:
- Sarcasm, jokes, irony. These things generally don’t follow a fixed set of rules, so they might not be correctly classified by sentiment analytics systems.
- Nuance. Words can have multiple meanings and connotations, which are entirely subject to the context they occur in.
- Multipolarity. When the given text is positive in some parts and negative in others.
- Negation detection. It can be challenging for the machine because the function and the scope of the word ‘not’ in a sentence is not definite; moreover, suffixes and prefixes such as ‘non-,’ ‘dis-,’ ‘-less’ etc. can change the meaning of a text.
7. Key takeaways and next steps
In this article, we examined the science and nuances of sentiment analysis. While sentimental analysis is a method that’s nowhere near perfect, as more data is generated and fed into machines, they will continue to get smarter and improve the accuracy with which they process that data.
All in all, sentimental analysis has a large use case and is an indispensable tool for companies that hope to leverage the power of data to make optimal decisions.
For those who believe in the power of data science and want to learn more, we recommend taking this free, 5-day introductory course in data analytics . You could also read more about related topics by reading any of the following articles:
- The Best Data Books for Aspiring Data Analysts
- PyTorch vs TensorFlow: What Are They And Which Should You Use?
- These Are the Best Data Bootcamps for Learning Python
- Bahasa Indonesia
- Sign out of AWS Builder ID
- AWS Management Console
- Account Settings
- Billing & Cost Management
- Security Credentials
- AWS Personal Health Dashboard
- Support Center
- Expert Help
- Knowledge Center
- AWS Support Overview
- AWS re:Post
- What is Cloud Computing?
- Cloud Computing Concepts Hub
- Machine Learning & AI
What is Sentiment Analysis?
Sentiment analysis is the process of analyzing digital text to determine if the emotional tone of the message is positive, negative, or neutral. Today, companies have large volumes of text data like emails, customer support chat transcripts, social media comments, and reviews. Sentiment analysis tools can scan this text to automatically determine the author’s attitude towards a topic. Companies use the insights from sentiment analysis to improve customer service and increase brand reputation.
Why is sentiment analysis important?
Sentiment analysis, also known as opinion mining, is an important business intelligence tool that helps companies improve their products and services. We give some benefits of sentiment analysis below.
Provide objective insights
Businesses can avoid personal bias associated with human reviewers by using artificial intelligence (AI)–based sentiment analysis tools. As a result, companies get consistent and objective results when analyzing customers’ opinions.
For example, consider the following sentence:
I'm amazed by the speed of the processor but disappointed that it heats up quickly.
Marketers might dismiss the discouraging part of the review and be positively biased towards the processor's performance. However, accurate sentiment analysis tools sort and classify text to pick up emotions objectively.
Build better products and services
A sentiment analysis system helps companies improve their products and services based on genuine and specific customer feedback. AI technologies identify real-world objects or situations (called entities) that customers associate with negative sentiment. From the above example, product engineers focus on improving the processor's heat management capability because the text analysis software associated disappointed ( negative ) with processor ( entity ) and heats up ( entity ).
Analyze at scale
Businesses constantly mine information from a vast amount of unstructured data, such as emails, chatbot transcripts, surveys, customer relationship management records, and product feedback. Cloud-based sentiment analysis tools allow businesses to scale the process of uncovering customer emotions in textual data at an affordable cost.
Real-time results
Businesses must be quick to respond to potential crises or market trends in today's fast-changing landscape. Marketers rely on sentiment analysis software to learn what customers feel about the company's brand, products, and services in real time and take immediate actions based on their findings. They can configure the software to send alerts when negative sentiments are detected for specific keywords.
What are sentiment analysis use cases?
Businesses use sentiment analysis to derive intelligence and form actionable plans in different areas.
Improve customer service
Customer support teams use sentiment analysis tools to personalize responses based on the mood of the conversation. Matters with urgency are spotted by artificial intelligence (AI)–based chatbots with sentiment analysis capability and escalated to the support personnel.
Brand monitoring
Organizations constantly monitor mentions and chatter around their brands on social media, forums, blogs, news articles, and in other digital spaces. Sentiment analysis technologies allow the public relations team to be aware of related ongoing stories. The team can evaluate the underlying mood to address complaints or capitalize on positive trends.
Market research
A sentiment analysis system helps businesses improve their product offerings by learning what works and what doesn't. Marketers can analyze comments on online review sites, survey responses, and social media posts to gain deeper insights into specific product features. They convey the findings to the product engineers who innovate accordingly.
Track campaign performance
Marketers use sentiment analysis tools to ensure that their advertising campaign generates the expected response. They track conversations on social media platforms and ensure that the overall sentiment is encouraging. If the net sentiment falls short of expectation, marketers tweak the campaign based on real-time data analytics.
How does sentiment analysis work?
Sentiment analysis is an application of natural language processing (NLP) technologies that train computer software to understand text in ways similar to humans. The analysis typically goes through several stages before providing the final result.
Preprocessing
During the preprocessing stage, sentiment analysis identifies key words to highlight the core message of the text.
- Tokenization breaks a sentence into several elements or tokens.
- Lemmatization converts words into their root form. For example, the root form of am is be .
- Stop-word removal filters out words that don't add meaningful value to the sentence. For example, with , for , at , and of are stop words.
Keyword analysis
NLP technologies further analyze the extracted keywords and give them a sentiment score. A sentiment score is a measurement scale that indicates the emotional element in the sentiment analysis system. It provides a relative perception of the emotion expressed in text for analytical purposes. For example, researchers use 10 to represent satisfaction and 0 for disappointment when analyzing customer reviews.
What are the approaches to sentiment analysis?
There are three main approaches used by sentiment analysis software.
The rule-based approach identifies, classifies, and scores specific keywords based on predetermined lexicons. Lexicons are compilations of words representing the writer's intent, emotion, and mood. Marketers assign sentiment scores to positive and negative lexicons to reflect the emotional weight of different expressions. To determine if a sentence is positive, negative, or neutral, the software scans for words listed in the lexicon and sums up the sentiment score. The final score is compared against the sentiment boundaries to determine the overall emotional bearing.
Rule-based analysis example
Consider a system with words like happy , affordable , and fast in the positive lexicon and words like poor , expensive , and difficult in a negative lexicon. Marketers determine positive word scores from 5 to 10 and negative word scores from -1 to -10. Special rules are set to identify double negatives, such as not bad , as a positive sentiment. Marketers decide that an overall sentiment score that falls above 3 is positive, while - 3 to 3 is labeled as mixed sentiment.
Pros and cons
A rule-based sentiment analysis system is straightforward to set up, but it's hard to scale. For example, you'll need to keep expanding the lexicons when you discover new keywords for conveying intent in the text input. Also, this approach may not be accurate when processing sentences influenced by different cultures.
This approach uses machine learning (ML) techniques and sentiment classification algorithms, such as neural networks and deep learning , to teach computer software to identify emotional sentiment from text. This process involves creating a sentiment analysis model and training it repeatedly on known data so that it can guess the sentiment in unknown data with high accuracy.
During the training, data scientists use sentiment analysis datasets that contain large numbers of examples. The ML software uses the datasets as input and trains itself to reach the predetermined conclusion. By training with a large number of diverse examples, the software differentiates and determines how different word arrangements affect the final sentiment score.
ML sentiment analysis is advantageous because it processes a wide range of text information accurately. As long as the software undergoes training with sufficient examples, ML sentiment analysis can accurately predict the emotional tone of the messages. However, a trained ML model is specific to one business area. This means sentiment analysis software trained with marketing data cannot be used for social media monitoring without retraining.
Hybrid sentiment analysis works by combining both ML and rule-based systems. It uses features from both methods to optimize speed and accuracy when deriving contextual intent in text. However, it takes time and technical efforts to bring the two different systems together.
What are the different types of sentiment analysis?
Businesses use different types of sentiment analysis to understand how their customers feel when interacting with products or services.
Fine-grained scoring
Fine-grained sentiment analysis refers to categorizing the text intent into multiple levels of emotion. Typically, the method involves rating user sentiment on a scale of 0 to 100, with each equal segment representing very positive, positive, neutral, negative, and very negative. Ecommerce stores use a 5-star rating system as a fine-grained scoring method to gauge purchase experience.
Aspect-based
Aspect-based analysis focuses on particular aspects of a product or service. For example, laptop manufacturers survey customers on their experience with sound, graphics, keyboard, and touchpad. They use sentiment analysis tools to connect customer intent with hardware-related keywords.
Intent-based
Intent-based analysis helps understand customer sentiment when conducting market research. Marketers use opinion mining to understand the position of a specific group of customers in the purchase cycle. They run targeted campaigns on customers interested in buying after picking up words like discounts , deals , and reviews in monitored conversations.
Emotional detection
Emotional detection involves analyzing the psychological state of a person when they are writing the text. Emotional detection is a more complex discipline of sentiment analysis, as it goes deeper than merely sorting into categories. In this approach, sentiment analysis models attempt to interpret various emotions, such as joy , anger , sadness , and regret , through the person's choice of words.
What are the challenges in sentiment analysis?
Despite advancements in natural language processing (NLP) technologies, understanding human language is challenging for machines. They may misinterpret finer nuances of human communication such as those given below.
It is extremely difficult for a computer to analyze sentiment in sentences that comprise sarcasm. Consider the following sentence, Yeah, great. It took three weeks for my order to arrive . Unless the computer analyzes the sentence with a complete understanding of the scenario, it will label the experience as positive based on the word great .
Negation is the use of negative words to convey a reversal of meaning in the sentence. For example, I wouldn't say the subscription was expensive. Sentiment analysis algorithms might have difficulty interpreting such sentences correctly, particularly if the negation happens across two sentences, such as, I thought the subscription was cheap. It wasn't.
Multipolarity
Multipolarity occurs when a sentence contains more than one sentiment. For example, a product review reads, I'm happy with the sturdy build but not impressed with the color. It becomes difficult for the software to interpret the underlying sentiment. You'll need to use aspect-based sentiment analysis to extract each entity and its corresponding emotion.
What is semantic analysis?
Semantic analysis is a computer science term for understanding the meaning of words in text information. It uses machine learning (ML) and natural language processing (NLP) to make sense of the relationship between words and grammatical correctness in sentences.
Sentiment analysis vs. semantic analysis
A sentiment analysis solution categorizes text by understanding the underlying emotion. It works by training the ML algorithm with specific datasets or setting rule-based lexicons. Meanwhile, a semantic analysis understands and works with more extensive and diverse information. Both linguistic technologies can be integrated to help businesses understand their customers better.
How does AWS help with sentiment analysis?
Amazon Comprehend is a natural language processing (NLP) solution that helps businesses extract and identify meaningful insights from text documents. It uses machine learning (ML) technologies to perform sentiment analysis with automated text extraction. Companies train Amazon Comprehend with industry-specific documents to produce highly accurate results.
- Amazon Comprehend Sentiment Analysis API tells developers if a piece of text is positive, negative, neutral, or mixed.
- Amazon Comprehend Targeted Sentiment allows businesses to narrow sentiment analysis to specific parts of products or services.
- Amazon Comprehend supports multiple languages, including German, English, Spanish, Italian, Portuguese, and French.
Get started with sentiment analysis by creating an AWS account today.
Sentiment Analysis Next steps
Ending Support for Internet Explorer
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 April 2024
A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM
- Md Saef Ullah Miah 1 ,
- Md Mohsin Kabir 2 ,
- Talha Bin Sarwar 1 ,
- Mejdl Safran 3 ,
- Sultan Alfarhood 4 &
- M. F. Mridha 1
Scientific Reports volume 14 , Article number: 9603 ( 2024 ) Cite this article
4333 Accesses
2 Altmetric
Metrics details
- Computational science
- Computer science
- Information technology
Sentiment analysis is an essential task in natural language processing that involves identifying a text’s polarity, whether it expresses positive, negative, or neutral sentiments. With the growth of social media and the Internet, sentiment analysis has become increasingly important in various fields, such as marketing, politics, and customer service. However, sentiment analysis becomes challenging when dealing with foreign languages, particularly without labelled data for training models. In this study, we propose an ensemble model of transformers and a large language model (LLM) that leverages sentiment analysis of foreign languages by translating them into a base language, English. We used four languages, Arabic, Chinese, French, and Italian, and translated them using two neural machine translation models: LibreTranslate and Google Translate. Sentences were then analyzed for sentiment using an ensemble of pre-trained sentiment analysis models: Twitter-Roberta-Base-Sentiment-Latest, bert-base-multilingual-uncased-sentiment, and GPT-3, which is an LLM from OpenAI. Our experimental results showed that the accuracy of sentiment analysis on translated sentences was over 86% using the proposed model, indicating that foreign language sentiment analysis is possible through translation to English, and the proposed ensemble model works better than the independent pre-trained models and LLM.
Similar content being viewed by others

Accurate structure prediction of biomolecular interactions with AlphaFold 3

Testing theory of mind in large language models and humans

OpenFold: retraining AlphaFold2 yields new insights into its learning mechanisms and capacity for generalization
Introduction.
Sentiment analysis, the computational task of determining the emotional tone within a text, has evolved as a critical subfield of natural language processing (NLP) over the past decades 1 , 2 . It systematically analyzes textual content to determine whether it conveys positive, negative, or neutral sentiments. This capability holds immense importance in understanding public opinion, customer feedback, and social discourse, making it a fundamental principle in various applications across fields such as marketing, politics, and customer service 3 , 4 , 5 . The general area of sentiment analysis has experienced exponential growth, driven primarily by the expansion of digital communication platforms and massive amounts of daily text data. However, the effectiveness of sentiment analysis has primarily been demonstrated in English owing to the availability of extensive labelled datasets and the development of sophisticated language models 6 . This leaves a significant gap in analysing sentiments in non-English languages, where labelled data are often insufficient or absent 7 , 8 .
Despite the growth in sentiment analysis research, a significant unanswered question persists: How can we effectively adapt sentiment analysis techniques to non-English languages without substantial labelled data? Our study seeks a persuasive answer to this question by presenting a comprehensive methodology and empirical results that demonstrate the feasibility and accuracy of cross-lingual sentiment analysis through translation.
This study explores translating foreign languages into a base language, English, to analyze text sentiments. For sentiment analysis, there are several advantages to translating foreign languages into a base language, such as English. These include:
Overcoming language barriers Language barriers pose a significant challenge in analyzing sentiments in foreign languages. By translating foreign text into a base language, such as English, analysts can overcome these barriers and analyze sentiment more accurately.
Standardization of language Translating foreign languages to a base language can help standardize the language used for sentiment analysis. This can reduce the variability in the language used in different languages and make it easier to compare sentiment across different texts.
Availability of sentiment analysis tools Many sentiment analysis tools are available in English, which makes it easier to analyze sentiment in the translated text. Analysts can use these tools to analyze sentiments in translated texts more efficiently and accurately.
Improved accuracy Translating foreign languages into a base language can improve the accuracy of sentiment analysis compared with traditional sentiment analysis approaches that do not consider language translation. This is because language translation can capture the nuances of foreign languages and convey them more easily to analysts.
The key contributions of this research are outlined as follows:
Advancement in sentiment analysis research: This study contributes to existing research on sentiment analysis by proposing and implementing a methodology for translating foreign languages into English and analyzing the sentiment of the translated text. This approach expands the scope of sentiment analysis beyond English texts and provides a framework for analyzing sentiments in various languages.
Insights into the effectiveness of the proposed approach: This study provides insight into the effectiveness of the developed methodology for sentiment analysis and language translation. By presenting the methodology and discussing its implementation, this research offers valuable information on the accuracy and reliability of sentiment analysis in foreign languages.
Methodological contribution: This study describes a methodology for translating foreign languages into English and conducting sentiment analysis. This contribution includes the techniques, algorithms, and tools employed in the translation process and sentiment analysis, providing a framework for other researchers to replicate or further improve.
Findings and implications: This study presents findings regarding the sentiment analysis of foreign languages and discusses their implications. These findings shed light on the challenges, limitations, and opportunities associated with sentiment analysis in different languages. These implications are valuable for researchers and practitioners in natural language processing, machine learning, social media analysis, and cross-cultural communication.
Practical insights for researchers and practitioners: This study aims to provide practical insights that are useful to researchers and practitioners in various domains. The findings and methodology presented in this research can guide future studies in sentiment analysis and language translation. Moreover, practitioners seeking to implement sentiment analysis in multilingual contexts can benefit from the insights and recommendations offered by this study.
By highlighting these contributions, this study demonstrates the novel aspects of this research and its potential impact on sentiment analysis and language translation.
The subsequent sections of this manuscript are structured as follows: In “ Related works ” section , we delve into the existing body of research relevant to our study. In “ Problem formulation ” section formulates the problem statement, while “ Methodology ” section outlines the methodology employed in this research. In “ Results and discussion ” section presents the experimental results and the accompanying discussions. The challenges of current technologies are presented in the “ Challenges ” section. Lastly, we draw our conclusions in “ Conclusions and future works ” section.
Related works
Sentiment analysis, a crucial natural language processing task, involves the automated detection of emotions expressed in text, distinguishing between positive, negative, or neutral sentiments. The digital age has enabled sentiment analysis across diverse domains. Nonetheless, conducting sentiment analysis in foreign languages, particularly without annotated data, presents complex challenges 9 . While traditional approaches have relied on multilingual pre-trained models for transfer learning, limited research has explored the possibility of leveraging translation to conduct sentiment analysis in foreign languages. Most studies have focused on applying transfer learning using multilingual pre-trained models, which have not yielded significant improvements in accuracy. However, the proposed method of translating foreign language text into English and subsequently analyzing the sentiment in the translated text remains relatively unexplored. This section presents an overview of related works in the field, highlighting the existing studies that have predominantly centred on transfer learning with multilingual pre-trained models and the gaps in testing the effectiveness of the proposed translation-based approach.
The work by Salameh et al. 10 presents a study on sentiment analysis of Arabic social media posts using state-of-the-art Arabic and English sentiment analysis systems and an Arabic-to-English translation system. This study outlines the advantages and disadvantages of each method and conducts experiments to determine the accuracy of the sentiment labels obtained using each technique. The results show that the sentiment analysis of English translations of Arabic texts produces competitive results. The study also answers several research questions related to sentiment prediction accuracy, loss of predictability when translating Arabic text into English, and the accuracy of automatic sentiment analysis compared to human annotation.
The work in 11 , systematically investigates the translation to English and analyzes the translated text for sentiment within the context of sentiment analysis. Arabic social media posts were employed as representative examples of the focus language text. The study reveals that sentiment analysis of English translations of Arabic texts yields competitive results compared with native Arabic sentiment analysis. Additionally, this research demonstrates the tangible benefits that Arabic sentiment analysis systems can derive from incorporating automatically translated English sentiment lexicons. Moreover, this study encompasses manual annotation studies designed to discern the reasons behind sentiment disparities between translations and source words or texts. This investigation is of particular significance as it contributes to the development of automatic translation systems. This research contributes to developing a state-of-the-art Arabic sentiment analysis system, creating a new dialectal Arabic sentiment lexicon, and establishing the first Arabic-English parallel corpus. Significantly, this corpus is independently annotated for sentiment by both Arabic and English speakers, thereby adding a valuable resource to the field of sentiment analysis.
The work described in 12 focuses on scrutinizing the preservation of sentiment through machine translation processes. To this end, a sentiment gold standard corpus featuring annotations from native financial experts was curated in English. Subsequently, this gold standard corpus was translated into a target language (German) employing a human translator and three distinct machine translation engines (Microsoft, Google, and Google Neural Network) and seamlessly integrated into Geofluent to facilitate pre- and post-processing procedures. Two critical experiments were conducted in this study. The first objective was to assess the overall translation quality using the BLEU algorithm as a benchmark. The second experiment identified which machine translation engines most effectively preserved sentiments. The findings of this investigation suggest that the successful transfer of sentiment through machine translation can be accomplished by utilizing Google and Google Neural Network in conjunction with Geofluent. This achievement marks a pivotal milestone in establishing a multilingual sentiment platform within the financial domain. Future endeavours will further integrate language-specific processing rules to enhance machine translation performance, thus advancing the project’s overarching objectives.
The work described in 13 , introduces GLUECoS, a benchmark designed to assess the efficacy of code-switched natural language processing (NLP) models across diverse tasks, with a particular focus on sentiment analysis. To evaluate sentiment analysis performance, this study employs English-Spanish and English-Hindi datasets, employing a range of cross-lingual embedding techniques such as MUSE, BiCVM, and BiSkip, along with the utilization of multilingual BERT (mBERT). Additionally, the authors proposed a refined version of the mBERT model, which undergoes further fine-tuning on synthetically generated code-switched data to enhance its suitability for code-switched settings. These findings reveal notable advancements in sentiment analysis. Specifically, on the English-Hindi dataset (SAIL), the state-of-the-art (SOTA) F1 score registers at 56.9, while leveraging the modified mBERT model yields the highest F1 score of 59.35. Similarly, for the English-Spanish dataset (Twitter sentiment), the SOTA F1 score was 64.6, with the modified mBERT model achieving the best score of 69.31. These outcomes underscore the efficacy of fine-tuning mBERT on synthetic code-switched data, demonstrating its capability to further optimize multilingual models for code-switching tasks, thereby showcasing promising avenues for enhancing sentiment analysis in code-switched contexts.
Recent advancements in machine translation have sparked significant interest in its application to sentiment analysis. The work mentioned in 19 delves into the potential opportunities and inherent limitations of machine translation in cross-lingual sentiment analysis. The crux of sentiment analysis involves acquiring linguistic features, often achieved through tools such as part-of-speech taggers and parsers or fundamental resources such as annotated corpora and sentiment lexica. The motivation behind this research stems from the arduous task of creating these tools and resources for every language, a process that demands substantial human effort. This limitation significantly hampers the development and implementation of language-specific sentiment analysis techniques similar to those used in English. The critical components of sentiment analysis include labelled corpora and sentiment lexica. This study systematically translated these resources into languages that have limited resources. The primary objective is to enhance classification accuracy, mainly when dealing with available (labelled or raw) training instances. In cases where access to training data is constrained, this research explores methods for translating sentiment lexica into the target language while simultaneously striving to enhance machine translation performance by generating additional contextual information.
The experiments conducted in this study focus on both English and Turkish datasets, encompassing movie and product reviews. The classification task involves two-class polarity detection (positive-negative), with the neutral class excluded. Encouraging outcomes are achieved in polarity detection experiments, notably by utilizing general-purpose classifiers trained on translated corpora. However, it is underscored that the discrepancies between corpora in different languages warrant further investigation to facilitate more seamless resource integration.
Additionally, quantitative evidence highlights the intricacies associated with lexica translation, as the inherent differences in expressing sentiment between languages pose challenges in preserving the sentiment of words and phrases during translation processes. This study provides valuable insights into the evolving landscape of cross-lingual sentiment analysis, shedding light on the potential and complexities of leveraging machine translation.
The work in 20 proposes a solution for finding large annotated corpora for sentiment analysis in non-English languages by utilizing a pre-trained multilingual transformer model and data-augmentation techniques. The authors showed that using machine-translated data can help distinguish relevant features for sentiment classification better using SVM models with Bag-of-N-Grams. The data-augmentation technique used in this study involves machine translation to augment the dataset. Specifically, the authors used a pre-trained multilingual transformer model to translate non-English tweets into English. They then used these translated tweets as additional training data for the sentiment analysis model. This simple technique allows for taking advantage of multilingual models for non-English tweet datasets of limited size.
Table 1 compares five latest works related to sentiment analysis and machine translation. Each study addressed specific aspects and challenges in sentiment analysis across various languages, shedding light on the advantages and limitations of machine translation techniques. The table concisely compares five recent studies in different domains, showing the advantages and limitations of utilizing advanced language models. These studies cover topics ranging from sentiment analysis in cryptocurrency to phishing email detection, highlighting the diverse applications and challenges associated with Large Language Models (LLMs) in various fields. Our study offers a novel solution to the challenges of sentiment analysis across multiple foreign languages. By introducing an ensemble model that combines a transformer and a large language model, our research demonstrates improved accuracy and reliability in sentiment analysis compared with individual pre-trained models or LLMs alone. Moreover, the proposed methodology for translating foreign languages to English before conducting sentiment analysis provides valuable insights into cross-lingual sentiment analysis techniques, with practical implications for business, social media analysis, and government intelligence. Overall, this study significantly advances the field of sentiment analysis by addressing the complexities of sentiment analysis in foreign languages and providing a robust framework for cross-lingual sentiment analysis that can be applied across diverse linguistic contexts.
Problem formulation
The problem addressed in this study can be formalized as follows. Let Sentiment Analysis be denoted as SA , a task in natural language processing (NLP). SA involves classifying text into different sentiment polarities, namely positive (P), negative (N), or neutral (U). With the increasing prevalence of social media and the Internet, SA has gained significant importance in various fields such as marketing, politics, and customer service. However, sentiment analysis becomes challenging when dealing with foreign languages, particularly without labelled data for training models.
Considering hypothesis H , foreign language sentiment analysis is feasible by translating the text into English and analyzing the sentiments in the translated text. We conducted experiments to validate this hypothesis using four different languages: Arabic (A), Chinese (C), French (F), and Italian (I). The translation process usesd the LibreTranslate API (T_libre) and Google Translate API (T_google). Each sentence s is then analyzed for sentiment using two pre-trained sentiment analysis models: Twitter-Roberta-Base-Sentiment-Latest (M_Twitter) and Bertweet-Base-Sentiment-Analysis (M_Bertweet) and an ensemble model consisting of Twitter-Roberta-Base-Sentiment-Latest 21 , bert-base-multilingual-uncased-sentiment 22 , and GPT-3 23 .
To measure the accuracy of sentiment analysis on translated sentences, we define Acc as an accuracy metric. Acc is the ratio of correctly classified sentences to the total number of sentences analyzed. Mathematically, Acc is given by the Eq. ( 1 ):
\(C\_correct\) represents the count of correctly classified sentences, and \(C\_total\) denotes the total number of sentences analyzed.
The primary objective of this study is to assess the feasibility of sentiment analysis of translated sentences, thereby providing insights into the potential of utilizing translated text for sentiment analysis and developing a new model for better accuracy. By evaluating the accuracy of sentiment analysis using Acc , we aim to validate hypothesis H that foreign language sentiment analysis is possible through translation to English.
The results of this study have implications for cross-lingual communication and understanding. If Hypothesis H is supported, it would signify the viability of sentiment analysis in foreign languages, thus facilitating improved comprehension of sentiments expressed in different languages. The findings of this research can be valuable into various domains, such as multilingual marketing campaigns, cross-cultural analysis, and international customer service, where understanding sentiment in foreign languages is of utmost importance.
Methodology
In this study, we employed a multi-step methodology to analyze the sentiment of foreign language text by translating them to a base language, English. The methodology comprises five phases: data collection, data cleaning and pre-processing, translation to English, sentiment analysis, and result evaluation. First, we collected data in the target language from various sources such as social media, news articles, and online forums. Next, we performed data cleaning and pre-processing to remove noise, duplicate content, and irrelevant information from the data. Afterwards, we translated the cleaned and pre-processed data into English using a machine translation system. Then, we analyzed the translated data using a sentiment analysis model designed for English text. Finally, we evaluated the results of sentiment analysis to determine the accuracy and effectiveness of the approach. Figure 1 shows the overview of the methodology employed in this study. In the following sections, we provide detailed descriptions of each phase of the methodology and the tools and techniques used in each phase.

Overview of the proposed method.
Data collection
In the initial stage of the research methodology, data in the target language was gathered from diverse and well-established sources, including SemEval-2017 Task 4: Sentiment Analysis in Twitter 24 , amazon_reviews_multi 25 , DEFT 2017 26 , and SENTIPOLC 2016 27 . This study employs four different languages, namely, Arabic (ar), Chinese (zh), French (fr), and Italian (it), which were selected based on their frequent usage in tweets on the Twitter platform. Additionally, the selection of these languages is supported by studies 28 , 29 , which have demonstrated that they are among the most commonly used message languages on Twitter. Moreover, these languages are among the most widely spoken languages in the world 30 . Each dataset has been annotated with three sentiment labels, namely, “positive”, “negative”, and “neutral”. These annotation tasks have taken place manually by the crowd workers in crowd-sourcing platforms. Table 2 shows the overview of the data collected and employed in this study. This table presents the data source, language, and number of sentences per data source employed in this study. Figure 2 shows the distribution of different languages in the utilized dataset.

Distribution of different languages in the dataset used in this study.
Data cleaning and pre-processing
In the second phase of the methodology, the collected data underwent a process of data cleaning and pre-processing to eliminate noise, duplicate content, and irrelevant information. This process involved multiple steps, including tokenization, stop-word removal, and removal of emojis and URLs. Tokenization was performed by dividing the text into individual words or phrases. In contrast, stop-word removal entailed the removal of commonly used words such as “and”, “the”, and “in”, which do not contribute to sentiment analysis. While stemming and lemmatization are helpful in some natural language processing tasks, they are generally unnecessary in Transformer-based sentiment analysis, as the models are designed to handle variations in word forms and inflexions. Therefore, stemming and lemmatization were not applied in this study’s data cleaning and pre-processing phase, which utilized a Transformer-based pre-trained model for sentiment analysis. Emoji removal was deemed essential in sentiment analysis as it can convey emotional information that may interfere with the sentiment classification process. URL removal was also considered crucial as URLs do not provide relevant information and can take up significant feature space. The complete data cleaning and pre-processing steps are presented in Algorithm 1.

Text Cleaner Algorithm
Translation to base language: English
In the third phase of the methodology, we translated the cleaned and pre-processed data to English using a self-hosted machine translation system, namely LibreTranslate 31 and a cloud-hosted service by Google translate neural machine translation (NMT) 32 . LibreTranslate is a free and open-source machine translation API that uses pre-trained NMT models to translate text between different languages. The input text is tokenized and then encoded into a numerical representation using an encoder neural network. The encoded representation is then passed through a decoder network that generates the translated text in the target language. Google Translate NMT uses a deep-learning neural network to translate text from one language to another. The neural network is trained on massive amounts of bilingual data to learn how to translate effectively. During translation, the input text is first tokenized into individual words or phrases, and each token is assigned a unique identifier. The tokens are then fed into the neural network, which processes them in a series of layers to generate a probability distribution over the possible translations. The output from the network is a sequence of tokens in the target language, which are then converted back into words or phrases for the final translated text. The neural network is trained to optimize for translation accuracy, considering both the meaning and context of the input text. One advantage of Google Translate NMT is its ability to handle complex sentence structures and subtle nuances in language.
For the prediction task, the translation process is iterative. Once a sentence’s translation is done, the sentence’s sentiment is analyzed, and output is provided. However, the sentences are initially translated to train the model, and then the sentiment analysis task is performed. The sentiment analysis process is discussed in the following section. Algorithm 2 presents the method employed in this study.

Translation Process
- Sentiment analysis
In the fourth phase of the methodology, we conducted sentiment analysis on the translated data using pre-trained sentiment analysis deep learning models and the proposed ensemble model. In this study, we have utilized an ensemble of two pre-trained sentiment analysis models from Hugging Face 33 , namely, Twitter-Roberta-Base-Sentiment-Latest 34 , bert-base-multilingual-uncased-sentiment 22 and the GPT-3 LLM from OpenAI 23 . The ensemble sentiment analysis model analyzed the text to determine the sentiment polarity (positive, negative, or neutral). The sentiment analysis process is shown in Algorithm 3. The algorithm shows step by step process followed in the sentiment analysis phase.
Hugging Face is a company that offers an open-source software library and a platform for building and sharing models for natural language processing (NLP). The platform provides access to various pre-trained models, including the Twitter-Roberta-Base-Sentiment-Latest and Bertweet-Base-Sentiment-Analysis models, that can be used for sentiment analysis.
One of the main advantages of using these models is their high accuracy and performance in sentiment analysis tasks, especially for social media data such as Twitter. These models are pre-trained on large amounts of text data, including social media content, which allows them to capture the nuances and complexities of language used in social media 35 . Another advantage of using these models is their ability to handle different languages and dialects. The models are trained on multilingual data, which makes them suitable for analyzing sentiment in text written in various languages 35 , 36 .

Sentiment Analysis Ensemble Model
The presented algorithm outlines an ensemble model for conducting sentiment analysis by harnessing the capabilities of three distinct natural language processing models: BERT, RoBERTa, and GPT-3. This algorithm begins by importing a CSV dataset and then initializing the sentiment analysis models of BERT and RoBERTa. Additionally, the GPT-3 model and tokenizer are loaded to facilitate the generation of sentiment-related text. The algorithm’s core revolves around an input sentence provided for sentiment analysis. The input sentence is analyzed using the BERT and RoBERTa models, storing their results for further processing. Following this, the GPT-3 model is leveraged to generate the sentiment of the given text based on a fixed prompt “provide the sentiment of the given text in a single class from positive, negative and neutral”.
The next step involves combining the predictions furnished by the BERT, RoBERTa, and GPT-3 models through a process known as majority voting. This entails tallying the occurrences of “positive”, “negative” and “neutral” sentiment labels. Depending on the outcome, and the algorithm ascribes the final sentiment.
Evaluation metrics
In the final phase of the methodology, we evaluated the results of sentiment analysis to determine the accuracy and effectiveness of the approach. We compared the sentiment analysis results with the ground truth sentiment (the original sentiment of the text labelled in the dataset) to assess the accuracy of the sentiment analysis.
In our evaluation phase, we utilized True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN) as metrics for assessing the performance of our binary classifier. These metrics are typically used to evaluate binary classification models. TP represents the number of correctly identified positive instances, TN indicates the number of correctly identified negative instances, FP represents the number of incorrectly classified positive instances, and FN represents the number of incorrectly classified negative instances. Defining TP, TN, FP, and FN is presented in Algorithm 4. This algorithm takes two inputs: the original language sentiment labelled in a dataset and the sentiment after translating it to English. It then compares the two sentiments and determines whether they are positive, negative or neutral. If the original sentiment is positive and the translated sentiment is positive, it is considered a true positive (TP). If the original sentiment is positive and the translated sentiment is negative, it is regarded as a false negative (FN). If the original sentiment is positive and the translated sentiment is neutral, it is considered a false positive (FP). If the original sentiment is negative and the translated sentiment is negative, it is regarded as a true negative (TN). If the original sentiment is negative and the translated sentiment is positive, it is considered a false positive (FP). If the original sentiment is negative and the translated sentiment is neutral, it is regarded as a false negative (FN). If the original and translated sentiments are neutral, it is considered a true positive (TP). If the original sentiment is neutral and the translated sentiment is positive, it is regarded as a false positive (FP). If the original sentiment is neutral and the translated sentiment is negative, it is considered a false negative (FN).

Defining TP, TN, FP and FN
Our study has three distinct classes: positive, negative, and neutral. As a result, we computed the metrics for each class separately. Precision is used to measure the ratio of correctly classified instances among all the instances the classifier identified as positive, while recall measures the proportion of correctly identified instances among all the positive instances in the dataset. The F1-score is the harmonic mean of precision and recall. Accuracy measures the ratio of correctly classified instances among all instances in the dataset. In contrast, specificity measures the proportion of correctly classified negative instances among all negative instances in the dataset. The evaluation metrics can be expressed by the following Eqs. ( 2 ), ( 3 ), ( 4 ), ( 5 ), and ( 6 ).
Results and discussion
In this section, we present and discuss the results of our experiment on sentiment analysis of foreign languages using machine learning models. We tested two different translation services, namely LibreTranslate and Google Translate, to translate Arabic, Chinese, French, and Italian sentences into English. The translated sentences were then analyzed for sentiment using three different pre-trained sentiment analysis models: Twitter-RoBERTa-Base-Sentiment-Latest, BERTweet-Base-Sentiment-Analysis, GPT-3, which is an LLM, and the proposed ensemble model. We conducted 8 experiments for each language pair, resulting in 32 experiments. We present the results of these experiments and discuss the performance of the translation services and the sentiment analysis models. Finally, we conclude the feasibility and effectiveness of using translated foreign language sentences for sentiment analysis.
Table 3 showcases the outcomes of diverse combinations involving translator and sentiment analyzer models on sentiment analysis tasks. The presented metrics encompass Accuracy, Precision, Recall, F1 Score, and Specificity, collectively offering a comprehensive assessment of the performance of various combinations in sentiment analysis tasks. The evaluation encompasses two primary translation services, namely LibreTranslate and Google Translate, coupled with four distinct sentiment analyzer models: Twitter-Roberta-Base, Bertweet-Base, GPT-3, and a novel Proposed Ensemble model.
Regarding accuracy, it is notable that the LibreTranslate-Bertweet-Base combination exhibited the lowest accuracy score of 0.5638 across all tested combinations. Conversely, Google Translate, combined with the Proposed Ensemble model, yielded the highest accuracy score of 0.8671, demonstrating its potential for achieving superior sentiment analysis results.
The performance of the GPT-3 model is noteworthy, as it consistently demonstrated strong sentiment analysis capabilities when paired with either the LibreTranslate or Google Translate services. This finding underscores the versatility and robustness of the GPT-3 model for sentiment analysis tasks across different translation platforms.
Moreover, the Proposed Ensemble model consistently delivered competitive results across multiple metrics, emphasizing its effectiveness as a sentiment analyzer across various translation contexts. This observation suggests that the ensemble approach can be valuable in achieving accurate sentiment predictions. A series of graphs have been generated to visually represent the experimental outcomes of various combinations of translators and sentiment analyzer models, offering a comprehensive insight into the effectiveness of these models in sentiment analysis shown in Fig. 3 .

Experimental results showing the outcomes of different evaluation metrics.
In the Accuracy Graph (Top Left), each graph represents the accuracy achieved by different combinations of translators and sentiment analyzer models. The x-axis identifies the translator used, while the y-axis denotes the accuracy score. The Google Translate combined with the proposed Ensemble Model emerges as the most accurate, yielding an accuracy score of approximately 0.8671.
Moving to the Precision Graph (Top Middle), this visualization focuses on precision, which measures the model’s ability to correctly identify instances of positive sentiment. Within this graph, Google Translate combined with the proposed Ensemble Model stands out with the highest precision score, reaching around 0.8091.
The Recall Graph (Top Right) centres on the recall metric, indicating the model’s proficiency in identifying all relevant positive sentiment instances. Here, Google Translate, paired with the proposed Ensemble Model, demonstrates the highest recall, approximately 0.8122.
The F1 Score Graph (Bottom Left) provides an overview of the F1 score, a metric that balances precision and recall to gauge the overall effectiveness of the sentiment analysis models. In this graph, Google Translate and the proposed Ensemble Model showcase the highest F1 score, at approximately 0.8106.
The Specificity Graph (Bottom Middle) focuses on specificity, a critical metric in sentiment analysis that assesses the model’s capacity to identify negative sentiment accurately. Here, Google Translate paired with the proposed Ensemble Model exhibits the highest specificity, roughly 0.5713.
The confusion matrices shown in Fig. 4 provide a detailed summary of the performance of different translator and sentiment analyzer model combinations in classifying sentiment. Each confusion matrix consists of four quadrants representing the following:
True negative (TN) The number of instances correctly classified as negative sentiment.
False positive (FP) The number of instances incorrectly classified as positive sentiment.
False negative (FN) The number of instances incorrectly classified as negative sentiment.
True positive (TP) The number of instances correctly classified as positive sentiment.
For instance, considering the confusion matrix for the LibreTranslate - Twitter-Roberta-Base combination, it shows that out of 891 instances:
312 were correctly classified as negative sentiment (TN).
179 were incorrectly classified as positive sentiment when they were actually negative (FP).
222 were incorrectly classified as negative sentiment when they were actually positive (FN).
346 were correctly classified as positive sentiment (TP).
Similarly, each confusion matrix provides insights into the strengths and weaknesses of different translator and sentiment analyzer model combinations in accurately classifying sentiment. Evaluating the numbers in these matrices helps understand the models’ overall performance and effectiveness in sentiment analysis tasks.

Confusion matrices from different experiments.
These graphical representations serve as a valuable resource for understanding how different combinations of translators and sentiment analyzer models influence sentiment analysis performance. Researchers and practitioners can leverage these visualizations to identify the most effective combinations for their specific applications, be it sentiment analysis in social media, customer reviews, or any other context, ensuring the optimal performance of sentiment analysis models. Following the presentation of the overall experimental results, the language-specific experimental findings are delineated and discussed in detail below.
Table 4 presents accuracy scores for different combinations of translator and sentiment analyzer models across four languages: Arabic, Chinese, French, and Italian. Across both LibreTranslate and Google Translate, the proposed ensemble model consistently achieves the highest accuracy scores, with values ranging from 0.83 to 0.88 across the four languages. For LibreTranslate, GPT-3 also demonstrates relatively high accuracy, particularly for Arabic, achieving a score of 0.81. Meanwhile, Google Translate paired with GPT-3 or the proposed ensemble model consistently outperforms other combinations, with accuracy scores ranging from 0.84 to 0.88 across languages. Notably, Chinese consistently scores higher accuracy than other languages across various translator and sentiment analyzer combinations. These findings suggest that the ensemble model, along with GPT-3, holds promise for enhancing accuracy in multilingual sentiment analysis tasks, with Chinese being relatively easier to analyze sentiment accurately.
Table 5 provides precision scores for different combinations of translator and sentiment analyzer models across four languages: Arabic, Chinese, French, and Italian. Within the LibreTranslate framework, the proposed ensemble model consistently achieves the highest precision scores across all languages, ranging from 0.75 to 0.82. Notably, the precision scores are relatively higher for Arabic and Chinese than for French and Italian. Similarly, the proposed ensemble model for Google Translate demonstrates superior precision scores, with values ranging from 0.7 to 0.87 across the four languages. Again, Arabic and Chinese exhibit higher precision scores than French and Italian. Additionally, GPT-3 paired with both LibreTranslate and Google Translate consistently shows competitive precision scores across all languages. These findings suggest that the proposed ensemble model, along with GPT-3, holds promise for improving precision in multilingual sentiment analysis tasks across diverse linguistic contexts.
Table 6 depicts recall scores for different combinations of translator and sentiment analyzer models. Across both LibreTranslate and Google Translate frameworks, the proposed ensemble model consistently demonstrates the highest recall scores across all languages, ranging from 0.75 to 0.82. Notably, for Arabic, Chinese, and French, the recall scores are relatively higher compared to Italian. Similarly, GPT-3 paired with both LibreTranslate and Google Translate consistently shows competitive recall scores across all languages. For Arabic, the recall scores are notably high across various combinations, indicating effective sentiment analysis for this language. These findings suggest that the proposed ensemble model, along with GPT-3, holds promise for improving recall in multilingual sentiment analysis tasks across diverse linguistic contexts.
Table 7 presents F1 scores for different combinations of translator and sentiment analyzer models across four languages: Arabic, Chinese, French, and Italian. Across both LibreTranslate and Google Translate frameworks, the proposed ensemble model consistently achieves the highest F1 scores across all languages, ranging from 0.746 to 0.844. Notably, for Chinese and Italian, the F1 scores are relatively higher than in Arabic and French. Additionally, GPT-3 paired with both LibreTranslate and Google Translate consistently demonstrates competitive F1 scores across all languages. For Chinese, in particular, the F1 scores are notably high across various combinations, indicating effective sentiment analysis for this language. These findings suggest that the proposed ensemble model, along with GPT-3, holds promise for improving F1 scores in multilingual sentiment analysis tasks across diverse linguistic contexts.
Table 8 provides specificity scores for different combinations of translator and sentiment analyzer models across four languages: Arabic, Chinese, French, and Italian. Specificity measures the proportion of correctly identified negative instances out of all actual negative instances. Across both LibreTranslate and Google Translate frameworks, the proposed ensemble model consistently achieves the highest specificity scores across all languages, ranging from 0.49 to 0.73. Notably, the specificity scores for Chinese are relatively higher than those for other languages. Additionally, Google Translate paired with the proposed ensemble model demonstrates high specificity scores for Chinese and Italian. However, it’s important to note that specificity scores are generally lower than other evaluation metrics, indicating that some models may struggle to identify negative sentiment instances accurately. These findings suggest that while the proposed ensemble model shows promise for improving specificity in sentiment analysis, further refinement may be needed to enhance performance across all languages and translators.
After that, this dataset is also trained and tested using an eXtended Language Model (XLM), XLM-T 37 . Which is a multilingual language model built upon the XLM-R architecture but with some modifications. Similar to XLM-R, it can be fine-tuned for sentiment analysis, particularly with datasets containing tweets due to its focus on informal language and social media data. However, for the experiment, this model was used in the baseline configuration and no fine tuning was done. Similarly, the dataset was also trained and tested using a multilingual BERT model called mBERT 38 . The experimental results are shown in Table 9 with the comparison of the proposed ensemble model.
The experimental result reveals promising performance gains achieved by the proposed ensemble models compared to established sentiment analysis models like XLM-T and mBERT. Both proposed models, leveraging LibreTranslate and Google Translate respectively, exhibit better accuracy and precision, surpassing 84% and 80%, respectively. Compared to XLM-T’s accuracy of 80.25% and mBERT’s 78.25%, these ensemble approaches demonstrably improve sentiment identification capabilities. The Google Translate ensemble model garners the highest overall accuracy (86.71%) and precision (80.91%), highlighting its potential for robust sentiment analysis tasks. While mBERT exhibits the highest recall (83.27%). The consistently lower specificity across all models underscores the shared challenge of accurately distinguishing neutral text from positive or negative sentiment, requiring further exploration and refinement. Compared to the other multilingual models, the proposed model’s performance gain may be due to the translation and cleaning of the sentences before the sentiment analysis task.
The outcomes of this experimentation hold significant implications for researchers and practitioners engaged in sentiment analysis tasks. The findings underscore the critical influence of translator and sentiment analyzer model choices on sentiment prediction accuracy. Additionally, the promising performance of the GPT-3 model and the Proposed Ensemble model highlights potential avenues for refining sentiment analysis techniques. It opens doors for future research in this dynamic field using LLMs.
In this study, we compared the performance of two popular translators, LibreTranslate and Google Translate, in combination with two pre-trained sentiment analysis models Twitter-Roberta-Base and Bertweet-Base, one Large Language Model GPT-3, and two multilingual models (XLM-t and mBERT) in four different languages, Arabic, Chinese, French, and Italian with our proposed ensemble model. Our evaluation was based on four metrics, precision, recall, F1 score, and specificity. Our results indicate that Google Translate, with the proposed ensemble model, achieved the highest F1 score in all four languages. Our findings suggest that Google Translate is better at translating foreign languages into English. The proposed ensemble model is the most suitable option for sentiment analysis on these four languages, considering that different language-translator pairs may require different models for optimal performance.
The results presented in this study provide strong evidence that foreign language sentiments can be analyzed by translating them into English, which serves as the base language. This concept is further supported by the fact that using machine translation and sentiment analysis models trained in English, we achieved high accuracy in predicting the sentiment of non-English languages such as Arabic, Chinese, French, and Italian. The obtained results demonstrate that both the translator and the sentiment analyzer models significantly impact the overall performance of the sentiment analysis task. It opens up new possibilities for sentiment analysis applications in various fields, including marketing, politics, and social media analysis.
Despite the advantages of translating foreign languages to a base language for sentiment analysis, there are several challenges associated with this approach that have surfaced in this experiment and also faced by different studies. This section discusses these challenges in more detail and explores the possible solutions.
Challenge I: translation accuracy
One of the primary challenges encountered in foreign language sentiment analysis is accuracy in the translation process. Machine translation systems often fail to capture the intricate nuances of the target language, resulting in erroneous translations that subsequently affect the precision of sentiment analysis outcomes 39 , 40 .
One potential solution to address the challenge of inaccurate translations entails leveraging human translation or a hybrid approach that combines machine and human translation. Human translation offers a more nuanced and precise rendition of the source text by considering contextual factors, idiomatic expressions, and cultural disparities that machine translation may overlook. However, it is essential to note that this approach can be resource-intensive in terms of time and cost. Nevertheless, its adoption can yield heightened accuracy, especially in specific applications that require meticulous linguistic analysis.
Alternatively, machine learning techniques can be used to train translation systems tailored to specific languages or domains. Training the system on extensive datasets and employing specialized machine learning algorithms and natural language processing methodologies can enhance the accuracy of translations, thereby reducing errors in subsequent sentiment analysis. Although it demands access to substantial datasets and domain-specific expertise, this approach offers a scalable and precise solution for foreign language sentiment analysis.
Challenge II: cultural sensitivity
Another critical consideration in translating foreign language text for sentiment analysis pertains to the influence of cultural variations on sentiment expression. Diverse cultures exhibit distinct conventions in conveying positive or negative emotions, posing challenges for accurate sentiment capture by translation tools or human translators 41 , 42 .
For instance, certain cultures may predominantly employ indirect means to express negative emotions, whereas others may manifest a more direct approach. Consequently, if sentiment analysis algorithms or models fail to account for these cultural disparities, precisely identifying negative sentiments within the translated text becomes arduous.
To mitigate this concern, incorporating cultural knowledge into the sentiment analysis process is imperative to enhance the accuracy of sentiment identification in translated text. Potential strategies include the utilization of domain-specific lexicons, training data curated for the specific cultural context, or applying machine learning models tailored to accommodate cultural differences. Integrating cultural awareness into sentiment analysis methodologies enables a more refined understanding of the sentiments expressed in the translated text, enabling comprehensive and accurate analysis across diverse linguistic and cultural domains.
Challenge III: idiomatic expressions
Another challenge when translating foreign language text for sentiment analysis is the idiomatic expressions and other language-specific attributes that may elude accurate capture by translation tools or human translators 43 .
Idioms represent phrases in which the figurative meaning deviates from the literal interpretation of the constituent words. Translating idiomatic expressions can be challenging because figurative connotations may not appear immediately in the translated text.
To proficiently identify sentiment within the translated text, a comprehensive consideration of these language-specific features is imperative, necessitating the application of specialized techniques. For instance, employing sentiment analysis algorithms trained on extensive data from the target language may enhance the capability to discern sentiments within idiomatic expressions and other language-specific attributes. More precise and comprehensive sentiment analysis can be achieved by incorporating techniques explicitly devised to address idiomatic expressions and other language-specific characteristics, thereby facilitating adequate cross-linguistic understanding and analysis.
Challenge IV: translation biases
An inherent limitation in translating foreign language text for sentiment analysis revolves around the potential introduction of biases or errors stemming from the translation process 44 . Although machine translation tools are often highly accurate, they can generate translations that deviate from the fidelity of the original text and fail to capture the intricacies and subtleties of the source language. Similarly, human translators generally exhibit greater accuracy but are not immune to introducing biases or misunderstandings during translation.
To minimize the risks of translation-induced biases or errors, meticulous translation quality evaluation becomes imperative in sentiment analysis. This evaluation entails employing multiple translation tools or engaging multiple human translators to cross-reference translations, thereby facilitating the identification of potential inconsistencies or discrepancies. Additionally, techniques such as back-translation can be employed, whereby the translated text is retranslated back into the original language and compared to the initial text to discern any disparities. By undertaking rigorous quality assessment measures, the potential biases or errors introduced during the translation process can be effectively mitigated, enhancing the reliability and accuracy of sentiment analysis outcomes.
Challenge V: language diversity
Another plausible constraint pertains to the practicality and feasibility of translating foreign language text, particularly in scenarios involving extensive text volumes or languages that present significant challenges. Situations characterized by a substantial corpus for sentiment analysis or the presence of exceptionally intricate languages may render traditional translation methods impractical or unattainable 45 . In such cases, alternative approaches are essential to conduct sentiment analysis effectively.
One viable avenue involves the development of language-specific sentiment analysis algorithms tailored to the intricacies of the target language. These algorithms were optimized to address the unique linguistic characteristics, cultural nuances, and sentiment expression patterns specific to the language under consideration. By customizing the sentiment analysis approach, the limitations associated with translation can be circumvented, thereby facilitating accurate sentiment analysis outcomes.
Another approach involves leveraging machine learning techniques to train sentiment analysis models on substantial quantities of data from the target language. This method capitalizes on large-scale data availability to create robust and effective sentiment analysis models. By training models directly on target language data, the need for translation is obviated, enabling more efficient sentiment analysis, especially in scenarios where translation feasibility or practicality is a concern.
By employing these alternative approaches, such as language-specific sentiment analysis algorithms or training on large-scale target language data, the challenges posed by the impractical or unfeasible translation of foreign language text can be effectively addressed, fostering improved sentiment analysis outcomes.
Challenge VI: handling slang, colloquial language, irony, and sarcasm
One significant challenge in translating foreign language text for sentiment analysis involves incorporating slang or colloquial language, which can perplex both translation tools and human translators 46 . Slang and colloquial languages exhibit considerable variations across regions and languages, rendering their accurate translation into a base language, such as English, challenging. For example, a Spanish review may contain numerous slang terms or colloquial expressions that non-fluent Spanish speakers may find challenging to comprehend. Similarly, a social media post in Arabic may employ slang or colloquial language unfamiliar to individuals who lack knowledge of language and culture. To accurately discern sentiments within text containing slang or colloquial language, specific techniques designed to handle such linguistic features are indispensable.
Another potential challenge in translating foreign language text for sentiment analysis is irony or sarcasm, which can prove intricate in identifying and interpreting, even for native speakers. Irony and sarcasm involve using language to express the opposite of the intended meaning, often for humorous purposes 47 , 48 . For instance, a French review may use irony or sarcasm to convey a negative sentiment; however, individuals lacking fluency in French may struggle to comprehend this intended tone. Similarly, a social media post in German may employ irony or sarcasm to express a positive sentiment, but this could be arduous to discern for those unfamiliar with language and culture. To accurately identify sentiment within a text containing irony or sarcasm, specialized techniques tailored to handle such linguistic phenomena become indispensable.
Notably, sentiment analysis algorithms trained on extensive amounts of data from the target language demonstrate enhanced proficiency in detecting and analyzing specific features in the text. Another potential approach involves using explicitly trained machine learning models to identify and classify these features and assign them as positive, negative, or neutral sentiments. These models can subsequently be employed to classify the sentiment conveyed within the text by incorporating slang, colloquial language, irony, or sarcasm. This facilitates a more accurate determination of the overall sentiment expressed.
Conclusions and future works
This study investigated the effectiveness of using different machine translation and sentiment analysis models to analyze sentiments in four foreign languages. Our results indicate that machine translation and sentiment analysis models can accurately analyze sentiment in foreign languages. Specifically, Google Translate and the proposed ensemble model performed the best in terms of precision, recall, and F1 score. Furthermore, our results suggest that using a base language (English in this case) for sentiment analysis after translation can effectively analyze sentiment in foreign languages. This study provides an ensemble model to perform sentiment analysis of foreign languages through machine translation and analysis in a base language, which can have potential applications in various fields, including business, social media analysis, and government intelligence. This model can be extended to languages other than those investigated in this study. We acknowledge that our study has limitations, such as the dataset size and sentiment analysis models used. These limitations should be addressed in future research.
Data availibility
The datasets generated during and/or analysed during the current study are available from the corresponding author upon reasonable request.
Yadav, A. & Vishwakarma, D. K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 53 , 4335–4385 (2020).
Article Google Scholar
Gandhi, A., Adhvaryu, K., Poria, S., Cambria, E. & Hussain, A. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inf. Fusion 91 , 424–444 (2023).
Cambria, E., Das, D., Bandyopadhyay, S. & Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis 1–10 (2017).
Sarker, I. H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2 , 160 (2021).
Article PubMed PubMed Central Google Scholar
Das, R. & Singh, T. D. Multimodal sentiment analysis: A survey of methods, trends and challenges. ACM Comput. Surv. (2023).
Mercha, E. M. & Benbrahim, H. Machine learning and deep learning for sentiment analysis across languages: A survey. Neurocomputing 531 , 195–216 (2023).
Oueslati, O., Cambria, E., HajHmida, M. B. & Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 112 , 408–430 (2020).
Dewaele, J.-M., Petrides, K. V. & Furnham, A. Effects of trait emotional intelligence and sociobiographical variables on communicative anxiety and foreign language anxiety among adult multilinguals: A review and empirical investigation. Lang. Learn. 58 , 911–960 (2008).
Chan, J.Y.-L., Bea, K. T., Leow, S. M. H., Phoong, S. W. & Cheng, W. K. State of the art: A review of sentiment analysis based on sequential transfer learning. Artif. Intell. Rev. 56 , 749–780 (2023).
Salameh, M., Mohammad, S. M., Kiritchenko, S. et al. Sentiment after translation: A case-study on Arabic social media posts. In HLT-NAACL 767–777 (2015).
Mohammad, S. M., Salameh, M. & Kiritchenko, S. How translation alters sentiment. J. Artif. Intell. Res. https://doi.org/10.1613/jair.4787 (2016).
Article MathSciNet Google Scholar
Zhang, C., Capelletti, M., Poulis, A., Stemann, T. & Nemcova, J. A case study of machine translation in financial sentiment analysis. In: Machine Translation Summit (2017).
Khanuja, S., Dandapat, S., Srinivasan, A., Sitaram, S. & Choudhury, M. Gluecos: An evaluation benchmark for code-switched NLP (2020). Preprint arXiv:2004.12376 .
Wahidur, R. S., Tashdeed, I., Kaur, M. & Lee, H.-N. Enhancing zero-shot crypto sentiment with fine-tuned language model and prompt engineering. IEEE Access (2024).
Xing, F. Designing heterogeneous LLM agents for financial sentiment analysis (2024). Preprint arXiv:2401.05799 .
Xu, S. et al. Reasoning before comparison: Llm-enhanced semantic similarity metrics for domain specialized text analysis (2024). Preprint arXiv:2402.11398 .
Uddin, M. A. & Sarker, I. H. An explainable transformer-based model for phishing email detection: A large language model approach (2024). Preprint arXiv:2402.13871 .
Rehan, M., Malik, M. S. I. & Jamjoom, M. M. Fine-tuning transformer models using transfer learning for multilingual threatening text identification. IEEE Access (2023).
Demirtas, E. Cross-Lingual Sentiment Analysis with Machine Translation . (Eindhoven University of Technology research portal, 2013).
Barriere, V. & Balahur, A. Improving sentiment analysis over non-English tweets using multilingual transformers and automatic translation for data-augmentation (2020). Preprint arXiv:2010.03486 .
cardiffnlp/twitter-roberta-base-sentiment. Hugging Face (2023).
nlptown/bert-base-multilingual-uncased-sentiment. Hugging Face.
Radford, A. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33 (2020).
Rosenthal, S., Farra, N. & Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017) 502–518 (Association for Computational Linguistics, 2017). https://doi.org/10.18653/v1/S17-2088 .
Keung, P., Lu, Y., Szarvas, G. & Smith, N. A. The multilingual amazon reviews corpus. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (2020).
Vinayakumar, R., SachinKumar, S., Premjith, B., Poornachandran, P. & Kp, S. Deft 2017—texts search @ taln/recital 2017: Deep analysis of opinion and figurative language on tweets in French. In Défi Fouille de Textes (2017).
Novielli, N. et al. SENTIPOLC 2016 dataset. https://doi.org/10.57771/N279-Q780 (2021). Type: dataset.
Alshaabi, T. et al. The growing amplification of social media: Measuring temporal and social contagion dynamics for over 150 languages on Twitter for 2009–2020. EPJ Data Sci. 10 , 15. https://doi.org/10.1140/epjds/s13688-021-00271-0 (2021).
Semiocast—Top languages on Twitter-stats—Semiocast (2023).
Lingua. The 20 most spoken languages in the world in 2022 (2022).
Libre Translate. Libre translate API 2021. (Accessed 26, April 2023); https://libretranslate.com/ .
Google translate. (Accessed 27 April 2023); https://translate.google.com/about/intl/en_ALL/ .
Wolf, T. et al. Hugging face’s transformers: State-of-the-art natural language processing 2019 (Accessed 27 April 2023); https://huggingface.co/transformers/ .
Loureiro, D., Barbieri, F., Neves, L., Anke, L. E. & Camacho-Collados, J. Timelms: Diachronic language models from twitter (2022). arXiv:2202.03829 .
Wiriyathammabhum, P. Tedb system description to a shared task on euphemism detection 2022 (2023). arXiv:2301.06602 .
Schmidt, S., Zorenböhmer, C., Arifi, D. & Resch, B. Polarity-based sentiment analysis of georeferenced tweets related to the 2022 twitter acquisition. Information https://doi.org/10.3390/info14020071 (2023).
Barbieri, F., Espinosa Anke, L. & Camacho-Collados, J. Xlm-t: Multilingual language models in twitter for sentiment analysis and beyond. In Proceedings of the Language Resources and Evaluation Conference 258–266 (European Language Resources Association, 2022).
Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR (2018). arXiv:1810.04805 .
Klubička, F., Toral, A. & Sánchez-Cartagena, V. M. Quantitative fine-grained human evaluation of machine translation systems: A case study on English to Croatian. Mach. Transl. 32 , 195–215 (2018).
Daems, J., Vandepitte, S., Hartsuiker, R. J. & Macken, L. Identifying the machine translation error types with the greatest impact on post-editing effort. Front. Psychol. 8 , 1282 (2017).
Li, D. Cross-cultural learning resource recommendation method and corpus construction based on online comment sentiment analysis. In 5th International Conference on Arts, Design and Contemporary Education (ICADCE 2019) 271–278 (Atlantis Press, 2019).
Mohammad, S. M. Sentiment analysis: Automatically detecting valence, emotions, and other affectual states from text. In Emotion Measurement 323–379 (Elsevier, 2021).
Singh, M., Kumar, R. & Chana, I. Machine translation systems for Indian languages: Review of modelling techniques, challenges, open issues and future research directions. Arch. Comput. Methods Eng. 28 , 2165–2193 (2021).
Vanroy, B. Syntactic difficulties in translation . Ph.D. Thesis (Ghent University, 2021).
Kashgary, A. D. The paradox of translating the untranslatable: Equivalence vs non-equivalence in translating from Arabic into English. J. King Saud Univ. Lang. Transl. 23 , 47–57 (2011).
Google Scholar
Goimil Vilacoba, V. James Joyce in translation: Colloquialisms, vulgarisms and idiomatic and cultural expressions in the Spanish and Galician versions of ‘Ulysses’. UDC Repository (2014).
Reyes, A., Rosso, P. & Veale, T. A multidimensional approach for detecting irony in twitter. Lang. Resour. Evaluat. 47 , 239–268 (2013).
Joshi, A., Bhattacharyya, P. & Carman, M. J. Automatic sarcasm detection: A survey. ACM Comput. Surv. (CSUR) 50 , 1–22 (2017).
Download references
Acknowledgements
The authors thank the Research Chair of Online Dialogue and Cultural Communication at King Saud University, Riyadh, Saudi Arabia, for funding this research.
This research is funded by the Research Chair of Online Dialogue and Cultural Communication at King Saud University in Riyadh, Saudi Arabia.
Author information
Authors and affiliations.
Department of Computer Science, American International University-Bangladesh, Dhaka, 1229, Bangladesh
Md Saef Ullah Miah, Talha Bin Sarwar & M. F. Mridha
Faculty of Informatics, Eötvös Loránd University, Budapest, 1117, Hungary
Md Mohsin Kabir
Research Chair of Online Dialogue and Cultural Communication, Department of Computer Science, College of Computer and Information Sciences, King Saud University, 11543, Riyadh, Saudi Arabia
Mejdl Safran
Department of Computer Science, College of Computer and Information Sciences, King Saud University, P.O. Box 51178, 11543, Riyadh, Saudi Arabia
Sultan Alfarhood
You can also search for this author in PubMed Google Scholar
Contributions
Author Contributions Conceptualization and Data curation: M.S.U.M.,T.B. Sarwar and M.M.K. Formal Analysis, Investigation, and Methodology: M.S., S.A. and M.F.M. Supervision and Visualization: M.F.M. Writing—original draft: M.S.U.M. and M.M.K. Writing—review & editing: M.S. and S.A.
Corresponding authors
Correspondence to Mejdl Safran or M. F. Mridha .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Miah, M.S.U., Kabir, M.M., Sarwar, T.B. et al. A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM. Sci Rep 14 , 9603 (2024). https://doi.org/10.1038/s41598-024-60210-7
Download citation
Received : 15 December 2023
Accepted : 19 April 2024
Published : 26 April 2024
DOI : https://doi.org/10.1038/s41598-024-60210-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Cross-lingual communication
- Neural machine translation
- Pretrained sentiment analyzer model
- Ensemble with LLM
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

Root out friction in every digital experience, super-charge conversion rates, and optimize digital self-service
Uncover insights from any interaction, deliver AI-powered agent coaching, and reduce cost to serve
Increase revenue and loyalty with real-time insights and recommendations delivered to teams on the ground
Know how your people feel and empower managers to improve employee engagement, productivity, and retention
Take action in the moments that matter most along the employee journey and drive bottom line growth
Whatever they’re are saying, wherever they’re saying it, know exactly what’s going on with your people
Get faster, richer insights with qual and quant tools that make powerful market research available to everyone
Run concept tests, pricing studies, prototyping + more with fast, powerful studies designed by UX research experts
Track your brand performance 24/7 and act quickly to respond to opportunities and challenges in your market
Explore the platform powering Experience Management
- Free Account
- For Digital
- For Customer Care
- For Human Resources
- For Researchers
- Financial Services
- All Industries
Popular Use Cases
- Customer Experience
- Employee Experience
- Net Promoter Score
- Voice of Customer
- Customer Success Hub
- Product Documentation
- Training & Certification
- XM Institute
- Popular Resources
- Customer Stories
- Artificial Intelligence
- Market Research
- Partnerships
- Marketplace
The annual gathering of the experience leaders at the world’s iconic brands building breakthrough business results, live in Salt Lake City.
- English/AU & NZ
- Español/Europa
- Español/América Latina
- Português Brasileiro
- REQUEST DEMO
- Experience Management
- Survey Data Analysis & Reporting
- Sentiment Analysis
What is sentiment analysis?
What is sentiment analysis used for, why is sentiment analysis important, use cases for sentiment analysis, types of sentiment analysis, pros and cons of using a sentiment analysis system, how does sentiment analysis work, sentiment analysis challenges, three places to analyze customer sentiment, sentiment analysis tools, analyzing customer sentiment, creating better experiences, try qualtrics for free, sentiment analysis and how to leverage it.
20 min read From survey results and customer reviews to social media mentions and chat conversations, today’s businesses have access to data from numerous sources. But how can teams turn all of that data into meaningful insights? Find out how sentiment analysis can help.
When it comes to branding, simply having a great product or service is not enough. In order to determine the true impact of a brand, organizations must leverage data from across customer feedback channels to fully understand the market perception of their offerings.
Quantitative feedback available via metrics such as net promoter scores can provide some information about brand performance, but qualitative feedback in the form of unstructured data provides more nuanced insight into how people actually “feel” about your brand .
Sifting through textual data, however, can be extremely time-consuming. Whether analyzing solicited feedback via channels such as surveys or examining unsolicited feedback found on social media, online forums, and more, it’s impossible to comprehensively identify and integrate data on brand sentiment when relying solely on manual processes.
Leveraging an omnichannel analytics platform allows teams to collect all of this information and aggregate it into a complete view. Once obtained, there are many ways to analyze and enrich the data, one of which involves conducting sentiment analysis. Sentiment analysis can be used to improve customer experience through direct and indirect interactions with your brand. Let’s consider the definition of sentiment analysis, how it works and when to use it.
Learn how TextiQ can help you conduct advanced sentiment analysis
Sentiment refers to the positivity or negativity expressed in text. Sentiment analysis provides an effective way to evaluate written or spoken language to determine if the expression is favorable, unfavorable, or neutral, and to what degree. Because of this, it gives a useful indication of how the customer felt about their experience.
If you’ve ever left an online review, made a comment about a brand or product online, or answered a large-scale market research survey , there’s a chance your responses have been through sentiment analysis.
Sentiment analysis is part of the greater umbrella of text mining, also known as text analysis . This type of analysis extracts meaning from many sources of text, such as surveys , reviews, public social media, and even articles on the Web. A score is then assigned to each clause based on the sentiment expressed in the text. For example, -1 for negative sentiment and +1 for positive sentiment. This is done using natural language processing (NLP).

Today’s algorithm-based sentiment analysis tools can handle huge volumes of customer feedback consistently and accurately. A type of text analysis , sentiment analysis, reveals how positive or negative customers feel about topics ranging from your products and services to your location, your advertisements, or even your competitors.
Accurate sentiment analysis can be difficult to conduct, what’s the benefit? Why do we use an AI-powered tool to categorize natural language feedback rather than our human brains?
Mostly, it’s a question of scale. Sentiment analysis is helpful when you have a large volume of text-based information that you need to generalize from.
For example, let’s say you work on the marketing team at a major motion picture studio, and you just released a trailer for a movie that got a huge volume of comments on Twitter.
You can read some – or even a lot – of the comments, but you won’t be able to get an accurate picture of how many people liked or disliked it unless you look at every last one and make a note of whether it was positive, negative or neutral. That would be prohibitively expensive and time-consuming, and the results would be prone to a degree of human error.
On top of that, you’d have a risk of bias coming from the person or people going through the comments. They might have certain views or perceptions that color the way they interpret the data, and their judgment may change from time to time depending on their mood, energy levels, and other normal human variations.
On the other hand, sentiment analysis tools provide a comprehensive, consistent overall verdict with a simple button press.
From there, it’s up to the business to determine how they’ll put that sentiment into action .
Sentiment analysis is critical because it helps provide insight into how customers perceive your brand .
Customer feedback – whether that’s via social media, the website, conversations with service agents, or any other source – contains a treasure trove of useful business information, but it isn’t enough to know what customers are talking about. Knowing how they feel will give you the most insight into how their experience was. Sentiment analysis is one way to understand those experiences.
Sometimes known as “opinion mining,” sentiment analysis can let you know if there has been a change in public opinion toward any aspect of your business. Peaks or valleys in sentiment scores give you a place to start if you want to make product improvements, train sales reps or customer care agents, or create new marketing campaigns.
We live in a world where huge amounts of written information are produced and published every moment, thanks to the internet, news articles, social media, and digital communications. Sentiment analysis can help companies keep track of how their brands and products are perceived, both at key moments and over a period of time.
It can also be used in market research , PR, marketing analysis, reputation management , stock analysis and financial trading, customer experience , product design , and many more fields.
Here are a few scenarios where sentiment analysis can save time and add value:
- Social media listening – in day-to-day monitoring, or around a specific event such as a product launch
- Analyzing survey responses for a large-scale research program
- Processing employee feedback in a large organization
- Identifying very unhappy customers so you can offer closed-loop follow up
- See where sentiment trends are clustered in particular groups or regions
- Competitor research – checking your approval levels against comparable businesses

Not all sentiment analysis is done the same way. There are different ways to approach it and a range of different algorithms and processes that can be used to do the job depending on the context of use and the desired outcome.
Basic sub-types of sentiment analysis include:
- Detecting sentiment This means parsing through text and sorting opinionated data (such as “I love this!”) from objective data (like “the restaurant is located downtown”).
- Categorizing sentiment This means detecting whether the sentiment is positive, negative, or neutral. Your tools may also add weighting to these categories, e.g very positive, positive, neutral, somewhat negative, negative.
- Clause-level Analysis Sometimes, the text contains mixed or ambivalent opinions, for example, “staff was very friendly but we waited too long to be served”. Being able to score feedback at the clause level indicates when there are both good and bad opinions expressed in one place , and can be useful in case the positives and negatives within a text cancel each other out and return a misleading neutral sentiment
In addition, you can choose whether to view the results of sentiment analysis at:
- Document-level (useful for professional reviews or press coverage)
- Sentence level (for short comments and evaluations)
- Sub-sentence level (for picking out the meaning in phrases or short clauses within a sentence)
Sentiment analysis is a powerful tool that offers a number of advantages, but like any research method, it has some limitations.
Advantages of sentiment analysis:
- Accurate, unbiased results
- Enhanced insights
- More time and energy available for staff do to higher-level tasks
- Consistent measures you can use to track sentiment over time
Disadvantages of sentiment analysis:
- Best for large and numerous data sets. To get real value out of sentiment analysis tools, you need to be analyzing large quantities of textual data on a regular basis.
- Sentiment analysis is still a developing field, and the results are not always perfect. You may still need to sense-check and manually correct results occasionally.
Sentiment analysis uses machine learning, statistics, and natural language processing (NLP) to find out how people think and feel on a macro scale. Sentiment analysis tools take written content and process it to unearth the positivity or negativity of the expression.
This is done in a couple of ways:
- Rule-based sentiment analysis This method uses a lexicon, or word-list, where each word is given a score for sentiment, for example “great” = 0.9, “lame” = -0.7, “okay” = 0.1 Sentences are assessed for overall positivity or negativity using these weightings. Rule-based systems usually require additional finessing to account for sarcasm, idioms, and other verbal anomalies.
- Machine learning-based sentiment analysis A computer model is given a training set of natural language feedback, manually tagged with sentiment labels. It learns which words and phrases have a positive sentiment or a negative sentiment. Once trained, it can then be used on new data sets.
In some cases, the best results come from combining the two methods.

Developing sentiment analysis tools is technically an impressive feat, since human language is grammatically intricate, heavily context-dependent, and varies a lot from person to person. If you say “I loved it,” another person might say “I’ve never seen better,” or “Leaves its rivals in the dust”. The challenge for an AI tool is to recognize that all these sentences mean the same thing.
Another challenge is to decide how language is interpreted since this is very subjective and varies between individuals. What sounds positive to one person might sound negative or even neutral to someone else. In designing algorithms for sentiment analysis, data scientists must think creatively in order to build useful and reliable tools.
Getting the correct sentiment classification
Sentiment classification requires your sentiment analysis tools to be sophisticated enough to understand not only when a data snippet is positive or negative, but how to extrapolate sentiment even when both positive and negative words are used. On top of that, it needs to be able to understand context and complications such as sarcasm or irony.
Human beings are complicated, and how we express ourselves can be similarly complex. Many types of sentiment analysis tools use a simple view of polarity (positive/neutral/negative), which means much of the meaning behind the data is lost.
Let’s see an example:
“I hated the setup process, but the product was easy to use so in the end, I think my purchase was worth it.”
A less sophisticated sentiment analysis tool might see the sentiment expressed here as “neutral” because the positive – “the product was easy to use so, in the end, I think my purchase was worth it” – and negative-tagged sentiments – “I hated the setup process” – cancel each other out.
However, polarity isn’t so cut-and-dry as being one or the other here. The final part – “in the end, I think my purchase was worth it” – means that as a human analyzing the text, we can see that generally, this customer felt mostly positive about the experience. That’s why a scale from positive to negative is needed, and why a sentiment analysis tool adds weighting along a scale of 1-11.

Scores are assigned with attention to grammar, context, industry, and source, and Qualtrics gives users the ability to adjust the sentiment scores to be even more business-specific.
Understanding context
Context is key for a sentiment analysis model to be correct. This means you need to make sure that your sentiment scoring tool not only knows that “happy” is positive—and that “not happy” is not, but understands that certain words that are context-dependent are viewed correctly.
As human beings, we know customers are pleased when they mention how “thin” their new laptop is, but that they’re complaining when they talk about the “thin” walls in your hotel. We understand that context.
Obviously, a tool that flags “thin” as negative sentiment in all circumstances is going to lose accuracy in its sentiment scores. The context is important.
This is where training natural language processing (NLP) algorithms come in. Natural language processing is a way of mimicking the human understanding of language, meaning context becomes more readily understood by your sentiment analysis tool.
Sentiment analysis algorithms are trained using this system over time, using deep learning to understand instances with context and apply that learning to future data. This is why a sophisticated sentiment analysis tool can help you to not only analyze vast volumes of data more quickly but also discern what context is common or important to your customers .
In a world of endless opinions on the Web, how people “feel” about your brand can be important for measuring the customer experience .
Consumers desire likable brands that understand them; brands that provide memorable on-and-offline experiences. The more in-tune a consumer feels with your brand, the more likely they’ll share feedback, and the more likely they’ll buy from you too. According to our Consumer trends research , 62% of consumers said that businesses need to care more about them, and 60% would buy more as a result.
But the opposite is true as well. As a matter of fact, 71 percent of Twitter users will take to the social media platform to voice their frustrations with a brand.
These conversations, both positive and negative, should be captured and analyzed to improve the customer experience. Sentiment analysis can help.
1. Text analysis for surveys
Surveys are a great way to connect with customers directly, and they’re also ripe with constructive feedback . The feedback within survey responses can be quickly analyzed for sentiment scores.
For the survey itself, consider questions that will generate qualitative customer experience metrics, some examples include:
- What was your most recent experience like?
- How much better (or worse) was your experience compared to your expectations?
- What is something you would have changed about your experience?
Remember, the goal here is to acquire honest textual responses from your customers so the sentiment within them can be analyzed. Another tip is to avoid close-ended questions that only generate “yes” or “no” responses. These types of questions won’t serve your analysis well.
Next, use a text analysis tool to break down the nuances of the responses. TextiQ is a tool that will not only provide sentiment scores but extract key themes from the responses.
After the sentiment is scored from survey responses, you’ll be able to address some of the more immediate concerns your customers have during their experiences.
Another great place to find text feedback is through customer reviews .
2. Text analysis for customer reviews
Did you know that 72 percent of customers will not take action until they’ve read reviews on a product or service? An astonishing 95 percent of customers read reviews prior to making a purchase. In today’s feedback-driven world, the power of customer reviews and peer insight is undeniable.
Review sites like G2 are common first-stops for customers looking for honest feedback on products and services. This feedback, like that in surveys, can be analyzed.
The benefit of customer reviews compared to surveys is that they’re unsolicited, which often leads to more honest and in-depth feedback.
To improve the customer experience, you can take the sentiment scores from customer reviews – positive, negative, and neutral – and identify gaps and pain points that may have not been addressed in the surveys. Remember, negative feedback is just as (if not more) beneficial to your business than positive feedback.
3. Text analysis for social media
Another way to acquire textual data is through social media analysis.
Monitoring tools ingest publicly available social media data on platforms such as Twitter and Facebook for brand mentions and assign sentiment scores accordingly. This has its upsides as well considering users are highly likely to take their uninhibited feedback to social media.
Regardless, a staggering 70 percent of brands don’t bother with feedback on social media. Because social media is an ocean of big data just waiting to be analyzed, brands could be missing out on some important information.
When choosing sentiment analysis technologies, bear in mind how you will use them. There are a number of options out there, from open-source solutions to in-built features within social listening tools. Some of them are limited in scope, while others are more powerful but require a high level of user knowledge.
Text iQ is a natural language processing tool within the Experience Management Platform™ that allows you to carry out sentiment analysis online using just your browser. It’s fully integrated, meaning that you can view and analyze your sentiment analysis results in the context of other data and metrics, including those from third-party platforms.
Like all our tools, it’s designed to be straightforward, clear, and accessible to those without specialized skills or experience, so there’s no barrier between you and the results you want to achieve.
When it comes to understanding the customer experience, the key is to always be on the lookout for customer feedback. Sentiment analysis is not a one-and-done effort and requires continuous monitoring. By reviewing your customers’ feedback on your business regularly, you can proactively get ahead of emerging trends and fix problems before it’s too late. Acquiring feedback and analyzing sentiment can provide businesses with a deep understanding of how customers truly “feel” about their brand. When you’re able to understand your customers, you’re able to provide a more robust customer experience.
Related resources
Analysis & Reporting
Margin of error 11 min read
Data saturation in qualitative research 8 min read, thematic analysis 11 min read, behavioral analytics 12 min read, statistical significance calculator: tool & complete guide 18 min read, regression analysis 19 min read, data analysis 31 min read, request demo.
Ready to learn more about Qualtrics?
- NPS Analysis
- Review Analysis
- CSAT Analysis
- Support Analysis
- Survey Analysis
- VoC Analysis
- Support Ticket Routing
- How it Works
- Text Classifiers
- Text Extractors
- Integrations
Sentiment Analyzer
Use sentiment analysis to quickly detect emotions in text data.
Play around with our sentiment analyzer, below:
Test with your own text
Get sentiment insights like these:

Sentiment analysis benefits:
MonkeyLearn Inc. All rights reserved 2024
- This tool is designed to provide general-purpose sentiment analysis for reasonably long passages of text written in the English language. The tool is not oriented toward any specific domain (e.g., business, religion, entertainment, politics, etc.). The general-purpose nature of this tool has both advantages and disadvantages.
- The sentiment analyzer was trained using the collection of more than 8,000 writing samples and transcripts of spoken conversations that appear in the American National Corpus (ANC). The ANC contains writing samples from a wide variety of genres and domains.
- Because of the design of the American National Corpus, the sentiment analyzer is most accurate with text written in American English after 1990.
- This tool produces an overall sentiment score. Although various passages within a sample of text may be particularly positive or negative, the sentiment score produced by this tool considers all of the text in the sample.
- Sentiment analysis is a difficult task because it involves human emotions. Research shows that humans will disagree about the sentiment of written text in about 20% of all cases. This means that even if the sentiment analyzer were a perfect tool, as a human being you would likely only agree with its conclusions about 80% of the time.
Sentiment lexicons and non-English languages: a survey
- Survey Paper
- Published: 22 July 2020
- Volume 62 , pages 4445–4480, ( 2020 )
Cite this article

- Mohammed Kaity 1 &
- Vimala Balakrishnan ORCID: orcid.org/0000-0002-6859-4488 1
2147 Accesses
27 Citations
2 Altmetric
Explore all metrics
The ever-increasing number of Internet users and online services, such as Amazon, Twitter and Facebook has rapidly motivated people to not just transact using the Internet but to also voice their opinions about products, services, policies, etc. Sentiment analysis is a field of study to extract and analyze public views and opinions. However, current research within this field mainly focuses on building systems and resources using the English language. The primary objective of this study is to examine existing research in building sentiment lexicon systems and to classify the methods with respect to non-English datasets. Additionally, the study also reviewed the tools used to build sentiment lexicons for non-English languages, ranging from those using machine translation to graph-based methods. Shortcomings are highlighted with the approaches along with recommendations to improve the performance of each approach and areas for further study and research.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price excludes VAT (USA) Tax calculation will be finalised during checkout.
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
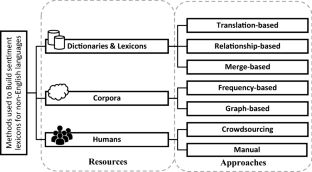
Similar content being viewed by others

A survey on sentiment analysis methods, applications, and challenges

A review on sentiment analysis and emotion detection from text

Sentiment Analysis in the Age of Generative AI
http://stardict.sourceforge.net .
http://www.dicts.info/uddl.php .
translate.google.com .
http://www.talkingcock.com/html/lexec.php .
http://www.singlishdictionary.com/ .
https://en.wikipedia.org/wiki/Singlish_vocabulary .
https://github.com/jeffreybreen/twitter-sentiment-analysis-tutorial-201107/tree/master/data/opinion-lexicon-English .
https://www.mturk.com/ .
http://www.jeuxdemots.org/emot.php .
https://github.com/facebookresearch/fastText .
Liu B (2012) Sentiment analysis and opinion mining. Synth Lect Hum Lang Technol 5(1):1–167
Google Scholar
Dodds PS, Harris KD, Kloumann IM, Bliss CA, Danforth CM (2011) Temporal patterns of happiness and information in a global social network: hedonometrics and Twitter. PLoS ONE 6(12):e26752
Akhtar MS, Gupta D, Ekbal A, Bhattacharyya P (2017) Feature selection and ensemble construction: a two-step method for aspect based sentiment analysis. Knowl Based Syst 125:116–135
Dashtipour K, Poria S, Hussain A, Cambria E, Hawalah AY, Gelbukh A, Zhou Q (2016) Multilingual sentiment analysis: state of the art and independent comparison of techniques. Cogn Comput 8(4):757–771
Lo SL, Cambria E, Chiong R, Cornforth D (2016) Multilingual sentiment analysis: from formal to informal and scarce resource languages. Artif Intell Rev 28:499–527
Biltawi M, Etaiwi W, Tedmori S, Hudaib A, Awajan A (2016) Sentiment classification techniques for Arabic language: a survey. In: 7th international conference on information and communication systems, ICICS 2016. Institute of Electrical and Electronics Engineers Inc
Mihalcea R, Banea C, Wiebe JM (2007) Learning multilingual subjective language via cross-lingual projections. In: Proceedings of the 45th annual meeting of the association of computational linguistics
Deng S, Sinha AP, Zhao H (2017) Adapting sentiment lexicons to domain-specific social media texts. Decis Support Syst 94:65–76
Wu S, Wu F, Chang Y, Wu C, Huang Y (2019) Automatic construction of target-specific sentiment lexicon. Expert Syst Appl 116:285–298
Ahire S (2014) A survey of sentiment lexicons. Computer Science and Engineering IIT Bombay, Bombay
Medhat W, Hassan A, Korashy H (2014) Sentiment analysis algorithms and applications: a survey. Ain Shams Eng J 5(4):1093–1113
Montoyo A, Martínez-Barco P, Balahur A (2012) Subjectivity and sentiment analysis: an overview of the current state of the area and envisaged developments. Decis Support Syst 53(4):675–679
Sun S, Luo C, Chen J (2017) A review of natural language processing techniques for opinion mining systems. Inf Fusion 36:10–25
Cambria E, Speer R, Havasi C, Hussain A (2010) SenticNet: a publicly available semantic resource for opinion mining. In: AAAI fall symposium: commonsense knowledge
Wilson T, Hoffmann P, Somasundaran S, Kessler J, Wiebe J, Choi Y, Cardie C, Riloff E, Patwardhan S (2005) OpinionFinder: a system for subjectivity analysis. In: Proceedings of HLT/EMNLP on interactive demonstrations. Association for Computational Linguistics
Hu M, Liu B (2004) Mining and summarizing customer reviews. In: Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining. ACM
Wilson T, Wiebe J, Hoffmann P (2005) Recognizing contextual polarity in phrase-level sentiment analysis. In: Proceedings of the conference on human language technology and empirical methods in natural language processing. Association for Computational Linguistics
El-Halees A (2011) Arabic opinion mining using combined classification approach. In: The international Arab conference on information technology, pp 10–13
Feng S, Song KS, Wang DL, Yu G (2015) A word-emoticon mutual reinforcement ranking model for building sentiment lexicon from massive collection of microblogs. World Wide Web Internet Web Inf Syst 18(4):949–967
Lafourcade M, Joubert A, Le Brun N (2015) Collecting and evaluating lexical polarity with a game with a purpose. In: RANLP
Abdaoui A, Azé J, Bringay S, Poncelet P (2016) FEEL: a French expanded emotion lexicon. Lang Resour Eval 51:1–23
Nusko B, Tahmasebi N, Mogren O (2016) Building a sentiment lexicon for Swedish. In: Digital humanities 2016. From digitization to knowledge 2016: resources and methods for semantic processing of digital works/texts, proceedings of the workshop, 11 July 2016, Krakow, Poland. Linköping University Electronic Press
Haniewicz K, Kaczmarek M, Adamczyk M, Rutkowski W (2014) Polarity lexicon for the polish language: design and extension with random walk algorithm. In: Swiatek J et al (eds) International conference on systems science, ICSS 2013. Springer, Berlin, pp 173–182
Ravi K, Ravi V (2015) A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowl Based Syst 89:14–46
Cambria E, Schuller B, Xia Y, Havasi C (2013) New avenues in opinion mining and sentiment analysis. IEEE Intell Syst 28(2):15–21
Giachanou A, Crestani F (2016) Like it or not: a survey of twitter sentiment analysis methods. ACM Comput Surv (CSUR) 49(2):28
Mohammad SM, Turney PD (2013) Crowdsourcing a word-emotion association lexicon. Comput Intell 29(3):436–465
MathSciNet Google Scholar
Cho H, Kim S, Lee J, Lee JS (2014) Data-driven integration of multiple sentiment dictionaries for lexicon-based sentiment classification of product reviews. Knowl Based Syst 71:61–71
Esuli A, Sebastiani F (2007) SENTIWORDNET: a high-coverage lexical resource for opinion mining. Technical Report 2007-TR-02. http://nmis.isti.cnr.it/sebastiani/Publications/2007TR02.pdf
Baccianella S, Esuli A, Sebastiani F (2010) SentiWordNet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining. In: LREC
Poria S, Gelbukh A, Hussain A, Howard N, Das D, Bandyopadhyay S (2013) Enhanced SenticNet with affective labels for concept-based opinion mining. IEEE Intell Syst 28(2):31–38
Hung C, Lin H-KJIIS (2013) Using objective words in SentiWordNet to improve word-of-mouth sentiment classification. IEEE Intell Syst 2:47–54
Plutchik R (2001) The nature of emotions human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. Am Sci 89(4):344–350
Araujo M, Reis J, Pereira A, Benevenuto F (2016) An evaluation of machine translation for multilingual sentence-level sentiment analysis. In: Proceedings of the 31st annual ACM symposium on applied computing. ACM
Perez-Rosas V, Banea C, Mihalcea R (2012) Learning sentiment lexicons in Spanish. In: Lrec 2012—eighth international conference on language resources and evaluation, pp 3077–3081
Stone PJ, Dunphy DC, Smith MS (1966) The general inquirer: a computer approach to content analysis. M.I.T. Press, Oxford, p 651
Nielsen FA (2011) A new ANEW: evaluation of a word list for sentiment analysis in microblogs. In: 1st workshop on making sense of microposts 2011: big things come in small packages, #MSM 2011—co-located with the 8th extended semantic web conference, ESWC 2011. Heraklion, Crete
Neviarouskaya A, Prendinger H, Ishizuka M (2009) SentiFul: generating a reliable lexicon for sentiment analysis. In: 2009 3rd international conference on affective computing and intelligent interaction and workshops, ACII 2009, Amsterdam
Wu F, Huang Y, Song Y, Liu S (2016) Towards building a high-quality microblog-specific Chinese sentiment lexicon. Decis Support Syst 87:39–49
Hammer H, Bai A, Yazidi A, Engelstad P (2014) Building sentiment lexicons applying graph theory on information from three norwegian thesauruses. Norsk Informatikkonferanse (NIK)
Al-Twairesh N, Al-Khalifa H, Al-Salman A (2016) AraSenTi: large-scale twitter-specific arabic sentiment lexicons. In: Association for computational linguistics, pp 697–705
Yao J, Wu G, Liu J, Zheng Y (2006) Using bilingual lexicon to judge sentiment orientation of Chinese words. In: The sixth IEEE international conference on computer and information technology, 2006. CIT’06. IEEE
Steinberger J, Ebrahim M, Ehrmann M, Hurriyetoglu A, Kabadjov M, Lenkova P, Steinberger R, Tanev H, Vázquez S, Zavarella V (2012) Creating sentiment dictionaries via triangulation. Decis Support Syst 53(4):689–694
Remus R, Quasthoff U, Heyer G (2010) SentiWS—a publicly available German-language resource for sentiment analysis. In: LREC
Denecke K (2008) Using sentiwordnet for multilingual sentiment analysis. In: IEEE 24th international conference on data engineering workshop, 2008. ICDEW 2008. IEEE
Banea C, Mihalcea R, Wiebe J (2013) Porting multilingual subjectivity resources across languages. IEEE Trans Affect Comput 4(2):211–225
Kim J, Li J-J, Lee J-H (2010) Evaluating multilanguage-comparability of subjectivity analysis systems. In: Proceedings of the 48th annual meeting of the association for computational linguistics. Association for Computational Linguistics
Basile V, Nissim M (2013) Sentiment analysis on Italian tweets. In: Proceedings of the 4th workshop on computational approaches to subjectivity, sentiment and social media analysis
Lo SL, Cambria E, Chiong R, Cornforth D (2016) A multilingual semi-supervised approach in deriving Singlish sentic patterns for polarity detection. Knowl Based Syst 105:236–247
Sidorov G, Miranda-Jiménez S, Viveros-Jiménez F, Gelbukh A, Castro-Sánchez N, Velásquez F, Díaz-Rangel I, Suárez-Guerra S, Treviño A, Gordon J (2012) Empirical study of machine learning based approach for opinion mining in tweets. In: Mexican international conference on artificial intelligence. Springer
Kim S-M, Hovy E (2006) Identifying and analyzing judgment opinions. In: Proceedings of the main conference on human language technology conference of the North American chapter of the association of computational linguistics. Association for Computational Linguistics
Das A, Bandyopadhyay S (2010) Sentiwordnet for bangla. Knowl Shar Event4 Task 2:1–8
Rouvier M, Favre B (2016) Building a robust sentiment lexicon with (almost) no resource. arXiv preprint arXiv:1612.05202
Hassan A, Abu-Jbara A, Jha R, Radev D (2011) Identifying the semantic orientation of foreign words. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies: short papers, vol 2. Association for Computational Linguistics
Rosell M, Kann V (2010) Constructing a swedish general purpose polarity lexicon random walks in the people’s dictionary of synonyms. SLTC 2010:19
Banea C, Wiebe JM, Mihalcea R (2008) A bootstrapping method for building subjectivity lexicons for languages with scarce resources. In: Proceedings of the international conference on language resources and evaluation, LREC 2008, 26 May–1 June 2008, Marrakech, Morocco, pp 2764–2467
Rao D, Ravichandran D (2009) Semi-supervised polarity lexicon induction. In: Proceedings of the 12th conference of the European chapter of the association for computational linguistics. Association for Computational Linguistics
Mahyoub FHH, Siddiqui MA, Dahab MY (2014) Building an Arabic sentiment lexicon using semi-supervised learning. J King Saud Univ Comput Inf Sci 26(4):417–424
Bakliwal A, Arora P, Varma V (2012) Hindi subjective lexicon: a lexical resource for hindi polarity classification. In: Proceedings of the eight international conference on language resources and evaluation (LREC)
Zhu Y, Wen Z, Wang P, Peng Z (2009) A method of building Chinese basic semantic lexicon based on word similarity. In: 2009 Chinese conference on pattern recognition, CCPR 2009 and the 1st CJK joint workshop on pattern recognition, CJKPR, Nanjing
Dehdarbehbahani I, Shakery A, Faili H (2014) Semi-supervised word polarity identification in resource-lean languages. Neural Netw 58:50–59
Darwich M, Noah SAM, Omar N (2016) Automatically generating a sentiment lexicon for the Malay language. Asia Pac J Inf Technol Multimed 5(1):49–59
Badaro G, Baly R, Hajj H, Habash N, El-Hajj W (2014) A large scale Arabic sentiment lexicon for Arabic opinion mining. ANLP 2014:165
Joshi A, Balamurali A, Bhattacharyya P (2010) A fall-back strategy for sentiment analysis in hindi: a case study. In: Proceedings of the 8th ICON
Abdul-Mageed M, Diab MT (2014) SANA: a large scale multi-genre, multi-dialect lexicon for Arabic subjectivity and sentiment analysis. In: LREC
Eskander R, Rambow O (2015) SLSA: a sentiment lexicon for Standard Arabic. In: Conference on empirical methods in natural language processing, EMNLP 2015. Association for Computational Linguistics (ACL)
Buscaldi D, Hernandez-Farias DI (2016) IRADABE2: lexicon merging and positional features for sentiment analysis in Italian. In: CLiC-it/EVALITA
Jha V, Savitha R, Hebbar SS, Shenoy PD, Venugopal K (2015) Hmdsad: Hindi multi-domain sentiment aware dictionary. In: 2015 International conference on computing and network communications (CoCoNet). IEEE
Rashed FE, Abdolvand N (2017) A supervised method for constructing sentiment lexicon in Persian language. J Comput Robot 10(1):11–19
Yang AM, Lin JH, Zhou YM, Chen J (2013) Research on building a Chinese sentiment lexicon based on SO-PMI. In: Zhang J et al (eds) Information technology applications in industry, Pts 1-4. Trans Tech Publications Ltd, Stafa-Zurich, pp 1688–1693
Elhawary M, Elfeky M (2010) Mining Arabic business reviews. In: 2010 IEEE international conference on data mining workshops (ICDMW). IEEE
Hong Y, Kwak H, Baek Y, Moon S (2013) Tower of babel: a crowdsourcing game building sentiment lexicons for resource-scarce languages. In: 22nd international conference on World Wide Web, WWW 2013, Rio de Janeiro
Al-Subaihin, A.A., H.S. Al-Khalifa, and A.S. Al-Salman. A proposed sentiment analysis tool for modern arabic using human-based computing. in Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services. 2011. ACM
Scharl A, Sabou M, Gindl S, Rafelsberger W, Weichselbraun A (2012) Leveraging the wisdom of the crowds for the acquisition of multilingual language resources. In: 8th international conference on language resources and evaluation (LREC-2012), 23–25 May 2012, Istanbul, Turkey, pp 379–383
Trakultaweekoon K, Klaithin S (2016) SenseTag: a tagging tool for constructing Thai sentiment lexicon. In: 2016 13th international joint conference on computer science and software engineering (JCSSE). IEEE
Abdul-Mageed M, Diab M, Kübler S (2014) SAMAR: subjectivity and sentiment analysis for Arabic social media. Comput Speech Lang 28(1):20–37
Pasha A, Al-Badrashiny M, Diab MT, El Kholy A, Eskander R, Habash N, Pooleery M, Rambow O, Roth R (2014) MADAMIRA: a fast, comprehensive tool for morphological analysis and disambiguation of Arabic. In: LREC
Cerini S, Compagnoni V, Demontis A, Formentelli M, Gandini G (2007) Micro-WNOp: a gold standard for the evaluation of automatically compiled lexical resources for opinion mining. In: Language resources and linguistic theory: typology, second language acquisition, English linguistics, pp 200–210
Balahur A, Steinberger R, Van Der Goot E, Pouliquen B, Kabadjov M (2009) Opinion mining on newspaper quotations. In: IEEE/WIC/ACM international joint conferences on web intelligence and intelligent agent technologies, 2009. WI-IAT’09. IEEE
Thelwall M, Buckley K, Paltoglou G, Cai D, Kappas A (2010) Sentiment strength detection in short informal text. J Am Soc Inf Sci Technol 61(12):2544–2558
Chen Y, Skiena S (2014) Building sentiment lexicons for all major languages. In: 52nd annual meeting of the association for computational linguistics, ACL 2014. Association for Computational Linguistics (ACL), Baltimore, MD
Moliner M (1984) Diccionario de uso del espanol.-v. 1–2
Miller GA (1995) WordNet: a lexical database for English. Commun ACM 38(11):39–41
Mohammad S, Turney P (2013) NRC emotion lexicon, in National Research Council. NRC Technical Report, Canada
Black W, Elkateb S, Rodriguez H, Alkhalifa M, Vossen P, Pease A, Fellbaum C (2006) Introducing the Arabic WordNet project. In: Proceedings of the third international WordNet conference
Narayan D, Chakrabarti D, Pande P, Bhattacharyya P (2002) An experience in building the indo WordNet—a WordNet for Hindi. In: First international conference on global WordNet, Mysore, India
Shamsfard M, Hesabi A, Fadaei H, Mansoory N, Famian A, Bagherbeigi S, Fekri E, Monshizadeh M, Assi SM (2010) Semi automatic development of FarsNet; the Persian WordNet. In: Proceedings of 5th global WordNet conference, Mumbai, India
Kann V, Rosell M (2005) Free construction of a free Swedish dictionary of synonyms. In: Proceedings of NODALIDA 2005, Citeseer
Karthikeyan A (2010) Hindi English WordNet linkage. CSE Department, IIT Bombay, Bombay
Borin L, Forsberg M, Lönngren L (2013) SALDO: a touch of yin to WordNet’s yang. Lang Resour Eval 47(4):1191–1211
Maamouri M, Graff D, Bouziri B, Krouna S, Bies A, Kulick S (2010) Standard Arabic morphological analyzer (SAMA) version 3.1. Linguistic Data Consortium, Catalog No.: LDC2010L01
Abdul-Mageed M, Diab MT (2011) Subjectivity and sentiment annotation of modern standard arabic newswire. In: Proceedings of the 5th linguistic annotation workshop. Association for Computational Linguistics
Buckwalter T (2004) Buckwalter Arabic morphological analyzer version 2.0. Linguistic Data Consortium, University of Pennsylvania, 2002. LDC Catalog No.: LDC2004L02. ISBN 1-58563-324-0
Wiebe J, Riloff E (2005) Creating subjective and objective sentence classifiers from unannotated texts. In: International conference on intelligent text processing and computational linguistics. Springer
Balahur A, Turchi M (2014) Comparative experiments using supervised learning and machine translation for multilingual sentiment analysis. Comput Speech Lang 28(1):56–75
Elkateb S, Black W, Rodríguez H, Alkhalifa M, Vossen P, Pease A, Fellbaum C (2006) Building a WordNet for arabic. In: Proceedings of the fifth international conference on language resources and evaluation (LREC 2006)
Turney PD (2001) Mining the web for synonyms: PMI-IR versus LSA on TOEFL. In: European conference on machine learning. Springer
Dumais ST, Furnas GW, Landauer TK, Deerwester S, Harshman R (1988) Using latent semantic analysis to improve access to textual information. In: Proceedings of the SIGCHI conference on human factors in computing systems. ACM
Stubbs M (2001) Computer-assisted text and corpus analysis: lexical cohesion and communicative competence. Handb Discourse Anal 18:304
Kumar P, Jaiswal UC (2016) A comparative study on sentiment analysis and opinion mining. Int J Eng Technol 8(2):938–943
Passaro LC, Pollacci L, Lenci A (2015) Item: a vector space model to bootstrap an italian emotive lexicon. CLiC It 60(15):215
Kaity M, Balakrishnan V (2019) An automatic non-English sentiment lexicon builder using unannotated corpus. J Supercomput 1–26
Turney PD (2002) Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. In: Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, pp 417–424. https://doi.org/10.3115/1073083.1073153
Turney PD, Littman ML (2002) Unsupervised learning of semantic orientation from a hundred-billion-word corpus. arXiv:cs/0212012
Pozzi FA, Fersini E, Messina E, Liu B (2017) Chapter 1—Challenges of sentiment analysis in social networks: an overview. In: Sentiment analysis in social networks. Morgan Kaufmann, Boston, pp 1–11
Lafourcade M, Le Brun N, Joubert A (2016) Mixing crowdsourcing and graph propagation to build a sentiment lexicon: feelings are contagious. In: Metais E et al (eds) Natural language processing and information systems, NLDB 2016. Springer, Cham, pp 258–266
Yuang CT, Banchs RE, Siong CE (2012) An empirical evaluation of stop word removal in statistical machine translation. In: Proceedings of the joint workshop on exploiting synergies between information retrieval and machine translation (ESIRMT) and hybrid approaches to machine translation (HyTra). Association for Computational Linguistics
Al-Kabi MN, Kazakzeh SA, Ata BMA, Al-Rababah SA, Alsmadi IM (2015) A novel root based Arabic stemmer. J King Saud Univ Comput Inf Sci 27(2):94–103
Zhang Y, Tsai FS (2009) Chinese novelty mining. In: Proceedings of the 2009 conference on empirical methods in natural language processing: volume 3. Association for Computational Linguistics
Abdul-Mageed M (2017) Modeling Arabic subjectivity and sentiment in lexical space. Inf Process Manag 56(2):291–307
Taboada M, Brooke J, Tofiloski M, Voll K, Stede M (2011) Lexicon-based methods for sentiment analysis. Comput Linguist 37(2):267–307
Manning C, Surdeanu M, Bauer J, Finkel J, Bethard S, McClosky D (2014) The Stanford CoreNLP natural language processing toolkit. In: Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations
Honnibal M, Montani I (2017) Spacy 2: natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing ( to appear )
Qiu X, Zhang Q, Huang X (2013) Fudannlp: a toolkit for chinese natural language processing. In: Proceedings of the 51st annual meeting of the association for computational linguistics: system demonstrations, pp 49–54
Abdelali A, Darwish K, Durrani N, Mubarak H (2016) Farasa: a fast and furious segmenter for Arabic. In: HLT-NAACL Demos
Zhang H-P, Yu H-K, Xiong D-Y, Liu Q (2003) HHMM-based Chinese lexical analyzer ICTCLAS. In: Proceedings of the second SIGHAN workshop on Chinese language processing-volume 17. Association for Computational Linguistics
Hussein DME-DM (2016) A survey on sentiment analysis challenges. J King Saud Univ Eng Sci
Bravo-Marquez F, Frank E, Pfahringer B (2016) Building a Twitter opinion lexicon from automatically-annotated tweets. Knowl Based Syst 108:65–78
Yue L, Chen W, Li X, Zuo W, Yin M (2018) A survey of sentiment analysis in social media. Knowl Inf Syst 1–47
Tang D, Wei F, Qin B, Zhou M, Liu T (2014) Building large-scale Twitter-specific sentiment lexicon: a representation learning approach. In: Proceedings of coling 2014, the 25th international conference on computational linguistics: technical papers, pp 172–182
Wang L, Xia R (2017) Sentiment lexicon construction with representation learning based on hierarchical sentiment supervision. In: Proceedings of the 2017 conference on empirical methods in natural language processing
Kong L, Li C, Ge J, Yang Y, Zhang F, Luo B (2018) Construction of microblog-specific chinese sentiment lexicon based on representation learning. In: Pacific Rim international conference on artificial intelligence. Springer
Amir S, Astudillo R, Ling W, Martins B, Silva MJ, Trancoso I (2015) Inesc-id: a regression model for large scale twitter sentiment lexicon induction. In: Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015)
Dong X, de Melo G (2018) Cross-lingual propagation for deep sentiment analysis. In: Proceedings of the 32nd AAAI conference on artificial intelligence (AAAI 2018). AAAI Press
Bojanowski P, Grave E, Joulin A, Mikolov T (2017) Enriching word vectors with subword information. Trans Assoc Comput Linguist 5:135–146
Tang D, Qin B, Liu T (2015) Deep learning for sentiment analysis: successful approaches and future challenges. Wiley Interdiscip Rev Data Min Knowl Discov 5(6):292–303
Wang K, Xia R (2016) A survey on automatical construction methods of sentiment lexicons. Acta Automatica Sinica 42(4):495–511
Download references
Author information
Authors and affiliations.
Department of Information Systems, Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
Mohammed Kaity & Vimala Balakrishnan
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Vimala Balakrishnan .
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Kaity, M., Balakrishnan, V. Sentiment lexicons and non-English languages: a survey. Knowl Inf Syst 62 , 4445–4480 (2020). https://doi.org/10.1007/s10115-020-01497-6
Download citation
Received : 10 October 2018
Accepted : 14 July 2020
Published : 22 July 2020
Issue Date : December 2020
DOI : https://doi.org/10.1007/s10115-020-01497-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Sentiment analysis
- Sentiment Lexicon
- Lexicon-based
- Multilingual sentiment analysis
- Find a journal
- Publish with us
- Track your research
Top 8 Sentiment Analysis Datasets in 2024
Cem is the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per Similarweb) including 60% of Fortune 500 every month.
Cem's work focuses on how enterprises can leverage new technologies in AI, automation, cybersecurity(including network security, application security), data collection including web data collection and process intelligence.
Sentiment analysis is a great way to understand the customers’ feelings toward a company and to see if they are associated with sales, investments, or agreements. Ensuring a reliable sentiment analysis depends on many factors, and one of its building blocks is the dataset used to train the models. However, finding the right dataset is easier said than done.
This article highlights the top sentiment analysis datasets to train your algorithms for more efficient and accurate sentiment analysis.
Although the quantity of the data is crucial, the quality or relevancy is also essential to have reliable results. For instance, if a retail company uses a dataset with financial jargon to train a customer sentiment analysis model, the algorithm may not provide reliable results as the words which the algorithm evaluates will be from a financial context.
So, having the right training dataset is crucial in evaluating the reviews, as you can develop new strategies with the insights you gather. Here we list the top eight sentiment analysis datasets to help you train your algorithm to obtain better results.
1. Amazon Review Data
This dataset contains information regarding product information (e.g., color, category, size, and images) and more than 230 million customer reviews from 1996 to 2018. The reviews are labeled based on their positive, negative, and neutral emotional tone.
Clickworker is a crowdsourced data collection expert and can provide the data required to fuel an open-source sentiment analysis tool. It works with 4 million registered data collectors worldwide who have proficiency in 30 languages and cover over 70 target markets.
They can help your company with sentiment analysis services using a pre-determined training dataset to understand your customers better.
2. Stanford Sentiment Treebank
Most sentiment analysis tools categorize the sentences by giving sentiment scores to each word without considering the sentence as a whole. Here , you can find almost 10,000 reviews on movies with sentiment scores ranging from 1 to 25. While 1 represents the most negative reviews and 25 corresponds to the most positive ones.
Figure 1. An example of a movie review and the sentiment score of each aggregate

3. Financial Phrasebank
The financial phrase bank dataset contains almost 5000 English sentences from financial news, and all sentences are classified based on their emotional tones as either positive, negative, or neutral. All the data is annotated by researchers knowledgeable in the finance domain.
Figure 2. Examples of the sentences from financial news and the corresponding sentiment label class

4. Webis-CLS-10 Dataset
Webis cross-lingual sentiment dataset includes 800.000 Amazon product reviews in English, German, French, and Japanese. Its multilingual nature allows for reaching more audiences and conducting comprehensive analyses.
5. CMU Multimodal Opinion Sentiment and Emotion Intensity
Not only do texts contain customers’ sentiments regarding services or products, but they can also be detected from videos or audio. CMU dataset includes multimodal data extracted from Youtube videos, such as the sentences and the voice tone used.
Figure 3. The word cloud of the topics mentioned in the videos

6. Yelp Polarity Reviews
This open-source dataset includes more than 500,000 training samples consisting of consumer reviews, ratings, and recommendations. The polarity score of each sentence is determined, and the keywords requested can be extracted.
7. WordStat Sentiment Dictionary
Wordstat Sentiment Dictionary classifies sentiments as negative or positive and combines three dictionaries: Harvard IV Dictionary, Regressive Imagery Dictionary, and Linguistic and Word Count Dictionary. The combination of different dictionaries allows for identifying synonyms and word patterns automatically.
8. Sentiment Lexicons For 81 Languages
Although English is the most spoken language globally, it is also crucial to analyze the sentiment of other language speakers. This dataset includes 81 languages such as Chinese, Spanish, and German, so it offers a variety of data from different languages and represents the worldwide sentiment better.
Using a trained dataset to run your algorithm is essential in sentiment analysis. So, working with reliable sources matters.
You can also check our data-driven list of sentiment analysis services.
Further Reading
- Consumer Insights: Why Is It Essential & Top 4 Data Sources
- How to Benefit From Social Media Sentiment Analysis?
- Top 5 Sentiment Analysis Challenges & Solutions
If you have further questions about sentiment analysis, do not hesitate to reach us:
This article was originally written by former AIMultiple industry analyst Begüm Yılmaz and reviewed by Cem Dilmegani.

Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Cem's hands-on enterprise software experience contributes to the insights that he generates. He oversees AIMultiple benchmarks in dynamic application security testing (DAST), data loss prevention (DLP), email marketing and web data collection. Other AIMultiple industry analysts and tech team support Cem in designing, running and evaluating benchmarks.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
AIMultiple.com Traffic Analytics, Ranking & Audience , Similarweb. Why Microsoft, IBM, and Google Are Ramping up Efforts on AI Ethics , Business Insider. Microsoft invests $1 billion in OpenAI to pursue artificial intelligence that’s smarter than we are , Washington Post. Data management barriers to AI success , Deloitte. Empowering AI Leadership: AI C-Suite Toolkit , World Economic Forum. Science, Research and Innovation Performance of the EU , European Commission. Public-sector digitization: The trillion-dollar challenge , McKinsey & Company. Hypatos gets $11.8M for a deep learning approach to document processing , TechCrunch. We got an exclusive look at the pitch deck AI startup Hypatos used to raise $11 million , Business Insider.
To stay up-to-date on B2B tech & accelerate your enterprise:
Next to Read
Top 7 examples of chatgpt sentiment analysis in 2024, top 3 sentiment analysis services in 2024, 5 use cases/applications of healthcare sentiment analysis in 2024.
Your email address will not be published. All fields are required.
Related research

Fake Review Detection in 2024: How it works & 3 Case Studies

Our Customer Success Stories
Repustate has helped organizations worldwide turn their data into actionable insights. Learn how these insights helped them increase productivity, customer loyalty, and sales revenue.
Table of Contents
Top Sources Of Sentiment Analysis Datasets
To train a sentiment analysis model, we need machine learning techniques to help the model learn data patterns from specialized sentiment analysis datasets. Powered by artificial intelligence, when the sentiment analysis model is trained on these datasets, it knows how to behave when presented with new data in a similar vein; improving the accuracy of data analysis stage of sentiment analysis process . If you are a company in the hospitality industry, you will need a model that has been trained on datasets that are collected and tagged from the hospitality industry. And so is the case with all industry verticals.
Such datasets need to be very wide in their scope of sentiment analysis applications and business cases. An efficiently trained sentiment model that can accurately analyze sentiment from text as well as videos, through video content analysis , is an invaluable asset for business intelligence. It can help you gain customer insights from not only reviews and surveys but also social platforms like YouTube, TikTok, Facebook, etc.
In the article, we present the top sources for great sentiment analysis datasets for various industries.
Why Is Sentiment Analysis Important For Business?
Sentiment analysis is important to all marketing departments for brand insights. It is used for social media monitoring, brand reputation monitoring, voice of the customer (VoC) data analysis, market research, patient experience analysis, and other functions. Sentiment analysis features employ the use of natural language processing (NLP) tasks and named entity recognition (NER) to identify and categorize entities and topics present in the data.
With an aspect-based sentiment analysis (ABSA) approach, companies can find extremely fine-grained insights from all sources of data for insights such as patient notes, EMRs, customer call logs, etc. There are however challenges that companies sometimes face while conducting sentiment analysis. You can read about sentiment analysis challenges and the solutions here.
Which are the top sentiment analysis datasets for machine learning?
Here are some top sentiment analysis datasets on various specialties and industries. They are free for download.
- Amazon product data :
This dataset has amazon product reviews and metadata including 142.8 million reviews spanning May 1996 to July 2014. It has reviews including ratings, text, and helpfulness votes. Product metadata includes descriptions, brand, category, price, and image features. The dataset also has links to views and purchase graphs. Read more about sentiment analysis on large scale amazon product reviews .
- OpinRank Review Dataset for hotels and cars:
This is one of those rare sentiment analysis datasets that has complete reviews on both the automotive and the hotel industries. It has 2,59,000 hotel reviews and 42,230 car reviews collected from TripAdvisor and Edmunds, respectively. Details include dates, favorite hotels and car models, user names, and the full review in text. The dataset contains information from 10 different cities including Dubai, Beijing, Las Vegas, and San Fransisco.
- Stanford Sentiment Dataset :
This dataset gives you recursive deep models for semantic compositionality over a sentiment treebank. It has more than 10,000 pieces of Stanford data from HTML files of Rotten Tomatoes.
- Cornell Movie Review Dataset:
This sentiment analysis dataset contains 2,000 positive and negatively tagged reviews. It also has more than 10,000 negative and positive tagged sentence texts.
- Lexicoder Sentiment Dictionary :
Another one of the key sentiment analysis datasets, this one is meant to be used within the Lexicoder that performs the content analysis. The dictionary has 2,800+ negative sentiment words and 1,709 positive sentiment words.
- Twitter US Airline Dataset :
This dataset contains tweets about all the major US airlines, since Feb 2015. It includes the Twitter user IDs, sentiment confidence score, negative and positive reasons, retweet counts, tweet text, date, time, and location.
This sentiment analysis dataset comprises positive and negative tagged reviews for thousands of Amazon products. The reviews contain ratings from 1 to 5 stars, which can be converted to binary if required.
- Opinion Lexicon :
This dataset provides a list of close to 7000 positive and negative opinion words or sentiment words in English.
- Paper Reviews Dataset :
One of the best sentiment analysis datasets in the English and Spanish languages, it gives reviews on computing and informatics conferences. You will notice a difference between how the paper is evaluated versus how the review was written by the original reviewer.
- First GOP Debate Twitter Sentiment:
This sentiment analysis dataset consists of around 14,000 labeled tweets that are positive, neutral, and negative about the first GOP debate that happened in 2016.
- IMDB Reviews Dataset :
This dataset contains 50K movie reviews from IMDB that can be used for binary sentiment classification. There are a set of 25,000 highly polar movie reviews for training and 25,000 for testing.
- Sentiment Polarity Lexicons For 81 Languages :
Among the many sentiment analysis datasets in multiple languages, this one is the most generous. It contains positive and negative sentiment lexicons for 81 languages. The sentiments were built based on English sentiment lexicons. The lexica were generated through graph propagation for the sentiment analysis based on a knowledge graph.
Click here to understand major sentiment analysis applications .
Finding The Right Sentiment Analysis API
Repustate’s sentiment analysis platform has been trained on sentiment analysis datasets in multiple industries. The engine processes millions of reviews per day for hundreds of clients across the globe. It enables real-time social media sentiment analysis and does so in 23 languages, natively. It provides topic-driven and aspect-based sentiment analysis and has a processing speed is 1,000 reviews per second.
Highly customizable and scalable, Repustate’s sentiment analysis API has been instrumental in supporting companies across industries in their business endeavors. From helping AARP develop a brand new diet program , to providing vital information to the Kingdom of Saudia Arabia in its healthcare plan, our solution helps you keep score of about each aspect of your business.
Additionally, our sentiment visualization dashboard gives you insights in graphs and charts so you can understand your data easily and get actionable insights
Join leading companies using Repustate
The implementation was seamless thanks to their developer friendly API and great documentation. Whenever our team had questions, Repustate provided fast, responsive support to ensure our questions and concerns were never left hanging.

We tried many vendors whose speed and accuracy were not as good as Repustate's. Arabic text data is not easy to mine for insight, but with Repustate we have found a technology partner who is a true expert in the field.

We are very satisfied with the accuracy of Repustate's Arabic sentiment analysis, as well as their and support which helped us to successfully deliver the requirements of our clients in the government and private sector.

We were blown away by the fact that they were able to put together a demo using our own YouTube channels on just a couple of days notice. What really stood out was the built-in semantic search capability.

Related Articles

Top 10 Word Cloud Generators
Top word cloud generation tools can transform your insight visualizations with their creativity, and give them an edge.

Top 8 Data Analysis Companies
Data analysis companies provide invaluable insights for growth strategies, product improvement, and market research that businesses rely on for profitability and sustainability.

Top 10 Data Cleaning Techniques for Better Results
Data cleaning techniques are essential to getting accurate results when you analyze data for various purposes, such as customer experience insights, brand monitoring, market research, or measuring employee satisfaction.
Analysis and Evaluation of Sentiments in Online Communities
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
- Cambridge Dictionary +Plus
Meaning of sentiment analysis in English
- Sentiment analysis can be used to analyze customer feedback , such as reviews , surveys , and social media posts .
- In recent years , the interest among the research community in sentiment analysis has grown exponentially .
- Kaya, Fidan and Toroslu (2012) investigated sentiment analysis of Turkish political news in online media .
- adverse publicity
- cross-selling
- customer relationship management
- differentiator
- opinion mining
- trade dress
- unadvertised
You can also find related words, phrases, and synonyms in the topics:

Word of the Day
have your head in the clouds
to not know the facts of a situation

Apples and oranges (Talking about differences, Part 2)

Learn more with +Plus
- Recent and Recommended {{#preferredDictionaries}} {{name}} {{/preferredDictionaries}}
- Definitions Clear explanations of natural written and spoken English English Learner’s Dictionary Essential British English Essential American English
- Grammar and thesaurus Usage explanations of natural written and spoken English Grammar Thesaurus
- Pronunciation British and American pronunciations with audio English Pronunciation
- English–Chinese (Simplified) Chinese (Simplified)–English
- English–Chinese (Traditional) Chinese (Traditional)–English
- English–Dutch Dutch–English
- English–French French–English
- English–German German–English
- English–Indonesian Indonesian–English
- English–Italian Italian–English
- English–Japanese Japanese–English
- English–Norwegian Norwegian–English
- English–Polish Polish–English
- English–Portuguese Portuguese–English
- English–Spanish Spanish–English
- English–Swedish Swedish–English
- Dictionary +Plus Word Lists
- English Noun
- All translations
To add sentiment analysis to a word list please sign up or log in.
Add sentiment analysis to one of your lists below, or create a new one.
{{message}}
Something went wrong.
There was a problem sending your report.

- Conferences
Top 10 Sentiment Analysis Dataset
- By Sameer Balaganur
- Last Updated on May 16, 2024
What are Sentiment Analysis Dataset?
Sentiment analysis has found its applications in various fields that are now helping enterprises to estimate and learn from their clients or customers correctly. Sentiment analysis is increasingly being used for social media monitoring, brand monitoring, the voice of the customer (VoC), customer service, and market research. Sentiment analysis uses NLP methods and algorithms that are either rule-based, hybrid, or rely on machine learning techniques to learn data from datasets.
The data needed in sentiment analysis should be specialised and are required in large quantities. The most challenging part about the sentiment analysis training process isn’t finding data in large amounts; instead, it is to find the relevant datasets. These data sets must cover a wide area of sentiment analysis applications and use cases.

10 Most Popular Sentiment Analysis Datasets in 2024
Below are listed some of the most popular datasets for sentiment analysis.
1. Amazon Product Data
Amazon product data is a subset of a large 142.8 million Amazon review dataset that was made available by Stanford professor, Julian McAuley. This sentiment analysis dataset contains reviews from May 1996 to July 2014. The dataset reviews include ratings, text, helpfull votes, product description, category information, price, brand, and image features.
Link to Amazon product dataset
2. Stanford Sentiment Treebank
This dataset contains just over 10,000 pieces of Stanford data from HTML files of Rotten Tomatoes. The sentiments are rated between 1 and 25, where one is the most negative and 25 is the most positive. The deep learning model by Stanford has been built on the representation of sentences based on the sentence structure instead just giving points based on the positive and negative words. For example: The Interview was neither that funny nor that witty. Even if there are words like funny and witty, the overall structure is a negative type.
Link to: Stanford Sentiment Treebank
Multi-Domain Sentiment Dataset
This dataset contains positive and negative files for thousands of Amazon products. Although the reviews are for older products, this data set is excellent to use. The data derives from the Department of Computer Science at John Hopkins University. The reviews contain ratings from 1 to 5 stars that can be converted to binary as needed.
Download original data:
- Unprocessed.tar.gz
- processed_acl.tar.gz
- processed_stars.tar.gz
IMDB Movie Reviews Dataset
This large movie dataset contains a collection of about 50,000 movie reviews from IMDB. In this dataset, only highly polarised reviews are being considered. The positive and negative reviews are even in number; however, the negative review has a score of ≤ 4 out of 10, and the positive review has a score of ≥ 7 out of 10.
Link to: IMDB Movie Reviews Dataset
Sentiment140
Sentiment140 is used to discover the sentiment of a brand or product or even a topic on the social media platform Twitter. Rather than working on keywords-based approach, which leverages high precision for lower recall, Sentiment140 works with classifiers built from machine learning algorithms. The Sentiment140 uses classification results for individual tweets along with the traditional surface that aggregated metrics. The Sentiment140 is used for brand management, polling, and planning a purchase.
Link to: Sentiment140 Dataset
Twitter US Airline Sentiment
This sentiment analysis dataset contains tweets since Feb 2015 about each of the major US airline. Each tweet is classified either positive, negative or neutral. The included features including Twitter ID, sentiment confidence score, sentiments, negative reasons, airline name, retweet count, name, tweet text, tweet coordinates, date and time of the tweet, and the location of the tweet.
Link to: Twitter US Airline Sentiment
Paper Reviews Data Set
Paper Reviews Data Set contains reviews from English and Spanish languages on computing and informatics conferences. The algorithm used will predict the opinions of academic paper reviews. Most of the dataset for the sentiment analysis of this type is sent in Spanish. It has a total of instances of N=405 evaluated with a 5-point scale, -2: very negative, -1: neutral, 1: positive, 2: very positive. The distribution of the scores is uniform, and there exists a difference between the way the paper is evaluated and the review written by the original reviewer.
Link to: Paper Reviews Dataset
Sentiment Lexicons For 81 Languages
Sentiment Lexicons for 81 Languages contains languages from Afrikaans to Yiddish. This data includes both positive and negative sentiment lexicons for a total of 81 languages. These lexica were generated via graph propagation for the sentiment analysis based on a knowledge graph which is a graphical representation of real-world objects and the relationship between them. The general idea is that words closely linked on a knowledge graph may have similar sentiment polarities. The sentiments were built based on English sentiment lexicons.
Link to: Sentiment Lexicons For 81 Languages
Lexicoder Sentiment Dictionary
This dataset for the sentiment analysis is designed to be used within the Lexicoder, which performs the content analysis. This dictionary consists of 2,858 negative sentiment words and 1,709 positive sentiment words. In addition to that, 2,860 negations of negative and 1,721 positive words are also included. Anyone willing to test this is advised by the developers to subtract negated positive words from positive counts and subtract the negated negative words from the negative count.
Link to: Lexicoder Sentiment Dictionary Dataset
Opin-Rank Review Dataset
Opin-Rank Review Dataset contains full reviews on cars and hotels. This data set includes about 2,59,000 hotel reviews and 42,230 car reviews collected from TripAdvisor and Edmunds, respectively. The car dataset has the models from 2007, 2008, 2009 and has about 140-250 cars from each year. The fields include dates, favourites, author names, and full review in text. The dataset contains information from 10 different cities which include Dubai, Beijing, Las Vegas, San Fransisco, etc. There are reviews of about 80-700 hotels from each city. The fields include review, date, title and full-textual review.
Link to: Opin-Rank Review Dataset
Top 10 Cartoonist to Follow in 2024
The Best AI Search Engines in 2024 – Perplexity AI Alternatives
Different Types of Classification Algorithms
Top Most Important Reasons to Use Linux Operating System
Representation Learning – Complete Guide for Beginner
Augmented Dickey-Fuller (ADF) Test In Time-Series Analysis
Bidirectional LSTM (Long-Short Term Memory) with Python Codes
Scribble Diffusion – Converts Doddles and Sketch to AI Images
Best AI Image Generator in 2024
What is Unstable Diffusion – Difference Between Stable Vs Unstable?
Difference Between NVIDIA H100 Vs A100: Which is the best GPU?
Top 10 Space Observatories in India
How to Build Your First Generative AI Agent with Mistral 7B LLM
Mira Murati – CTO of OpenAI

Join the forefront of data innovation at the Data Engineering Summit 2024, where industry leaders redefine technology’s future.
© Analytics India Magazine Pvt Ltd & AIM Media House LLC 2024
- Terms of use
- Privacy Policy

Subscribe to our Youtube channel and see how AI ecosystem works.
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
- 10 Best AI Tools for Sentiment Analysis
- What is Sentiment Analysis?
- Sentiment Analysis of YouTube Comments
- Top 10 AI Tools for Data Analysis
- How to use PyTorch for sentiment analysis on textual data?
- Amazon Product Review Sentiment Analysis using RNN
- NLP Sentiment Analysis for US Election
- Aspect Modelling in Sentiment Analysis
- Fine-tuning BERT model for Sentiment Analysis
- Sentiment Analysis of Hindi Text - Python
- Facebook Sentiment Analysis using python
- Sentiment Analysis using JavaScript and API
- Python | Sentiment Analysis using VADER
- Python - Sentiment Analysis using Affin
- What is Data Analysis?
- Flipkart Reviews Sentiment Analysis using Python
- Exploratory Data Analysis in Julia
- Twitter Sentiment Analysis using Python
- EDA | Exploratory Data Analysis in Python
Dataset for Sentiment Analysis
Sentiment analysis, which helps understand how people feel and what they think, is very important in studying public opinions, customer thoughts, and social media buzz. But to make sentiment analysis work well, we need good datasets to train and test our systems. In this article, we will look at some of the popular datasets used for sentiment analysis and discuss them.

- List of Sentiment Analysis Datasets
Table of Content
1. IMDb Reviews Dataset
2. twitter sentiment analysis dataset, 3. amazon product reviews, 4. yelp reviews dataset, 5. sentiment140, 6. airbnb reviews dataset, 7. kaggle movie reviews dataset, 8. stanford sentiment treebank, 9. financial news sentiment analysis dataset, 10. semeval, 11. youtube comments dataset, 12. reddit comments dataset, 13. e-commerce reviews dataset, 14. hotel reviews dataset, 15. movielens dataset, why sentiment analysis is important, benefits of using sentiment analysis dataset, dataset for sentiment analysis faqs.
- The IMDb Reviews Dataset provides a wealth of information about movies and audience opinions. I
- it’s particularly useful for sentiment analysis tasks, where researchers and analysts can study how people feel about certain films.
- This dataset enables us to understand which movies are generally well-received and which ones might have faced criticism.
To download the dataset: Internet Movie Database (IMDb).
- Twitter is a goldmine for understanding public opinion in real-time.
- With the Twitter Sentiment Analysis Dataset, researchers can analyze the sentiment behind tweets, whether they’re expressing joy about a recent event, frustration about a political decision, or anything in between.
- This dataset helps to gauge the overall sentiment of Twitter users on various topics.
To download the dataset : Twitter Sentiment Analysis
- As one of the largest online marketplaces, Amazon generates massive amounts of customer feedback.
- The Amazon Product Reviews dataset allows businesses and analysts to gain insights into customer satisfaction levels, product quality, and areas for improvement.
- By categorizing reviews into positive and negative sentiments, companies can understand what aspects of their products resonate with customers and what needs improvement.
To download the dataset: Amazon Product Reviews
- Yelp is a go-to platform for people looking for recommendations on restaurants, hotels, and various services.
- The Yelp Reviews Dataset provides valuable insights into customer experiences and satisfaction levels.
- Businesses can use this dataset to monitor and improve their services based on feedback from customers.
The dataset can be downloaded from the official website.
- With Sentiment140, researchers can analyze the sentiment expressed in tweets.
- This dataset is particularly valuable for understanding public opinion on social media platforms like Twitter.
- By categorizing tweets into positive and negative sentiments, analysts can identify trends, monitor public sentiment on specific topics, and track changes over time.
- The Airbnb Reviews Dataset offers insights into the experiences of guests who have stayed at various accommodations listed on the platform.
- By analyzing sentiment labels attached to reviews, hosts and property managers can understand guest satisfaction levels and areas for improvement.
- This dataset helps in providing better hospitality services and enhancing the overall guest experience.
To download the dataset: Airbnb Reviews Dataset
- The Kaggle Movie Reviews Dataset is a treasure trove of opinions about movies.
- By analyzing sentiment labels associated with movie reviews, filmmakers, critics, and movie enthusiasts can gain insights into audience preferences and sentiments.
- This dataset aids in understanding which aspects of a movie resonate with viewers and which ones may need improvement.
- The Stanford Sentiment Treebank offers a detailed perspective on sentiment analysis.
- With hierarchical sentiment annotations, researchers can delve deep into the structure of sentences and phrases to understand the nuances of sentiment expression.
- This dataset is valuable for fine-grained sentiment analysis tasks and improving the accuracy of sentiment analysis models.
- Financial markets are heavily influenced by news and public sentiment.
- The Financial News Sentiment Analysis Dataset provides annotated news articles with sentiment polarity, allowing analysts to gauge market sentiment and investor opinions.
- By understanding the sentiment behind financial news, traders and investors can make more informed decisions.
- SemEval datasets cover a wide range of sentiment analysis tasks across different domains and languages.
- Researchers and developers can use these datasets to benchmark sentiment analysis models and evaluate their performance on various tasks.
- SemEval datasets provide a standardized evaluation framework for advancing the field of sentiment analysis.
- YouTube is a popular platform for sharing and consuming video content.
- The YouTube Comments Dataset contains comments from users, providing insights into viewer reactions and opinions.
- By analyzing sentiment labels attached to comments, content creators and marketers can understand audience engagement and tailor their content accordingly.
- Reddit is known for its diverse communities and discussions on various topics.
- The Reddit Comments Dataset offers insights into community sentiment and discussions across different subreddits.
- By analyzing sentiment labels attached to comments, researchers can understand prevailing opinions and sentiments on specific topics discussed on Reddit.
- The E-commerce Reviews Dataset includes feedback from customers on e-commerce platforms like eBay and Etsy.
- By categorizing reviews into positive and negative sentiments, businesses can understand customer satisfaction levels, identify popular products, and address any issues or concerns raised by customers.
- This dataset helps in improving the overall shopping experience for online shoppers.
- The Hotel Reviews Dataset provides insights into guest experiences and satisfaction levels at hotels listed on booking platforms like Booking.com and TripAdvisor.
- By analyzing sentiment labels attached to reviews, hotel managers and staff can identify areas for improvement and enhance the quality of services provided to guests.
- This dataset is invaluable for maintaining high standards of hospitality and guest satisfaction.
- The MovieLens Dataset contains user ratings and reviews of movies, offering insights into viewer preferences and sentiments.
- By analyzing sentiment expressed in reviews, movie recommendation systems can better understand user preferences and provide personalized recommendations.
- This dataset helps in enhancing the movie-watching experience for viewers by recommending movies they’re likely to enjoy.
- Sentiment analysis plays a crucial role in understanding and leveraging human emotions and opinions, offering valuable insights across various domains without revealing AI-generated content. In business, it helps companies gauge customer satisfaction, improve products and services, and enhance overall customer experience.
- By analyzing sentiment, businesses can identify emerging trends, predict customer behavior, and tailor their marketing strategies accordingly. In social media, sentiment analysis helps track public opinion on various topics, monitor brand reputation, and detect potential crises.
- High-quality datasets to be used for sentiment analysis is critical for training precise machine learning models. These datasets offer a range of texts with sentiment labels, enabling algorithms to discern patterns and make accurate forecasts.
- Employing such datasets can enhance the effectiveness of sentiment analysis systems for businesses, providing them with more dependable insights. This, in turn, enables a deeper understanding of customer opinions, preferences, and behaviors, which can be utilized to enhance products, services, and marketing approaches.
- Moreover, sentiment analysis datasets empower researchers and developers to progress in natural language processing (NLP) and create more advanced algorithms for sentiment analysis, benefiting sectors such as e-commerce, social media, and customer services.
What is a sentiment analysis dataset?
A sentiment analysis dataset is a collection of text data annotated with sentiment labels. These labels indicate the sentiment expressed in the text, typically categorized as positive, negative, or neutral. Some datasets may also include more granular sentiment categories or intensity levels.
How do I choose the right dataset for my sentiment analysis project?
When choosing a dataset, consider the following factors: Domain Relevance: Select a dataset that matches the domain of your project (e.g., movie reviews, product reviews, social media). Dataset Size: Ensure the dataset is large enough to train your model effectively. Annotation Quality: Check if the sentiment labels are accurately and consistently annotated. Granularity of Sentiment Labels: Determine if you need binary (positive/negative), ternary (positive/negative/neutral), or more fine-grained sentiment labels.
How can I evaluate the performance of my sentiment analysis model?
Evaluate your model using metrics such as: Accuracy: The proportion of correctly predicted sentiment labels. Precision, Recall, and F1 Score: Useful for imbalanced datasets, where F1 Score is the harmonic mean of precision and recall. Confusion Matrix: Provides a detailed breakdown of true positives, true negatives, false positives, and false negatives.

Please Login to comment...
Similar reads.
- Data Science Blogathon 2024
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
What is Customer Sentiment Score & How to Measure It?

The customer sentiment score can help you tell how well-perceived your brand is.
But how can you measure and improve it?
Let’s explore the customer sentiment score, how to measure it with user feedback , and what strategies you can execute to elevate the customer experience.
- Customer sentiment refers to customers’ emotions and attitudes towards your brand, providing insights into their satisfaction levels .
- The customer sentiment score quantifies customers’ emotions and attitudes towards your brand, ranging from 0 to 100.
- A good sentiment score varies by industry. Higher scores indicate more positive customer feelings and benchmarks differing across sectors (in SaaS being 40).
- Measuring customer sentiment helps understand customer needs, enhance customer experience, boost retention , reduce churn guide business strategy, and monitor brand health.
- Here are the steps to perform a customer sentiment analysis:
- Invest in sentiment analysis tools to gather and analyze feedback accurately with features like real-time analysis and multi-source integration.
- Collect customer feedback through in-app surveys like NPS , CSAT , and CES surveys to capture timely and relevant insights.
- Analyze survey responses to identify common themes and sentiments, uncovering specific issues and areas of satisfaction.
- Assign positive and negative scores to responses to calculate the overall customer sentiment score and track changes over time.
- Combine sentiment scores with other data points to gain a holistic view of the customer experience (and create a customer-centric experience ).
- Let’s go over some strategies to improve your customer sentiment score:
- Improve customer experience based on feedback insights, prioritizing areas of dissatisfaction to enhance customer satisfaction .
- Track customer sentiment score to measure the effectiveness of product strategies and identify areas for improvement.
- Proactively engage with customers through direct interactions, personalized emails , and loyalty programs to improve satisfaction.
- Personalize customer interactions by segmenting the user base and tailoring communications, offers, and support to individual preferences.
- Userpilot can help you to: collect feedback for customer sentiment analytics, analyze customer profiles , access the NPS dashboard , and create customized in-app flows to improve customer sentiment.
- You’ll need a platform to do this. Why not book a Userpilot demo to see how you can gather feedback, calculate your score, and increase it?

Try Userpilot and Take Your Customer Experience to the Next Level
- 14 Day Trial
- No Credit Card Required

What is customer sentiment?
Customer sentiment refers to customers’ emotions and attitudes towards your brand, product, or service. It touches on their overall feelings—whether positive, negative, or neutral—and provides insights into their satisfaction and loyalty levels.
It goes beyond surface-level feedback and it involves analyzing feedback from various sources (such as social media, customer reviews, surveys , and direct interactions). This way, you can identify areas of improvement and enhance the product experience to meet customer needs more effectively.
What is the customer sentiment score?
The customer sentiment score is a quantitative metric that measures customers’ emotions and attitudes toward your brand, product, or service.
It ranges from 0 to 100, and it’s calculated by subtracting the percentage of negative responses ( detractors ) to the percentage of positive responses (promoters).
What is a good sentiment score?
A good sentiment score can vary widely depending on the industry and specific benchmarks. Generally, a higher sentiment score indicates a more positive overall customer feeling.
But what’s considered “good” can differ from one sector to another. For example, according to Retently’s 2024 NPS benchmark , here’s the average sentiment score for each industry:
- Insurance: 80
- Consulting: 76
- Financial Services: 73
- Technology & Services: 61
- Ecommerce: 52
- Digital Marketing Agencies: 59
- B2B Software & SaaS: 40
- Logistics & Transportation: 40
- Construction: 37
- Cloud & Hosting: 39
- Internet Software & Services: 16.
That said, a score between 0-30 can be pretty regular (with room for improvement). Higher than that, and your business is doing a good job at keeping generating promoters (more than 70 is excellent and translates into massive word-of-mouth results).
Why is it crucial to measure customer sentiment?
Measuring and analyzing customer sentiment helps you stay aligned with your customer’s expectations and make improvements to enhance their overall experience.
Not only that, staying on track with your customer sentiment is essential for several other reasons too, including:
- Understand Customer Needs: You can gain insights into what your customers value most and what pain points they experience—and provide a better service.
- Enhance Customer Experience : You can identify areas where your service excels and areas that need improvement, leading to more satisfied and loyal customers .
- Boost Customer Retention : Customers who feel positively about your brand are more likely to stay loyal and continue using your products or services.
- Guide Business Strategy : Customer sentiment data provides actionable insights that can guide customer success , marketing, product development, customer service , and even sales.
- Monitor Brand Health : Keeping a pulse on customer sentiment helps you understand how your brand is perceived in the market and its reputation.
How to perform customer sentiment analysis?
Performing customer sentiment analysis involves several steps, from collecting feedback to deriving actionable insights.
Let’s go over each of them:
Invest in sentiment analysis tools
First, you’ll need the right software to gather and analyze feedback. Sentiment analysis tools are designed to interpret and categorize customer feedback accurately—and provide actionable feedback.
A good tool should include:
- Real-time analysis so you can stay up-to-date with the latest data at any time.
- Integration with multiple feedback sources (such as social media, NPS surveys , and reviews).
- Survey builder so you can create, customize, and trigger sentiment surveys like NPS, CSAT, and CES.
- Detailed reporting capabilities where you can track changes over time and predict future trends based on customer data.
Collect customer feedback
Now, you can start gathering feedback.
For this, in-app surveys are an effective way to capture user feedback in real-time, directly within your app. These surveys can be triggered at strategic points in the user journey , ensuring that you capture relevant and timely feedback.
Some of these include:
- NPS surveys. It asks customers how likely they are to recommend your product or service to others on a scale of 0 to 10. Great for measuring customer loyalty and differentiate between promoters, passives, and detractors.

- CSAT surveys. Ask users how satisfied they are with your product, a feature, support, etc.
- CES surveys. It measures how much effort it takes to use your product.
Pro tip: Follow up these surveys with an open-ended question so users can provide more details behind their answers.
Analyze survey responses
Once you’ve collected feedback, it’s time to visualize the data to identify common words and sentiments among user responses.
Your sentiment analysis tool of choice will show you how many responses you got, what answers were chosen (and their percentage), and the individual answers to the open-ended questions.
Here, dive deeper into the responses to uncover specific issues, praises, and suggestions. Look for recurring themes and patterns that can highlight common pain points or areas of satisfaction.
The goal is to reveal the underlying causes of customer sentiment, enabling you to address root issues effectively.

Give positive and negative scores to responses
Now, to calculate the customer sentiment score, you need to assign a sentiment to each response.
In general, positive feedback receives the highest scores, negative sentiments receive a low score, and neutral sentiment falls in between. For example, for NPS surveys , promoters respond with a score of 9-10, detractors with a score of 1-5, and neutrals between 6 and 8.
This scoring process can be done manually or automated using sentiment analysis tools that assign scores based on the detected sentiment. The result will be your customer sentiment score, making it easier to track changes and trends over time.
This way, you can get a snapshot of customer sentiment at a given time. And as a result, assess the effectiveness of your product strategies .

Gather customer sentiment insights
Combining sentiment scores with other data points provides a holistic view of the customer experience .
For example, pairing sentiment analysis data with customer demographics, purchase history, and usage patterns can reveal deeper insights into how your product resonates with different customer segments —and decide how to make your product appeal to those audiences.
This way, if sentiment analysis reveals dissatisfaction with a particular feature, you can prioritize improvements in that area. If other aspects of your product get positive customer sentiment, leverage these strengths in your marketing and customer engagement efforts .
As a result, you can create a more customer-centric approach that leads to a bigger community of loyal customers.
How to improve customer sentiment score
Now, let’s look at four key strategies to improve customer sentiment score:
Improve customer experience based on the insights from customer feedback
A high customer sentiment score is often linked to a smooth customer experience.
That said, you can use CSAT or CES surveys to identify areas where customers have expressed dissatisfaction and prioritize addressing these issues to enhance the customer experience.
This data can also be used as a qualitative customer service metric. For example, if customers frequently mention slow response times from customer support , invest in training and expanding your support team to ensure quicker and more efficient responses.
Regularly measure customer sentiment score
Regularly tracking customer sentiment scores is crucial for tracking the effect of your product strategies and identifying more areas for improvement.
For this, make sure to send surveys frequently and perform sentiment analysis every quarter as you implement different strategies.
The best moments to do this can be after major product updates , during key business milestones, or following significant marketing campaigns.
As a result, you’ll be able to gauge the immediate impact of your actions and adjust strategies accordingly.
Proactively engage with customers to improve customer satisfaction
One way to improve sentiment scores is to get yourself out there and engage more with customers.
This can mean reaching out to customers directly to gather feedback , address specific concerns, and show appreciation for their loyalty. You can also send personalized emails , follow up with surveys, and provide direct customer support to make customers feel valued and heard.
For example, you can implement a loyalty program that rewards (e.g. discounts, early access, exclusive content) customers for providing feedback, engaging with your product, and bringing referrals . This way, you can provide value to your user base and improve their sentiment toward your brand.
Personalize customer interactions
According to a McKinsey study , 76 to 78% of consumers are more likely to purchase, recommend, and make repeat purchases from companies that personalize the customer experience (i.e. better customer sentiment).
The best way to personalize CX is by segmenting your user base and designing communications, offers, and support experiences to individual preferences and behaviors.
For instance, you can personalize email campaigns by addressing customers by their names and recommending products based on their past purchases. This level of personalization makes customers feel recognized and appreciated, leading to more positive sentiments.
Tracking and improving customer sentiment score with Userpilot
Userpilot offers a comprehensive suite of tools designed to help you track and improve your customer sentiment score.
Here’s how you can leverage Userpilot’s features to enhance customer satisfaction:
- Collect feedback by creating and triggering in-app surveys inside your app, such as NPS surveys , CES surveys , and CSAT surveys . These can be triggered automatically so you can collect feedback on your sleep.
- Analyze customer’s profiles to check their survey responses and track their sentiment. This way, you can identify patterns or trends from different customer segments.
- Get access to an NPS dashboard where you can watch metrics like NPS, response rates, and the distribution of promoters, passives, and detractors . You can also filter results by different segments to get deeper insights.

- Create customized in-app flows and onboarding experiences based on customer feedback and sentiment analysis. Including built-in tracking features to watch over the performance of tooltips , checklists , and so on.
Understanding and improving your customer sentiment score can lead to enhanced customer satisfaction, boost customer loyalty, and drive long-term growth.
By taking the time to regularly measure and act on customer sentiment data, you’ll be able to stay aligned with your customer’s needs and expectations.
Since you’ll need a platform to do this, why not book a Userpilot demo to see how you can gather feedback, calculate your score, and increase it?
Try Userpilot and Take Your Product Growth to the Next Level
Leave a comment cancel reply.
Save my name, email, and website in this browser for the next time I comment.

Get The Insights!
The fastest way to learn about Product Growth,Management & Trends.
The coolest way to learn about Product Growth, Management & Trends. Delivered fresh to your inbox, weekly.
The fastest way to learn about Product Growth, Management & Trends.
You might also be interested in ...
What is ux design: your essential guide to user experience fundamentals, what is customer sentiment score & how to measure it.
Aazar Ali Shad
Gamification in UX Design: How to Boost User Engagement
- Today's news
- Reviews and deals
- Climate change
- 2024 election
- Fall allergies
- Health news
- Mental health
- Sexual health
- Family health
- So mini ways
- Unapologetically
- Buying guides
Entertainment
- How to Watch
- My Portfolio
- Latest News
- Stock Market
- Premium News
- Biden Economy
- EV Deep Dive
- Stocks: Most Actives
- Stocks: Gainers
- Stocks: Losers
- Trending Tickers
- World Indices
- US Treasury Bonds
- Top Mutual Funds
- Highest Open Interest
- Highest Implied Volatility
- Stock Comparison
- Advanced Charts
- Currency Converter
- Investment Ideas
- Research Reports
- Basic Materials
- Communication Services
- Consumer Cyclical
- Consumer Defensive
- Financial Services
- Industrials
- Real Estate
- Mutual Funds
- Analyst Rating
- Technical Events
- Smart Money
- Top Holdings
- Credit cards
- Balance Transfer Cards
- Cash-back Cards
- Rewards Cards
- Travel Cards
- Personal Loans
- Student Loans
- Car Insurance
- Morning Brief
- Market Domination
- Market Domination Overtime
- Asking for a Trend
- Opening Bid
- Stocks in Translation
- Lead This Way
- Good Buy or Goodbye?
- Fantasy football
- Pro Pick 'Em
- College Pick 'Em
- Fantasy baseball
- Fantasy hockey
- Fantasy basketball
- Download the app
- Daily fantasy
- Scores and schedules
- GameChannel
- World Baseball Classic
- Premier League
- CONCACAF League
- Champions League
- Motorsports
- Horse racing
- Newsletters
New on Yahoo
- Privacy Dashboard
Yahoo Finance
Sofi stock analysis: the fintech powerhouse wall street is wrong about.
While the latest news from SoFi Technologies (NASDAQ: SOFI ) has largely been positive, you wouldn’t think that if all you did was view a SoFi Technologies stock chart. Despite beating quarterly earnings, shares in the fintech firm and neobank continue to slump. Clearly, market sentiment for SoFi remains on the bearish side.
With 17.6% of its float sold short, Wall Street’s “smart money” suggests downside risk for the stock. With shares more-than reasonably priced, and plenty suggesting that the bull case will prevail, your best move with SoFi may be to go against the grain.
SoFi Technologies Stock and the Market’s Bearish Stance
On April 29, SoFi released its fiscal results for the quarter ending March 31, 2024, along with updates to guidance. As mentioned above, SoFi delivered an earnings beat, with GAAP earnings per share coming in at 2 cents , versus forecasts calling for EPS of 1 cent per share. Net revenue of $580.65 million also came in moderately ahead of consensus.
InvestorPlace - Stock Market News, Stock Advice & Trading Tips
Compared to the prior year’s quarter, net revenue was up 26% , adjusted EBITDA was up 91%, and tangible book value was up by 28%. Memberships and total products were up 44% and 38%, respectively, compared to Q1 2023. In terms of outlook, SoFi slightly raised full-year revenue and earnings guidance.
So, with such solid results, why has the market maintained a bearish stance on SoFi Technologies stock? Chalk it up to several factors.
For one, lending revenue fell during the quarter. Also, SoFi may have raised full-year guidance, but its updated guidance for the current quarter fell short of expectations .
To top things off, longstanding concerns about credit quality and loan accounting practices continue to linger. Yet while these factors helped to drive a post-earnings plunge for SoFi Technologies, there are substantive counters to both concerns.
Onward and Upward in the Years Ahead
Mizuho’s Dan Dolev has long been bullish on SoFi Technologies stock. Since the latest earnings release, the analyst has reiterated this view, as well as his $12 per share price target.
In his latest research notes, Dolev has pointed out that recent sale of delinquent loans , plus the company’s prudence when it comes to near-term lending growth , are encouraging signs for SoFi’s ability to ride out a potential economic downturn.
With this, you may be thinking, “ok, downside risk for SOFI may not be so massive, but what up the upside potential?”
Lending growth may not be too impressive right now, but the rest of SoFi’s business continues to hum along with above-average rates of growth.
Now at the point of profitability, incremental revenue growth is poised to have an outsized impact on earnings. Sell-side forecasts call for EPS to nearly triple next year, to 23 cents.
The high end of 2025 forecasts call for EPS of 36 cents. Macro issues could normalize by then, paving the way for a resurgence in lending growth. A spate of positive developments like these could send SOFI onward and upward to substantially higher prices.
Bottom Line: Buy Now, Ahead of the Sentiment Shift
At 88.3 times forward earnings, SoFi Technologies shares may seem pricey, but with exponential earnings growth likely because of operating leverage, don’t assume this rich forward multiple means SOFI is overvalued.
A few years from now, SoFi’s earnings could scale up to $1 per share. Not too shabby, compared to SOFI’s current $7.30 per share stock price.
Although there’s the risk shares could get stuck with a lower multiple, due to the fact that it’s more of a bank than a pure-play fintech, hitting Dolev’s $12 per share price target is well within reach.
With all of this in mind, ahead of the next sharp shift in sentiment back to bullish for SoFi Technologies stock, consider it a buy at current prices.
On the date of publication, Thomas Niel did not hold (either directly or indirectly) any positions in the securities mentioned in this article. The opinions expressed in this article are those of the writer, subject to the InvestorPlace.com Publishing Guidelines .
Thomas Niel, contributor for InvestorPlace.com, has been writing single-stock analysis for web-based publications since 2016.
More From InvestorPlace
The #1 AI Investment Might Be This Company You’ve Never Heard Of
Musk’s “Project Omega” May Be Set to Mint New Millionaires. Here’s How to Get In.
It doesn’t matter if you have $500 or $5 million. Do this now.
The post SOFI Stock Analysis: The Fintech Powerhouse Wall Street Is Wrong About appeared first on InvestorPlace .
Recommended Stories
Is most-watched stock quicklogic corporation (quik) worth betting on now.
Zacks.com users have recently been watching QuickLogic (QUIK) quite a bit. Thus, it is worth knowing the facts that could determine the stock's prospects.
2 Stock-Split Stocks Billionaires Are Buying Hand Over Fist, and 1 They've Sent to the Chopping Block
Wall Street's brightest billionaire money managers have mixed feelings about this year's class of companies enacting stock splits.
Stocks splits are usually bullish. Here are 8 expensive stocks that could get a boost by following Nvidia's 10-for-1 move.
Companies that split their stock see an average annual return of 25% after the split compared to a 12% return for the broader market.
Cathie Wood's Ark Invest has destroyed $14 billion in wealth over the past decade, Morningstar says
"These funds managed to lose value for shareholders even during a generally bullish market," Morningstar analyst Amy Arnott said.
Did QuantumScape Just Say "Checkmate" to Tesla?
QuantumScape just shipped a new version of its solid-state batteries.
1 Stock to Buy Before It Breaks New Ground in Artificial Intelligence (AI) Next Month
One company is set to lead the charge in the next phase of AI development.
Here's the Average Income and Net Worth for American Households by Age
The average American is a millionaire with a six-figure income, but those numbers are misleading.
Goldman Sachs Predicts up to 108% Rally for These 2 ‘Strong Buy’ Stocks
Given the S&P 500‘s recent surge beyond 5,300, surpassing some experts’ year-end targets, is it prudent for investors to be concerned about a potential overheating in the market? Goldman Sachs’ chief US equity strategist David Kostin believes that now that the S&P has climbed above the 5,200 target he’d predicted, there just isn’t much more room at the top this year. Kostin believes that the current combination of high stock valuations and low projections for 2024 GDP and earnings growth are lik
Dow Jones Futures Rise With U.S. Markets Shut; 7 Stocks Near Buy Points
The market rally had a mixed week as breadth narrowed. Microsoft and Merck led stocks near buy points. Here's what to do.
How to Play Costco (COST) Ahead of Q3 Earnings Release
Costco (COST) remains a dominant force in the warehouse retail sector with its wide array of high-quality merchandise and distinctive membership-based business model.
IMAGES
VIDEO
COMMENTS
Sentiment analysis, or opinion mining, is the process of analyzing large volumes of text to determine whether it expresses a positive sentiment, a negative sentiment or a neutral sentiment. Companies now have access to more data about their customers than ever before, presenting both an opportunity and a challenge: analyzing the vast amounts of ...
Sentiment analysis is a technique through which you can analyze a piece of text to determine the sentiment behind it. It combines machine learning and natural language processing (NLP) to achieve this. Using basic Sentiment analysis, a program can understand whether the sentiment behind a piece of text is positive, negative, or neutral.
The following are some popular models for sentiment analysis models available on the Hub that we recommend checking out: Twitter-roberta-base-sentiment is a roBERTa model trained on ~58M tweets and fine-tuned for sentiment analysis. Fine-tuning is the process of taking a pre-trained large language model (e.g. roBERTa in this case) and then tweaking it with additional training data to make it ...
Sentiment Analysis: A Definitive Guide. Sentiment analysis (or opinion mining) is a natural language processing (NLP) technique used to determine whether data is positive, negative or neutral. Sentiment analysis is often performed on textual data to help businesses monitor brand and product sentiment in customer feedback, and understand ...
This model ("SiEBERT", prefix for "Sentiment in English") is a fine-tuned checkpoint of RoBERTa-large ( Liu et al. 2019 ). It enables reliable binary sentiment analysis for various types of English-language text. For each instance, it predicts either positive (1) or negative (0) sentiment. The model was fine-tuned and evaluated on 15 data sets ...
Sentiment analysis, also known as opinion mining, is a powerful tool that uses artificial intelligence and natural language processing (NLP) to understand the emotional tone behind a piece of text. It goes beyond simply identifying keywords to analyze the context and intention of the language used. This blog post serves as a comprehensive guide ...
Sentiment analysis (also known as opinion mining or emotion AI) is the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information. Sentiment analysis is widely applied to voice of the customer materials such as reviews and survey responses, online and social ...
Sentiment analysis, also known as opinion mining, is the process of determining the emotions behind a piece of text. Sentiment analysis aims to categorize the given text as positive, negative, or neutral. Furthermore, it then identifies and quantifies subjective information about those texts with the help of: 2.
Sentiment analysis is the process of analyzing digital text to determine if the emotional tone of the message is positive, negative, or neutral. Today, companies have large volumes of text data like emails, customer support chat transcripts, social media comments, and reviews. Sentiment analysis tools can scan this text to automatically ...
Sentiment analysis is a growing field at the intersection of linguistics and computer science that attempts to automatically determine the sentiment contained in text. Sentiment can be characterized as positive or negative evaluation expressed through language. Common applications of sentiment analysis include the automatic determination of whether a review posted online (of a movie, a book ...
Sentiment analysis is the practice of using algorithms to classify various samples of related text into overall positive and negative categories. With NLTK, you can employ these algorithms through powerful built-in machine learning operations to obtain insights from linguistic data. ... Make sure to specify english as the desired language since ...
A. Sentiment analysis in NLP (Natural Language Processing) is the process of determining the sentiment or emotion expressed in a piece of text, such as positive, negative, or neutral. It involves using machine learning algorithms and linguistic techniques to analyze and classify subjective information.
Sentiment analysis is an essential task in natural language processing that involves identifying a text's polarity, whether it expresses positive, negative, or neutral sentiments. With the ...
Sentiment analysis uses machine learning, statistics, and natural language processing (NLP) to find out how people think and feel on a macro scale. Sentiment analysis tools take written content and process it to unearth the positivity or negativity of the expression. This is done in a couple of ways:
If there is sentiment, which objects in the text the sentiment is referring to and the actual sentiment phrase such as poor, blurry, inexpensive, … (Not just positive or negative.) This is also called aspect-based analysis [1]. As a technique, sentiment analysis is both interesting and useful. First, to the interesting part.
Sentiment analysis is a beneficial technique for enhancing the quality of decisions, products, and services by both consumers and businesses (Alshamsi et al., 2020). In social media monitoring, SA ...
Sentiment Analyzer. Use sentiment analysis to quickly detect emotions in text data. Play around with our sentiment analyzer, below: Test with your own text. Classify Text. Results. Tag Confidence. Positive 99.1%. Get sentiment insights like these: Sentiment analysis benefits: 👍 ...
Overview. This free tool will allow you to conduct a sentiment analysis on virtually any text written in English. The tool computes a sentiment score that reflects the overall sentiment, tone, or emotional feeling of your input text. Sentiment scores range from -100 to +100, where -100 indicates a very negative or serious tone and +100 ...
There are many more dictionaries for sentiment analysis available in English, including also domain-specific dictionaries for sentiment in finance. Following the suggestion by De Vries et al. (Citation 2018), we used machine translation to translate the gold standard texts. For this, we used both Google Translate and DeepL to translate the gold ...
A sentiment lexicon is one of the most valuable resources of sentiment analysis for any language [10, 22, 25].They are vital resources for both lexicon-based and machine-based learning approaches [], with many researchers leveraging sentiment lexicons to produce unsupervised sentiment models or as training features to train machine learning algorithms in supervised approaches [].
Webis-CLS-10 Dataset. Webis cross-lingual sentiment dataset includes 800.000 Amazon product reviews in English, German, French, and Japanese. Its multilingual nature allows for reaching more audiences and conducting comprehensive analyses. 5. CMU Multimodal Opinion Sentiment and Emotion Intensity.
Among the many sentiment analysis datasets in multiple languages, this one is the most generous. It contains positive and negative sentiment lexicons for 81 languages. The sentiments were built based on English sentiment lexicons. The lexica were generated through graph propagation for the sentiment analysis based on a knowledge graph.
Abstract: In this research paper, we focus on understanding people's feelings and opinions in online social forums, like social media platforms and discussion boards. These forums are crucial for conversations and sharing information online. Our main goals are to explain what sentiment analysis is, discuss the unique challenges of analyzing sentiments in social forums, review different methods ...
SENTIMENT ANALYSIS definition: 1. the process of using computer software to find out people's opinions or feelings about something…. Learn more.
10 Most Popular Sentiment Analysis Datasets in 2024. Below are listed some of the most popular datasets for sentiment analysis. 1. Amazon Product Data. Amazon product data is a subset of a large 142.8 million Amazon review dataset that was made available by Stanford professor, Julian McAuley.
A sentiment analysis dataset is a collection of text data annotated with sentiment labels. These labels indicate the sentiment expressed in the text, typically categorized as positive, negative, or neutral. Some datasets may also include more granular sentiment categories or intensity levels.
Here are the steps to perform a customer sentiment analysis: Invest in sentiment analysis tools to gather and analyze feedback accurately with features like real-time analysis and multi-source integration. Collect customer feedback through in-app surveys like NPS, CSAT, and CES surveys to capture timely and relevant insights.
Clearly, market sentiment for SoFi remains on the bearish side. With 17.6% of its float sold short, Wall Street's "smart money" suggests downside risk for the stock. With shares more-than ...
That said, bullish investors can watch for possible breaks of recent daily lows at $326.90 (recorded on April 25th, 2024) as an initial sign that this stock might be heading lower. If this ...