
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager

Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
How to Do a Systematic Review: A Best Practice Guide for Conducting and Reporting Narrative Reviews, Meta-Analyses, and Meta-Syntheses
Affiliations.
- 1 Behavioural Science Centre, Stirling Management School, University of Stirling, Stirling FK9 4LA, United Kingdom; email: [email protected].
- 2 Department of Psychological and Behavioural Science, London School of Economics and Political Science, London WC2A 2AE, United Kingdom.
- 3 Department of Statistics, Northwestern University, Evanston, Illinois 60208, USA; email: [email protected].
- PMID: 30089228
- DOI: 10.1146/annurev-psych-010418-102803
Systematic reviews are characterized by a methodical and replicable methodology and presentation. They involve a comprehensive search to locate all relevant published and unpublished work on a subject; a systematic integration of search results; and a critique of the extent, nature, and quality of evidence in relation to a particular research question. The best reviews synthesize studies to draw broad theoretical conclusions about what a literature means, linking theory to evidence and evidence to theory. This guide describes how to plan, conduct, organize, and present a systematic review of quantitative (meta-analysis) or qualitative (narrative review, meta-synthesis) information. We outline core standards and principles and describe commonly encountered problems. Although this guide targets psychological scientists, its high level of abstraction makes it potentially relevant to any subject area or discipline. We argue that systematic reviews are a key methodology for clarifying whether and how research findings replicate and for explaining possible inconsistencies, and we call for researchers to conduct systematic reviews to help elucidate whether there is a replication crisis.
Keywords: evidence; guide; meta-analysis; meta-synthesis; narrative; systematic review; theory.
PubMed Disclaimer
Similar articles
- The future of Cochrane Neonatal. Soll RF, Ovelman C, McGuire W. Soll RF, et al. Early Hum Dev. 2020 Nov;150:105191. doi: 10.1016/j.earlhumdev.2020.105191. Epub 2020 Sep 12. Early Hum Dev. 2020. PMID: 33036834
- A Primer on Systematic Reviews and Meta-Analyses. Nguyen NH, Singh S. Nguyen NH, et al. Semin Liver Dis. 2018 May;38(2):103-111. doi: 10.1055/s-0038-1655776. Epub 2018 Jun 5. Semin Liver Dis. 2018. PMID: 29871017 Review.
- Publication Bias and Nonreporting Found in Majority of Systematic Reviews and Meta-analyses in Anesthesiology Journals. Hedin RJ, Umberham BA, Detweiler BN, Kollmorgen L, Vassar M. Hedin RJ, et al. Anesth Analg. 2016 Oct;123(4):1018-25. doi: 10.1213/ANE.0000000000001452. Anesth Analg. 2016. PMID: 27537925 Review.
- Summarizing systematic reviews: methodological development, conduct and reporting of an umbrella review approach. Aromataris E, Fernandez R, Godfrey CM, Holly C, Khalil H, Tungpunkom P. Aromataris E, et al. Int J Evid Based Healthc. 2015 Sep;13(3):132-40. doi: 10.1097/XEB.0000000000000055. Int J Evid Based Healthc. 2015. PMID: 26360830
- RAMESES publication standards: meta-narrative reviews. Wong G, Greenhalgh T, Westhorp G, Buckingham J, Pawson R. Wong G, et al. BMC Med. 2013 Jan 29;11:20. doi: 10.1186/1741-7015-11-20. BMC Med. 2013. PMID: 23360661 Free PMC article.
- Surveillance of Occupational Exposure to Volatile Organic Compounds at Gas Stations: A Scoping Review Protocol. Mendes TMC, Soares JP, Salvador PTCO, Castro JL. Mendes TMC, et al. Int J Environ Res Public Health. 2024 Apr 23;21(5):518. doi: 10.3390/ijerph21050518. Int J Environ Res Public Health. 2024. PMID: 38791733 Free PMC article. Review.
- Association between poor sleep and mental health issues in Indigenous communities across the globe: a systematic review. Fernandez DR, Lee R, Tran N, Jabran DS, King S, McDaid L. Fernandez DR, et al. Sleep Adv. 2024 May 2;5(1):zpae028. doi: 10.1093/sleepadvances/zpae028. eCollection 2024. Sleep Adv. 2024. PMID: 38721053 Free PMC article.
- Barriers to ethical treatment of patients in clinical environments: A systematic narrative review. Dehkordi FG, Torabizadeh C, Rakhshan M, Vizeshfar F. Dehkordi FG, et al. Health Sci Rep. 2024 May 1;7(5):e2008. doi: 10.1002/hsr2.2008. eCollection 2024 May. Health Sci Rep. 2024. PMID: 38698790 Free PMC article.
- Studying Adherence to Reporting Standards in Kinesiology: A Post-publication Peer Review Brief Report. Watson NM, Thomas JD. Watson NM, et al. Int J Exerc Sci. 2024 Jan 1;17(7):25-37. eCollection 2024. Int J Exerc Sci. 2024. PMID: 38666001 Free PMC article.
- Evidence for Infant-directed Speech Preference Is Consistent Across Large-scale, Multi-site Replication and Meta-analysis. Zettersten M, Cox C, Bergmann C, Tsui ASM, Soderstrom M, Mayor J, Lundwall RA, Lewis M, Kosie JE, Kartushina N, Fusaroli R, Frank MC, Byers-Heinlein K, Black AK, Mathur MB. Zettersten M, et al. Open Mind (Camb). 2024 Apr 3;8:439-461. doi: 10.1162/opmi_a_00134. eCollection 2024. Open Mind (Camb). 2024. PMID: 38665547 Free PMC article.
- Search in MeSH
LinkOut - more resources
Full text sources.
- Ingenta plc
- Ovid Technologies, Inc.
Other Literature Sources
- scite Smart Citations
Miscellaneous
- NCI CPTAC Assay Portal
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
- Methodology
- Open access
- Published: 11 October 2016
Reviewing the research methods literature: principles and strategies illustrated by a systematic overview of sampling in qualitative research
- Stephen J. Gentles 1 , 4 ,
- Cathy Charles 1 ,
- David B. Nicholas 2 ,
- Jenny Ploeg 3 &
- K. Ann McKibbon 1
Systematic Reviews volume 5 , Article number: 172 ( 2016 ) Cite this article
53k Accesses
27 Citations
13 Altmetric
Metrics details
Overviews of methods are potentially useful means to increase clarity and enhance collective understanding of specific methods topics that may be characterized by ambiguity, inconsistency, or a lack of comprehensiveness. This type of review represents a distinct literature synthesis method, although to date, its methodology remains relatively undeveloped despite several aspects that demand unique review procedures. The purpose of this paper is to initiate discussion about what a rigorous systematic approach to reviews of methods, referred to here as systematic methods overviews , might look like by providing tentative suggestions for approaching specific challenges likely to be encountered. The guidance offered here was derived from experience conducting a systematic methods overview on the topic of sampling in qualitative research.
The guidance is organized into several principles that highlight specific objectives for this type of review given the common challenges that must be overcome to achieve them. Optional strategies for achieving each principle are also proposed, along with discussion of how they were successfully implemented in the overview on sampling. We describe seven paired principles and strategies that address the following aspects: delimiting the initial set of publications to consider, searching beyond standard bibliographic databases, searching without the availability of relevant metadata, selecting publications on purposeful conceptual grounds, defining concepts and other information to abstract iteratively, accounting for inconsistent terminology used to describe specific methods topics, and generating rigorous verifiable analytic interpretations. Since a broad aim in systematic methods overviews is to describe and interpret the relevant literature in qualitative terms, we suggest that iterative decision making at various stages of the review process, and a rigorous qualitative approach to analysis are necessary features of this review type.
Conclusions
We believe that the principles and strategies provided here will be useful to anyone choosing to undertake a systematic methods overview. This paper represents an initial effort to promote high quality critical evaluations of the literature regarding problematic methods topics, which have the potential to promote clearer, shared understandings, and accelerate advances in research methods. Further work is warranted to develop more definitive guidance.
Peer Review reports
While reviews of methods are not new, they represent a distinct review type whose methodology remains relatively under-addressed in the literature despite the clear implications for unique review procedures. One of few examples to describe it is a chapter containing reflections of two contributing authors in a book of 21 reviews on methodological topics compiled for the British National Health Service, Health Technology Assessment Program [ 1 ]. Notable is their observation of how the differences between the methods reviews and conventional quantitative systematic reviews, specifically attributable to their varying content and purpose, have implications for defining what qualifies as systematic. While the authors describe general aspects of “systematicity” (including rigorous application of a methodical search, abstraction, and analysis), they also describe a high degree of variation within the category of methods reviews itself and so offer little in the way of concrete guidance. In this paper, we present tentative concrete guidance, in the form of a preliminary set of proposed principles and optional strategies, for a rigorous systematic approach to reviewing and evaluating the literature on quantitative or qualitative methods topics. For purposes of this article, we have used the term systematic methods overview to emphasize the notion of a systematic approach to such reviews.
The conventional focus of rigorous literature reviews (i.e., review types for which systematic methods have been codified, including the various approaches to quantitative systematic reviews [ 2 – 4 ], and the numerous forms of qualitative and mixed methods literature synthesis [ 5 – 10 ]) is to synthesize empirical research findings from multiple studies. By contrast, the focus of overviews of methods, including the systematic approach we advocate, is to synthesize guidance on methods topics. The literature consulted for such reviews may include the methods literature, methods-relevant sections of empirical research reports, or both. Thus, this paper adds to previous work published in this journal—namely, recent preliminary guidance for conducting reviews of theory [ 11 ]—that has extended the application of systematic review methods to novel review types that are concerned with subject matter other than empirical research findings.
Published examples of methods overviews illustrate the varying objectives they can have. One objective is to establish methodological standards for appraisal purposes. For example, reviews of existing quality appraisal standards have been used to propose universal standards for appraising the quality of primary qualitative research [ 12 ] or evaluating qualitative research reports [ 13 ]. A second objective is to survey the methods-relevant sections of empirical research reports to establish current practices on methods use and reporting practices, which Moher and colleagues [ 14 ] recommend as a means for establishing the needs to be addressed in reporting guidelines (see, for example [ 15 , 16 ]). A third objective for a methods review is to offer clarity and enhance collective understanding regarding a specific methods topic that may be characterized by ambiguity, inconsistency, or a lack of comprehensiveness within the available methods literature. An example of this is a overview whose objective was to review the inconsistent definitions of intention-to-treat analysis (the methodologically preferred approach to analyze randomized controlled trial data) that have been offered in the methods literature and propose a solution for improving conceptual clarity [ 17 ]. Such reviews are warranted because students and researchers who must learn or apply research methods typically lack the time to systematically search, retrieve, review, and compare the available literature to develop a thorough and critical sense of the varied approaches regarding certain controversial or ambiguous methods topics.
While systematic methods overviews , as a review type, include both reviews of the methods literature and reviews of methods-relevant sections from empirical study reports, the guidance provided here is primarily applicable to reviews of the methods literature since it was derived from the experience of conducting such a review [ 18 ], described below. To our knowledge, there are no well-developed proposals on how to rigorously conduct such reviews. Such guidance would have the potential to improve the thoroughness and credibility of critical evaluations of the methods literature, which could increase their utility as a tool for generating understandings that advance research methods, both qualitative and quantitative. Our aim in this paper is thus to initiate discussion about what might constitute a rigorous approach to systematic methods overviews. While we hope to promote rigor in the conduct of systematic methods overviews wherever possible, we do not wish to suggest that all methods overviews need be conducted to the same standard. Rather, we believe that the level of rigor may need to be tailored pragmatically to the specific review objectives, which may not always justify the resource requirements of an intensive review process.
The example systematic methods overview on sampling in qualitative research
The principles and strategies we propose in this paper are derived from experience conducting a systematic methods overview on the topic of sampling in qualitative research [ 18 ]. The main objective of that methods overview was to bring clarity and deeper understanding of the prominent concepts related to sampling in qualitative research (purposeful sampling strategies, saturation, etc.). Specifically, we interpreted the available guidance, commenting on areas lacking clarity, consistency, or comprehensiveness (without proposing any recommendations on how to do sampling). This was achieved by a comparative and critical analysis of publications representing the most influential (i.e., highly cited) guidance across several methodological traditions in qualitative research.
The specific methods and procedures for the overview on sampling [ 18 ] from which our proposals are derived were developed both after soliciting initial input from local experts in qualitative research and an expert health librarian (KAM) and through ongoing careful deliberation throughout the review process. To summarize, in that review, we employed a transparent and rigorous approach to search the methods literature, selected publications for inclusion according to a purposeful and iterative process, abstracted textual data using structured abstraction forms, and analyzed (synthesized) the data using a systematic multi-step approach featuring abstraction of text, summary of information in matrices, and analytic comparisons.
For this article, we reflected on both the problems and challenges encountered at different stages of the review and our means for selecting justifiable procedures to deal with them. Several principles were then derived by considering the generic nature of these problems, while the generalizable aspects of the procedures used to address them formed the basis of optional strategies. Further details of the specific methods and procedures used in the overview on qualitative sampling are provided below to illustrate both the types of objectives and challenges that reviewers will likely need to consider and our approach to implementing each of the principles and strategies.
Organization of the guidance into principles and strategies
For the purposes of this article, principles are general statements outlining what we propose are important aims or considerations within a particular review process, given the unique objectives or challenges to be overcome with this type of review. These statements follow the general format, “considering the objective or challenge of X, we propose Y to be an important aim or consideration.” Strategies are optional and flexible approaches for implementing the previous principle outlined. Thus, generic challenges give rise to principles, which in turn give rise to strategies.
We organize the principles and strategies below into three sections corresponding to processes characteristic of most systematic literature synthesis approaches: literature identification and selection ; data abstraction from the publications selected for inclusion; and analysis , including critical appraisal and synthesis of the abstracted data. Within each section, we also describe the specific methodological decisions and procedures used in the overview on sampling in qualitative research [ 18 ] to illustrate how the principles and strategies for each review process were applied and implemented in a specific case. We expect this guidance and accompanying illustrations will be useful for anyone considering engaging in a methods overview, particularly those who may be familiar with conventional systematic review methods but may not yet appreciate some of the challenges specific to reviewing the methods literature.
Results and discussion
Literature identification and selection.
The identification and selection process includes search and retrieval of publications and the development and application of inclusion and exclusion criteria to select the publications that will be abstracted and analyzed in the final review. Literature identification and selection for overviews of the methods literature is challenging and potentially more resource-intensive than for most reviews of empirical research. This is true for several reasons that we describe below, alongside discussion of the potential solutions. Additionally, we suggest in this section how the selection procedures can be chosen to match the specific analytic approach used in methods overviews.
Delimiting a manageable set of publications
One aspect of methods overviews that can make identification and selection challenging is the fact that the universe of literature containing potentially relevant information regarding most methods-related topics is expansive and often unmanageably so. Reviewers are faced with two large categories of literature: the methods literature , where the possible publication types include journal articles, books, and book chapters; and the methods-relevant sections of empirical study reports , where the possible publication types include journal articles, monographs, books, theses, and conference proceedings. In our systematic overview of sampling in qualitative research, exhaustively searching (including retrieval and first-pass screening) all publication types across both categories of literature for information on a single methods-related topic was too burdensome to be feasible. The following proposed principle follows from the need to delimit a manageable set of literature for the review.
Principle #1:
Considering the broad universe of potentially relevant literature, we propose that an important objective early in the identification and selection stage is to delimit a manageable set of methods-relevant publications in accordance with the objectives of the methods overview.
Strategy #1:
To limit the set of methods-relevant publications that must be managed in the selection process, reviewers have the option to initially review only the methods literature, and exclude the methods-relevant sections of empirical study reports, provided this aligns with the review’s particular objectives.
We propose that reviewers are justified in choosing to select only the methods literature when the objective is to map out the range of recognized concepts relevant to a methods topic, to summarize the most authoritative or influential definitions or meanings for methods-related concepts, or to demonstrate a problematic lack of clarity regarding a widely established methods-related concept and potentially make recommendations for a preferred approach to the methods topic in question. For example, in the case of the methods overview on sampling [ 18 ], the primary aim was to define areas lacking in clarity for multiple widely established sampling-related topics. In the review on intention-to-treat in the context of missing outcome data [ 17 ], the authors identified a lack of clarity based on multiple inconsistent definitions in the literature and went on to recommend separating the issue of how to handle missing outcome data from the issue of whether an intention-to-treat analysis can be claimed.
In contrast to strategy #1, it may be appropriate to select the methods-relevant sections of empirical study reports when the objective is to illustrate how a methods concept is operationalized in research practice or reported by authors. For example, one could review all the publications in 2 years’ worth of issues of five high-impact field-related journals to answer questions about how researchers describe implementing a particular method or approach, or to quantify how consistently they define or report using it. Such reviews are often used to highlight gaps in the reporting practices regarding specific methods, which may be used to justify items to address in reporting guidelines (for example, [ 14 – 16 ]).
It is worth recognizing that other authors have advocated broader positions regarding the scope of literature to be considered in a review, expanding on our perspective. Suri [ 10 ] (who, like us, emphasizes how different sampling strategies are suitable for different literature synthesis objectives) has, for example, described a two-stage literature sampling procedure (pp. 96–97). First, reviewers use an initial approach to conduct a broad overview of the field—for reviews of methods topics, this would entail an initial review of the research methods literature. This is followed by a second more focused stage in which practical examples are purposefully selected—for methods reviews, this would involve sampling the empirical literature to illustrate key themes and variations. While this approach is seductive in its capacity to generate more in depth and interpretive analytic findings, some reviewers may consider it too resource-intensive to include the second step no matter how selective the purposeful sampling. In the overview on sampling where we stopped after the first stage [ 18 ], we discussed our selective focus on the methods literature as a limitation that left opportunities for further analysis of the literature. We explicitly recommended, for example, that theoretical sampling was a topic for which a future review of the methods sections of empirical reports was justified to answer specific questions identified in the primary review.
Ultimately, reviewers must make pragmatic decisions that balance resource considerations, combined with informed predictions about the depth and complexity of literature available on their topic, with the stated objectives of their review. The remaining principles and strategies apply primarily to overviews that include the methods literature, although some aspects may be relevant to reviews that include empirical study reports.
Searching beyond standard bibliographic databases
An important reality affecting identification and selection in overviews of the methods literature is the increased likelihood for relevant publications to be located in sources other than journal articles (which is usually not the case for overviews of empirical research, where journal articles generally represent the primary publication type). In the overview on sampling [ 18 ], out of 41 full-text publications retrieved and reviewed, only 4 were journal articles, while 37 were books or book chapters. Since many books and book chapters did not exist electronically, their full text had to be physically retrieved in hardcopy, while 11 publications were retrievable only through interlibrary loan or purchase request. The tasks associated with such retrieval are substantially more time-consuming than electronic retrieval. Since a substantial proportion of methods-related guidance may be located in publication types that are less comprehensively indexed in standard bibliographic databases, identification and retrieval thus become complicated processes.
Principle #2:
Considering that important sources of methods guidance can be located in non-journal publication types (e.g., books, book chapters) that tend to be poorly indexed in standard bibliographic databases, it is important to consider alternative search methods for identifying relevant publications to be further screened for inclusion.
Strategy #2:
To identify books, book chapters, and other non-journal publication types not thoroughly indexed in standard bibliographic databases, reviewers may choose to consult one or more of the following less standard sources: Google Scholar, publisher web sites, or expert opinion.
In the case of the overview on sampling in qualitative research [ 18 ], Google Scholar had two advantages over other standard bibliographic databases: it indexes and returns records of books and book chapters likely to contain guidance on qualitative research methods topics; and it has been validated as providing higher citation counts than ISI Web of Science (a producer of numerous bibliographic databases accessible through institutional subscription) for several non-biomedical disciplines including the social sciences where qualitative research methods are prominently used [ 19 – 21 ]. While we identified numerous useful publications by consulting experts, the author publication lists generated through Google Scholar searches were uniquely useful to identify more recent editions of methods books identified by experts.
Searching without relevant metadata
Determining what publications to select for inclusion in the overview on sampling [ 18 ] could only rarely be accomplished by reviewing the publication’s metadata. This was because for the many books and other non-journal type publications we identified as possibly relevant, the potential content of interest would be located in only a subsection of the publication. In this common scenario for reviews of the methods literature (as opposed to methods overviews that include empirical study reports), reviewers will often be unable to employ standard title, abstract, and keyword database searching or screening as a means for selecting publications.
Principle #3:
Considering that the presence of information about the topic of interest may not be indicated in the metadata for books and similar publication types, it is important to consider other means of identifying potentially useful publications for further screening.
Strategy #3:
One approach to identifying potentially useful books and similar publication types is to consider what classes of such publications (e.g., all methods manuals for a certain research approach) are likely to contain relevant content, then identify, retrieve, and review the full text of corresponding publications to determine whether they contain information on the topic of interest.
In the example of the overview on sampling in qualitative research [ 18 ], the topic of interest (sampling) was one of numerous topics covered in the general qualitative research methods manuals. Consequently, examples from this class of publications first had to be identified for retrieval according to non-keyword-dependent criteria. Thus, all methods manuals within the three research traditions reviewed (grounded theory, phenomenology, and case study) that might contain discussion of sampling were sought through Google Scholar and expert opinion, their full text obtained, and hand-searched for relevant content to determine eligibility. We used tables of contents and index sections of books to aid this hand searching.
Purposefully selecting literature on conceptual grounds
A final consideration in methods overviews relates to the type of analysis used to generate the review findings. Unlike quantitative systematic reviews where reviewers aim for accurate or unbiased quantitative estimates—something that requires identifying and selecting the literature exhaustively to obtain all relevant data available (i.e., a complete sample)—in methods overviews, reviewers must describe and interpret the relevant literature in qualitative terms to achieve review objectives. In other words, the aim in methods overviews is to seek coverage of the qualitative concepts relevant to the methods topic at hand. For example, in the overview of sampling in qualitative research [ 18 ], achieving review objectives entailed providing conceptual coverage of eight sampling-related topics that emerged as key domains. The following principle recognizes that literature sampling should therefore support generating qualitative conceptual data as the input to analysis.
Principle #4:
Since the analytic findings of a systematic methods overview are generated through qualitative description and interpretation of the literature on a specified topic, selection of the literature should be guided by a purposeful strategy designed to achieve adequate conceptual coverage (i.e., representing an appropriate degree of variation in relevant ideas) of the topic according to objectives of the review.
Strategy #4:
One strategy for choosing the purposeful approach to use in selecting the literature according to the review objectives is to consider whether those objectives imply exploring concepts either at a broad overview level, in which case combining maximum variation selection with a strategy that limits yield (e.g., critical case, politically important, or sampling for influence—described below) may be appropriate; or in depth, in which case purposeful approaches aimed at revealing innovative cases will likely be necessary.
In the methods overview on sampling, the implied scope was broad since we set out to review publications on sampling across three divergent qualitative research traditions—grounded theory, phenomenology, and case study—to facilitate making informative conceptual comparisons. Such an approach would be analogous to maximum variation sampling.
At the same time, the purpose of that review was to critically interrogate the clarity, consistency, and comprehensiveness of literature from these traditions that was “most likely to have widely influenced students’ and researchers’ ideas about sampling” (p. 1774) [ 18 ]. In other words, we explicitly set out to review and critique the most established and influential (and therefore dominant) literature, since this represents a common basis of knowledge among students and researchers seeking understanding or practical guidance on sampling in qualitative research. To achieve this objective, we purposefully sampled publications according to the criterion of influence , which we operationalized as how often an author or publication has been referenced in print or informal discourse. This second sampling approach also limited the literature we needed to consider within our broad scope review to a manageable amount.
To operationalize this strategy of sampling for influence , we sought to identify both the most influential authors within a qualitative research tradition (all of whose citations were subsequently screened) and the most influential publications on the topic of interest by non-influential authors. This involved a flexible approach that combined multiple indicators of influence to avoid the dilemma that any single indicator might provide inadequate coverage. These indicators included bibliometric data (h-index for author influence [ 22 ]; number of cites for publication influence), expert opinion, and cross-references in the literature (i.e., snowball sampling). As a final selection criterion, a publication was included only if it made an original contribution in terms of novel guidance regarding sampling or a related concept; thus, purely secondary sources were excluded. Publish or Perish software (Anne-Wil Harzing; available at http://www.harzing.com/resources/publish-or-perish ) was used to generate bibliometric data via the Google Scholar database. Figure 1 illustrates how identification and selection in the methods overview on sampling was a multi-faceted and iterative process. The authors selected as influential, and the publications selected for inclusion or exclusion are listed in Additional file 1 (Matrices 1, 2a, 2b).
Literature identification and selection process used in the methods overview on sampling [ 18 ]
In summary, the strategies of seeking maximum variation and sampling for influence were employed in the sampling overview to meet the specific review objectives described. Reviewers will need to consider the full range of purposeful literature sampling approaches at their disposal in deciding what best matches the specific aims of their own reviews. Suri [ 10 ] has recently retooled Patton’s well-known typology of purposeful sampling strategies (originally intended for primary research) for application to literature synthesis, providing a useful resource in this respect.
Data abstraction
The purpose of data abstraction in rigorous literature reviews is to locate and record all data relevant to the topic of interest from the full text of included publications, making them available for subsequent analysis. Conventionally, a data abstraction form—consisting of numerous distinct conceptually defined fields to which corresponding information from the source publication is recorded—is developed and employed. There are several challenges, however, to the processes of developing the abstraction form and abstracting the data itself when conducting methods overviews, which we address here. Some of these problems and their solutions may be familiar to those who have conducted qualitative literature syntheses, which are similarly conceptual.
Iteratively defining conceptual information to abstract
In the overview on sampling [ 18 ], while we surveyed multiple sources beforehand to develop a list of concepts relevant for abstraction (e.g., purposeful sampling strategies, saturation, sample size), there was no way for us to anticipate some concepts prior to encountering them in the review process. Indeed, in many cases, reviewers are unable to determine the complete set of methods-related concepts that will be the focus of the final review a priori without having systematically reviewed the publications to be included. Thus, defining what information to abstract beforehand may not be feasible.
Principle #5:
Considering the potential impracticality of defining a complete set of relevant methods-related concepts from a body of literature one has not yet systematically read, selecting and defining fields for data abstraction must often be undertaken iteratively. Thus, concepts to be abstracted can be expected to grow and change as data abstraction proceeds.
Strategy #5:
Reviewers can develop an initial form or set of concepts for abstraction purposes according to standard methods (e.g., incorporating expert feedback, pilot testing) and remain attentive to the need to iteratively revise it as concepts are added or modified during the review. Reviewers should document revisions and return to re-abstract data from previously abstracted publications as the new data requirements are determined.
In the sampling overview [ 18 ], we developed and maintained the abstraction form in Microsoft Word. We derived the initial set of abstraction fields from our own knowledge of relevant sampling-related concepts, consultation with local experts, and reviewing a pilot sample of publications. Since the publications in this review included a large proportion of books, the abstraction process often began by flagging the broad sections within a publication containing topic-relevant information for detailed review to identify text to abstract. When reviewing flagged text, the reviewer occasionally encountered an unanticipated concept significant enough to warrant being added as a new field to the abstraction form. For example, a field was added to capture how authors described the timing of sampling decisions, whether before (a priori) or after (ongoing) starting data collection, or whether this was unclear. In these cases, we systematically documented the modification to the form and returned to previously abstracted publications to abstract any information that might be relevant to the new field.
The logic of this strategy is analogous to the logic used in a form of research synthesis called best fit framework synthesis (BFFS) [ 23 – 25 ]. In that method, reviewers initially code evidence using an a priori framework they have selected. When evidence cannot be accommodated by the selected framework, reviewers then develop new themes or concepts from which they construct a new expanded framework. Both the strategy proposed and the BFFS approach to research synthesis are notable for their rigorous and transparent means to adapt a final set of concepts to the content under review.
Accounting for inconsistent terminology
An important complication affecting the abstraction process in methods overviews is that the language used by authors to describe methods-related concepts can easily vary across publications. For example, authors from different qualitative research traditions often use different terms for similar methods-related concepts. Furthermore, as we found in the sampling overview [ 18 ], there may be cases where no identifiable term, phrase, or label for a methods-related concept is used at all, and a description of it is given instead. This can make searching the text for relevant concepts based on keywords unreliable.
Principle #6:
Since accepted terms may not be used consistently to refer to methods concepts, it is necessary to rely on the definitions for concepts, rather than keywords, to identify relevant information in the publication to abstract.
Strategy #6:
An effective means to systematically identify relevant information is to develop and iteratively adjust written definitions for key concepts (corresponding to abstraction fields) that are consistent with and as inclusive of as much of the literature reviewed as possible. Reviewers then seek information that matches these definitions (rather than keywords) when scanning a publication for relevant data to abstract.
In the abstraction process for the sampling overview [ 18 ], we noted the several concepts of interest to the review for which abstraction by keyword was particularly problematic due to inconsistent terminology across publications: sampling , purposeful sampling , sampling strategy , and saturation (for examples, see Additional file 1 , Matrices 3a, 3b, 4). We iteratively developed definitions for these concepts by abstracting text from publications that either provided an explicit definition or from which an implicit definition could be derived, which was recorded in fields dedicated to the concept’s definition. Using a method of constant comparison, we used text from definition fields to inform and modify a centrally maintained definition of the corresponding concept to optimize its fit and inclusiveness with the literature reviewed. Table 1 shows, as an example, the final definition constructed in this way for one of the central concepts of the review, qualitative sampling .
We applied iteratively developed definitions when making decisions about what specific text to abstract for an existing field, which allowed us to abstract concept-relevant data even if no recognized keyword was used. For example, this was the case for the sampling-related concept, saturation , where the relevant text available for abstraction in one publication [ 26 ]—“to continue to collect data until nothing new was being observed or recorded, no matter how long that takes”—was not accompanied by any term or label whatsoever.
This comparative analytic strategy (and our approach to analysis more broadly as described in strategy #7, below) is analogous to the process of reciprocal translation —a technique first introduced for meta-ethnography by Noblit and Hare [ 27 ] that has since been recognized as a common element in a variety of qualitative metasynthesis approaches [ 28 ]. Reciprocal translation, taken broadly, involves making sense of a study’s findings in terms of the findings of the other studies included in the review. In practice, it has been operationalized in different ways. Melendez-Torres and colleagues developed a typology from their review of the metasynthesis literature, describing four overlapping categories of specific operations undertaken in reciprocal translation: visual representation, key paper integration, data reduction and thematic extraction, and line-by-line coding [ 28 ]. The approaches suggested in both strategies #6 and #7, with their emphasis on constant comparison, appear to fall within the line-by-line coding category.
Generating credible and verifiable analytic interpretations
The analysis in a systematic methods overview must support its more general objective, which we suggested above is often to offer clarity and enhance collective understanding regarding a chosen methods topic. In our experience, this involves describing and interpreting the relevant literature in qualitative terms. Furthermore, any interpretative analysis required may entail reaching different levels of abstraction, depending on the more specific objectives of the review. For example, in the overview on sampling [ 18 ], we aimed to produce a comparative analysis of how multiple sampling-related topics were treated differently within and among different qualitative research traditions. To promote credibility of the review, however, not only should one seek a qualitative analytic approach that facilitates reaching varying levels of abstraction but that approach must also ensure that abstract interpretations are supported and justified by the source data and not solely the product of the analyst’s speculative thinking.
Principle #7:
Considering the qualitative nature of the analysis required in systematic methods overviews, it is important to select an analytic method whose interpretations can be verified as being consistent with the literature selected, regardless of the level of abstraction reached.
Strategy #7:
We suggest employing the constant comparative method of analysis [ 29 ] because it supports developing and verifying analytic links to the source data throughout progressively interpretive or abstract levels. In applying this approach, we advise a rigorous approach, documenting how supportive quotes or references to the original texts are carried forward in the successive steps of analysis to allow for easy verification.
The analytic approach used in the methods overview on sampling [ 18 ] comprised four explicit steps, progressing in level of abstraction—data abstraction, matrices, narrative summaries, and final analytic conclusions (Fig. 2 ). While we have positioned data abstraction as the second stage of the generic review process (prior to Analysis), above, we also considered it as an initial step of analysis in the sampling overview for several reasons. First, it involved a process of constant comparisons and iterative decision-making about the fields to add or define during development and modification of the abstraction form, through which we established the range of concepts to be addressed in the review. At the same time, abstraction involved continuous analytic decisions about what textual quotes (ranging in size from short phrases to numerous paragraphs) to record in the fields thus created. This constant comparative process was analogous to open coding in which textual data from publications was compared to conceptual fields (equivalent to codes) or to other instances of data previously abstracted when constructing definitions to optimize their fit with the overall literature as described in strategy #6. Finally, in the data abstraction step, we also recorded our first interpretive thoughts in dedicated fields, providing initial material for the more abstract analytic steps.
Summary of progressive steps of analysis used in the methods overview on sampling [ 18 ]
In the second step of the analysis, we constructed topic-specific matrices , or tables, by copying relevant quotes from abstraction forms into the appropriate cells of matrices (for the complete set of analytic matrices developed in the sampling review, see Additional file 1 (matrices 3 to 10)). Each matrix ranged from one to five pages; row headings, nested three-deep, identified the methodological tradition, author, and publication, respectively; and column headings identified the concepts, which corresponded to abstraction fields. Matrices thus allowed us to make further comparisons across methodological traditions, and between authors within a tradition. In the third step of analysis, we recorded our comparative observations as narrative summaries , in which we used illustrative quotes more sparingly. In the final step, we developed analytic conclusions based on the narrative summaries about the sampling-related concepts within each methodological tradition for which clarity, consistency, or comprehensiveness of the available guidance appeared to be lacking. Higher levels of analysis thus built logically from the lower levels, enabling us to easily verify analytic conclusions by tracing the support for claims by comparing the original text of publications reviewed.
Integrative versus interpretive methods overviews
The analytic product of systematic methods overviews is comparable to qualitative evidence syntheses, since both involve describing and interpreting the relevant literature in qualitative terms. Most qualitative synthesis approaches strive to produce new conceptual understandings that vary in level of interpretation. Dixon-Woods and colleagues [ 30 ] elaborate on a useful distinction, originating from Noblit and Hare [ 27 ], between integrative and interpretive reviews. Integrative reviews focus on summarizing available primary data and involve using largely secure and well defined concepts to do so; definitions are used from an early stage to specify categories for abstraction (or coding) of data, which in turn supports their aggregation; they do not seek as their primary focus to develop or specify new concepts, although they may achieve some theoretical or interpretive functions. For interpretive reviews, meanwhile, the main focus is to develop new concepts and theories that integrate them, with the implication that the concepts developed become fully defined towards the end of the analysis. These two forms are not completely distinct, and “every integrative synthesis will include elements of interpretation, and every interpretive synthesis will include elements of aggregation of data” [ 30 ].
The example methods overview on sampling [ 18 ] could be classified as predominantly integrative because its primary goal was to aggregate influential authors’ ideas on sampling-related concepts; there were also, however, elements of interpretive synthesis since it aimed to develop new ideas about where clarity in guidance on certain sampling-related topics is lacking, and definitions for some concepts were flexible and not fixed until late in the review. We suggest that most systematic methods overviews will be classifiable as predominantly integrative (aggregative). Nevertheless, more highly interpretive methods overviews are also quite possible—for example, when the review objective is to provide a highly critical analysis for the purpose of generating new methodological guidance. In such cases, reviewers may need to sample more deeply (see strategy #4), specifically by selecting empirical research reports (i.e., to go beyond dominant or influential ideas in the methods literature) that are likely to feature innovations or instructive lessons in employing a given method.
In this paper, we have outlined tentative guidance in the form of seven principles and strategies on how to conduct systematic methods overviews, a review type in which methods-relevant literature is systematically analyzed with the aim of offering clarity and enhancing collective understanding regarding a specific methods topic. Our proposals include strategies for delimiting the set of publications to consider, searching beyond standard bibliographic databases, searching without the availability of relevant metadata, selecting publications on purposeful conceptual grounds, defining concepts and other information to abstract iteratively, accounting for inconsistent terminology, and generating credible and verifiable analytic interpretations. We hope the suggestions proposed will be useful to others undertaking reviews on methods topics in future.
As far as we are aware, this is the first published source of concrete guidance for conducting this type of review. It is important to note that our primary objective was to initiate methodological discussion by stimulating reflection on what rigorous methods for this type of review should look like, leaving the development of more complete guidance to future work. While derived from the experience of reviewing a single qualitative methods topic, we believe the principles and strategies provided are generalizable to overviews of both qualitative and quantitative methods topics alike. However, it is expected that additional challenges and insights for conducting such reviews have yet to be defined. Thus, we propose that next steps for developing more definitive guidance should involve an attempt to collect and integrate other reviewers’ perspectives and experiences in conducting systematic methods overviews on a broad range of qualitative and quantitative methods topics. Formalized guidance and standards would improve the quality of future methods overviews, something we believe has important implications for advancing qualitative and quantitative methodology. When undertaken to a high standard, rigorous critical evaluations of the available methods guidance have significant potential to make implicit controversies explicit, and improve the clarity and precision of our understandings of problematic qualitative or quantitative methods issues.
A review process central to most types of rigorous reviews of empirical studies, which we did not explicitly address in a separate review step above, is quality appraisal . The reason we have not treated this as a separate step stems from the different objectives of the primary publications included in overviews of the methods literature (i.e., providing methodological guidance) compared to the primary publications included in the other established review types (i.e., reporting findings from single empirical studies). This is not to say that appraising quality of the methods literature is not an important concern for systematic methods overviews. Rather, appraisal is much more integral to (and difficult to separate from) the analysis step, in which we advocate appraising clarity, consistency, and comprehensiveness—the quality appraisal criteria that we suggest are appropriate for the methods literature. As a second important difference regarding appraisal, we currently advocate appraising the aforementioned aspects at the level of the literature in aggregate rather than at the level of individual publications. One reason for this is that methods guidance from individual publications generally builds on previous literature, and thus we feel that ahistorical judgments about comprehensiveness of single publications lack relevance and utility. Additionally, while different methods authors may express themselves less clearly than others, their guidance can nonetheless be highly influential and useful, and should therefore not be downgraded or ignored based on considerations of clarity—which raises questions about the alternative uses that quality appraisals of individual publications might have. Finally, legitimate variability in the perspectives that methods authors wish to emphasize, and the levels of generality at which they write about methods, makes critiquing individual publications based on the criterion of clarity a complex and potentially problematic endeavor that is beyond the scope of this paper to address. By appraising the current state of the literature at a holistic level, reviewers stand to identify important gaps in understanding that represent valuable opportunities for further methodological development.
To summarize, the principles and strategies provided here may be useful to those seeking to undertake their own systematic methods overview. Additional work is needed, however, to establish guidance that is comprehensive by comparing the experiences from conducting a variety of methods overviews on a range of methods topics. Efforts that further advance standards for systematic methods overviews have the potential to promote high-quality critical evaluations that produce conceptually clear and unified understandings of problematic methods topics, thereby accelerating the advance of research methodology.
Hutton JL, Ashcroft R. What does “systematic” mean for reviews of methods? In: Black N, Brazier J, Fitzpatrick R, Reeves B, editors. Health services research methods: a guide to best practice. London: BMJ Publishing Group; 1998. p. 249–54.
Google Scholar
Cochrane handbook for systematic reviews of interventions. In. Edited by Higgins JPT, Green S, Version 5.1.0 edn: The Cochrane Collaboration; 2011.
Centre for Reviews and Dissemination: Systematic reviews: CRD’s guidance for undertaking reviews in health care . York: Centre for Reviews and Dissemination; 2009.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gotzsche PC, Ioannidis JPA, Clarke M, Devereaux PJ, Kleijnen J, Moher D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: explanation and elaboration. BMJ. 2009;339:b2700–0.
Barnett-Page E, Thomas J. Methods for the synthesis of qualitative research: a critical review. BMC Med Res Methodol. 2009;9(1):59.
Article PubMed PubMed Central Google Scholar
Kastner M, Tricco AC, Soobiah C, Lillie E, Perrier L, Horsley T, Welch V, Cogo E, Antony J, Straus SE. What is the most appropriate knowledge synthesis method to conduct a review? Protocol for a scoping review. BMC Med Res Methodol. 2012;12(1):1–1.
Article Google Scholar
Booth A, Noyes J, Flemming K, Gerhardus A. Guidance on choosing qualitative evidence synthesis methods for use in health technology assessments of complex interventions. In: Integrate-HTA. 2016.
Booth A, Sutton A, Papaioannou D. Systematic approaches to successful literature review. 2nd ed. London: Sage; 2016.
Hannes K, Lockwood C. Synthesizing qualitative research: choosing the right approach. Chichester: Wiley-Blackwell; 2012.
Suri H. Towards methodologically inclusive research syntheses: expanding possibilities. New York: Routledge; 2014.
Campbell M, Egan M, Lorenc T, Bond L, Popham F, Fenton C, Benzeval M. Considering methodological options for reviews of theory: illustrated by a review of theories linking income and health. Syst Rev. 2014;3(1):1–11.
Cohen DJ, Crabtree BF. Evaluative criteria for qualitative research in health care: controversies and recommendations. Ann Fam Med. 2008;6(4):331–9.
Tong A, Sainsbury P, Craig J. Consolidated criteria for reportingqualitative research (COREQ): a 32-item checklist for interviews and focus groups. Int J Qual Health Care. 2007;19(6):349–57.
Article PubMed Google Scholar
Moher D, Schulz KF, Simera I, Altman DG. Guidance for developers of health research reporting guidelines. PLoS Med. 2010;7(2):e1000217.
Moher D, Tetzlaff J, Tricco AC, Sampson M, Altman DG. Epidemiology and reporting characteristics of systematic reviews. PLoS Med. 2007;4(3):e78.
Chan AW, Altman DG. Epidemiology and reporting of randomised trials published in PubMed journals. Lancet. 2005;365(9465):1159–62.
Alshurafa M, Briel M, Akl EA, Haines T, Moayyedi P, Gentles SJ, Rios L, Tran C, Bhatnagar N, Lamontagne F, et al. Inconsistent definitions for intention-to-treat in relation to missing outcome data: systematic review of the methods literature. PLoS One. 2012;7(11):e49163.
Article CAS PubMed PubMed Central Google Scholar
Gentles SJ, Charles C, Ploeg J, McKibbon KA. Sampling in qualitative research: insights from an overview of the methods literature. Qual Rep. 2015;20(11):1772–89.
Harzing A-W, Alakangas S. Google Scholar, Scopus and the Web of Science: a longitudinal and cross-disciplinary comparison. Scientometrics. 2016;106(2):787–804.
Harzing A-WK, van der Wal R. Google Scholar as a new source for citation analysis. Ethics Sci Environ Polit. 2008;8(1):61–73.
Kousha K, Thelwall M. Google Scholar citations and Google Web/URL citations: a multi‐discipline exploratory analysis. J Assoc Inf Sci Technol. 2007;58(7):1055–65.
Hirsch JE. An index to quantify an individual’s scientific research output. Proc Natl Acad Sci U S A. 2005;102(46):16569–72.
Booth A, Carroll C. How to build up the actionable knowledge base: the role of ‘best fit’ framework synthesis for studies of improvement in healthcare. BMJ Quality Safety. 2015;24(11):700–8.
Carroll C, Booth A, Leaviss J, Rick J. “Best fit” framework synthesis: refining the method. BMC Med Res Methodol. 2013;13(1):37.
Carroll C, Booth A, Cooper K. A worked example of “best fit” framework synthesis: a systematic review of views concerning the taking of some potential chemopreventive agents. BMC Med Res Methodol. 2011;11(1):29.
Cohen MZ, Kahn DL, Steeves DL. Hermeneutic phenomenological research: a practical guide for nurse researchers. Thousand Oaks: Sage; 2000.
Noblit GW, Hare RD. Meta-ethnography: synthesizing qualitative studies. Newbury Park: Sage; 1988.
Book Google Scholar
Melendez-Torres GJ, Grant S, Bonell C. A systematic review and critical appraisal of qualitative metasynthetic practice in public health to develop a taxonomy of operations of reciprocal translation. Res Synthesis Methods. 2015;6(4):357–71.
Article CAS Google Scholar
Glaser BG, Strauss A. The discovery of grounded theory. Chicago: Aldine; 1967.
Dixon-Woods M, Agarwal S, Young B, Jones D, Sutton A. Integrative approaches to qualitative and quantitative evidence. In: UK National Health Service. 2004. p. 1–44.
Download references
Acknowledgements
Not applicable.
There was no funding for this work.
Availability of data and materials
The systematic methods overview used as a worked example in this article (Gentles SJ, Charles C, Ploeg J, McKibbon KA: Sampling in qualitative research: insights from an overview of the methods literature. The Qual Rep 2015, 20(11):1772-1789) is available from http://nsuworks.nova.edu/tqr/vol20/iss11/5 .
Authors’ contributions
SJG wrote the first draft of this article, with CC contributing to drafting. All authors contributed to revising the manuscript. All authors except CC (deceased) approved the final draft. SJG, CC, KAB, and JP were involved in developing methods for the systematic methods overview on sampling.
Authors’ information
Competing interests.
The authors declare that they have no competing interests.
Consent for publication
Ethics approval and consent to participate, author information, authors and affiliations.
Department of Clinical Epidemiology and Biostatistics, McMaster University, Hamilton, Ontario, Canada
Stephen J. Gentles, Cathy Charles & K. Ann McKibbon
Faculty of Social Work, University of Calgary, Alberta, Canada
David B. Nicholas
School of Nursing, McMaster University, Hamilton, Ontario, Canada
Jenny Ploeg
CanChild Centre for Childhood Disability Research, McMaster University, 1400 Main Street West, IAHS 408, Hamilton, ON, L8S 1C7, Canada
Stephen J. Gentles
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Stephen J. Gentles .
Additional information
Cathy Charles is deceased
Additional file
Additional file 1:.
Submitted: Analysis_matrices. (DOC 330 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License ( http://creativecommons.org/licenses/by/4.0/ ), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated.
Reprints and permissions
About this article
Cite this article.
Gentles, S.J., Charles, C., Nicholas, D.B. et al. Reviewing the research methods literature: principles and strategies illustrated by a systematic overview of sampling in qualitative research. Syst Rev 5 , 172 (2016). https://doi.org/10.1186/s13643-016-0343-0
Download citation
Received : 06 June 2016
Accepted : 14 September 2016
Published : 11 October 2016
DOI : https://doi.org/10.1186/s13643-016-0343-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Systematic review
- Literature selection
- Research methods
- Research methodology
- Overview of methods
- Systematic methods overview
- Review methods
Systematic Reviews
ISSN: 2046-4053
- Submission enquiries: Access here and click Contact Us
- General enquiries: [email protected]

Archer Library
Quantitative research: literature review .
- Archer Library This link opens in a new window
- Research Resources handout This link opens in a new window
- Locating Books
- Library eBook Collections This link opens in a new window
- A to Z Database List This link opens in a new window
- Research & Statistics
- Literature Review Resources
- Citations & Reference
Exploring the literature review
Literature review model: 6 steps.

Adapted from The Literature Review , Machi & McEvoy (2009, p. 13).
Your Literature Review
Step 2: search, boolean search strategies, search limiters, ★ ebsco & google drive.

1. Select a Topic
"All research begins with curiosity" (Machi & McEvoy, 2009, p. 14)
Selection of a topic, and fully defined research interest and question, is supervised (and approved) by your professor. Tips for crafting your topic include:
- Be specific. Take time to define your interest.
- Topic Focus. Fully describe and sufficiently narrow the focus for research.
- Academic Discipline. Learn more about your area of research & refine the scope.
- Avoid Bias. Be aware of bias that you (as a researcher) may have.
- Document your research. Use Google Docs to track your research process.
- Research apps. Consider using Evernote or Zotero to track your research.
Consider Purpose
What will your topic and research address?
In The Literature Review: A Step-by-Step Guide for Students , Ridley presents that literature reviews serve several purposes (2008, p. 16-17). Included are the following points:
- Historical background for the research;
- Overview of current field provided by "contemporary debates, issues, and questions;"
- Theories and concepts related to your research;
- Introduce "relevant terminology" - or academic language - being used it the field;
- Connect to existing research - does your work "extend or challenge [this] or address a gap;"
- Provide "supporting evidence for a practical problem or issue" that your research addresses.
★ Schedule a research appointment
At this point in your literature review, take time to meet with a librarian. Why? Understanding the subject terminology used in databases can be challenging. Archer Librarians can help you structure a search, preparing you for step two. How? Contact a librarian directly or use the online form to schedule an appointment. Details are provided in the adjacent Schedule an Appointment box.
2. Search the Literature
Collect & Select Data: Preview, select, and organize
Archer Library is your go-to resource for this step in your literature review process. The literature search will include books and ebooks, scholarly and practitioner journals, theses and dissertations, and indexes. You may also choose to include web sites, blogs, open access resources, and newspapers. This library guide provides access to resources needed to complete a literature review.
Books & eBooks: Archer Library & OhioLINK
| Books | |
Databases: Scholarly & Practitioner Journals
Review the Library Databases tab on this library guide, it provides links to recommended databases for Education & Psychology, Business, and General & Social Sciences.
Expand your journal search; a complete listing of available AU Library and OhioLINK databases is available on the Databases A to Z list . Search the database by subject, type, name, or do use the search box for a general title search. The A to Z list also includes open access resources and select internet sites.
Databases: Theses & Dissertations
Review the Library Databases tab on this guide, it includes Theses & Dissertation resources. AU library also has AU student authored theses and dissertations available in print, search the library catalog for these titles.
Did you know? If you are looking for particular chapters within a dissertation that is not fully available online, it is possible to submit an ILL article request . Do this instead of requesting the entire dissertation.
Newspapers: Databases & Internet
Consider current literature in your academic field. AU Library's database collection includes The Chronicle of Higher Education and The Wall Street Journal . The Internet Resources tab in this guide provides links to newspapers and online journals such as Inside Higher Ed , COABE Journal , and Education Week .
The Chronicle of Higher Education has the nation’s largest newsroom dedicated to covering colleges and universities. Source of news, information, and jobs for college and university faculty members and administrators
The Chronicle features complete contents of the latest print issue; daily news and advice columns; current job listings; archive of previously published content; discussion forums; and career-building tools such as online CV management and salary databases. Dates covered: 1970-present.
Search Strategies & Boolean Operators
There are three basic boolean operators: AND, OR, and NOT.
Used with your search terms, boolean operators will either expand or limit results. What purpose do they serve? They help to define the relationship between your search terms. For example, using the operator AND will combine the terms expanding the search. When searching some databases, and Google, the operator AND may be implied.
Overview of boolean terms
| Search results will contain of the terms. | Search results will contain of the search terms. | Search results the specified search term. |
| Search for ; you will find items that contain terms. | Search for ; you will find items that contain . | Search for online education: you will find items that contain . |
| connects terms, limits the search, and will reduce the number of results returned. | redefines connection of the terms, expands the search, and increases the number of results returned. | excludes results from the search term and reduces the number of results. |
|
Adult learning online education: |
Adult learning online education: |
Adult learning online education: |
About the example: Boolean searches were conducted on November 4, 2019; result numbers may vary at a later date. No additional database limiters were set to further narrow search returns.
Database Search Limiters
Database strategies for targeted search results.
Most databases include limiters, or additional parameters, you may use to strategically focus search results. EBSCO databases, such as Education Research Complete & Academic Search Complete provide options to:
- Limit results to full text;
- Limit results to scholarly journals, and reference available;
- Select results source type to journals, magazines, conference papers, reviews, and newspapers
- Publication date
Keep in mind that these tools are defined as limiters for a reason; adding them to a search will limit the number of results returned. This can be a double-edged sword. How?
- If limiting results to full-text only, you may miss an important piece of research that could change the direction of your research. Interlibrary loan is available to students, free of charge. Request articles that are not available in full-text; they will be sent to you via email.
- If narrowing publication date, you may eliminate significant historical - or recent - research conducted on your topic.
- Limiting resource type to a specific type of material may cause bias in the research results.
Use limiters with care. When starting a search, consider opting out of limiters until the initial literature screening is complete. The second or third time through your research may be the ideal time to focus on specific time periods or material (scholarly vs newspaper).
★ Truncating Search Terms
Expanding your search term at the root.
Truncating is often referred to as 'wildcard' searching. Databases may have their own specific wildcard elements however, the most commonly used are the asterisk (*) or question mark (?). When used within your search. they will expand returned results.
Asterisk (*) Wildcard
Using the asterisk wildcard will return varied spellings of the truncated word. In the following example, the search term education was truncated after the letter "t."
| Original Search | |
| adult education | adult educat* |
| Results included: educate, education, educator, educators'/educators, educating, & educational |
Explore these database help pages for additional information on crafting search terms.
- EBSCO Connect: Basic Searching with EBSCO
- EBSCO Connect: Searching with Boolean Operators
- EBSCO Connect: Searching with Wildcards and Truncation Symbols
- ProQuest Help: Search Tips
- ERIC: How does ERIC search work?
★ EBSCO Databases & Google Drive
Tips for saving research directly to Google drive.
Researching in an EBSCO database?
It is possible to save articles (PDF and HTML) and abstracts in EBSCOhost databases directly to Google drive. Select the Google Drive icon, authenticate using a Google account, and an EBSCO folder will be created in your account. This is a great option for managing your research. If documenting your research in a Google Doc, consider linking the information to actual articles saved in drive.
EBSCO Databases & Google Drive
EBSCOHost Databases & Google Drive: Managing your Research
This video features an overview of how to use Google Drive with EBSCO databases to help manage your research. It presents information for connecting an active Google account to EBSCO and steps needed to provide permission for EBSCO to manage a folder in Drive.
About the Video: Closed captioning is available, select CC from the video menu. If you need to review a specific area on the video, view on YouTube and expand the video description for access to topic time stamps. A video transcript is provided below.
- EBSCOhost Databases & Google Scholar
Defining Literature Review
What is a literature review.
A definition from the Online Dictionary for Library and Information Sciences .
A literature review is "a comprehensive survey of the works published in a particular field of study or line of research, usually over a specific period of time, in the form of an in-depth, critical bibliographic essay or annotated list in which attention is drawn to the most significant works" (Reitz, 2014).
A systemic review is "a literature review focused on a specific research question, which uses explicit methods to minimize bias in the identification, appraisal, selection, and synthesis of all the high-quality evidence pertinent to the question" (Reitz, 2014).
Recommended Reading

About this page
EBSCO Connect [Discovery and Search]. (2022). Searching with boolean operators. Retrieved May, 3, 2022 from https://connect.ebsco.com/s/?language=en_US
EBSCO Connect [Discover and Search]. (2022). Searching with wildcards and truncation symbols. Retrieved May 3, 2022; https://connect.ebsco.com/s/?language=en_US
Machi, L.A. & McEvoy, B.T. (2009). The literature review . Thousand Oaks, CA: Corwin Press:
Reitz, J.M. (2014). Online dictionary for library and information science. ABC-CLIO, Libraries Unlimited . Retrieved from https://www.abc-clio.com/ODLIS/odlis_A.aspx
Ridley, D. (2008). The literature review: A step-by-step guide for students . Thousand Oaks, CA: Sage Publications, Inc.
Archer Librarians
Schedule an appointment.
Contact a librarian directly (email), or submit a request form. If you have worked with someone before, you can request them on the form.
- ★ Archer Library Help • Online Reqest Form
- Carrie Halquist • Reference & Instruction
- Jessica Byers • Reference & Curation
- Don Reams • Corrections Education & Reference
- Diane Schrecker • Education & Head of the IRC
- Tanaya Silcox • Technical Services & Business
- Sarah Thomas • Acquisitions & ATS Librarian
- << Previous: Research & Statistics
- Next: Literature Review Resources >>
- Last Updated: Jun 27, 2024 11:14 AM
- URL: https://libguides.ashland.edu/quantitative
Archer Library • Ashland University © Copyright 2023. An Equal Opportunity/Equal Access Institution.
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Literature Review
What exactly is a literature review.
- Critical Exploration and Synthesis: It involves a thorough and critical examination of existing research, going beyond simple summaries to synthesize information.
- Reorganizing Key Information: Involves structuring and categorizing the main ideas and findings from various sources.
- Offering Fresh Interpretations: Provides new perspectives or insights into the research topic.
- Merging New and Established Insights: Integrates both recent findings and well-established knowledge in the field.
- Analyzing Intellectual Trajectories: Examines the evolution and debates within a specific field over time.
- Contextualizing Current Research: Places recent research within the broader academic landscape, showing its relevance and relation to existing knowledge.
- Detailed Overview of Sources: Gives a comprehensive summary of relevant books, articles, and other scholarly materials.
- Highlighting Significance: Emphasizes the importance of various research works to the specific topic of study.
How do Literature Reviews Differ from Academic Research Papers?
- Focus on Existing Arguments: Literature reviews summarize and synthesize existing research, unlike research papers that present new arguments.
- Secondary vs. Primary Research: Literature reviews are based on secondary sources, while research papers often include primary research.
- Foundational Element vs. Main Content: In research papers, literature reviews are usually a part of the background, not the main focus.
- Lack of Original Contributions: Literature reviews do not introduce new theories or findings, which is a key component of research papers.
Purpose of Literature Reviews
- Drawing from Diverse Fields: Literature reviews incorporate findings from various fields like health, education, psychology, business, and more.
- Prioritizing High-Quality Studies: They emphasize original, high-quality research for accuracy and objectivity.
- Serving as Comprehensive Guides: Offer quick, in-depth insights for understanding a subject thoroughly.
- Foundational Steps in Research: Act as a crucial first step in conducting new research by summarizing existing knowledge.
- Providing Current Knowledge for Professionals: Keep professionals updated with the latest findings in their fields.
- Demonstrating Academic Expertise: In academia, they showcase the writer’s deep understanding and contribute to the background of research papers.
- Essential for Scholarly Research: A deep understanding of literature is vital for conducting and contextualizing scholarly research.
A Literature Review is Not About:
- Merely Summarizing Sources: It’s not just a compilation of summaries of various research works.
- Ignoring Contradictions: It does not overlook conflicting evidence or viewpoints in the literature.
- Being Unstructured: It’s not a random collection of information without a clear organizing principle.
- Avoiding Critical Analysis: It doesn’t merely present information without critically evaluating its relevance and credibility.
- Focusing Solely on Older Research: It’s not limited to outdated or historical literature, ignoring recent developments.
- Isolating Research: It doesn’t treat each source in isolation but integrates them into a cohesive narrative.
Steps Involved in Conducting a Research Literature Review (Fink, 2019)
1. choose a clear research question., 2. use online databases and other resources to find articles and books relevant to your question..
- Google Scholar
- OSU Library
- ERIC. Index to journal articles on educational research and practice.
- PsycINFO . Citations and abstracts for articles in 1,300 professional journals, conference proceedings, books, reports, and dissertations in psychology and related disciplines.
- PubMed . This search system provides access to the PubMed database of bibliographic information, which is drawn primarily from MEDLINE, which indexes articles from about 3,900 journals in the life sciences (e.g., health, medicine, biology).
- Social Sciences Citation Index . A multidisciplinary database covering the journal literature of the social sciences, indexing more than 1,725 journals across 50 social sciences disciplines.
3. Decide on Search Terms.
- Pick words and phrases based on your research question to find suitable materials
- You can start by finding models for your literature review, and search for existing reviews in your field, using “review” and your keywords. This helps identify themes and organizational methods.
- Narrowing your topic is crucial due to the vast amount of literature available. Focusing on a specific aspect makes it easier to manage the number of sources you need to review, as it’s unlikely you’ll need to cover everything in the field.
- Use AND to retrieve a set of citations in which each citation contains all search terms.
- Use OR to retrieve citations that contain one of the specified terms.
- Use NOT to exclude terms from your search.
- Be careful when using NOT because you may inadvertently eliminate important articles. In Example 3, articles about preschoolers and academic achievement are eliminated, but so are studies that include preschoolers as part of a discussion of academic achievement and all age groups.
4. Filter out articles that don’t meet criteria like language, type, publication date, and funding source.
- Publication language Example. Include only studies in English.
- Journal Example. Include all education journals. Exclude all medical journals.
- Author Example. Include all articles by Andrew Hayes.
- Setting Example. Include all studies that take place in family settings. Exclude all studies that take place in the school setting.
- Participants or subjects Example. Include children that are younger than 6 years old.
- Program/intervention Example. Include all programs that are teacher-led. Exclude all programs that are learner-initiated.
- Research design Example. Include only longitudinal studies. Exclude cross-sectional studies.
- Sampling Example. Include only studies that rely on randomly selected participants.
- Date of publication Example. Include only studies published from January 1, 2010, to December 31, 2023.
- Date of data collection Example. Include only studies that collected data from 2010 through 2023. Exclude studies that do not give dates of data collection.
- Duration of data collection Example. Include only studies that collect data for 12 months or longer.
5. Evaluate the methodological quality of the articles, including research design, sampling, data collection, interventions, data analysis, results, and conclusions.
- Maturation: Changes in individuals due to natural development may impact study results, such as intellectual or emotional growth in long-term studies.
- Selection: The method of choosing and assigning participants to groups can introduce bias; random selection minimizes this.
- History: External historical events occurring simultaneously with the study can bias results, making it hard to isolate the study’s effects.
- Instrumentation: Reliable data collection tools are essential to ensure accurate findings, especially in pretest-posttest designs.
- Statistical Regression: Selection based on extreme initial measures can lead to misleading results due to regression towards the mean.
- Attrition: Loss of participants during a study can bias results if those remaining differ significantly from those who dropped out.
- Reactive Effects of Testing: Pre-intervention measures can sensitize participants to the study’s aims, affecting outcomes.
- Interactive Effects of Selection: Unique combinations of intervention programs and participants can limit the generalizability of findings.
- Reactive Effects of Innovation: Artificial experimental environments can lead to uncharacteristic behavior among participants.
- Multiple-Program Interference: Difficulty in isolating an intervention’s effects due to participants’ involvement in other activities or programs.
- Simple Random Sampling : Every individual has an equal chance of being selected, making this method relatively unbiased.
- Systematic Sampling : Selection is made at regular intervals from a list, such as every sixth name from a list of 3,000 to obtain a sample of 500.
- Stratified Sampling : The population is divided into subgroups, and random samples are then taken from each subgroup.
- Cluster Sampling : Natural groups (like schools or cities) are used as batches for random selection, both at the group and individual levels.
- Convenience Samples : Selection probability is unknown; these samples are easy to obtain but may not be representative unless statistically validated.
- Study Power: The ability of a study to detect an effect, if present, is known as its power. Power analysis helps identify a sample size large enough to detect this effect.
- Test-Retest Reliability: High correlation between scores obtained at different times, indicating consistency over time.
- Equivalence/Alternate-Form Reliability: The degree to which two different assessments measure the same concept at the same difficulty level.
- Homogeneity: The extent to which all items or questions in a measure assess the same skill, characteristic, or quality.
- Interrater Reliability: Degree of agreement among different individuals assessing the same item or concept.
- Content Validity: Measures how thoroughly and appropriately a tool assesses the skills or characteristics it’s supposed to measure. Face Validity: Assesses whether a measure appears effective at first glance in terms of language use and comprehensiveness. Criterion Validity: Includes predictive validity (forecasting future performance) and concurrent validity (agreement with already valid measures). Construct Validity: Experimentally established to show that a measure effectively differentiates between people with and without certain characteristics.
- Relies on factors like the scale (categorical, ordinal, numerical) of independent and dependent variables, the count of these variables, and whether the data’s quality and characteristics align with the chosen statistical method’s assumptions.
6. Use a standard form for data extraction, train reviewers if needed, and ensure quality.
7. interpret the results, using your experience and the literature’s quality and content. for a more detailed analysis, a meta-analysis can be conducted using statistical methods to combine study results., 8. produce a descriptive review or perform a meta-analysis..
- Example: Bryman, A. (2007). Effective leadership in higher education: A literature review. Studies in higher education, 32(6), 693-710.
- Clarify the objectives of the analysis.
- Set explicit criteria for including and excluding studies.
- Describe in detail the methods used to search the literature.
- Search the literature using a standardized protocol for including and excluding studies.
- Use a standardized protocol to collect (“abstract”) data from each study regarding study purposes, methods, and effects (outcomes).
- Describe in detail the statistical method for pooling results.
- Report results, conclusions, and limitations.
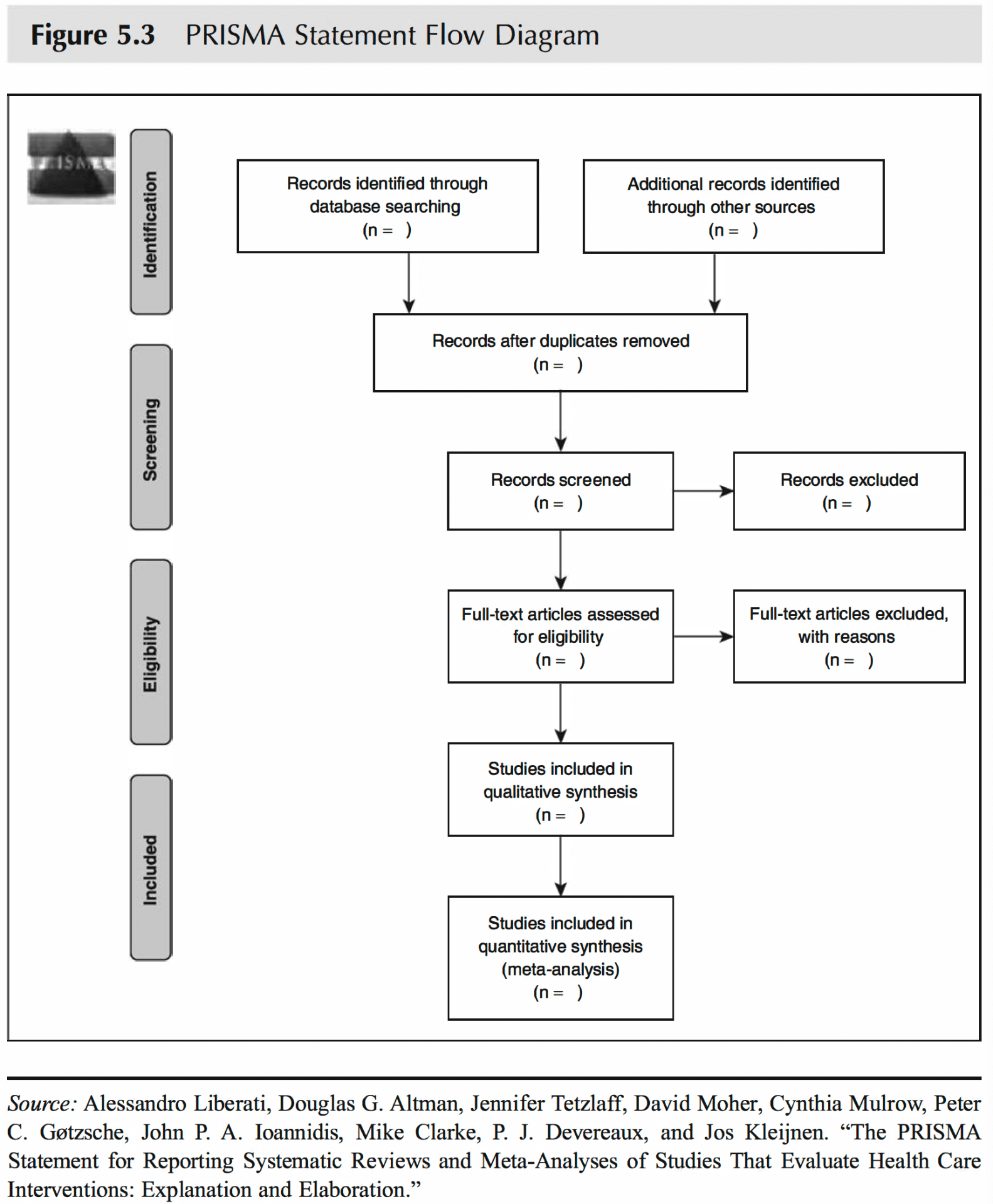
- Example: Yu, Z. (2023). A meta-analysis of the effect of virtual reality technology use in education. Interactive Learning Environments, 31 (8), 4956-4976.
- Essential and Multifunctional Bibliographic Software: Tools like EndNote, ProCite, BibTex, Bookeeper, Zotero, and Mendeley offer more than just digital storage for references; they enable saving and sharing search strategies, directly inserting references into reports and scholarly articles, and analyzing references by thematic content.
- Comprehensive Literature Reviews: Involve supplementing electronic searches with a review of references in identified literature, manual searches of references and journals, and consulting experts for both unpublished and published studies and reports.
- One of the most famous reporting checklists is the Consolidated Standards of Reporting Trials ( CONSORT ). CONSORT consists of a checklist and flow diagram. The checklist includes items that need to be addressed in the report.
References:
Bryman, A. (2007). Effective leadership in higher education: A literature review. Studies in higher education , 32 (6), 693-710.
Fink, A. (2019). Conducting research literature reviews: From the internet to paper . Sage publications.
Yu, Z. (2023). A meta-analysis of the effect of virtual reality technology use in education. Interactive Learning Environments, 31 (8), 4956-4976.
- Locations and Hours
- UCLA Library
- Research Guides
- Biomedical Library Guides
Systematic Reviews
- Types of Literature Reviews
What Makes a Systematic Review Different from Other Types of Reviews?
- Planning Your Systematic Review
- Database Searching
- Creating the Search
- Search Filters and Hedges
- Grey Literature
- Managing and Appraising Results
- Further Resources
Reproduced from Grant, M. J. and Booth, A. (2009), A typology of reviews: an analysis of 14 review types and associated methodologies. Health Information & Libraries Journal, 26: 91–108. doi:10.1111/j.1471-1842.2009.00848.x
| Aims to demonstrate writer has extensively researched literature and critically evaluated its quality. Goes beyond mere description to include degree of analysis and conceptual innovation. Typically results in hypothesis or mode | Seeks to identify most significant items in the field | No formal quality assessment. Attempts to evaluate according to contribution | Typically narrative, perhaps conceptual or chronological | Significant component: seeks to identify conceptual contribution to embody existing or derive new theory | |
| Generic term: published materials that provide examination of recent or current literature. Can cover wide range of subjects at various levels of completeness and comprehensiveness. May include research findings | May or may not include comprehensive searching | May or may not include quality assessment | Typically narrative | Analysis may be chronological, conceptual, thematic, etc. | |
| Mapping review/ systematic map | Map out and categorize existing literature from which to commission further reviews and/or primary research by identifying gaps in research literature | Completeness of searching determined by time/scope constraints | No formal quality assessment | May be graphical and tabular | Characterizes quantity and quality of literature, perhaps by study design and other key features. May identify need for primary or secondary research |
| Technique that statistically combines the results of quantitative studies to provide a more precise effect of the results | Aims for exhaustive, comprehensive searching. May use funnel plot to assess completeness | Quality assessment may determine inclusion/ exclusion and/or sensitivity analyses | Graphical and tabular with narrative commentary | Numerical analysis of measures of effect assuming absence of heterogeneity | |
| Refers to any combination of methods where one significant component is a literature review (usually systematic). Within a review context it refers to a combination of review approaches for example combining quantitative with qualitative research or outcome with process studies | Requires either very sensitive search to retrieve all studies or separately conceived quantitative and qualitative strategies | Requires either a generic appraisal instrument or separate appraisal processes with corresponding checklists | Typically both components will be presented as narrative and in tables. May also employ graphical means of integrating quantitative and qualitative studies | Analysis may characterise both literatures and look for correlations between characteristics or use gap analysis to identify aspects absent in one literature but missing in the other | |
| Generic term: summary of the [medical] literature that attempts to survey the literature and describe its characteristics | May or may not include comprehensive searching (depends whether systematic overview or not) | May or may not include quality assessment (depends whether systematic overview or not) | Synthesis depends on whether systematic or not. Typically narrative but may include tabular features | Analysis may be chronological, conceptual, thematic, etc. | |
| Method for integrating or comparing the findings from qualitative studies. It looks for ‘themes’ or ‘constructs’ that lie in or across individual qualitative studies | May employ selective or purposive sampling | Quality assessment typically used to mediate messages not for inclusion/exclusion | Qualitative, narrative synthesis | Thematic analysis, may include conceptual models | |
| Assessment of what is already known about a policy or practice issue, by using systematic review methods to search and critically appraise existing research | Completeness of searching determined by time constraints | Time-limited formal quality assessment | Typically narrative and tabular | Quantities of literature and overall quality/direction of effect of literature | |
| Preliminary assessment of potential size and scope of available research literature. Aims to identify nature and extent of research evidence (usually including ongoing research) | Completeness of searching determined by time/scope constraints. May include research in progress | No formal quality assessment | Typically tabular with some narrative commentary | Characterizes quantity and quality of literature, perhaps by study design and other key features. Attempts to specify a viable review | |
| Tend to address more current matters in contrast to other combined retrospective and current approaches. May offer new perspectives | Aims for comprehensive searching of current literature | No formal quality assessment | Typically narrative, may have tabular accompaniment | Current state of knowledge and priorities for future investigation and research | |
| Seeks to systematically search for, appraise and synthesis research evidence, often adhering to guidelines on the conduct of a review | Aims for exhaustive, comprehensive searching | Quality assessment may determine inclusion/exclusion | Typically narrative with tabular accompaniment | What is known; recommendations for practice. What remains unknown; uncertainty around findings, recommendations for future research | |
| Combines strengths of critical review with a comprehensive search process. Typically addresses broad questions to produce ‘best evidence synthesis’ | Aims for exhaustive, comprehensive searching | May or may not include quality assessment | Minimal narrative, tabular summary of studies | What is known; recommendations for practice. Limitations | |
| Attempt to include elements of systematic review process while stopping short of systematic review. Typically conducted as postgraduate student assignment | May or may not include comprehensive searching | May or may not include quality assessment | Typically narrative with tabular accompaniment | What is known; uncertainty around findings; limitations of methodology | |
| Specifically refers to review compiling evidence from multiple reviews into one accessible and usable document. Focuses on broad condition or problem for which there are competing interventions and highlights reviews that address these interventions and their results | Identification of component reviews, but no search for primary studies | Quality assessment of studies within component reviews and/or of reviews themselves | Graphical and tabular with narrative commentary | What is known; recommendations for practice. What remains unknown; recommendations for future research |
- << Previous: Home
- Next: Planning Your Systematic Review >>
- Last Updated: Apr 17, 2024 2:02 PM
- URL: https://guides.library.ucla.edu/systematicreviews
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Systematic Review | Definition, Example, & Guide
Systematic Review | Definition, Example & Guide
Published on June 15, 2022 by Shaun Turney . Revised on November 20, 2023.
A systematic review is a type of review that uses repeatable methods to find, select, and synthesize all available evidence. It answers a clearly formulated research question and explicitly states the methods used to arrive at the answer.
They answered the question “What is the effectiveness of probiotics in reducing eczema symptoms and improving quality of life in patients with eczema?”
In this context, a probiotic is a health product that contains live microorganisms and is taken by mouth. Eczema is a common skin condition that causes red, itchy skin.
Table of contents
What is a systematic review, systematic review vs. meta-analysis, systematic review vs. literature review, systematic review vs. scoping review, when to conduct a systematic review, pros and cons of systematic reviews, step-by-step example of a systematic review, other interesting articles, frequently asked questions about systematic reviews.
A review is an overview of the research that’s already been completed on a topic.
What makes a systematic review different from other types of reviews is that the research methods are designed to reduce bias . The methods are repeatable, and the approach is formal and systematic:
- Formulate a research question
- Develop a protocol
- Search for all relevant studies
- Apply the selection criteria
- Extract the data
- Synthesize the data
- Write and publish a report
Although multiple sets of guidelines exist, the Cochrane Handbook for Systematic Reviews is among the most widely used. It provides detailed guidelines on how to complete each step of the systematic review process.
Systematic reviews are most commonly used in medical and public health research, but they can also be found in other disciplines.
Systematic reviews typically answer their research question by synthesizing all available evidence and evaluating the quality of the evidence. Synthesizing means bringing together different information to tell a single, cohesive story. The synthesis can be narrative ( qualitative ), quantitative , or both.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Systematic reviews often quantitatively synthesize the evidence using a meta-analysis . A meta-analysis is a statistical analysis, not a type of review.
A meta-analysis is a technique to synthesize results from multiple studies. It’s a statistical analysis that combines the results of two or more studies, usually to estimate an effect size .
A literature review is a type of review that uses a less systematic and formal approach than a systematic review. Typically, an expert in a topic will qualitatively summarize and evaluate previous work, without using a formal, explicit method.
Although literature reviews are often less time-consuming and can be insightful or helpful, they have a higher risk of bias and are less transparent than systematic reviews.
Similar to a systematic review, a scoping review is a type of review that tries to minimize bias by using transparent and repeatable methods.
However, a scoping review isn’t a type of systematic review. The most important difference is the goal: rather than answering a specific question, a scoping review explores a topic. The researcher tries to identify the main concepts, theories, and evidence, as well as gaps in the current research.
Sometimes scoping reviews are an exploratory preparation step for a systematic review, and sometimes they are a standalone project.
Prevent plagiarism. Run a free check.
A systematic review is a good choice of review if you want to answer a question about the effectiveness of an intervention , such as a medical treatment.
To conduct a systematic review, you’ll need the following:
- A precise question , usually about the effectiveness of an intervention. The question needs to be about a topic that’s previously been studied by multiple researchers. If there’s no previous research, there’s nothing to review.
- If you’re doing a systematic review on your own (e.g., for a research paper or thesis ), you should take appropriate measures to ensure the validity and reliability of your research.
- Access to databases and journal archives. Often, your educational institution provides you with access.
- Time. A professional systematic review is a time-consuming process: it will take the lead author about six months of full-time work. If you’re a student, you should narrow the scope of your systematic review and stick to a tight schedule.
- Bibliographic, word-processing, spreadsheet, and statistical software . For example, you could use EndNote, Microsoft Word, Excel, and SPSS.
A systematic review has many pros .
- They minimize research bias by considering all available evidence and evaluating each study for bias.
- Their methods are transparent , so they can be scrutinized by others.
- They’re thorough : they summarize all available evidence.
- They can be replicated and updated by others.
Systematic reviews also have a few cons .
- They’re time-consuming .
- They’re narrow in scope : they only answer the precise research question.
The 7 steps for conducting a systematic review are explained with an example.
Step 1: Formulate a research question
Formulating the research question is probably the most important step of a systematic review. A clear research question will:
- Allow you to more effectively communicate your research to other researchers and practitioners
- Guide your decisions as you plan and conduct your systematic review
A good research question for a systematic review has four components, which you can remember with the acronym PICO :
- Population(s) or problem(s)
- Intervention(s)
- Comparison(s)
You can rearrange these four components to write your research question:
- What is the effectiveness of I versus C for O in P ?
Sometimes, you may want to include a fifth component, the type of study design . In this case, the acronym is PICOT .
- Type of study design(s)
- The population of patients with eczema
- The intervention of probiotics
- In comparison to no treatment, placebo , or non-probiotic treatment
- The outcome of changes in participant-, parent-, and doctor-rated symptoms of eczema and quality of life
- Randomized control trials, a type of study design
Their research question was:
- What is the effectiveness of probiotics versus no treatment, a placebo, or a non-probiotic treatment for reducing eczema symptoms and improving quality of life in patients with eczema?
Step 2: Develop a protocol
A protocol is a document that contains your research plan for the systematic review. This is an important step because having a plan allows you to work more efficiently and reduces bias.
Your protocol should include the following components:
- Background information : Provide the context of the research question, including why it’s important.
- Research objective (s) : Rephrase your research question as an objective.
- Selection criteria: State how you’ll decide which studies to include or exclude from your review.
- Search strategy: Discuss your plan for finding studies.
- Analysis: Explain what information you’ll collect from the studies and how you’ll synthesize the data.
If you’re a professional seeking to publish your review, it’s a good idea to bring together an advisory committee . This is a group of about six people who have experience in the topic you’re researching. They can help you make decisions about your protocol.
It’s highly recommended to register your protocol. Registering your protocol means submitting it to a database such as PROSPERO or ClinicalTrials.gov .
Step 3: Search for all relevant studies
Searching for relevant studies is the most time-consuming step of a systematic review.
To reduce bias, it’s important to search for relevant studies very thoroughly. Your strategy will depend on your field and your research question, but sources generally fall into these four categories:
- Databases: Search multiple databases of peer-reviewed literature, such as PubMed or Scopus . Think carefully about how to phrase your search terms and include multiple synonyms of each word. Use Boolean operators if relevant.
- Handsearching: In addition to searching the primary sources using databases, you’ll also need to search manually. One strategy is to scan relevant journals or conference proceedings. Another strategy is to scan the reference lists of relevant studies.
- Gray literature: Gray literature includes documents produced by governments, universities, and other institutions that aren’t published by traditional publishers. Graduate student theses are an important type of gray literature, which you can search using the Networked Digital Library of Theses and Dissertations (NDLTD) . In medicine, clinical trial registries are another important type of gray literature.
- Experts: Contact experts in the field to ask if they have unpublished studies that should be included in your review.
At this stage of your review, you won’t read the articles yet. Simply save any potentially relevant citations using bibliographic software, such as Scribbr’s APA or MLA Generator .
- Databases: EMBASE, PsycINFO, AMED, LILACS, and ISI Web of Science
- Handsearch: Conference proceedings and reference lists of articles
- Gray literature: The Cochrane Library, the metaRegister of Controlled Trials, and the Ongoing Skin Trials Register
- Experts: Authors of unpublished registered trials, pharmaceutical companies, and manufacturers of probiotics
Step 4: Apply the selection criteria
Applying the selection criteria is a three-person job. Two of you will independently read the studies and decide which to include in your review based on the selection criteria you established in your protocol . The third person’s job is to break any ties.
To increase inter-rater reliability , ensure that everyone thoroughly understands the selection criteria before you begin.
If you’re writing a systematic review as a student for an assignment, you might not have a team. In this case, you’ll have to apply the selection criteria on your own; you can mention this as a limitation in your paper’s discussion.
You should apply the selection criteria in two phases:
- Based on the titles and abstracts : Decide whether each article potentially meets the selection criteria based on the information provided in the abstracts.
- Based on the full texts: Download the articles that weren’t excluded during the first phase. If an article isn’t available online or through your library, you may need to contact the authors to ask for a copy. Read the articles and decide which articles meet the selection criteria.
It’s very important to keep a meticulous record of why you included or excluded each article. When the selection process is complete, you can summarize what you did using a PRISMA flow diagram .
Next, Boyle and colleagues found the full texts for each of the remaining studies. Boyle and Tang read through the articles to decide if any more studies needed to be excluded based on the selection criteria.
When Boyle and Tang disagreed about whether a study should be excluded, they discussed it with Varigos until the three researchers came to an agreement.
Step 5: Extract the data
Extracting the data means collecting information from the selected studies in a systematic way. There are two types of information you need to collect from each study:
- Information about the study’s methods and results . The exact information will depend on your research question, but it might include the year, study design , sample size, context, research findings , and conclusions. If any data are missing, you’ll need to contact the study’s authors.
- Your judgment of the quality of the evidence, including risk of bias .
You should collect this information using forms. You can find sample forms in The Registry of Methods and Tools for Evidence-Informed Decision Making and the Grading of Recommendations, Assessment, Development and Evaluations Working Group .
Extracting the data is also a three-person job. Two people should do this step independently, and the third person will resolve any disagreements.
They also collected data about possible sources of bias, such as how the study participants were randomized into the control and treatment groups.
Step 6: Synthesize the data
Synthesizing the data means bringing together the information you collected into a single, cohesive story. There are two main approaches to synthesizing the data:
- Narrative ( qualitative ): Summarize the information in words. You’ll need to discuss the studies and assess their overall quality.
- Quantitative : Use statistical methods to summarize and compare data from different studies. The most common quantitative approach is a meta-analysis , which allows you to combine results from multiple studies into a summary result.
Generally, you should use both approaches together whenever possible. If you don’t have enough data, or the data from different studies aren’t comparable, then you can take just a narrative approach. However, you should justify why a quantitative approach wasn’t possible.
Boyle and colleagues also divided the studies into subgroups, such as studies about babies, children, and adults, and analyzed the effect sizes within each group.
Step 7: Write and publish a report
The purpose of writing a systematic review article is to share the answer to your research question and explain how you arrived at this answer.
Your article should include the following sections:
- Abstract : A summary of the review
- Introduction : Including the rationale and objectives
- Methods : Including the selection criteria, search method, data extraction method, and synthesis method
- Results : Including results of the search and selection process, study characteristics, risk of bias in the studies, and synthesis results
- Discussion : Including interpretation of the results and limitations of the review
- Conclusion : The answer to your research question and implications for practice, policy, or research
To verify that your report includes everything it needs, you can use the PRISMA checklist .
Once your report is written, you can publish it in a systematic review database, such as the Cochrane Database of Systematic Reviews , and/or in a peer-reviewed journal.
In their report, Boyle and colleagues concluded that probiotics cannot be recommended for reducing eczema symptoms or improving quality of life in patients with eczema. Note Generative AI tools like ChatGPT can be useful at various stages of the writing and research process and can help you to write your systematic review. However, we strongly advise against trying to pass AI-generated text off as your own work.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
A literature review is a survey of scholarly sources (such as books, journal articles, and theses) related to a specific topic or research question .
It is often written as part of a thesis, dissertation , or research paper , in order to situate your work in relation to existing knowledge.
A literature review is a survey of credible sources on a topic, often used in dissertations , theses, and research papers . Literature reviews give an overview of knowledge on a subject, helping you identify relevant theories and methods, as well as gaps in existing research. Literature reviews are set up similarly to other academic texts , with an introduction , a main body, and a conclusion .
An annotated bibliography is a list of source references that has a short description (called an annotation ) for each of the sources. It is often assigned as part of the research process for a paper .
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Turney, S. (2023, November 20). Systematic Review | Definition, Example & Guide. Scribbr. Retrieved July 5, 2024, from https://www.scribbr.com/methodology/systematic-review/
Is this article helpful?

Shaun Turney
Other students also liked, how to write a literature review | guide, examples, & templates, how to write a research proposal | examples & templates, what is critical thinking | definition & examples, get unlimited documents corrected.
✔ Free APA citation check included ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
University Libraries
- Research Guides
- Blackboard Learn
- Interlibrary Loan
- Study Rooms
- University of Arkansas
Literature Reviews
- Qualitative or Quantitative?
- Getting Started
- Finding articles
- Primary sources? Peer-reviewed?
- Review Articles/ Annual Reviews...?
- Books, ebooks, dissertations, book reviews
Qualitative researchers TEND to:
Researchers using qualitative methods tend to:
- t hink that social sciences cannot be well-studied with the same methods as natural or physical sciences
- feel that human behavior is context-specific; therefore, behavior must be studied holistically, in situ, rather than being manipulated
- employ an 'insider's' perspective; research tends to be personal and thereby more subjective.
- do interviews, focus groups, field research, case studies, and conversational or content analysis.

Image from https://www.editage.com/insights/qualitative-quantitative-or-mixed-methods-a-quick-guide-to-choose-the-right-design-for-your-research?refer-type=infographics
Qualitative Research (an operational definition)
Qualitative Research: an operational description
Purpose : explain; gain insight and understanding of phenomena through intensive collection and study of narrative data
Approach: inductive; value-laden/subjective; holistic, process-oriented
Hypotheses: tentative, evolving; based on the particular study
Lit. Review: limited; may not be exhaustive
Setting: naturalistic, when and as much as possible
Sampling : for the purpose; not necessarily representative; for in-depth understanding
Measurement: narrative; ongoing
Design and Method: flexible, specified only generally; based on non-intervention, minimal disturbance, such as historical, ethnographic, or case studies
Data Collection: document collection, participant observation, informal interviews, field notes
Data Analysis: raw data is words/ ongoing; involves synthesis
Data Interpretation: tentative, reviewed on ongoing basis, speculative
- Qualitative research with more structure and less subjectivity
- Increased application of both strategies to the same study ("mixed methods")
- Evidence-based practice emphasized in more fields (nursing, social work, education, and others).
Some Other Guidelines
- Guide for formatting Graphs and Tables
- Critical Appraisal Checklist for an Article On Qualitative Research
Quantitative researchers TEND to:
Researchers using quantitative methods tend to:
- think that both natural and social sciences strive to explain phenomena with confirmable theories derived from testable assumptions
- attempt to reduce social reality to variables, in the same way as with physical reality
- try to tightly control the variable(s) in question to see how the others are influenced.
- Do experiments, have control groups, use blind or double-blind studies; use measures or instruments.

Quantitative Research (an operational definition)
Quantitative research: an operational description
Purpose: explain, predict or control phenomena through focused collection and analysis of numberical data
Approach: deductive; tries to be value-free/has objectives/ is outcome-oriented
Hypotheses : Specific, testable, and stated prior to study
Lit. Review: extensive; may significantly influence a particular study
Setting: controlled to the degree possible
Sampling: uses largest manageable random/randomized sample, to allow generalization of results to larger populations
Measurement: standardized, numberical; "at the end"
Design and Method: Strongly structured, specified in detail in advance; involves intervention, manipulation and control groups; descriptive, correlational, experimental
Data Collection: via instruments, surveys, experiments, semi-structured formal interviews, tests or questionnaires
Data Analysis: raw data is numbers; at end of study, usually statistical
Data Interpretation: formulated at end of study; stated as a degree of certainty
This page on qualitative and quantitative research has been adapted and expanded from a handout by Suzy Westenkirchner. Used with permission.
Images from https://www.editage.com/insights/qualitative-quantitative-or-mixed-methods-a-quick-guide-to-choose-the-right-design-for-your-research?refer-type=infographics.
- << Previous: Books, ebooks, dissertations, book reviews
- Last Updated: Jul 1, 2024 9:09 AM
- URL: https://uark.libguides.com/litreview
- See us on Instagram
- Follow us on Twitter
- Phone: 479-575-4104
Communicative Sciences and Disorders
- Online Learners: Quick Links
- ASHA Journals
- Research Tip 1: Define the Research Question
- Reference Resources
- Evidence Summaries & Clinical Guidelines
- Drug Information
- Health Data & Statistics
- Patient/Consumer Facing Materials
- Images/Streaming Video
- Database Tutorials
- Crafting a Search
- Cited Reference Searching
- Research Tip 4: Find Grey Literature
- Research Tip 5: Save Your Work
- Cite and Manage Your Sources
- Critical Appraisal
- What are Literature Reviews?
- Conducting & Reporting Systematic Reviews
- Finding Systematic Reviews
- Tutorials & Tools for Literature Reviews
- Point of Care Tools (Mobile Apps)
Choosing a Review Type
For guidance related to choosing a review type, see:
- "What Type of Review is Right for You?" - Decision Tree (PDF) This decision tree, from Cornell University Library, highlights key difference between narrative, systematic, umbrella, scoping and rapid reviews.
- Reviewing the literature: choosing a review design Noble, H., & Smith, J. (2018). Reviewing the literature: Choosing a review design. Evidence Based Nursing, 21(2), 39–41. https://doi.org/10.1136/eb-2018-102895
- What synthesis methodology should I use? A review and analysis of approaches to research synthesis Schick-Makaroff, K., MacDonald, M., Plummer, M., Burgess, J., & Neander, W. (2016). What synthesis methodology should I use? A review and analysis of approaches to research synthesis. AIMS Public Health, 3 (1), 172-215. doi:10.3934/publichealth.2016.1.172 More information less... ABSTRACT: Our purpose is to present a comprehensive overview and assessment of the main approaches to research synthesis. We use "research synthesis" as a broad overarching term to describe various approaches to combining, integrating, and synthesizing research findings.
- Right Review - Decision Support Tool Not sure of the most suitable review method? Answer a few questions and be guided to suitable knowledge synthesis methods. Updated in 2022 and featured in the Journal of Clinical Epidemiology 10.1016/j.jclinepi.2022.03.004
Types of Evidence Synthesis / Literature Reviews
Literature reviews are comprehensive summaries and syntheses of the previous research on a given topic. While narrative reviews are common across all academic disciplines, reviews that focus on appraising and synthesizing research evidence are increasingly important in the health and social sciences.
Most evidence synthesis methods use formal and explicit methods to identify, select and combine results from multiple studies, making evidence synthesis a form of meta-research.
The review purpose, methods used and the results produced vary among different kinds of literature reviews; some of the common types of literature review are detailed below.
Common Types of Literature Reviews 1
Narrative (literature) review.
- A broad term referring to reviews with a wide scope and non-standardized methodology
- Search strategies, comprehensiveness of literature search, time range covered and method of synthesis will vary and do not follow an established protocol
Integrative Review
- A type of literature review based on a systematic, structured literature search
- Often has a broadly defined purpose or review question
- Seeks to generate or refine and theory or hypothesis and/or develop a holistic understanding of a topic of interest
- Relies on diverse sources of data (e.g. empirical, theoretical or methodological literature; qualitative or quantitative studies)
Systematic Review
- Systematically and transparently collects and categorize existing evidence on a question of scientific, policy or management importance
- Follows a research protocol that is established a priori
- Some sub-types of systematic reviews include: SRs of intervention effectiveness, diagnosis, prognosis, etiology, qualitative evidence, economic evidence, and more.
- Time-intensive and often takes months to a year or more to complete
- The most commonly referred to type of evidence synthesis; sometimes confused as a blanket term for other types of reviews
Meta-Analysis
- Statistical technique for combining the findings from disparate quantitative studies
- Uses statistical methods to objectively evaluate, synthesize, and summarize results
- Often conducted as part of a systematic review
Scoping Review
- Systematically and transparently collects and categorizes existing evidence on a broad question of scientific, policy or management importance
- Seeks to identify research gaps, identify key concepts and characteristics of the literature and/or examine how research is conducted on a topic of interest
- Useful when the complexity or heterogeneity of the body of literature does not lend itself to a precise systematic review
- Useful if authors do not have a single, precise review question
- May critically evaluate existing evidence, but does not attempt to synthesize the results in the way a systematic review would
- May take longer than a systematic review
Rapid Review
- Applies a systematic review methodology within a time-constrained setting
- Employs methodological "shortcuts" (e.g., limiting search terms and the scope of the literature search), at the risk of introducing bias
- Useful for addressing issues requiring quick decisions, such as developing policy recommendations
Umbrella Review
- Reviews other systematic reviews on a topic
- Often defines a broader question than is typical of a traditional systematic review
- Most useful when there are competing interventions to consider
1. Adapted from:
Eldermire, E. (2021, November 15). A guide to evidence synthesis: Types of evidence synthesis. Cornell University LibGuides. https://guides.library.cornell.edu/evidence-synthesis/types
Nolfi, D. (2021, October 6). Integrative Review: Systematic vs. Scoping vs. Integrative. Duquesne University LibGuides. https://guides.library.duq.edu/c.php?g=1055475&p=7725920
Delaney, L. (2021, November 24). Systematic reviews: Other review types. UniSA LibGuides. https://guides.library.unisa.edu.au/SystematicReviews/OtherReviewTypes
Further Reading: Exploring Different Types of Literature Reviews
- A typology of reviews: An analysis of 14 review types and associated methodologies Grant, M. J., & Booth, A. (2009). A typology of reviews: An analysis of 14 review types and associated methodologies. Health Information and Libraries Journal, 26 (2), 91-108. doi:10.1111/j.1471-1842.2009.00848.x More information less... ABSTRACT: The expansion of evidence-based practice across sectors has lead to an increasing variety of review types. However, the diversity of terminology used means that the full potential of these review types may be lost amongst a confusion of indistinct and misapplied terms. The objective of this study is to provide descriptive insight into the most common types of reviews, with illustrative examples from health and health information domains.
- Clarifying differences between review designs and methods Gough, D., Thomas, J., & Oliver, S. (2012). Clarifying differences between review designs and methods. Systematic Reviews, 1 , 28. doi:10.1186/2046-4053-1-28 More information less... ABSTRACT: This paper argues that the current proliferation of types of systematic reviews creates challenges for the terminology for describing such reviews....It is therefore proposed that the most useful strategy for the field is to develop terminology for the main dimensions of variation.
- Are we talking the same paradigm? Considering methodological choices in health education systematic review Gordon, M. (2016). Are we talking the same paradigm? Considering methodological choices in health education systematic review. Medical Teacher, 38 (7), 746-750. doi:10.3109/0142159X.2016.1147536 More information less... ABSTRACT: Key items discussed are the positivist synthesis methods meta-analysis and content analysis to address questions in the form of "whether and what" education is effective. These can be juxtaposed with the constructivist aligned thematic analysis and meta-ethnography to address questions in the form of "why." The concept of the realist review is also considered. It is proposed that authors of such work should describe their research alignment and the link between question, alignment and evidence synthesis method selected.
- Meeting the review family: Exploring review types and associated information retrieval requirements Sutton, A., Clowes, M., Preston, L., & Booth, A. (2019). Meeting the review family: Exploring review types and associated information retrieval requirements. Health Information & Libraries Journal, 36(3), 202–222. doi: 10.1111/hir.12276

Integrative Reviews
"The integrative review method is an approach that allows for the inclusion of diverse methodologies (i.e. experimental and non-experimental research)." (Whittemore & Knafl, 2005, p. 547).
- The integrative review: Updated methodology Whittemore, R., & Knafl, K. (2005). The integrative review: Updated methodology. Journal of Advanced Nursing, 52 (5), 546–553. doi:10.1111/j.1365-2648.2005.03621.x More information less... ABSTRACT: The aim of this paper is to distinguish the integrative review method from other review methods and to propose methodological strategies specific to the integrative review method to enhance the rigour of the process....An integrative review is a specific review method that summarizes past empirical or theoretical literature to provide a more comprehensive understanding of a particular phenomenon or healthcare problem....Well-done integrative reviews present the state of the science, contribute to theory development, and have direct applicability to practice and policy.

- Conducting integrative reviews: A guide for novice nursing researchers Dhollande, S., Taylor, A., Meyer, S., & Scott, M. (2021). Conducting integrative reviews: A guide for novice nursing researchers. Journal of Research in Nursing, 26(5), 427–438. https://doi.org/10.1177/1744987121997907
- Rigour in integrative reviews Whittemore, R. (2007). Rigour in integrative reviews. In C. Webb & B. Roe (Eds.), Reviewing Research Evidence for Nursing Practice (pp. 149–156). John Wiley & Sons, Ltd. https://doi.org/10.1002/9780470692127.ch11
Scoping Reviews
Scoping reviews are evidence syntheses that are conducted systematically, but begin with a broader scope of question than traditional systematic reviews, allowing the research to 'map' the relevant literature on a given topic.
- Scoping studies: Towards a methodological framework Arksey, H., & O'Malley, L. (2005). Scoping studies: Towards a methodological framework. International Journal of Social Research Methodology, 8 (1), 19-32. doi:10.1080/1364557032000119616 More information less... ABSTRACT: We distinguish between different types of scoping studies and indicate where these stand in relation to full systematic reviews. We outline a framework for conducting a scoping study based on our recent experiences of reviewing the literature on services for carers for people with mental health problems.
- Scoping studies: Advancing the methodology Levac, D., Colquhoun, H., & O'Brien, K. K. (2010). Scoping studies: Advancing the methodology. Implementation Science, 5 (1), 69. doi:10.1186/1748-5908-5-69 More information less... ABSTRACT: We build upon our experiences conducting three scoping studies using the Arksey and O'Malley methodology to propose recommendations that clarify and enhance each stage of the framework.
- Methodology for JBI scoping reviews Peters, M. D. J., Godfrey, C. M., McInerney, P., Baldini Soares, C., Khalil, H., & Parker, D. (2015). The Joanna Briggs Institute reviewers’ manual: Methodology for JBI scoping reviews [PDF]. Retrieved from The Joanna Briggs Institute website: http://joannabriggs.org/assets/docs/sumari/Reviewers-Manual_Methodology-for-JBI-Scoping-Reviews_2015_v2.pdf More information less... ABSTRACT: Unlike other reviews that address relatively precise questions, such as a systematic review of the effectiveness of a particular intervention based on a precise set of outcomes, scoping reviews can be used to map the key concepts underpinning a research area as well as to clarify working definitions, and/or the conceptual boundaries of a topic. A scoping review may focus on one of these aims or all of them as a set.
Systematic vs. Scoping Reviews: What's the Difference?
YouTube Video 4 minutes, 45 seconds
Rapid Reviews
Rapid reviews are systematic reviews that are undertaken under a tighter timeframe than traditional systematic reviews.
- Evidence summaries: The evolution of a rapid review approach Khangura, S., Konnyu, K., Cushman, R., Grimshaw, J., & Moher, D. (2012). Evidence summaries: The evolution of a rapid review approach. Systematic Reviews, 1 (1), 10. doi:10.1186/2046-4053-1-10 More information less... ABSTRACT: Rapid reviews have emerged as a streamlined approach to synthesizing evidence - typically for informing emergent decisions faced by decision makers in health care settings. Although there is growing use of rapid review "methods," and proliferation of rapid review products, there is a dearth of published literature on rapid review methodology. This paper outlines our experience with rapidly producing, publishing and disseminating evidence summaries in the context of our Knowledge to Action (KTA) research program.
- What is a rapid review? A methodological exploration of rapid reviews in Health Technology Assessments Harker, J., & Kleijnen, J. (2012). What is a rapid review? A methodological exploration of rapid reviews in Health Technology Assessments. International Journal of Evidence‐Based Healthcare, 10 (4), 397-410. doi:10.1111/j.1744-1609.2012.00290.x More information less... ABSTRACT: In recent years, there has been an emergence of "rapid reviews" within Health Technology Assessments; however, there is no known published guidance or agreed methodology within recognised systematic review or Health Technology Assessment guidelines. In order to answer the research question "What is a rapid review and is methodology consistent in rapid reviews of Health Technology Assessments?", a study was undertaken in a sample of rapid review Health Technology Assessments from the Health Technology Assessment database within the Cochrane Library and other specialised Health Technology Assessment databases to investigate similarities and/or differences in rapid review methodology utilised.
- Rapid Review Guidebook Dobbins, M. (2017). Rapid review guidebook. Hamilton, ON: National Collaborating Centre for Methods and Tools.
- NCCMT Summary and Tool for Dobbins' Rapid Review Guidebook National Collaborating Centre for Methods and Tools. (2017). Rapid review guidebook. Hamilton, ON: McMaster University. Retrieved from http://www.nccmt.ca/knowledge-repositories/search/308
- << Previous: Literature Reviews
- Next: Conducting & Reporting Systematic Reviews >>
- Last Updated: Jun 26, 2024 3:00 PM
- URL: https://guides.nyu.edu/speech
To read this content please select one of the options below:
Please note you do not have access to teaching notes, a contemporary systematic literature review of equestrian tourism: emerging advancements and future insights.
Journal of Hospitality and Tourism Insights
ISSN : 2514-9792
Article publication date: 2 July 2024
Horse-based tourism stands at the intersection of cultural heritage, leisure activities, and eco-friendly travel, captivating enthusiasts and researchers alike with its diverse facets and impacts. This study examines the horse-based tourism literature to provide an overview of horse-based tourism publications.
Design/methodology/approach
Using a systematic literature review (SLR) method, pertinent journal articles published over the past 3 decades were retrieved and analyzed. Based on the review process, 44 papers were identified and analyzed by publication year, journal distribution, research method, and lead author. Using Leximancer software, a thematic analysis was undertaken to determine the major themes of horse-based tourism.
The findings revealed a rising trend of horse-based tourism articles and the appearance of an increasing number of studies in tourism-oriented journals. In addition, it was discovered that the majority of available studies are qualitative, whereas quantitative research is few and limited.
Research limitations/implications
Our research establishes a foundational resource for future studies and scholarly discourse on the multifaceted contributions of horse-based tourism.
Practical implications
This study can assist decision-makers in understanding the potential of horse-based tourism in the sustainable development of destinations. Moreover, it provides clear direction on implementing appropriate strategies to manage horse-based tourism.
Originality/value
This study distinguishes itself as the inaugural comprehensive literature review encompassing the breadth of horse-based tourism publications and research domains. By pioneering this endeavor, we not only contribute a unique perspective to the existing body of knowledge in the field but also emphasize the vital role of horse-based tourism in fostering economic and social sustainability for the countries involved.
- Horse-based tourism
- Equestrian tourism
- Systematic literature review
- Research domains
- Thematic analysis
Rezapouraghdam, H. , Saydam, M.B. , Altun, O. , Roudi, S. and Nosrati, S. (2024), "A contemporary systematic literature review of equestrian tourism: emerging advancements and future insights", Journal of Hospitality and Tourism Insights , Vol. ahead-of-print No. ahead-of-print. https://doi.org/10.1108/JHTI-01-2024-0046
Emerald Publishing Limited
Copyright © 2024, Emerald Publishing Limited
Related articles
All feedback is valuable.
Please share your general feedback
Report an issue or find answers to frequently asked questions
Contact Customer Support
Warning: The NCBI web site requires JavaScript to function. more...
An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Galdas P, Darwin Z, Fell J, et al. A systematic review and metaethnography to identify how effective, cost-effective, accessible and acceptable self-management support interventions are for men with long-term conditions (SELF-MAN). Southampton (UK): NIHR Journals Library; 2015 Aug. (Health Services and Delivery Research, No. 3.34.)

A systematic review and metaethnography to identify how effective, cost-effective, accessible and acceptable self-management support interventions are for men with long-term conditions (SELF-MAN).
Chapter 2 quantitative review methods.
A systematic review and meta-analysis was conducted based upon a protocol published on the PROSPERO database (registration number CRD42013005394, URL: www.crd.york.ac.uk/PROSPERO/display_record.asp?ID=CRD42013005394 ).
Deviations from the original protocol are presented in Box 1 .
Deviations from original PROSPERO protocol The target population are male adults (aged 18 years or over) living with one or more long-term conditions.
- Search strategy
We searched the following databases using a search strategy developed in conjunction with an information specialist from the Centre for Reviews and Dissemination, University of York (see Appendix 1 ): Cochrane Database of Systematic Reviews (CDSR); Database of Abstracts of Reviews of Effects (DARE) (up to July 2013); PROSPERO (International Prospective Register of Systematic Reviews) (up to July 2013); and Medical Literature Analysis and Retrieval System Online (MEDLINE) (January 2012 to July 2013). The breadth of the literature identified meant we took a pragmatic approach and limited our search to CDSR; see Box 1 .
Inclusion/exclusion criteria
Randomised controlled trials (RCTs) investigating self-management support interventions in men with LTCs (identified via Cochrane systematic reviews of self-management support interventions) were included. Studies which analysed the effects of self-management support interventions in sex groups within a RCT were also identified and synthesised separately.
The following population, intervention, comparison and outcome criteria were used:
- Population and setting : adults, 18 years of age or older, diagnosed with a LTC. We limited the review to studies of patients with 14 ‘exemplar’ LTCs (informed by disease areas prioritised in the PRISMS study and team discussions): asthma, diabetes, depression, hypertension, heart failure, chronic obstructive pulmonary disease (COPD), arthritis, chronic kidney disease, chronic pain, human immunodeficiency virus (HIV), testicular cancer, prostate cancer, prostate hyperplasia and chronic skin conditions in any setting. Studies including inpatients with depression were excluded. Studies including patients with multimorbidity involving at least one ‘exemplar’ condition were considered.
An intervention primarily designed to develop the abilities of patients to undertake management of health conditions through education, training and support to develop patient knowledge, skills or psychological and social resources.
- Comparison : any comparison group. We considered studies using ‘care as usual’ or any other intervention.
- Outcomes : effectiveness, cost-effectiveness. We extracted data on the effect of interventions on health status, clinical measures, health behaviour, health-care use, self-efficacy, knowledge and understanding, communication with health-care professionals (HCPs) and effects on members/carers.
- Study design : RCTs identified via eligible Cochrane systematic reviews. Only papers published in the English language were included, as translation was not feasible in the time frame of the project. In instances where records were unobtainable, attempts were made to contact authors to request the information.
Criteria for defining a self-management support intervention The intervention should, through some means of education, training or support, help people with a LTC by:
- Identification of studies
We piloted the screening criteria on a sample of papers before undertaking the main screening, in order to identify and resolve any inconsistencies. Screening was conducted in two phases:
- identification of relevant Cochrane systematic reviews
- identification of relevant RCTs within included Cochrane systematic reviews.
For phase 1, an initial screen by title and abstract was conducted by one researcher. Two researchers then screened each article independently according to the screening criteria to identify relevant systematic reviews. Disagreements were resolved by a third researcher (principal investigator) as required.
For phase 2, each Cochrane review was screened independently for eligible RCTs by two researchers. The eligibility of each RCT was checked using the study information presented within Cochrane reviews before full papers were sourced. Full texts of each RCT were independently screened by two researchers and disagreements were resolved by a third researcher (principal investigator) as required.
For this review we focused on identifying male-only RCTs and trials which analysed the effects of interventions by sex groups. Agreement on Cochrane review eligibility was 89% and agreement on male-only RCT inclusion/exclusion and identification of RCTs containing sex group analyses was > 90%.
- Data extraction
We designed a data extraction sheet and piloted this on a sample of papers prior to the main data extraction. Relevant data from each included article were extracted by a member of the review team and checked for completeness and accuracy by a second member of the team. Disagreements were discussed and resolved by a third person (principal investigator) as required. In instances where key information for meta-analysis was missing, efforts were made to contact authors. We extracted data on study and population characteristics, intervention details (setting, duration, frequency, individual/group, delivered by), outcome measures of health status, clinical measures, health behaviour, health-care use, self-efficacy, knowledge and understanding, communication with HCPs and items for quality assessment (Cochrane risk of bias tool 35 ). Items for economic evaluations [hospital admission, service use, health-related quality of life (HRQoL), incremental cost-effectiveness ratios] were also extracted.
Where studies were reported in multiple publications, each publication was included and relevant data were extracted.
- Quality assessment strategy
We extracted data on the methodological quality of all included male-only RCTs and appraised this using the Cochrane risk of bias tool. Quality appraisal was undertaken by two researchers independently and disagreements were resolved through discussion. Sequence generation, allocation concealment, blinding, incomplete outcome data, selective outcome reporting and other sources of bias were assessed, assigning low, high or unclear risk of bias, as appropriate. The purpose of the quality appraisal was to describe the quality of the evidence base, not to give an inclusion/exclusion criterion.
Randomised controlled trials containing sex group analyses were assessed for quality using assessment criteria adapted from Pincus et al. 36 and Sun et al. 37 ‘Yes’, ‘No’ and ‘Unclear’ were recorded as responses to the following quality appraisal questions:
- Was the group hypothesis considered a priori?
- Was gender included as a stratification factor at randomisation?
- Was gender one of a small number of planned group hypotheses tested (≤ 5)?
- Was the study free of other bias (randomisation, allocation concealment, outcome reporting)?
- Data analysis
Meta-analysis was conducted using Review Manager version 5.2 (The Nordic Cochrane Centre, The Cochrane Collaboration, Copenhagen, Denmark).
Data were extracted, analysed and presented as standardised mean difference (SMD) to account for the different instruments used, unless otherwise stated. As a guide to the magnitude of effect, we categorised an effect size of 0.2 as representing a ‘small’ effect, 0.5 a ‘moderate’ effect and 0.8 a ‘large’ effect. 38
A random-effects model was used to combine study data. Statistical heterogeneity was assessed with the I 2 value, with ‘low’ heterogeneity set at ≤ 25%, ‘moderate’ 50% and ‘high’ 75%.
In instances where studies contained multiple intervention groups, each group was extracted and analysed independently, dividing the control group sample size to avoid double counting in the analysis.
The following outcome measures were used in the analysis where possible: HRQoL, depression, anxiety, fatigue, stress, distress, pain and self-efficacy. Where a study contained more than one measure of a particular outcome (e.g. depression measured by the Centre for Epidemiologic Studies Depression Scale 39 and Beck Depression Inventory 40 ), the tool most established in the wider literature was chosen for meta-analysis. If the tool had multiple subscales, a judgement was made about the most relevant subscale. Where studies reported at multiple time periods, outcome measures reported at or closest to 6 months were used, as measures around this time were by far the most frequently reported.
Unless otherwise specified in the results section, positive effect sizes indicate beneficial outcomes for HRQoL and self-efficacy outcomes, while negative effect sizes indicate beneficial outcomes for depression, anxiety, fatigue, stress, distress and pain outcomes.
We conducted four types of analysis, described below.
Analysis 1: ‘within-Cochrane review analysis’
Analysis 1 sought to determine whether studies in males show larger, similar or smaller effects than studies in females and mixed-sex groups within interventions included within the ‘parent’ Cochrane review. We screened all included Cochrane reviews of self-management support interventions to identify those that contained analysis on outcomes of interest and at least two relevant male-only RCTs. Where an eligible review was identified that met these criteria, the studies were categorised as male only, mixed sex and female only ( Figure 1 ).
Analysis 1: ‘within-Cochrane review analysis’.
Such comparisons across trials do not have the protection of randomisation, and there may be differences between the studies included in each sex group which account for differences in effects between groups. We presented data on the comparability of these trials within these three categories, including the age of the included patient populations, and on the quality of the studies (using allocation concealment as an indicator of quality).
We report the effect size [together with significance and 95% confidence interval (CI)] of self-management support in each sex group (male only, mixed sex, female only). We conducted analyses to test whether or not interventions showed significantly different effects in sex groups. It should be noted that the power to detect significant differences in such analyses can be limited.
Analysis 2: ‘across-Cochrane review analysis’
Analysis 2 sought to determine whether studies in males show larger, similar or smaller effects than studies in females and mixed-sex groups within types of self-management support pooled across reviews.
In analysis 2, data were pooled according to broad intervention type across reviews, rather than within individual reviews as in analysis 1 ( Figure 2 ). This allowed us to determine whether broad types/components of self-management support interventions show larger, similar or smaller effects in males than in females and mixed populations. Limitations in the data meant that we were able to conduct analyses on only physical activity, education, peer support, and HCP monitoring and feedback interventions.
Analysis 2: ‘across-Cochrane review analysis’.
We report the effect size (together with significance and 95% CI) of self-management support in each sex group (male only, mixed sex, female only). We conducted analyses to test whether or not interventions showed significantly different effects in sex groups. It should be noted that the power to detect significant differences in such analyses can be limited.
Analysis 3: ‘male-only intervention type analyses’
We conducted a meta-analysis on trials including males only, according to broad intervention type – physical activity, education, peer support, and HCP monitoring and feedback – and compared effects between intervention types ( Figure 3 ). This allowed us to determine whether or not certain broad categories of self-management support intervention were effective in men.
Analysis 3: ‘male-only intervention type analyses’.
Analysis 4: ‘within-trial sex group analysis’
We identified RCTs which analysed the effects of self-management support interventions in sex groups. We sought to extract relevant data on the direction and size of moderating effects in secondary analysis (i.e. whether males show larger, similar or smaller effects than females), and assess these effects in the context of relevant design data, such as sample size, and the quality of the secondary analysis ( Figure 4 ).
Analysis 4: ‘within-trial sex group analysis’.
Sex group analyses within trials do in theory provide greater comparability in terms of patient and intervention characteristics than analyses 1–3.
A mixture of LTCs was included within each analysis, constituting the main analysis. Although this was not in the original protocol, we attempted to conduct an analysis by each disease area. We found there were sufficient data to conduct a sex-comparative analysis in only cancer studies; the results are presented in Appendix 2 .
- Coding interventions for analysis
The plan to use the behavioural change techniques (BCT) taxonomy was dropped (see Box 1 on protocol deviations). Post hoc, we took a pragmatic approach to coding interventions. Development of the intervention categories was informed by the published literature identified in this project and previous work conducted by the PRISMS and RECURSIVE project teams. 7 , 33 Table 1 provides a list of the categories and their associated description. Categories were designed to be broadly representative of the interventions identified and facilitate comparison of intervention types in the analysis. Two members of the review team independently assessed the ‘type’ of self-management support intervention in each study in order to categorise it, and disagreements were identified and resolved by discussion with a team member.
Self-management support intervention categories and description
- Economic evaluation
The review of cost-effectiveness studies was initially planned as a two-stage review. First, we would review economic evaluations of self-management interventions on males only. Subsequently, we would review all economic evaluations with group analyses in which the costs and effects for males and females could be separated.
Study quality was assessed using a modified version of the Drummond checklist where appropriate. 45
- Study characteristics
Setting and sample
We identified a total of 40 RCTs on self-management support interventions conducted in male-only samples (some trials have more than one reference) ( Figure 5 ). The majority of the studies were conducted in the USA ( n = 23), 46 – 70 with the remainder conducted in the UK ( n = 6), 71 – 78 Canada ( n = 5), 79 – 83 Spain ( n = 3), 84 – 88 Sweden ( n = 1), 89 Poland ( n = 1) 90 and Greece ( n = 1). 91 Males with prostate cancer were the most frequently studied male-only population ( n = 15) included in this review. 48 , 49 , 52 , 58 , 59 , 61 , 64 – 66 , 68 , 69 , 72 , 78 , 80 , 89 Other disease areas included hypertension ( n = 6), 47 , 71 , 79 , 82 , 83 , 85 , 86 COPD ( n = 6), 54 , 55 , 73 – 76 , 81 , 84 , 87 , 88 heart failure ( n = 4), 62 , 67 , 90 , 91 type 2 diabetes ( n = 3), 46 , 50 , 51 , 70 diabetes of unspecified type ( n = 1), 56 arthritis ( n = 1) 63 and testicular cancer ( n = 1). 77 One multimorbidity study recruited obese men with type 2 diabetes and chronic kidney disease. 57 The age of participants ranged from 25 to 89 years and, where reported, ethnicity was predominantly white. Only one study reported socioeconomic status using a validated tool; 63 the majority of other publications included a description of education or annual income.
Preferred Reporting Items for Systematic Reviews and Meta-Analyses flow diagram for the quantitative review.
Self-management support interventions
A total of 51 distinct self-management support interventions were reported across the 40 included male-only studies. Physical activity ( n = 16), 49 , 57 , 62 , 72 – 76 , 78 , 80 , 81 , 84 , 87 – 91 education ( n = 36), 46 – 55 , 58 – 61 , 63 – 67 , 70 – 72 , 77 , 79 – 81 , 83 – 88 peer support ( n = 17) 47 , 49 , 53 , 56 , 68 – 72 , 80 and HCP monitoring and feedback ( n = 25) 46 , 47 , 50 – 52 , 56 , 57 , 60 , 61 , 66 – 68 , 70 , 71 , 75 , 76 , 78 – 80 , 82 – 89 were the most frequently reported components of these interventions. Three interventions with a psychological component, 64 , 77 two interventions containing a financial incentive component 82 , 83 and one study containing an action plan component 19 were also identified.
Twenty-three of the interventions were aimed at individuals, 46 , 48 , 50 – 52 , 54 , 55 , 60 , 61 , 64 , 65 , 67 – 69 , 75 – 78 , 82 – 86 20 were aimed at groups 47 , 53 , 58 , 59 , 62 , 66 , 70 , 71 , 79 , 89 – 91 and the remainder used a mixed individual and group approach ( n = 6). 49 , 56 , 72 – 74 , 80 , 81 , 87 , 88 It was unclear what approach was used in two studies. 57 , 63 Over half of the interventions lasted 0–5 months ( n = 28), 47 , 53 , 58 – 64 , 67 – 69 , 71 – 80 , 85 , 86 12 interventions ranged between 6 and 11 months, 46 , 52 , 54 – 57 , 66 , 70 , 84 , 90 , 91 six interventions were 12 months or longer 49 , 65 , 81 , 82 , 84 , 87 , 88 and in five cases the total programme duration was unclear. 48 , 83 , 89
The mode of administration of the interventions varied. They included telephone-based support ( n = 6), 60 , 61 , 65 , 67 face-to-face delivery ( n = 21), 47 , 53 – 55 , 58 , 59 , 62 – 64 , 66 , 68 – 70 , 77 , 83 , 89 – 91 remote unsupervised activities ( n = 2), 75 , 76 , 78 a combination of face-to-face delivery and remote unsupervised activities ( n = 20), 46 – 51 , 57 , 71 – 74 , 79 – 82 , 84 – 89 and a combination of face-to-face delivery and telephone support ( n = 2). 52 , 56
In terms of setting, interventions were reported to be home-based ( n = 11), 46 , 52 , 60 , 61 , 65 , 67 , 75 , 76 , 78 at a non-home location such as a dedicated gym, pharmacy, hospital clinic, work, university laboratory, coffee shop or other community-based venue ( n = 12), 53 – 55 , 62 – 64 , 68 – 70 , 77 , 85 , 86 , 90 a combination of home and non-home-based venue ( n = 14) 48 – 51 , 56 , 57 , 72 – 74 , 79 – 84 , 87 , 88 or not clearly reported in the publication ( n = 14). 47 , 58 , 59 , 66 , 71 , 89 , 91
Half of the studies 79 – 82 , 46 , 48 – 51 , 53 , 56 , 58 , 59 , 66 , 70 , 72 , 78 , 84 , 87 , 88 reported on some aspect of compliance with the self-management intervention and most participants were followed up for 6 months or less ( n = 24) following participation in the intervention.
Table 2 provides an overview of study details and Table 3 includes detailed descriptions of the self-management support intervention.
Male-only study characteristics
Male-only studies: self-management support intervention characteristics
- Quality assessment: risk of bias
Study quality was assessed using the Cochrane risk of bias tool, 92 which covers six key domains: sequence generation, allocation concealment, blinding performance, incomplete outcome data, selective outcome reporting and other sources of bias.
Studies were often poorly reported, making judgements of quality difficult. With the exception of selective outcome reporting, the most frequent rating for all domains was an unclear risk of bias. For the selective outcome-reporting domain, a low risk of bias was most frequently reported assignment. Table 4 describes the risk of bias allocation for each study by each domain. Figure 6 presents a summary of the male-only study quality assessment findings.
Male-only study Cochrane risk of bias findings
Summary of male-only study Cochrane risk of bias findings.
Included under terms of UK Non-commercial Government License .
- Cite this Page Galdas P, Darwin Z, Fell J, et al. A systematic review and metaethnography to identify how effective, cost-effective, accessible and acceptable self-management support interventions are for men with long-term conditions (SELF-MAN). Southampton (UK): NIHR Journals Library; 2015 Aug. (Health Services and Delivery Research, No. 3.34.) Chapter 2, Quantitative review methods.
- PDF version of this title (3.9M)
In this Page
Other titles in this collection.
- Health Services and Delivery Research
Recent Activity
- Quantitative review methods - A systematic review and metaethnography to identif... Quantitative review methods - A systematic review and metaethnography to identify how effective, cost-effective, accessible and acceptable self-management support interventions are for men with long-term conditions (SELF-MAN)
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
- Open access
- Published: 05 July 2024
Integrating virtual patients into undergraduate health professions curricula: a framework synthesis of stakeholders’ opinions based on a systematic literature review
- Joanna Fąferek 1 ,
- Pierre-Louis Cariou 2 ,
- Inga Hege 3 ,
- Anja Mayer 4 ,
- Luc Morin 2 ,
- Daloha Rodriguez-Molina 5 ,
- Bernardo Sousa-Pinto 6 &
- Andrzej A. Kononowicz 7
BMC Medical Education volume 24 , Article number: 727 ( 2024 ) Cite this article
Metrics details
Virtual patients (VPs) are widely used in health professions education. When they are well integrated into curricula, they are considered to be more effective than loosely coupled add-ons. However, it is unclear what constitutes their successful integration. The aim of this study was to identify and synthesise the themes found in the literature that stakeholders perceive as important for successful implementation of VPs in curricula.
We searched five databases from 2000 to September 25, 2023. We included qualitative, quantitative, mixed-methods and descriptive case studies that defined, identified, explored, or evaluated a set of factors that, in the perception of students, teachers, course directors and researchers, were crucial for VP implementation. We excluded effectiveness studies that did not consider implementation characteristics, and studies that focused on VP design factors. We included English-language full-text reports and excluded conference abstracts, short opinion papers and editorials. Synthesis of results was performed using the framework synthesis method with Kern’s six-step model as the initial framework. We appraised the quality of the studies using the QuADS tool.
Our search yielded a total of 4808 items, from which 21 studies met the inclusion criteria. We identified 14 themes that formed an integration framework. The themes were: goal in the curriculum; phase of the curriculum when to implement VPs; effective use of resources; VP alignment with curricular learning objectives; prioritisation of use; relation to other learning modalities; learning activities around VPs; time allocation; group setting; presence mode; VPs orientation for students and faculty; technical infrastructure; quality assurance, maintenance, and sustainability; assessment of VP learning outcomes and learning analytics. We investigated the occurrence of themes across studies to demonstrate the relevance of the framework. The quality of the studies did not influence the coverage of the themes.
Conclusions
The resulting framework can be used to structure plans and discussions around implementation of VPs in curricula. It has already been used to organise the curriculum implementation guidelines of a European project. We expect it will direct further research to deepen our knowledge on individual integration themes.
Peer Review reports
Introduction
Virtual patients (VPs) are defined as interactive computer simulations of real-life clinical scenarios for the purpose of health professions training, education, or assessment [ 1 ]. Several systematic reviews have demonstrated that learning using VPs is associated with educational gains when compared to no intervention and is non-inferior to traditional, non-computer-aided, educational methods [ 2 , 3 , 4 ]. This conclusion holds true across several health professions, including medicine [ 3 , 5 ], nursing [ 6 ] and pharmacy [ 7 ]. The strength of VPs in health professions education lies in fostering clinical reasoning [ 4 , 6 , 8 ] and related communication skills [ 5 , 7 , 9 ]. At the same time, the research syntheses report high heterogeneity of obtained results [ 2 , 4 ]. Despite suggestions in the literature that VPs that are well integrated into curricula are more effective than loosely coupled add-ons [ 5 , 10 , 11 ], there is no clarity on what constitutes successful integration. Consequently, the next important step in the research agenda around VPs is to investigate strategies for effectively implementing VPs into curricula [ 9 , 12 , 13 ].
In the context of healthcare innovation, implementation is the process of uptaking a new finding, policy or technology in the routine practice of health services [ 14 , 15 , 16 ]. In many organisations, innovations are rolled out intuitively, which at times ends in failure even though the new tool has previously shown good results in laboratory settings [ 17 ]. A large review of over 500 implementation studies showed that better-implemented health promotion programs yield 2–3 times larger mean effect sizes than poorly implemented ones [ 18 ]. Underestimation of the importance and difficulty of implementation processes is costly and may lead to unjustified attribution of failure to the new product, while the actual problem is inadequate methods for integration of the innovation into practice [ 15 ].
The need for research into different ways of integrating computer technology into medical schools was recognised by Friedman as early as 1994 [ 19 ]. However, studies of the factors and processes of technology implementation in medical curricula have long been scarce [ 12 ]. While the terminology varies across studies, we will use the terms introduction, integration, incorporation , and implementation of VPs into curricula interchangeably. Technology adoption is the decision to use a new technology in a curriculum, and we view it as the first phase of implementation. In an early guide to the integration of VPs into curricula, Huwendiek et al. recommended, based on their experience, the consideration of four aspects relevant to successful implementation: blending face-to-face learning with on-line VP sessions; designing collaborative learning around VPs; allowing students flexibility in deciding when/where/how to learn with VPs; and constructively aligning learning objectives with suitable VPs and matched assessment [ 20 ]. In a narrative review of VPs in medical curricula, Cendan and Lok identified a few practices which are recommended for the use of VPs in curricula: filling gaps in clinical experience with standardised and safe practice, replacing paper cases with interactive models showing variations in clinical presentations, and providing individualised feedback based on objective observation of student activities. These authors also highlighted cost as a significant barrier to the implementation process [ 21 ]. Ellaway and Davies proposed a theoretical construct based on Activity Theory to relate VPs to their use and to link to other educational interventions in curricula [ 22 ]. However, a systematic synthesis of the literature on the identified integration factors and steps relevant to VP implementation is lacking.
The context of this study was a European project called iCoViP (International Collection of Virtual Patients; https://icovip.eu ) , which involved project partners from France, Germany, Poland, Portugal, and Spain and succeeded in creating a collection of 200 open-access VPs available in 6 languages to support clinical reasoning education [ 23 ]. Such a collection would benefit from being accompanied by integration guidelines to inform potential users on how to implement the collection into their curricula. However, guidelines require frameworks to structure the recommendations. Existing integration frameworks are limited in scope for a specific group of health professions, were created mostly for evaluation rather than guidance, or are theoretical or opinion-based, without an empirical foundation [ 24 , 25 , 26 ].
Inspired by the methodological development of qualitative literature synthesis [ 27 ], we decided to build a mosaic of the available studies in order to identify and describe what stakeholders believe is important when planning the integration of VPs into health professions curricula. The curriculum stakeholders in our review included students, teachers, curriculum planners, and researchers in health professions education. We aimed to develop a framework that would configure existing research on curriculum implementations, structure future practice guidelines, and inform research agendas in order to strengthen the evidence behind the recommendations.
Therefore, the research aim of this study was to identify and synthesise themes across the literature that, in stakeholders’ opinions, are important for the successful implementation of VPs in health professions curricula.
This systematic review is reported in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) framework [ 28 ].
Eligibility criteria
We selected studies whose main objective was to define, identify, explore, or evaluate a set of factors that, in the view of the authors or study participants, contribute to the successful implementation of VPs in curricula. Table 1 summarises the inclusion and exclusion criteria.
The curricula in which VPs were included targeted undergraduate health professions students, such as human medicine, dentistry, nursing, or pharmacy programs. We were interested in the perspectives of all possible stakeholders engaged in planning or directly affected by undergraduate health professions curricula, such as students, teachers, curriculum planners, course directors, and health professions education researchers. We excluded postgraduate and continuing medical education curricula, faculty development courses not specifically designed to prepare a faculty to teach an undergraduate curriculum with VPs, courses for patients, as well as education at secondary school level and below. Also excluded were alternative and complementary medicine programs and programs in which students do not interact with human patients, such as veterinary medicine.
Similar to the previous systematic review [ 4 ], we excluded from the review VP simulations that required non-standard computer equipment (like virtual reality headsets) and those in which the VP was merely a static case vignette without interaction or the VP was simulated by a human (e.g., a teacher answering emails from students as a virtual patient). We included studies in which VPs were presented in the context of health professions curricula; we excluded studies in which VPs were used as extracurricular activities (e.g., one-time learning opportunities, such as conference workshops) or merely as part of laboratory experimentation.
We included all studies that presented original research, and we excluded editorials and opinion papers. Systematic reviews were included in the first stage so we could manually search for references in order to detect relevant studies that had potentially been omitted. We included studies that aimed to comprehensively identify or evaluate external contextual factors relevant for the integration of VPs into curricula or that examined activities around VPs and the organisational, curricular and accreditation context (the constructed and framed layers of activities in Ellaway & Davies’ model [ 22 ]). As the goal was to investigate integration strategies, we excluded VP design studies that looked into techniques for authoring VPs or researched technical or pedagogical mechanisms encoded in VPs that could not be easily altered (i.e., encoded layer of VP activities [ 22 ]). As we looked into studies that comprehensively investigated a set of integration factors that are important in the implementation process, we excluded studies that focus on program effectiveness (i.e., whether or not a VP integration worked) but do not describe in detail how the VPs were integrated into curricula or investigate what integration factors contributed to the implementation process. We also excluded studies that focused on a single integration factor as our goal was to explore the broad perspective of stakeholders’ opinions on what factors matter in integration of VPs into curricula.
We only included studies published in English as we aimed to qualitatively analyse the stakeholders’ opinions in depth and did not want to rely on translations. We chose the year 2000 as the starting point for inclusion. We recognise that VPs were used before this date but also acknowledge the significant shift in infrastructure from offline technologies to the current web-based platforms, user-friendly graphical web browsers, and broadband internet, all of which appeared around the turn of the millennium. Additionally, VP literature before 2000 was mainly focused on demonstrating technology rather than integrating these tools into curricula [ 12 , 19 ].
Information sources and search
We systematically searched the following five bibliographic databases: MEDLINE (via PubMed), EMBASE (via Elsevier), Educational Resource Information Center (ERIC) (via EBSCO), CINAHL Complete (via EBSCO), Web of Science (via Clarivate). The search strategies are presented in Supplementary Material S1 . We launched the first query on March 8, 2022, and the last update was carried out on September 25, 2023. The search results were imported into the Rayyan on-line software [ 29 ]. Duplicate items were removed. Each abstract was screened by at least two reviewers working independently. In the case of disagreement between reviewers, we included the abstract for full text analysis. Next, we downloaded the full text of the included abstracts, and pairs of reviewers analysed the content in order to determine whether they met the inclusion criteria. In the case of disagreement, a third reviewer was consulted to arbitrate the decision.
Data extraction and analysis
Reviewers working independently extracted relevant characteristics of the included studies to an online spreadsheet. We extracted such features as the country in which the study was conducted, the study approach, the data collection method, the year of implementation in the curriculum, the medical topic of the VPs, the type and number of participants, the number of included VPs, the type of VP software, and the provenance of the cases (e.g., self-developed, part of a commercial database or open access repository).
The qualitative synthesis followed the five steps of the framework synthesis method [ 27 , pp. 188–190]. In the familiarisation phase (step 1), the authors who were involved previously in the screening and data extraction process read the full text versions of the included studies to identify text segments containing opinions on how VPs should be implemented into curricula.
Next, after a working group discussion, we selected David Kern’s six-step curriculum development [ 30 ] for the pragmatic initial frame (step 2). Even though it is not a VP integration framework in itself, we regarded it as a “best fit” to configure a broad range of integration factors spanning the whole process of curriculum development. David Kern’s model is often used for curriculum design and reform and has also been applied in the design of e-learning curricula [ 31 ]. Through a series of asynchronous rounds of comments, on-line meetings and one face-to-face workshop that involved a group of stakeholders from the iCoViP project, we iteratively clustered the recommendations into the themes that emerged. Each theme was subsumed to one of Kern’s six-steps in the initial framework. Next, we formulated definitions of the themes.
In the indexing phase (step 3), two authors (JF and AK) systematically coded the results and discussion sections of all the included empirical studies, line-by-line, using the developed themes as a coding frame. Text segments grouped into individual themes were comparatively analysed for consistency and to identify individual topics within themes. Coding was performed using MaxQDA software for qualitative analysis (MaxQDA, version 22.5 [ 32 ]). Disagreements were discussed and resolved by consensus, leading to iterative refinements of the coding frame, clarifications of definitions, and re-coding until a final framework was established.
Subsequently, the studies were charted (step 4) into tables in order to compare their characteristics. Similar papers were clustered based on study design to facilitate closer comparisons. A quality appraisal of the included studies was then performed using a standardised tool. Finally, a visual representation of the framework was designed and discussed among the research team, allowing for critical reflection on the consistency of the themes.
In the concluding step (step 5), in order to ensure the completeness and representativeness of the framework for the analysed body of literature, we mapped the themes from the developed framework to the studies in which they were found, and we analysed how individual themes corresponded to the conceptual and implementation evaluation models identified during the review. We looked for patterns and attempted to interpret them. We also looked for inconsistencies and tensions in the studies to identify potential areas for future research.
Quality appraisal of the included studies
To appraise the quality of the included studies, we selected the QuADS (Quality Assessment with Diverse Studies) tool [ 33 ], which is suitable for assessing the quality of studies with diverse designs, including mixed- or multi-method studies. This tool consists of 13 items on a four-point scale (0: not reported; 1: reported but inadequate; 2: reported and partially adequate; 3: sufficiently reported). QuADS has previously been successfully used in synthesis of studies in the field of health professions education [ 34 ] and technology-enhanced learning environments [ 35 ]. The included qualitative studies, quantitative surveys, and mixed-methods interview studies were independently assessed by two reviewers (JF, AK). The results were then compared; if differences arose, the justifications were discussed and a final judgement was reached by consensus. Following the approach taken by Goagoses et al. [ 35 ], we divided the studies into three groups, depending on the summary quality score: weak (≤ 49% of QuADS points); medium (50–69%) and high (≥ 70%) study quality.
Characteristics of the included studies
The selection process for the included studies is presented in Fig. 1 .
PRISMA flowchart of the study selection process
Our search returned a total of 4808 items. We excluded duplicate records ( n = 2201), abstracts not meeting the inclusion criteria ( n = 2526), and complete reports ( n = 59) after full text analysis. In the end, 21 studies met our inclusion criteria.
Types of included studies
In the analysis of the 21 included studies, 18 were classified as empirical studies, while three studies were identified as theoretical or evaluation models.
The purpose of the 18 empirical studies was to survey or directly observe the reaction of stakeholders to curriculum integration strategies in order to identify or describe the relevant factors (Table 2 ). Study types included qualitative ( n = 4) [ 11 , 36 , 37 , 38 ], mixed-methods ( n = 4) [ 39 , 40 , 41 , 42 ], quantitative survey ( n = 4) [ 10 , 43 , 44 , 45 ], and descriptive case studies ( n = 6) [ 46 , 47 , 48 , 49 , 50 , 51 ]. Data collection methods included questionnaires ( n = 9) [ 10 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 48 ], focus groups and small group interviews ( n = 8) [ 11 , 36 , 37 , 38 , 39 , 41 , 42 , 48 ], system log analyses ( n = 3) [ 44 , 47 , 48 ], direct observations ( n = 1) [ 44 ], or narrative descriptions of experiences with integration ( n = 5) [ 46 , 47 , 49 , 50 , 51 ]. The vast majority of studies reported experiences from integration of VPs into medical curricula ( n = 15). Two studies reported integration of VPs into nursing programs [ 40 , 51 ], one in a dentistry [ 40 ] and one in a pharmacy program [ 41 ]. One study was unspecific about the health professions program [ 46 ].
The remaining three of the included studies represented a more theoretical approach: one aimed to create a conceptual model [ 25 ]; the other two [ 24 , 26 ] presented evaluation models of the integration process (Table 3 ). We analysed them separately, considering their different structures, and we mapped the components of these models to our framework in the last stage of the framework synthesis.
Themes in the developed framework
The developed framework (Table 4 ), which we named the iCoViP Virtual Patient Curriculum Integration Framework (iCoViP Framework), contains 14 themes and 51 topic codes. The final version of the codebook used in the study can be found in Supplementary Material S2 . Below, we describe the individual themes.
General needs assessment
In the Goal theme, we coded perceptions regarding appropriate general uses of VPs in curricula. This covers the competencies to be trained using VPs, but also unique strengths and limitations of VPs as a learning method that should influence decisions regarding their adoption in curricula.
A common opinion was that VPs should target clinical reasoning skills and subskills such as acquisition/organisation of clinical information, development of illness scripts (sign, symptoms, risk factors, knowledge of disease progress over time), patient-centred care (including personal preferences and cultural competencies in patient interaction) [ 11 , 36 , 37 , 38 , 39 , 40 , 42 , 43 , 44 , 45 , 46 , 49 , 50 , 51 ]. According to these opinions, a strength of VPs is their potential for self-directed learning in an authentic, practice-relevant, safe environment that gives opportunities for reflection and “productive struggle” [ 37 , 39 , 49 ]. VPs also make it possible for students to practise decision-making in undifferentiated patient cases and observe the development of disease longitudinally [ 45 ]. For instance, some students valued the potential of VPs as a tool that integrates basic knowledge with clinical application in a memorable experience:
We associate a disease more to a patient than to the textbook. If I saw the patient, saw the photo and questioned the patient in the program, I will remember more easily, I’ll have my flashback of that pathology more than if I only studied my class notes or a book. {Medical student, 4th year, Columbia} [ 36 ].
Another perceived function of VPs is to help fill gaps in curricula and clinical experiences [ 36 , 37 , 38 , 42 , 45 , 50 ]. This supporting factor for the implementation of VPs in curricula is particularly strong when combined with the need to meet regulatory requirements [ 42 ].
Varying opinions were expressed regarding the aim of VPs to represent rare diseases (or common conditions but with unusual symptoms) [ 43 , 48 ] versus common clinical pictures [ 37 , 40 ]. Another tension arose when considering whether VPs should be used to introduce new factual/conceptual knowledge versus serving as a knowledge application and revision tool:
The students, however, differed from leaders and teachers in assuming that VPS should offer a reasonable load of factual knowledge with each patient. More as a surprise came the participants’ preference for usual presentations of common diseases. [ 40 ].
Limitations of VPs were voiced when the educational goal was related to physical contact and hands-on training because, in some aspects of communication skills, physical examination, or application of medical equipment, VPs clearly have inferior properties to real patients, human actors or physical mannequins [ 36 , 51 ].
Targeted needs assessment
The Phase theme described the moment in curricula when the introduction of VPs was regarded as adequate. According to some opinions, VPs should be introduced early in curricula to provide otherwise limited exposure to real patients [ 39 , 43 ]:
Students of the pre-clinical years show a high preference in the adoption of VPs as learning activities. That could be explained from the lack of any clinical contact with real patients in their two first years of study and their willingness to have early, even virtual, clinical encounters. [ 43 ].
The tendency to introduce VPs early in curricula was confronted with the problem of students’ limited core knowledge as they were required to use VPs before they had learnt about the features of the medical conditions they were supposed to recognise [ 41 , 48 ]. At the other end of the time axis, we did not encounter opinions that specified when it would be too late to use VPs in curricula. Even final-year students stated that they preferred to augment their clinical experience with VPs [ 43 ].
In the Resources theme, we gathered opinions regarding the cost and assets required for the integration of VPs into curricula. Cost can be a barrier that, if not addressed properly, can slow down or even stop an implementation, therefore it should be addressed early in the implementation process. This includes monetary funds [ 42 ] and availability of adequately qualified personnel [ 38 ] and their time [ 47 ].
For instance, it was found that if a faculty member is primarily focused on clinical work, their commitment to introducing innovation in VPs will be limited and will tend to revert to previous practices unless additional resources are provided to support the change [ 38 ].
The Resources theme also included strategies to follow when there is only a limited number of resources to implement VPs in a curriculum. Some suggested solutions included the sharing of VPs with other institutions [ 50 ], the exchange of know-how on the implementation of VPs with more experienced institutions and networks of excellence [ 38 , 42 ], and increasing faculties’ awareness of the benefits of using VPs, also in terms of reduced workload after the introduction of VPs in curricula [ 38 ]. Finally, another aspect of this theme was the (lack of) awareness of the cost of implementing VPs in curricula across stakeholder groups [ 40 ].
Goals and objectives
The Alignment theme grouped utterances highlighting the importance of selecting the correct VP content for curricula and matching VPs with several elements of curricula, such as learning objectives, the content of VPs across different learning forms, as well as the need to adapt VPs to local circumstances. The selection criteria included discussion regarding the number of VPs [ 36 ], fine-grained learning objectives that could be achieved using VPs [ 42 , 50 ], and selection of an appropriate difficulty level, which preferably should gradually increase [ 11 , 49 ].
It was noticed that VPs can be used to systematically cover a topic. For example, they can align with implementation of clinical reasoning themes in curricula [ 38 ] or map a range of diseases that are characteristic of a particular region of interest, thereby filling gaps in important clinical exposure and realistically representing the patient population [ 36 ].
Several approaches were mentioned regarding the alignment of VPs with curricula that include the selection of learning methods adjusted to the type of learning objectives [ 45 ], introduction of VPs in small portions in relevant places in curricula to avoid large-scale changes [ 38 ], alignment of VP content with assessment [ 39 ], and the visibility of this alignment by explicitly presenting the specific learning objectives addressed by VPs [ 49 ]. It is crucial to retain cohesion of educational content across a range of learning modalities:
I worked through a VP, and then I went to the oncology ward where I saw a patient with a similar disease. After that we discussed the disease. It was great that it was all so well coordinated and it added depth and some [sic!] much needed repetition to the case. {Medical student, 5th year, Germany} [ 11 ].
We also noted unresolved dilemmas, such as whether to present VPs in English as the modern lingua franca to support the internationalisation of studies, versus the need to adapt VPs to the local native language of learners in order to improve accessibility and perceived relevance [ 50 ].
Prioritisation
Several studies presented ideas for achieving higher Prioritisation of VPs in student agendas. The common but “heavy-handed” approach to increase motivation was to make completion of VPs a mandatory requirement to obtain course credits [ 36 , 48 , 51 ]. However, this approach was then often criticised for promoting superficial learning and lack of endorsement for self-directed learning [ 47 ]. Motivation was reported to increase when content was exam-relevant [ 11 ].
According to yet another mentioned strategy, motivation comes with greater engagement of teachers who intensively reference VPs in their classes and often give meaningful feedback regarding their use [ 40 ] or construct group activities around them [ 46 ]. It was suggested that VPs ought to have dedicated time for their use which should not compete with activities with obviously higher priorities, such as meeting real patients [ 37 ].
Another idea for motivation was adjustment of VPs to local needs, language and culture. It was indicated that it would be helpful to promote VPs’ authenticity by stressing the similarity of presented scenarios to problems clinicians encounter in clinical practice (e.g., using teacher testimonials [ 48 ]). Some students saw VPs as being more relevant when they are comprehensively described in course guides and syllabi [ 39 ]. The opinions about VPs that circulate among more-experienced students are also important:
Definitely if the year above kind of approves of something you definitely think you need it. {Medical student, 3rd year, UK} [ 39 ].
Peer opinion was also important for teachers, who were reported to be more likely to adopt VPs in their teaching if they have heard positive opinions from colleagues using them, know the authors of VP cases, or respect organisations that endorse the use of VP software [ 38 , 42 ]:
I was amazed because it was a project that seemed to have incredible scope, it was huge. I was impressed that there was the organization to really roll out and develop all these cases and have this national organization involved. {Clerkship director, USA} [ 42 ].
Educational strategies
The Relation theme contained opinions about the connections between VPs and other types of learning activities. This theme was divided into preferences regarding which types of activities should be replaced or extended by VPs, and the relative order in which they should appear in curricula. We noticed general warnings that VPs should not be added on top of existing activities as this is likely to cause work overload for students [ 10 , 45 ]. The related forms of education that came up in the discussions were expository methods like lectures and reading assignments (e.g., textbooks, websites), small group discussions in seminars (e.g., problem-based learning [PBL] sessions, follow-up seminars), alternative forms of simulations (e.g., simulated patients, human patient simulators), clinical teaching (i.e., meeting with real patients and bedside learning opportunities), and preparation for assessments.
Lectures were seen as a form of providing core knowledge that could later be applied in VPs:
Working through the VP before attending the lecture was not as useful to me as attending the lecture before doing the VP. I feel I was able to get more out of the VP when I first attended the lecture in which the substance and procedures were explained. {Medical student, 5th year, Germany} [ 11 ].
Textbooks were helpful as a source of reference knowledge while solving VPs that enabled students to reflect while applying this knowledge in clinical context. Such a learning scenario was regarded impossible in front of real patients:
But here it’s very positive right now when we really don’t know everything about rheumatic diseases, that we can sit with our books at the same time as we have a patient in front of us. {Medical student, 3rd year, Sweden} [ 37 ].
Seminars (small group discussions) were perceived as learning events that motivate students to work intensively with VPs and as an opportunity to ask questions about them [ 11 , 46 , 47 ], with the warning that teachers should not simply repeat the content of VPs as this would be boring [ 44 ]. The reported combination of VPs with simulated patients made it possible to increase the fidelity of the latter by means of realistic representation of clinical signs (e.g., cranial nerve palsies) [ 48 ]. It was noticed that VPs can connect different forms of simulation, “turn[ing] part-task training into whole-task training” [ 46 ], or allow more thorough and nuanced preparation for other forms of simulation (e.g., mannequin-based simulation) [ 46 ]. A common thread in the discussion was the relation between VPs and clinical teaching [ 10 , 11 , 37 , 39 , 45 , 46 ]. The opinions included warnings against spending too much time with VPs at the expense of bedside teaching [ 37 , 51 ]. The positive role of VPs was highlighted in preparing for clinical experience or as a follow-up to meeting real patients because working with VPs is not limited by time and is not influenced by emotions [ 37 ].
Huwendiek et al. [ 11 ] suggested a complete sequence of activities which has found confirmation in some other studies [ 48 ]: lectures, VP, seminars and, finally, real patients. However, we also identified alternative solutions, such as VPs that are discussed between lectures as springboards to introduce new concepts [ 49 ]. In addition, some studies concluded that students should have the right to decide which form of learning they prefer in order to achieve their learning objectives [ 38 , 48 ], but this conflicts with limited resources, a problem the students seem not to consider when expressing their preferences.
In the Activities theme, we grouped statements about tasks constructed by teachers around VPs. This includes teachers asking questions to probe whether students have understood the content of VPs, and guiding students in their work with VPs [ 11 , 49 ]. Students were also expected to ask their teachers questions to clarify content [ 43 ]. Some educators felt that students trained using VPs ask too many questions instead of relying more on their clinical reasoning skills and asking fewer, but more pertinent questions [ 38 ].
Students were asked to compare two or more VPs with similar symptoms to recognise key diagnostic features [ 11 ] and to reflect on cases, discuss their decisions, and summarise VPs to their peers or document them in a standardised form [ 11 , 46 , 49 , 51 ]. Another type of activity was working with textbooks while solving VP cases [ 37 ] or following a standard/institutional checklist [ 51 ]. Finally, some students expected more activities around VPs and felt left alone to struggle with learning with VPs [ 37 ].
Implementation
Another theme grouped stakeholders’ opinions regarding Time. A prominent topic was the time required for VP activities. Some statements provided the exact amount of time allocated to VP activities (e.g., one hour a week [ 51 ]), sometimes suggesting that it should be increased. There were several comments from students complaining about insufficient time allocated for VP activities:
There was also SO much information last week and with studying for discretionary IRATs constantly, I felt that I barely had enough time to synthesize the information and felt burdened by having a deadline for using the simulation. {Medical student, 2nd year, USA} [ 48 ].
Interestingly, the perceived lack of time was sometimes interpreted by researchers as a matter of students not assigning high enough priority to VP tasks because they do not consider them relevant [ 39 ].
Some students expected their teachers to help them with time management. Mechanisms for this included explicitly allocated time slots for work with VPs, declaration of the required time spent on working with VPs, and setting deadlines for task completion:
Without a time limit we can say: I’ll check the cases later, and then nothing happens; but if there’s a time limit, well, this week I see cardiac failure patients etc. It’s more practical for us and also for the teachers, I think. {Medical student, 4th year, Columbia} [ 36 ].
This expectation conflicts with the views that students should learn to self-regulate their activities, that setting a minimum amount of time that students should spend working with VPs will discourage them from doing more, and that deadlines cause an acute burst of activity shortly before them, but no activity otherwise [ 47 , 48 ].
Finally, it was interesting to notice that some educators and students perceived VPs as a more time-efficient way of collecting clinical experience than meeting real patients [ 37 , 38 ].
The Group theme included preferences for working alone or in a group. The identified comments revealed tensions between the benefits of working in groups, such as gaining new perspectives, higher motivation thanks to teamwork, peer support:
You get so much more from the situation when you discuss things with someone else, than if you would be working alone. {Medical student, 3rd year, Sweden} [ 37 ].
and the flexibility of working alone [ 43 , 44 , 46 , 49 ]. Some studies reported on their authors’ experiences in selection of group size [ 11 , 48 ]. It was also noted that smaller groups motivated more intensive work [ 41 , 44 ].
In the Presence theme, we coded preferences regarding whether students should work on VPs in a computer lab, a shared space, seminar rooms, or at home. Some opinions valued flexibility in selecting the place of work (provided a good internet connection is available) [ 11 , 36 ]. Students reported working from home in order to prepare well for work in a clinical setting:
... if you can work through a VP at home, you can check your knowledge about a certain topic by working through the relevant VP to see how you would do in a more realistic situation. {Medical student, 5th year, Germany} [ 11 ].
Some elements of courses related to simulated patient encounters had to be done during obligatory face-to-face training in a simulation lab (e.g., physical examination) that accompanied work with VPs [ 51 ]. Finally, it was observed that VPs offer sufficient flexibility to support different forms of blended learning scenarios [ 46 ]. Synchronous collaborative learning can be combined with asynchronous individual learning, which is particularly effective when there is a need for collaboration between geographically dispersed groups [ 46 ], for instance if a school has more than one campus.
Orientation
In the Orientation theme, we included all comments that relate to the need for teacher training, the content of teacher training courses, and the form of preparation of faculty members and students for using VPs. Knowledge and skills mentioned as useful for the faculty were awareness about how VPs fit into curricula [ 42 ], small-group facilitation skills, clinical experience [ 11 ], and experience with online learning [ 38 ]. Teachers expected to be informed about the advantages/disadvantages and evidence of effectiveness of VPs [ 38 ]. For students, the following prerequisites were identified: the ability to operate VP tools and experience with online learning in general, high proficiency of the language in which the VPs are presented and, for some scenarios (e.g., learning by design), also familiarity with VP methodology [ 38 , 47 , 48 , 50 , 51 ]. It was observed that introduction of VPs is more successful when both teachers and students are familiar with the basics of clinical reasoning theory and explicit teaching methods [ 38 ].
Forms of student orientation that were also identified regarding the use of VPs included demonstrations and introductions at the start of learning units [ 42 ], handouts and email reminders, publication of online schedules for assigned VPs, and expected time to complete them [ 11 , 48 ].
Infrastructure
The Infrastructure theme grouped stakeholders’ requirements regarding the technical environment in which VPs work. This included the following aspects: stable internet connection, secure login, usability of the user interface, robust software (well tested for errors and able to handle many simultaneous users), interoperability (e.g., support for the standardised exchange of VPs between universities) and access to an IT helpdesk [ 11 , 40 , 42 , 47 , 50 ]. It was noticed that technical glitches can have a profound influence on the perceived success of VP integration:
Our entire team had some technical difficulties, whether during the log-in process or during the patient interviews themselves and felt that our learning was somewhat compromised by this. {Medical student, 2nd year, USA} [ 48 ].
Evaluating the effectiveness
Sustainability & quality.
In the Sustainability & Quality theme, we indexed statements regarding the need to validate and update VP content, and its alignment with curricular goals and actual assessment to respond to changes in local conditions and regulatory requirements [ 45 ].
The need to add new cases to VP collections that are currently in use was mentioned [ 40 ]. This theme also included the requirement to evaluate students’ opinions on VPs using questionnaires, feedback sessions and observations [ 47 , 48 , 49 ]. Some of the stakeholders required evidence regarding the quality of VPs before they decided to adopt them [ 38 , 42 , 50 ]. Interestingly, it was suggested that awareness of the need for quality control of VPs varied between stakeholder groups, with low estimation of the importance of this factor among educational leaders:
Leaders also gave very low scores to both case validation and case exchange with other higher education institutions (the latter finding puts into perspective the current development of VPS interoperability standards). The leaders’ lack of interest in case validation may reflect a de facto conviction, that it is the ‘shell’ that validates the content. [ 40 ].
The Assessment theme encompasses a broad selection of topics related to various forms of using VPs in the assessment of educational outcomes related to VPs. This includes general comments on VPs as an assessment form, use of VPs in formative and summative assessment, as well as the use of learning analytics methods around VPs.
General topics identified in this theme included which learning objectives should be assessed with VPs, such as the ability to conduct medical diagnostic processes effectively [ 36 ], the authenticity of VPs as a form of examination [ 36 ], the use of VPs for self-directed assessment [ 11 , 39 , 43 , 46 ], and the emotions associated with assessment using VPs, e.g., reduced stress and a feeling of competitiveness [ 36 , 48 ].
Other topics discussed in the context of assessment included the pedagogical value of using VPs for assessments [ 36 ], such as the improved retention of information through reflection on diagnostic errors made with VPs [ 48 ], and VPs’ ability to illustrate the consequences of students’ errors [ 46 ]. Methods of providing feedback during learning with VPs were also described [ 11 ]. It was highlighted that data from assessments using VPs can aid teachers in planning future training [ 49 , 51 ]. Furthermore, it was observed that feedback from formative assessments with VPs motivates students to engage more deeply in their future learning [ 10 , 41 , 47 ]:
It definitely helped what we did wrong and what we should have caught, because there was a lot that I missed and I didn’t realize it until I got the feedback and in the feedback it also said where you would find it most of the time and why you would have looked there in the first place. {Pharmacy student, 4th year, Canada} [ 41 ].
In several papers [ 42 , 47 , 48 , 51 ], suggestions were made regarding the types of metrics that can be used to gauge students’ performance (e.g., time to complete tasks related to VPs, the accuracy of answers given in the context of VPs, recall and precision in selecting key features in the diagnostic process, the order of selecting diagnostic methods, and the quality of medical documentation prepared by students from VPs). The use of specific metrics and the risks associated with them were discussed. For instance, time spent on a task was sometimes seen as a metric of decision efficiency (a speed-based decision score) that should be minimised [ 48 ], or as an indicator of diligence in VP analysis that should be maximised [ 47 ]. Time measurements in on-line environments can be influenced by external factors like parallel learning using different methods (e.g. consulting a textbook) or interruptions unrelated to learning [ 47 ].
Finally, the analysed studies discussed summative aspects of assessment, including arguments regarding the validity of using VPs in assessments [ 51 ], the need to ensure alignment between VPs and examination content [ 49 ], and the importance of VP assessment in relation to other forms of assessment (e.g., whether it should be part of high-stakes examinations) [ 40 , 51 ]. The studies also explored forms of assessment that should be used to test students’ assimilation of content delivered through VPs [ 47 ], the challenges related to assessing clinical reasoning [ 38 ], and the risk of academic dishonesty in grading based on VP performance [ 48 ].
Mapping of the literature using the developed framework
We mapped the occurrence of the iCoViP Framework themes across the included empirical studies, as presented in Fig. 2 .
Code matrix of the occurrence of themes in the included empirical studies
Table 5 displays a pooled number of studies in which each theme occurred. The three most frequently covered themes were Prioritisation , Goal , and Alignment . These themes were present in approx. 90% of the analysed papers. Each theme from the framework appeared in at least four studies. The least-common themes, present in fewer than one-third of studies, were Phase , Presence , and Resources .
We mapped the iCoViP Framework to the three identified existing theoretical and evaluation models (Fig. 3 ).
Mapping of the existing integration models to the iCoViP Framework
None of the compared models contained a category that could not be mapped to the themes from the iCoViP Framework. The model by Georg & Zary [ 25 ] covered the fewest themes from our framework, including only the common categories of Goal, Alignment, Activities and Assessment . The remaining two models by Huwendiek et al. [ 24 ] and Kleinheksel & Ritzhaupt [ 26 ] underpinned integration quality evaluation tools and covered the majority of themes (9 out of 14 each). There were three themes not covered by any of the models: Phase, Resources, and Presence .
Quality assessment of studies
The details of the quality appraisal of the empirical studies using the QuADS tool are presented in Supplementary Material S3 . The rated papers had medium (50–69%; [ 39 , 40 , 43 ]) to high quality (≥ 70%; [ 10 , 11 , 36 , 37 , 38 , 41 , 42 , 44 , 45 ]). Owing to the difficulty in identifying the study design elements in the included descriptive case studies [ 46 , 47 , 48 , 49 , 50 , 51 ], we decided against assessing their methodological quality with the QuADS tool. This difficulty can also be interpreted as indicative of the low quality of the studies in this group.
The QuADS quality criterion that was most problematic in the reported studies was the inadequate involvement of stakeholders in study design. Most studies reported the involvement of students or teachers only in questionnaire pilots, but not in the conceptualisation of the research. Another issue was the lack of explicit referral to the theoretical frameworks upon which the studies were based. Finally, in many of the studies, participants were selected using convenience sampling, or the authors did not report purposeful selection of the study group.
We found high-quality studies in qualitative, quantitative, and mixed-methods research. There was no statistical correlation between study quality and the number of topics covered. For sensitivity analysis, we excluded all medium-quality and descriptive studies from the analysis; this did not reduce the number of iCoViP Framework topics covered by the remaining high-quality studies.
In our study, we synthesised the literature that describes stakeholders’ perceptions of the implementation of VPs in health professions curricula. We systematically analysed research reports from a mix of study designs that provided a broad perspective on the relevant factors. The main outcome of this study is the iCoViP Framework, which represents a mosaic of 14 themes encompassing many specific topics encountered by stakeholders when reflecting on VPs in health professions curricula. We examined the prevalence of the identified themes in the included studies to justify the relevance of the framework. Finally, we assessed the quality of the analysed studies.
Significance of the results
The significance of the developed framework lies in its ability to provide the health professions education community with a structure that can guide VP implementation efforts and serve as a scaffold for training and research in the field of integration of VPs in curricula. The developed framework was immediately applied in the structuring of the iCoViP Curriculum Implementation Guideline. This dynamic document, available on the website of the iCoViP project [ https://icovip.eu/knowledge-base ], presents the recommendations taken from the literature review and the project partners’ experiences with how to implement VPs, particularly the collection of 200 VPs developed during the iCoViP project [ 23 ]. To improve the accessibility of this guideline, we have added a glossary with definitions of important terms. We have already been using the framework to structure faculty development courses on the topic of teaching with VPs.
It is clear from our study that the success of integrating VPs into curricula depends on the substantial effort that is required of stakeholders to make changes in the learning environment to enable VPs to work well in the context of local health professions education programs. The wealth of themes discussed in the literature around VPs confirms what is known from implementation science: the quality of the implementation is as important as the quality of the product [ 15 ]. This might be disappointing for those who hope VPs are a turnkey solution that can be easily purchased to save time, under the misconception that implementation will occur effortlessly.
Our review also makes it evident that implementation of VPs is a team endeavour. Without understanding, acceptance and mutual support at all levels of the institutional hierarchy and a broad professional background, different aspects of the integration of VPs into curricula will not match. Students should not be left to their own devices when using VPs. They need to understand the relevance of the learning method used in a given curriculum by observing teachers’ engagement in the routine use of VPs, and they should properly understand the relationship between VPs and student assessment. Despite the IT-savviness of many students, they should be shown how and when to use VPs, while also allowing room for creative, self-directed learning. Finally, students should not get the impression that their use of VPs comes at the expense of something they give higher priority, such as direct patient contact or teacher feedback. Teachers facilitating learning with VPs should be convinced of their utility and effectiveness, and they need to know how to use VPs by themselves before recommending them to students. It is important that teachers are aware that VPs, like any other teaching resources, require quality control linked with perpetual updates. They should feel supported by more-experienced colleagues and an IT helpdesk if methodological or technical issues arise. Last but not least, curriculum managers should recognise the benefits and limitations of VPs, how they align with institutional goals, and that their adoption requires both time and financial resources for sustainment. All of this entails communication, coordinated efforts, and shared decision-making during the implementation of VPs in curricula.
Implications for the field
Per Nilsen has divided implementation theories, models and frameworks into three broad categories: process models, determinant frameworks and evaluation models [ 16 ]. We view the iCoViP Framework primarily as a process model. This perspective originates from the initial framework we adopted in our systematic review, namely Kern’s 6-steps curriculum development process [ 30 ], which facilitates the grouping of curricula integration factors into discrete steps and suggests a specific order in which to address implementation tasks. Our intention in using this framework was also to structure how-to guidelines, which are another hallmark of process models. As already noted by Nilsen and as is evident in Kern’s model, implementation process models are rarely applied linearly in practice and require a pragmatic transition between steps, depending on the situation.
The boundary between the classes of implementation models is blurred [ 16 ] and there is significant overlap. It is therefore not surprising that the iCoViP framework can be interpreted through the lens of a determinant framework which configures many factors (facilitators and barriers) that influence VP implementation in curricula. Nilsen’s category of determinant frameworks includes the CFIR framework [ 52 ], which was also chosen by Kassianos et al. to structure their study included in this review [ 38 ]. A comparison of the themes emerging from their study and our framework indicates a high degree of agreement (as depicted in Fig. 2 ). We interpret this as a positive indication of research convergence. Our framework extends this research by introducing numerous fine-grained topic codes that are characteristic of VP integration into curricula.
The aim of our research was not to develop an evaluation framework. For this purpose, the two evaluation tools available in the literature by Huwendiek et al. [ 24 ] and Kleinheksel & Ritzhaupt [ 26 ] are suitable. However, the factors proposed in our framework can further inform and potentially extend existing or new tools for assessing VP integration.
Despite the plethora of available implementation science theories and models [ 16 ], their application in health professions curricula is limited [ 15 ]. The studies included in the systematic review only occasionally reference implementation sciences theories directly (exceptions are CFIR and UTAUT [ 38 ], Rogers’ Diffusion of Innovation Theory [ 26 , 42 ] and Surry’s RIPPLES model [ 42 ]). However, it is important to acknowledge that implementation science is itself an emerging field that is gradually gaining recognition. Furthermore, as noticed by Dubrowski & Dubrowski [ 17 ], the direct application of general implementation science models does not guarantee success and requires verification and adaptation.
Limitations and strengths
This study is based on stakeholders’ perceptions of the integration of VPs into curricula. The strength of the evidence behind the recommendations expressed in the analysed studies is low from a positivist perspective as it is based on subjective opinions. However, by adopting a more interpretivist stance in this review, our goal is not to offer absolute, ready-to-copy recommendations. Instead, we aim to provide a framework that organises the implementation themes identified in the literature into accessible steps. It is beyond the scope of this review to supply an inventory of experimental evidence for the validity of the recommendations in each topic, as was intended in previous systematic reviews [ 4 ]. We recognise that, for some themes, it will always be challenging to achieve a higher level of evidence due to practical constraints in organising studies that experiment with different types of curricula. The complexity, peculiarities, and context-dependency of implementation likely preclude one-size-fits-all recommendations for VP integration. Nevertheless, even in such a situation, a framework for sorting through past experiences with integration of VPs proves valuable for constructing individual solutions that fit a particular context.
The aim of our study was to cover experiences from different health professions programs in the literature synthesis. However, with a few exceptions, the results show a dominance of medical programs in research on VP implementation in curricula. This, although beyond the authors’ control, limits the applicability of our review findings. The data clearly indicates a need for more research into the integration of VPs into health professions curricula other than medicine.
The decision to exclude single-factor studies from the framework synthesis is justified by our aim to provide a comprehensive overview of the integration process. Nevertheless, recommendations from identified single-factor studies [ 53 , 54 , 55 ] were subsequently incorporated into the individual themes in the iCoViP project implementation guideline. We did not encounter any studies on single factors that failed to align with any of the identified themes within the framework. Due to practical reasons concerning the review’s feasibility, we did not analyse studies in languages other than English and did not explore non-peer-reviewed grey literature databases. However, we recognise the potential of undertaking such activities in preparing future editions of the iCoViP guideline as we envisage this resource as an evolving document.
We acknowledge that our systematic review was shaped by the European iCoViP project [ 23 ]. However, we did not confine our study to just a single VP model, thereby encompassing a broad range of technical implementations. The strength of this framework synthesis lies in the diversity of its contributors affiliated with several European universities in different countries, who were at different stages of their careers, and had experience with various VP systems.
Further research
The iCoViP framework, by charting a map of themes around VP integration in health professions curricula, provides a foundation for further, more focused research on individual themes. The less-common themes or conflicts and inconsistencies in recommendations found in the literature synthesis may be a promising starting point.
An example of this is the phase of the curriculum into which a given VP fits. We see that proponents of early and late introduction of VPs use different arguments. The recommendation that VPs should be of increasing difficulty seems to be valid, but what is missing is the detail of what this means in practice. We envisage that this will be researched by exploring models of integration that cater for different levels of student expertise.
There are also varying opinions between those who see VPs as tools for presenting rare, intriguing cases, and those who see the commonality and practice relevance of the clinical problems presented in VPs as the most important factor. However, these opposing stances can be harmonised by developing a methodology to establish a well-balanced case-mix of VPs with different properties depending upon the needs of the learners and curricular context. Another point of division is the recognition of VPs as a tool for internationalising studies and supporting student mobility, versus the expectation that VPs should be adapted to local circumstances. These disparate beliefs can be reconciled by research into the design of activities around VPs that explicitly addresses the different expectations and confirm or refute their usefulness.
A significant barrier to the adoption of VPs is cost. While universities are occasionally willing to make a one-off investment in VPs for prestige or research purposes, the field needs more sustainable models. These should be suitable for different regions of the world and demonstrate how VPs can be maintained at a high level of quality in the face of limited time and resources. This is particularly important in low-resource countries and those affected by crises (e.g., war, natural disasters, pandemics), where the need for VPs is even greater than in developed countries due to the shortage of health professionals involved in teaching [ 56 ]. However, most of the studies included in our systematic review are from high-income countries. This shows a clear need for more research into the implementation of VPs in health professions curricula in developing countries.
Finally, an interesting area for future research is the interplay of different types of simulation modalities in curricula. The studies we reviewed do not recommend one type of simulation over another as each method has its unique advantages. In line with previous suggestions [ 46 ], we see a need for further research into practical implementation methods of such integrated simulation scenarios in curricula.
Stakeholders’ perceptions were structured into 14 themes by this framework synthesis of mixed methods studies on the curricular integration of VPs. We envision that teachers, course directors and curriculum designers will benefit from this framework when they decide to introduce VPs in their teaching. We anticipate that our summary will inspire health professions education researchers to conduct new studies that will deepen our understanding of how to effectively and efficiently implement VPs in curricula. Last but not least, we hope that our research will empower students to express their expectations regarding how they would like to learn with VPs in curricula, thus helping them to become better health professionals in the future.
Data availability
All datasets produced and analysed during the current study are available from the corresponding author upon reasonable request.
Abbreviations
- Virtual patients
International Collection of Virtual Patients
Quality Assessment with Diverse Studies
Liaison Committee on Medical Education (LCME) accreditation standard
Computer-assisted Learning in Paediatrics Program
Problem-Based Learning
Ellaway R, Poulton T, Fors U, McGee JB, Albright S. Building a virtual patient commons. Med Teach. 2008;30:170–4.
Article Google Scholar
Cook DA, Erwin PJ, Triola MM. Computerized virtual patients in Health professions Education: a systematic review and Meta-analysis. Acad Med. 2010;85:1589–602.
Consorti F, Mancuso R, Nocioni M, Piccolo A. Efficacy of virtual patients in medical education: a meta-analysis of randomized studies. Comput Educ. 2012;59:1001–8.
Kononowicz AA, Woodham LA, Edelbring S, Stathakarou N, Davies D, Saxena N, et al. Virtual Patient Simulations in Health Professions Education: systematic review and Meta-analysis by the Digital Health Education Collaboration. J Med Internet Res. 2019;21:e14676.
Lee J, Kim H, Kim KH, Jung D, Jowsey T, Webster CS. Effective virtual patient simulators for medical communication training: a systematic review. Med Educ. 2020;54:786–95.
Foronda CL, Fernandez-Burgos M, Nadeau C, Kelley CN, Henry MN. Virtual Simulation in nursing education: a systematic review spanning 1996 to 2018. Simul Healthc J Soc Simul Healthc. 2020;15:46–54.
Richardson CL, White S, Chapman S. Virtual patient technology to educate pharmacists and pharmacy students on patient communication: a systematic review. BMJ Simul Technol Enhanc Learn. 2020;6:332–8.
Plackett R, Kassianos AP, Mylan S, Kambouri M, Raine R, Sheringham J. The effectiveness of using virtual patient educational tools to improve medical students’ clinical reasoning skills: a systematic review. BMC Med Educ. 2022;22:365.
Kelly S, Smyth E, Murphy P, Pawlikowska T. A scoping review: virtual patients for communication skills in medical undergraduates. BMC Med Educ. 2022;22:429.
Berman N, Fall LH, Smith S, Levine DA, Maloney CG, Potts M, et al. Integration strategies for using virtual patients in clinical clerkships. Acad Med. 2009;84:942–9.
Huwendiek S, Duncker C, Reichert F, De Leng BA, Dolmans D, Van Der Vleuten CPM, et al. Learner preferences regarding integrating, sequencing and aligning virtual patients with other activities in the undergraduate medical curriculum: a focus group study. Med Teach. 2013;35:920–9.
Cook DA. The Research we still are not doing: an agenda for the study of computer-based learning. Acad Med. 2005;80:541–8.
Berman NB, Fall LH, Maloney CG, Levine DA. Computer-assisted instruction in Clinical Education: a Roadmap to increasing CAI implementation. Adv Health Sci Educ. 2008;13:373–83.
Eccles MP, Mittman BS. Welcome to implementation science. Implement Sci. 2006;1:1, 1748-5908-1–1.
Dubrowski R, Barwick M, Dubrowski A. I wish I knew this Before… an implementation science primer and model to Guide Implementation of Simulation Programs in Medical Education. In: Safir O, Sonnadara R, Mironova P, Rambani R, editors. Boot Camp Approach to Surgical Training. Cham: Springer International Publishing; 2018. pp. 103–21.
Chapter Google Scholar
Nilsen P. Making sense of implementation theories, models and frameworks. Implement Sci. 2015;10:53.
Dubrowski R, Dubrowski A. Why should implementation science matter in simulation-based health professions education? Cureus. 2018. https://doi.org/10.7759/cureus.3754 .
Google Scholar
Durlak JA, DuPre EP. Implementation matters: a review of research on the influence of implementation on program outcomes and the factors affecting implementation. Am J Community Psychol. 2008;41:327–50.
Friedman C. The research we should be doing. Acad Med. 1994;69:455–7.
Huwendiek S, Muntau AC, Maier EM, Tönshoff B, Sostmann K. E-Learning in Der Medizinischen Ausbildung: Leitfaden Zum Erfolgreichen Einsatz in Der Pädiatrie. Monatsschr Kinderheilkd. 2008;156:458–63.
Cendan J, Lok B. The use of virtual patients in medical school curricula. Adv Physiol Educ. 2012;36:48–53.
Ellaway RH, Davies D. Design for learning: deconstructing virtual patient activities. Med Teach. 2011;33:303–10.
Mayer A, Da Silva Domingues V, Hege I, Kononowicz AA, Larrosa M, Martínez-Jarreta B, et al. Planning a Collection of virtual patients to train clinical reasoning: a blueprint representative of the European Population. Int J Environ Res Public Health. 2022;19:6175.
Huwendiek S, Haider HR, Tönshoff B, Leng BD. Evaluation of curricular integration of virtual patients: development of a student questionnaire and a reviewer checklist within the electronic virtual patient (eVIP) project. Bio-Algorithms Med-Syst. 2009;5:35–44.
Georg C, Zary N. Web-based virtual patients in nursing education: development and validation of theory-anchored design and activity models. J Med Internet Res. 2014;16:e105.
Kleinheksel AJ, Ritzhaupt AD. Measuring the adoption and integration of virtual patient simulations in nursing education: an exploratory factor analysis. Comput Educ. 2017;108:11–29.
Gough D, Oliver S, Thomas J. An introduction to systematic reviews. SAGE; 2017.
Moher D, Liberati A, Tetzlaff J, Altman DG, for the PRISMA Group. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. BMJ. 2009;339(jul21 1):b2535–2535.
Ouzzani M, Hammady H, Fedorowicz Z, Elmagarmid A. Rayyan—a web and mobile app for systematic reviews. Syst Rev. 2016;5:210.
Thomas PA, Kern DE, Hughes MT, Chen BY, editors. Curriculum development for medical education: a six-step approach. Third edition. Baltimore: Johns Hopkins University Press; 2016.
Chen BY, Kern DE, Kearns RM, Thomas PA, Hughes MT, Tackett S. From modules to MOOCs: application of the Six-Step Approach to Online Curriculum Development for Medical Education. Acad Med. 2019;94:678–85.
VERBI Software. MAXQDA 2022.5. Software. 2023. maxqda.com.
Harrison R, Jones B, Gardner P, Lawton R. Quality assessment with diverse studies (QuADS): an appraisal tool for methodological and reporting quality in systematic reviews of mixed- or multi-method studies. BMC Health Serv Res. 2021;21:144.
Opie JE, McLean SA, Vuong AT, Pickard H, McIntosh JE. Training of lived experience workforces: a Rapid Review of Content and outcomes. Adm Policy Ment Health Ment Health Serv Res. 2023;50:177–211.
Goagoses N, Suovuo T, Bgt, Winschiers-Theophilus H, Suero Montero C, Pope N, Rötkönen E, et al. A systematic review of social classroom climate in online and technology-enhanced learning environments in primary and secondary school. Educ Inf Technol. 2024;29:2009–42.
Botezatu M, Hult H, Fors UG. Virtual patient simulation: what do students make of it? A focus group study. BMC Med Educ. 2010;10:91.
Edelbring S, Dastmalchi M, Hult H, Lundberg IE, Dahlgren LO. Experiencing virtual patients in clinical learning: a phenomenological study. Adv Health Sci Educ. 2011;16:331–45.
Kassianos AP, Plackett R, Kambouri MA, Sheringham J. Educators’ perspectives of adopting virtual patient online learning tools to teach clinical reasoning in medical schools: a qualitative study. BMC Med Educ. 2023;23:424.
McCarthy D, O’Gorman C, Gormley G. Intersecting virtual patients and microbiology: fostering a culture of learning. Ulster Med J. 2015;84(3):173-8.
Botezatu M, Hult Hå, Kassaye Tessma M, Fors UGH. As time goes by: stakeholder opinions on the implementation and use of a virtual patient simulation system. Med Teach. 2010;32:e509–16.
Dahri K, MacNeil K, Chan F, Lamoureux E, Bakker M, Seto K, et al. Curriculum integration of virtual patients. Curr Pharm Teach Learn. 2019;11:1309–15.
Schifferdecker KE, Berman NB, Fall LH, Fischer MR. Adoption of computer-assisted learning in medical education: the educators’ perspective: adoption of computer-assisted learning in medical education. Med Educ. 2012;46:1063–73.
Dafli E, Fountoukidis I, Hatzisevastou-Loukidou C, D Bamidis P. Curricular integration of virtual patients: a unifying perspective of medical teachers and students. BMC Med Educ. 2019;19:416.
Edelbring S, Broström O, Henriksson P, Vassiliou D, Spaak J, Dahlgren LO, et al. Integrating virtual patients into courses: follow-up seminars and perceived benefit. Med Educ. 2012;46:417–25.
Lang VJ, Kogan J, Berman N, Torre D. The evolving role of online virtual patients in Internal Medicine Clerkship Education nationally. Acad Med. 2013;88:1713–8.
Ellaway R, Topps D, Lee S, Armson H. Virtual patient activity patterns for clinical learning. Clin Teach. 2015;12:267–71.
Hege I, Ropp V, Adler M, Radon K, Mäsch G, Lyon H, et al. Experiences with different integration strategies of case-based e-learning. Med Teach. 2007;29:791–7.
Hirumi A, Johnson T, Reyes RJ, Lok B, Johnsen K, Rivera-Gutierrez DJ, et al. Advancing virtual patient simulations through design research and interPLAY: part II—integration and field test. Educ Technol Res Dev. 2016;64:1301–35.
Kulasegaram K, Mylopoulos M, Tonin P, Bernstein S, Bryden P, Law M, et al. The alignment imperative in curriculum renewal. Med Teach. 2018;40:443–8.
Fors UGH, Muntean V, Botezatu M, Zary N. Cross-cultural use and development of virtual patients. Med Teach. 2009;31:732–8.
Kelley CG. Using a virtual patient in an Advanced Assessment Course. J Nurs Educ. 2015;54:228–31.
Damschroder LJ, Aron DC, Keith RE, Kirsh SR, Alexander JA, Lowery JC. Fostering implementation of health services research findings into practice: a consolidated framework for advancing implementation science. Implement Sci. 2009;4:50.
Zary N, Johnson G, Fors U. Web-based virtual patients in dentistry: factors influencing the use of cases in the Web‐SP system. Eur J Dent Educ. 2009;13:2–9.
Maier EM, Hege I, Muntau AC, Huber J, Fischer MR. What are effects of a spaced activation of virtual patients in a pediatric course? BMC Med Educ. 2013;13:45.
Johnson TR, Lyons R, Kopper R, Johnsen KJ, Lok BC, Cendan JC. Virtual patient simulations and optimal social learning context: a replication of an aptitude–treatment interaction effect. Med Teach. 2014;36:486–94.
Mayer A, Yaremko O, Shchudrova T, Korotun O, Dospil K, Hege I. Medical education in times of war: a mixed-methods needs analysis at Ukrainian medical schools. BMC Med Educ. 2023;23:804.
Download references
Acknowledgements
The authors would like to thank Zuzanna Oleniacz and Joanna Ożga for their contributions in abstract screening and data extraction, as well as all the participants who took part in the iCoViP project and the workshops.
The study has been partially funded by the ERASMUS + program, iCoViP project (International Collection of Virtual Patients) from European Union grant no. 2020-1-DE01-KA226-005754 and internal funds from Jagiellonian University Medical College (N41/DBS/001125).
Author information
Authors and affiliations.
Center for Innovative Medical Education, Jagiellonian University Medical College, Medyczna 7, Krakow, 30-688, Poland
Joanna Fąferek
Faculty of Medicine, Paris Saclay University, Le Kremlin-Bicetre, 94270, France
Pierre-Louis Cariou & Luc Morin
Paracelsus Medical University, Prof.-Ernst-Nathan-Str. 1, 90419, Nürnberg, Germany
Medical Education Sciences, University of Augsburg, 86159, Augsburg, Germany
Institute and Clinic for Occupational, Social and Environmental Medicine, LMU University Hospital, 80336, Munich, Germany
Daloha Rodriguez-Molina
Department of Community Medicine, Information and Health Decision Sciences, Faculty of Medicine, University of Porto, Porto, Portugal
Bernardo Sousa-Pinto
Department of Bioinformatics and Telemedicine, Jagiellonian University Medical College, Medyczna 7, Krakow, 30-688, Poland
Andrzej A. Kononowicz
You can also search for this author in PubMed Google Scholar
Contributions
JF and AK conceived the idea for the study. JF coordinated the research team activities. All authors contributed to the writing of the review protocol. AK designed the literature search strategies. All authors participated in screening and data extraction. JF retrieved and managed the abstracts and full-text articles. JF and AK performed qualitative analysis of the data and quality appraisal. AK, JF and IH designed the illustrations for this study. All authors interpreted the analysis and contributed to the discussion. JF and AK drafted the manuscript. PLC, IH, AM, LM, DRM, BSP read and critically commented on the manuscript. All authors gave final approval of the version submitted.
Corresponding authors
Correspondence to Joanna Fąferek or Andrzej A. Kononowicz .
Ethics declarations
Ethics approval and consent to participate.
Systematic review of literature - not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary material 2, supplementary material 3, supplementary material 4, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Fąferek, J., Cariou, PL., Hege, I. et al. Integrating virtual patients into undergraduate health professions curricula: a framework synthesis of stakeholders’ opinions based on a systematic literature review. BMC Med Educ 24 , 727 (2024). https://doi.org/10.1186/s12909-024-05719-1
Download citation
Received : 20 March 2024
Accepted : 27 June 2024
Published : 05 July 2024
DOI : https://doi.org/10.1186/s12909-024-05719-1
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Curriculum development
- Systematic review
- Framework synthesis
BMC Medical Education
ISSN: 1472-6920
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- Advanced Search
Investigating the behavioural intentions of museum visitors towards VR: : A systematic literature review
New citation alert added.
This alert has been successfully added and will be sent to:
You will be notified whenever a record that you have chosen has been cited.
To manage your alert preferences, click on the button below.
New Citation Alert!
Please log in to your account
Information & Contributors
Bibliometrics & citations, view options, recommendations, the empirical study of customer satisfaction and continued behavioural intention towards self-service banking: technology readiness as an antecedent.
Self-Service Banking (SSB) is one instance of the Self-Service Technologies (SSTs) in e-banking. This study examines consumer satisfaction and the long-term usage intention of SSB. In the proposed model, four dimensions of Technology Readiness (TR) (...
Using Personas to Model Museum Visitors
It is widely agreed that museums and other cultural heritage venues should provide visitors with personalised interaction and services such as personalised mobile guides, although currently most do not. Since museum visitors are typically first-time ...
Examining Consumers' Behavioral Intentions Towards Online Home Services Applications
On-demand home service application (HSA) is a technological advancement that has brought various day-to-day services to our doorstep with just a few clicks. By using consumer-perceived values (utilitarian, hedonic, and social), trust transfer theory, and ...
Information
Published in.
Elsevier Science Publishers B. V.
Netherlands
Publication History
Author tags.
- Behavioural intentions
- Museum visitors
- VR technology
- Review-article
Contributors
Other metrics, bibliometrics, article metrics.
- 0 Total Citations
- 0 Total Downloads
- Downloads (Last 12 months) 0
- Downloads (Last 6 weeks) 0
View options
Login options.
Check if you have access through your login credentials or your institution to get full access on this article.
Full Access
Share this publication link.
Copying failed.
Share on social media
Affiliations, export citations.
- Please download or close your previous search result export first before starting a new bulk export. Preview is not available. By clicking download, a status dialog will open to start the export process. The process may take a few minutes but once it finishes a file will be downloadable from your browser. You may continue to browse the DL while the export process is in progress. Download
- Download citation
- Copy citation
We are preparing your search results for download ...
We will inform you here when the file is ready.
Your file of search results citations is now ready.
Your search export query has expired. Please try again.
Comparative analysis of open-source federated learning frameworks - a literature-based survey and review
- Original Article
- Open access
- Published: 28 June 2024
Cite this article
You have full access to this open access article

- Pascal Riedel ORCID: orcid.org/0000-0001-9910-3867 1 , 3 ,
- Lukas Schick 2 ,
- Reinhold von Schwerin 1 ,
- Manfred Reichert 3 ,
- Daniel Schaudt 1 &
- Alexander Hafner 1
353 Accesses
Explore all metrics
While Federated Learning (FL) provides a privacy-preserving approach to analyze sensitive data without centralizing training data, the field lacks an detailed comparison of emerging open-source FL frameworks. Furthermore, there is currently no standardized, weighted evaluation scheme for a fair comparison of FL frameworks that would support the selection of a suitable FL framework. This study addresses these research gaps by conducting a comparative analysis of 15 individual open-source FL frameworks filtered by two selection criteria, using the literature review methodology proposed by Webster and Watson. These framework candidates are compared using a novel scoring schema with 15 qualitative and quantitative evaluation criteria, focusing on features, interoperability, and user friendliness. The evaluation results show that the FL framework Flower outperforms its peers with an overall score of 84.75%, while Fedlearner lags behind with a total score of 24.75%. The proposed comparison suite offers valuable initial guidance for practitioners and researchers in selecting an FL framework for the design and development of FL-driven systems. In addition, the FL framework comparison suite is designed to be adaptable and extendable accommodating the inclusion of new FL frameworks and evolving requirements.
Similar content being viewed by others

Artificial intelligence in higher education: the state of the field

Tailored gamification in education: A literature review and future agenda

Systematic Reviews in Educational Research: Methodology, Perspectives and Application
Avoid common mistakes on your manuscript.
1 Introduction
Federated Learning (FL) is a semi-distributed Machine Learning (ML) concept that has gained popularity in recent years, addressing data privacy concerns associated with centralized ML [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ]. For example, data-driven applications with sensitive data such as in healthcare [ 8 , 9 , 10 , 11 , 12 ], finance [ 13 , 14 ], personalized IoT devices [ 15 , 16 ] or public service [ 17 , 18 ] require a technical guarantee of data privacy, which can be achieved by the use of FL.
In FL, a predefined number of clients with sensitive training data and a coordinator server jointly train a global model, while the local training data remains on the original client and is isolated from other clients [ 1 , 19 ]. In the FL training process, the global model is created by the server with randomly initialized weights and distributed to the clients of the FL system [ 20 , 21 ]. The goal of a federated training process is the minimization of the following objective function:
where \(N\) is the number of clients, \(n_k\) the amount of sensitive training data on client \(k\) , \(n\) the total amount of training data on all clients and \(F_k(w)\) is the local loss function [ 1 , 22 , 23 ]. Each client trains an initial model obtained by the coordinator server with the client’s local training data [ 24 ]). The locally updated model weights are asynchronously sent back to the coordinator server, where an updated global model is computed using an aggregation strategy such as Federated Averaging (FedAvg) [ 1 , 7 , 20 , 25 , 26 , 27 ]. The new global model is distributed back to the clients for a new federated training round. The number of federated training rounds is set in advance on the server side and is a hyperparameter that can be tuned [ 1 , 5 , 28 , 29 ]. An overview of the FL architecture is introduced in Fig. 1 . Also, FL can reduce the complexity and cost of model training by allowing a model to be trained on multiple smaller datasets on different clients, rather than on a single large, centralized dataset that requires an exhaustive data collection process beforehand [ 30 , 31 , 32 ]. Although there are a several key challenges to solve in the FL domain, security features such as homomorphic encryption [ 33 , 34 ] and differential privacy [ 6 , 35 , 36 ] are already used to guarantee and improve data privacy and security in FL systems [ 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 ].

Basic FL architecture overview
The advent of FL has spurred the development of various FL frameworks aimed at facilitating the deployment of FL applications, offering standardized functionalities and enhanced usability. Despite the proliferation of these frameworks, the selection of an optimal FL framework for specific project requirements remains a non-trivial challenge for practitioners due to the diversity and complexity of the choices available. This situation is exacerbated by two notable deficiencies in the FL research literature: first, the absence of a methodologically rigorous, in-depth comparative analysis of the most relevant open-source FL frameworks; and second, the lack of a standardized, weighted scoring scheme for a systematic and objective evaluation of these frameworks.
To the best of our knowledge, this comparative study is the most thorough to date, assessing the widest array of open-source FL frameworks against the broadest spectrum of criteria. Consequently, this study endeavors to fill the aforementioned research gaps by providing a robust FL framework comparison suite that could serve as a research-based guide for practitioners navigating the selection of suitable FL frameworks for their projects.
This study provides a comprehensive and user targeted comparison of 15 open-source FL frameworks by performing a systematic literature review according to Webster and Watson [ 45 ]. In this way, relevant FL frameworks and comparison criteria are identified, which are the basis for the comperative analysis. A novel weighted scoring system is proposed for the evaluation of FL frameworks. The proposed comparison criteria and the scoring system in this study can be utilized by practitioners and researchers to determine whether a particular FL framework fulfills their needs. Thus, the major contributions of this study can be summarized as follows:
Proposing 15 comparison criteria for the evaluation of FL frameworks based on a methodological literature review.
Introducing a novel weighted scoring matrix for these comparison criteria.
Conducting an in-depth comparison of 15 relevant open-source FL Frameworks.
In addition, a Research Question (RQ) oriented approach is used in this study with the aim to answer the following three RQs:
RQ 1: Which relevant frameworks for FL exist and are open-source?
RQ 2: Which criteria enable a qualitative and quantitative comparison of FL frameworks?
RQ 3: Which FL framework offers the most added value to practitioners and researchers?
The RQs are addressed and answered in ascending order in Sect. 5.4 on page 16.
The remainder of this paper is organized as follows. Section 2 discusses relevant related work and shows how the main contribution of this paper differs from the others. Section 3 details the literature review methodology applied in this work. Section 4 briefly introduces inclusion criteria and the FL framework candidates. Section 5 presents and discusses the comparison criteria, the weighting schema and the scoring results from the conducted FL framework comparison analysis. Section 6 describes the limitations of this study and suggests future work. Finally, Sect. 7 draws the conclusions of this survey.
2 Related work
In recent years, several research papers have been published dealing with individual FL frameworks. Some developers published works detailing and highlighting their own FL frameworks. For instance, the developers of FedML [ 46 ], Sherpa.ai FL [ 47 ], IBM FL [ 48 ], OpenFL [ 49 ], FATE [ 50 ], Flower [ 51 ], FLUTE [ 52 ], FederatedScope [ 53 ], FedLab [ 54 ] and EasyFL [ 55 ] have all published white papers introducing the features of their released frameworks. These papers include a general introduction to FL, open FL challenges, and how their FL framework can address them, while [ 29 , 46 , 47 , 51 , 52 , 55 ] also provide small comparisons of a few existing FL frameworks. These comparisons were chosen subjectively and are biased, usually in favor of the FL framework developed by the author making the comparison, meaning a neutral, independent and holistic comparison is missing so far. In addition, there are research papers that address the current state of FL research, some of them using specific FL frameworks for technical implementation or evaluation purposes. For example, [ 5 ] showed a general and comprehensive overview of FL. They examined possible future research directions and challenges of FL, such as protection strategies against federated security attacks, and mentioned sources of federated bias. Moreover, they briefly introduced and described some popular FL frameworks, including FATE [ 56 ], PaddleFL [ 57 ], NVIDIA Clara (now a platform offering AI models for healthcare applications) [ 58 ], IBM FL [ 59 ], Flower [ 51 ] and FedLearner [ 60 ]. Another work [ 61 ] followed a similar approach as [ 5 ] and described central FL concepts such as the training process and FL algorithms in more detail before including a brief comparison overview of several FL frameworks. The authors of both works ( [ 5 ] and [ 61 ]) refrain from evaluating FL frameworks and drawing conclusions from their conducted comparison analyses. In contrast to the aforementioned works, [ 62 ] described an in-depth comparison of multiple FL frameworks (TFF [ 63 ], FATE [ 56 ], PySyft [ 64 ] PaddleFL [ 57 ], FL &DP [ 65 ]). Both qualitative (in the form of a table comparing features of the frameworks) and quantitative comparisons (in the form of experiments, measuring training time and accuracy for three classification problems) are performed. Based on their evaluations, [ 62 ] recommended PaddleFL for the industrial usage, citing its high test accuracy for model inference tasks and range of features ready for practical use. A similar qualitative and quantitative FL framework comparison is provided by [ 66 ]. Their comparison contained more FL framework candidates than in the comparison conducted by [ 62 ] (9 vs 5). Furthermore, [ 66 ] performed a larger set of benchmark experiments, in which different FL paradigms were considered. The qualitative comparison was of a similar scope as in [ 62 ], although some criteria were left out (e.g., supported data types and protocols) and others have been added (e.g., documentation availability and GPU Support). Although the authors did not make a recommendation for a particular FL framework, they described a general decision-making process that can be used to determine the most appropriate FL framework.
In contrast to previous works, where the selection of comparison criteria for FL frameworks was often arbitrary, our study introduces a methodologically rigorous approach for a comparative analysis of FL frameworks. Prior works did not incorporate weighted importance of criteria nor did they employ a scoring mechanism for a systematic evaluation of FL frameworks. In addition, there was a lack of comprehensiveness in the inclusion of available and pertinent open-source FL frameworks. Our work advances the field by encompassing a broader spectrum of framework candidates and employing a more integrative methodology for evaluating FL frameworks with a novel weighted scoring approach. Leveraging the structured literature review methodology by Webster and Watson, this comparative study identifies the most pertinent quantitative and qualitative criteria for FL framework users, ensuring a selection of comparison criteria that is both comprehensive and methodically sound, surpassing the scope of similar studies.
3 Research method
We applied the literature review methodology proposed by Webster and Watson [ 45 ] to address the RQs (see Sect. 1 on page 1). They introduced a systematic in-depth review schema for the identification and evaluation of relevant research literature. Webster and Watson’s literature review method was published in response to the lack of reviewing articles in the information systems field, which the authors believe has slowed the progress in the field [ 45 ]. Their methodology has gained popularity since publication, with over 10 000 citations (based on Google Scholar citation count). According to [ 45 ], the collection process of relevant research literature should be concept-oriented or author-centric and is not limited to individual journals or geographical regions. They recommend to identify appropriate journal articles and conference proceedings by conducting a keyword-based search in different literature databases. Additional relevant sources should be identified by searching the references of the literature collected in this manner. This technique is called backward search and can be combined with forward search , which locates literature that cites one of the originally identified documents as a literature source. An overview of the searching methodology applied in this paper is shown in Fig. 2 . We used the research literature review of Webster and Watson [ 45 ] to build the knowledge base for a literature-driven comparison analysis of open-source FL frameworks.

Process flow used in this study to identify and filter relevant publications for the literature review
3.1 Literature databases and search string
For the literature search, the publication databases ACM Digital Library, EBSCOhost and IEEE Xplore were used to identify relevant publications and literature sources (see Fig. 2 ). As recommended by [ 45 ] we mainly searched for peer-reviewed journal articles and conference proceedings, so that a reliable research is feasible. A logical combination of the following terms served as the search string:
‘federated learning’ AND ‘framework’ AND ‘open-source’ OR ‘federated framework’ AND ‘privacy-preserving machine learning’ AND ‘open-source’.
In some cases, additional search keywords were used, determined by reviewing the tables of contents of the retrieved literature based on the search string [ 45 ]. In addition, the research literature was filtered by publication date from 2016 to 2024 to obtain more recent sources. 2016 was chosen as date filter because that was the first year the term federated learning was officially used in a publication [ 1 ]. The forward and backward searches, as described by Webster and Watson [ 45 ], were used to identify additional relevant sources. This made it possible to identify publications that referenced other relevant publications, most of which were not much older than the origin publications. One reason for this could be that the term federated learning did not exist before 2016, so the range of publication dates is quite narrow. For the forward search, Google Scholar, Science Direct, Semantic Scholar, and ArXiv were used in addition to the literature databases mentioned above.
3.2 Inclusion and exclusion criteria
To further filter the identified publications, the following certain inclusion and exclusion criteria were used, defined as follows:
Inclusion Criteria :
The identified publication deals with the topic of federated learning and contributes answers to at least one of the RQs (see Sect. 1 on page 1).
The title and the abstract seem to contribute to the RQs and contain at least one of the following terms: framework, federated learning, machine learning, evaluation or open-source.
Exclusion Criteria :
The publication is not written in English.
The title and abstract do not appear to contribute to the RQs and do not contain a term from the search string (see Subsect. 3.1 ) or inclusion criteria.
The publication is a patent, master thesis, or a non-relevant web page.
The publication is not electronically accessible without payment (i.e. only print issue).
All relevant aspects of the publication are already included in another publication.
The publication only compares existing research and has no new input.
A publication is included in the pool of relevant literature for reviewing if both inclusion criteria are met, and it is excluded if any of the exclusion criteria is fulfilled. Exceptions that are not subject to these criteria are sources that additionally serve to quantitatively or qualitatively support the comparison, such as GitHub repositories or the websites from the FL frameworks. Such sources are also included in our literature database, having a low relevance score.
3.3 Pool of publications
We initially checked the titles and abstracts of the publications for the individual key words of the search term (see Subsect. 3.1 on page 4) and added the publications to the literature pool if there were any matches based on the defined inclusion and exclusion criteria (see Subsect. 3.2 on page 5). Thus, 1328 individual publications from the literature databases were obtained. With the introduction and conclusion, 1196 publications have been eliminated due to lack of relevance. As a result, 132 publications, including 60 peer-reviewed journal articles, 27 conference proceedings, 10 white papers and 35 online sources form the basis for the literature-driven comparative analysis. In the refinement process (see step 3 on Fig. 2 on page 4), duplicated sources were removed, since in some cases the same publication was listed in at least or more than two literature databases.
3.4 Literature review
For the literature review a concept-oriented matrix according to Webster and Watson was used, which enables a systematic relevance assessment of the identified literature [ 45 ]. A publication is rated according to the number of concepts covered. Based on the RQs (see Sect. 1 on page 1), the individual concepts or topics for the literature review in this study are defined as follows:
FL General Information (GI)
FL Security Mechanisms (SM)
FL Algorithms (AL)
FL Frameworks (FW)
For each identified source, the title, the type of publication, the name of the publishing journal or conference if applicable, the number of citations, and a brief summary of the relevant content were noted. Afterwards, the literature was scored based on a scale of 1 to 4, with a publication scored 4 representing high relevance and a publication scored 1 representing low relevance. The rating schema is based on the concepts described above and defined as follows:
1 Point: Relevant to one specific concept except for FW.
2 Points: Relevant to at least two concepts or FW.
3 Points: Relevant to at least three concepts or FW and one or two other concepts.
4 Points: Relevant to all four concepts (GI, SM, AL and FW).
Additional sources not directly related to the concepts defined above were included in the concept Misc. and have been automatically assigned a relevance score of 1. An excerpt of the applied concept-oriented tabular literature review according to Webster and Watson [ 45 ] can be found in Table 1 on page 7. In this study, the knowledge base obtained from the literature review forms the basis for the weighted comparison and evaluation of different open-source FL frameworks (see Sect. 5 on page 8).
3.5 Literature analysis
To analyze the research literature, a Latent Dirichlet Allocation (LDA) was applied on the identified publications to discover common overlapping topics [ 67 ]. This could be used to verify the relevance of our chosen Literature Review Concepts. Stop words, numerical characters and conjunctions have been filtered out in advance. The number of components of the LDA was set to 10. This number was chosen after conducting a grid search and analyzing the generated topics. With the number of components set to 10, a topic that could be assigned to the Literature Review Concept ‘FL Frameworks’ was included for the first time. Thus, this was the lowest number of topics with which all four of the identified Literature Review Concepts were captured by the LDA. In each topic, the LDA determined the 20 most relevant words from the provided literature. Relevance represents the amount of times a word was assigned to a given topic [ 67 ]. Figure 5 (see Appendix, on page 18) displays these identified topics and their most relevant words. The topics were further condensed into the previously defined four concepts in Table 2 . A word cloud consisting of the most common words in the identified literature can be seen in Fig. 6 (see Appendix, on page 19).
The literature-driven analysis reveals that FL frameworks have not often been part of research works on FL (see Table 2 ). This work aims to close this research gap. Figure 3 on page 6 shows the distribution of reviewed FL sources by the publication year. Noticeable is that FL received an overall boost in research interest in 2022 compared to 2021 (25 vs 14 publications). We expect the number of research publications on the four FL concepts described (see Subsect. 3.4 on page 5) to increase in the future as more user-friendly FL frameworks facilitate accessibility to FL to a wider range of users. It is worth to mention that some sources dealing with FL frameworks are GitHub repositories and white papers of the framework developers. In conducting the literature review (see Table 1 on page 7), a total of 18 FL frameworks were identified for the comparison and evaluation. To filter the number of FL frameworks, inclusion criteria are defined and used in this study. These filter criteria and the selected FL frameworks are described in the next section.

Histogram of reviewed literature by year of publication from 2016 (first FL publication) to February 2024 (current research)
4 Federated learning frameworks
Although the term FL was coined as early as in 2016 [ 1 ], it is only in recent years that more Python-based frameworks have emerged that attempt to provide FL in a more user-friendly and application-oriented manner (see Fig. 3 on page 6). Some of the identified FL frameworks are hidden behind paywalls or are completely outdated and no longer actively developed and supported, making it impractical to include them for a fair comparison. Therefore, the following two inclusion criteria must be fulfilled by the FL frameworks in order to be considered as comparison candidates.
4.1 Inclusion criteria
Open-Source Availability In this paper, we also want to contribute to the topic of open-source in AI solutions and affirm its importance in the research community. In times when more and more AI applications are offered behind obfuscated paywalls (e.g., OpenAI [ 68 ]), researchers and developers should also consider the numerous advantages when developing innovative AI solutions as open-source products. After all, the rapid development of AI has only been possible due to numerous previous relevant open-source works. Thus, for the comparison study only open-source FL frameworks are chosen.
A few enterprises, such as IBM [ 59 ] or Microsoft [ 69 ], offer both a commercial integration and a open-source version of their FL frameworks for research purposes. For such FL frameworks only the free versions are considered in our comparison analysis.
Commercial FL frameworks such as Sherpa.ai FL [ 47 , 65 ] are not considered in this work as they do not follow the spirit of open-source. Benchmarking frameworks such as LEAF [ 70 ] or FedScale [ 71 ] were also excluded.
Community Popularity Another inclusion criterion used for filtering FL frameworks is the popularity in the community. It can be assumed that FL frameworks with an active and large GitHub community are more actively developed, more likely to be supported in the long term and thus more beneficial for practitioners. Therefore, this criterion excludes smaller or experimental FL frameworks, such as OpenFed [ 72 ].
As a metric for community activity the number of GitHub Stars are used. FL frameworks that have received at least 200 GitHub Stars for their code repositories are considered. The GitHub Stars indicate how many GitHub users bookmarked the repository, which can be interpreted as a reflection of the popularity of a GitHub repository. In fact, only FL frameworks provided by a company or an academic institution are considered in this study.
4.2 Considered frameworks
To provide a first initial overview of the 15 filtered FL frameworks, a comparison of them is shown in Table 3 on page 9 based on the following metrics: the developer country of origin, GitHub stars, the number of Git releases, dates of the initial and lates releases. Notably, PySyft is the most popular FL framework with over 9000 GitHub stars, followed by FATE AI and FedML. In general, FL frameworks which were released earlier have a higher numbers of GitHub stars. PySyft and TFF have been updated the most, while FLUTE has not yet had an official release on GitHub. Apart from Flower, all other FL frameworks were developed either in China or in the USA. 200 was chosen as the critical value, as this produces a manageable number of FL frameworks with the greatest popularity. In addition, a clear break between the much and little observed frameworks can be seen in this value range, as only a few frameworks can be found between 500 and 200, before the number of repositories increases drastically below 200 stars.
5 Framework comparison and evaluation
This section starts with the introduction of the comparison criteria and the weighted scoring system in Subsec. 5.1 on page 8. Then, the comparison and evaluation of the 15 FL frameworks is performed and the results are presented in 5.2 on page 11. This section closes with a discussion and analysis of our findings in 5.3 on page 14.
5.1 Criteria and weighting definition
To ensure a detailed comparison, the FL frameworks are examined from three different perspectives, namely Features , Interoperability and User Friendliness using a weighted scoring system. All three main comparison categories each make up 100%. For each comparison category, this subsection describes individual comparison criteria and their weighting in descending order of relevance. The comparison criteria in each perspective category were selected based on the systematic literature review described in 3.4 on page 5.
Features This comparison category aims to examine and compare the inherent features of each FL framework. From the user’s point of view, it is mandatory to know the relevant features of an FL framework in order to select a suitable framework for an FL project. Typical FL framework features include the support of different FL Paradigms (horizontal, vertical, and federated transfer learning), Security Mechanisms (cryptographic and algorithm-based methods), different FL Algorithms and specific federated ML Models [ 33 , 34 , 95 , 96 , 97 , 98 , 99 , 100 , 101 ].
In terms of weighting, Security Mechanisms is weighted most heavily at 35%, because increased data privacy and security is the main motivation for using FL in most applications [ 102 ] and the inherent properties of FL do not guarantee complete security [ 34 , 103 , 104 , 105 , 106 ].
FL Algorithms and ML Models are given equal weighting at 25%, as both a wide range of algorithms and models are important to make an FL framework adaptable to different data-driven use cases [ 62 , 66 , 102 ].
The criterion FL Paradigms is weighted at 15%, because horizontal FL is still the most common FL paradigm [ 102 ], making the inclusion of other FL paradigms (i.e. vertical FL [ 107 ], and federated transfer learning [ 108 ]) less pertinent.
Interoperability
Interoperability is a mandatory factor in the evaluation of FL frameworks, particularly in terms of their compatibility with various software and hardware environments. This category includes support for multiple operating systems beyond the universally supported Linux containerization via Docker, CUDA support for leveraging GPUs, and the feasibility of deploying federated applications to physical edge devices [ 66 ].
The criterion Rollout To Edge Devices is weighted at 50%. This comparison criterion is crucial for the practical deployment of FL applications, enabling real-world applications rather than mere simulations confined to a single device [ 62 , 66 ]. Without this, the scope of FL frameworks would be significantly limited to theoretical or constrained environments.
Support for different Operating Systems is assigned a weight of 25%. This inclusivity ensures that a broader range of practitioners can engage with the FL framework, thereby expanding its potential user base and facilitating wider adoption across various platforms [ 62 ].
GPU Support is considered important due to the acceleration it can provide to model training processes, and is weighted at 15%. Although beneficial for computational efficiency, GPU support is not as critical as the other criteria for the core functionality of an FL framework [ 66 ].
Lastly, Docker Installation is recognized as a criterion with a 10% weight. Docker’s containerization technology offers a uniform and isolated environment for FL applications, mitigating setup complexities and compatibility issues across diverse computing infrastructures [ 109 ]. While Docker support enhances versatility and accessibility, it is deemed optional since there are FL frameworks available that may not necessitate containerization for running on other OSes. Although Docker’s containerization is a beneficial attribute for FL frameworks, it is not as heavily weighted as the capacity for edge device deployment or OS support, which are more essential for the practical implementation and broad usability of FL applications.
User Friendliness The aim of this comparison category is to examine and compare the simplicity and user-friendliness of the individual FL frameworks when creating FL applications. The simple use of an FL framework can shorten the development times in an FL project and thus save costs. Therefore, the following comparison criteria should be considered in this criteria group: Development Effort needed to create and run an FL session, federated Model Accuracy on unseen data, available online Documentation , FL Training Speed , Data Preparation Effort , Model Evaluation techniques and, if existing, the Pricing Systems for additional functionalities (e.g., online dashboards and model pipelines) [ 62 , 66 ].
The criteria Development Effort and Model Accuracy are deemed most critical, each carrying a 25% weight, due to their direct impact on the usability of FL frameworks and the effectiveness of the resultant FL applications [ 110 ]. The focus is on quantifying the ease with which developers can leverage the framework to create and deploy FL applications. This facet is critical as it directly influences the time-to-market and development costs of FL projects. Also for the FL application’s success it is important how well a federated model can perform on unseen new data [ 62 , 66 ].
The Documentation aspect is weighted with 20%. Given the novelty of many FL frameworks and the potential scarcity of coding examples, the availability and quality of documentation are evaluated [ 66 ]. This criterion underscores the importance of well-structured and informative documentation that can aid developers in effectively utilizing the FL framework, encompassing tutorials, API documentation, and example projects.
The Training Speed criteria is weighted lower with 10%, since a faster training time is advantageous for any FL framework, but is less relevant compared to a high model accuracy [ 62 , 66 ]. It reflects on the optimization and computational efficiency of the framework in processing FL tasks.
The Data Preparation Effort is assigned a weight of 10%. It evaluates the degree to which an FL framework supports data preprocessing and readiness, considering the ease with which data can be formatted, augmented, and made suitable for federated training. Although not critical for the operational use of an FL framework, streamlined data preparation processes can enhance developer productivity.
Model Evaluation receives the lowest weighting of 5%. It scrutinizes the methodologies and tools available within the FL framework for assessing global model performance and robustness, including validation techniques and metrics. Different model evaluation methods are helpful for practitioners, but not necessary for the effective use of an FL framework [ 66 ]. Thus, this criterion has more a supportive role in the broader context of FL application development.
Since the focus of this work is on open-source FL frameworks, the Pricing Systems is also only weighted at 5%. For FL frameworks that offer additional functionalities through paid versions, this evaluates the cost-benefit ratio of such features. While the core focus is on open-source frameworks, the assessment of pricing systems is still relevant for understanding the scalability and industrial applicability of the framework’s extended features.
To assess the scores for the Development Effort , Model Accuracy , Training Speed , Data Preparation Effort and Model Evaluation criteria, a federated test application has been created, simulating an FL setting while running on a single device. This application used the MNIST dataset [ 111 , 112 ] and performed an image multi-class classification task with a multi-layer perceptron neural network model. A grid search approach was used to identify an optimal hyperparameter configuration. The selected hyperparameters for the model trainings were used identically for testing each FL framework (see Table 4 on page 11).
Weighted Scoring In each of the three comparison categories mentioned above, the criteria are assigned weights that sum up to 100%. Consequently, the total score for all comparison criteria within a category represents the percentage score obtained by an evaluated FL framework in that particular category. These percentage scores for each category are then combined using a weighted sum to derive an overall total score. This serves as a final metric for selecting the best FL framework across all categories. All criterion weights are also listed in Table 7 on page 20 in the Appendix.
The distribution of the weighting of the three top level categories is as follows:
User Friendliness has the highest weighting ( 50% ), as the criteria in this category have the greatest impact for practitioners working with FL frameworks.
Features has the second highest weighting ( 30% ), as this category indicates which functionalities such as Security Mechanisms or FL Paradigms are supported in an FL framework.
Interoperability is weighted as the lowest ( 20% ), as it primarily indicates the installation possibilities of an FL framework, but does not represent core functionalities or the framework’s usability.
The FL frameworks can achieve one of three possible scores in each criterion: a score of zero is awarded if the FL framework does not fulfill the requirements of the criterion at all. A half score is awarded if the FL framework partially meets the requirements. A score of one is awarded if the FL framework fully meets the requirements. If a criterion cannot be verified or tested at all, then it is marked with N.A. (Not Available). This is treated as a score of zero in this criterion when calculating the total score. The detailed scoring schemes for each criterion are given in Table 7 on page 20 in the Appendix.
5.2 Comparison results
The scoring Table 5 on page 12 shows the comparison matrix of the 15 FL framework candidates on the basis of the defined categories and criteria from Subsect. 5.1 on page 8. In the following, we explain our assessment of the individual comparison criteria for the FL frameworks. Note: we write the individual comparison criteria in capital letters to highlight them.
Evaluation of Features It can be noted that for the first criterion, Security Mechanisms , five FL frameworks (PySyft, PaddleFL, FLARE, FLSim and FederatedScope) provide both cryptographic and algorithmic security features such as differential privacy, secure aggregation strategies, secure multiparty computation, trusted execution environments and homomorphic encryption [ 6 , 34 , 35 , 53 , 108 , 113 , 114 , 115 , 116 , 117 , 118 , 119 , 120 , 121 , 122 ]. Therefore, these FL frameworks receive the full score for this criterion. On the other hand, FATE AI, FedML, TFF, Flower, FedLearner, OpenFL, IBM FL and FLUTE all provide only one type of security mechanism. Thus, these FL frameworks receive half the score [ 48 , 49 , 50 , 52 , 57 , 63 , 64 , 66 , 78 , 86 , 87 , 123 ]. FedLab and EasyFL provide no security mechanisms and receive a score of zero in this criterion [ 54 , 55 , 92 ].
For the next criterion, FL Algorithms , the FL frameworks: FedML, TFF, Flower, OpenFL, IBM FL, FLARE, FLUTE, FederatedScope and FedLab receive full scores, because they provide out-of-the-box implementations of the FedAvg [ 1 ] algorithm as well as several different adaptive FL algorithms such as FedProx, FedOpt and FedAdam [ 124 , 125 ]. On the other hand, FATE AI, FedLearner, PaddleFL, FLSim and EasyFL only provide FedAvg as an aggregation strategy; other algorithms are not available in these FL frameworks by default, resulting in a halving of the score on this criterion. PySyft is the only FL framework candidate that requires manual implementation of an FL strategy (even for FedAvg). Therefore, PySyft receives a zero score on this criterion as it requires more effort to set up a training process [ 46 , 51 , 52 , 57 , 60 , 62 , 63 , 73 , 81 , 83 , 86 , 87 , 89 , 92 , 93 ].
For building ML Models , PySyft, FATE AI, FedML, Flower, OpenFL, IBM FL, FLARE and FederatedScope support the deep learning libraries Tensorflow and PyTorch. They provide users with a wide range of federatable ML models. Therefore, these FL frameworks are awarded the full marks on this criterion. However, TFF (Tensorflow), FedLearner (Tensorflow), PaddleFL (PaddlePaddle), FLSim (PyTorch), FLUTE (PyTorch), FedLab (PyTorch) and EasyFL (PyTorch) receive half the score because users are limited to only one supported ML library [ 52 , 57 , 60 , 62 , 63 , 64 , 76 , 78 , 81 , 83 , 86 , 87 , 89 , 91 , 93 ].
In terms of FL Paradigms , there are seven FL frameworks that support both horizontal and vertical FL and therefore receive full marks: PySyft, FATE AI, FedML, Flower, FedLearner, PaddleFL and FederatedScope. TFF, OpenFL, IBM FL, FLARE, FLSim, FLUTE, FedLab and EasyFL receive a zero score because they only support the standard horizontal FL paradigm [ 55 , 57 , 66 , 74 , 78 , 81 , 83 , 86 , 87 , 88 , 90 , 92 , 126 ].
Evaluation of Interoperability The Rollout To Edge Devices that allows FL applications to be implemented in real-world environments (e.g., on thin-clients or IoT devices) is possible with PySyft, FedML, Flower, IBM FL and FLARE. Therefore, they receive full marks on this criterion. However, PySyft only supports Raspberry Pi, while the other four FL frameworks also support the Nvidia Jetson Development Kits [ 86 ]. FATE AI, PaddleFL, FederatedScope and EasyFL each receive half the possible score because the rollout process on edge devices is more cumbersome compared to the other FL frameworks. For example, FATE AI and PaddleFL require edge devices with at least 100 GB of storage and 6 GB of RAM, which excludes most single-board computers. The FL frameworks TFF, FedLearner, OpenFL, FLUTE, FLSim and FedLab do not score on this criterion because they only support FL in simulation mode on a single device [ 46 , 52 , 60 , 62 , 63 , 64 , 77 , 83 , 87 , 89 , 91 , 93 ].
For the Operating System support, PySyft, FedML, Flower, IBM FL, FLARE, FLSim, FederatedScope and FedLab receive full marks, as Windows and MacOS are natively supported. On the other hand, the following FL framework candidates support only one of each: TFF (MacOS), OpenFL (MacOS), FLUTE (Windows) and EasyFL (MacOS) receive half the score. FATE AI, FedLearner and PaddleFL run only on Linux and require Docker containers when used on Windows or MacOS. Therefore, these three FL frameworks do not receive any points for this criterion [ 50 , 57 , 60 , 73 , 76 , 78 , 79 , 81 , 83 , 84 , 87 , 88 , 90 , 91 , 93 ].
All compared FL frameworks offer GPU Support and receive full scores on this criterion, except for FLSim. The documentation of FLSim makes no reference to a CUDA acceleration mode during FL training and CUDA could not be enabled during the conducted experiments. Therefore, this FL framework receives a score of zero in this criterion [ 51 , 52 , 63 , 66 , 73 , 74 , 76 , 81 , 83 , 86 , 87 , 90 , 91 , 93 ].
13 of the 15 FL framework candidates have a Docker containerization option and therefore receive full marks. These frameworks provide Docker images, which can be installed using the Docker Engine. By setting up a Docker container, it is possible to create an isolated environment which makes it possible to install software even though its requirements are not supported by the system specifications [ 109 ]. Some frameworks like FLARE and OpenFL provide a Dockerfile which builds the image automatically, while other frameworks like PaddleFL provide a documentation on how to install the Docker image manually. Surprisingly, FLSim and Microsoft’s FLUTE do not seem to support Docker containers. The use of Docker containers was not mentioned in the documentations and was not possible during the experiments conducted. Therefore, these two FL frameworks receive zero points for this criterion [ 57 , 60 , 73 , 74 , 76 , 78 , 79 , 81 , 83 , 84 , 87 , 88 , 90 , 91 , 93 ].
Evaluation of User Friendliness For the FATE AI, PaddleFL, and FedLearner FL frameworks, it is not possible to evaluate the criteria Development Effort , Model Accuracy , Training Speed , Data Preparation effort, and model Evaluation because of a number of issues with these FL frameworks, such as failed installations on Windows, Linux or MacOS. Thus, these FL frameworks are marked as N.A. in the mentioned criteria, because test experiments could not be performed with them.
For Development Effort , TFF, OpenFL, FedLab and EasyFL receive a score of one as the setup of applications with these frameworks was intuitive, fast and required few lines of code. FedML, Flower, IBM FL, FLSim, FLUTE and FederatedScope receive a half score, since development requires more lines of code than with the four frameworks mentioned previously, but aspects of the training process like the federated aggregation step or the local loss step are implemented. PySyft and FLARE require the most development effort because parts of the training process, such as gradient descent, must be implemented and set by the user, which is not the case for the other FL framework candidates. Thus, PySyft and FLARE are rewarded with zero points on Development Effort.
As for the global Model Accuracy , PySyft, Flower, OpenFL, IBM FL, FLARE, FLSim, FedLab and EasyFL achieved a test accuracy of over 90% in the performed MNIST classification simulation. On the other hand, FedML, TFF, FLUTE and FederatedScope performed worse, achieving an accuracy below the 90% threshold, thus receiving only half the score, even though the same model architecture, configuration and parameters have been used (see Table 4 on page 11). The test accuracies for the tested frameworks can be found in Table 6 on page 13.
Surprisingly, the amount and quality of Documentation available for the FL frameworks varies widely. PySyft [ 64 , 73 ], TFF [ 63 , 79 ], Flower [ 51 , 77 , 78 ] FLARE [ 84 , 85 , 86 ] and EasyFL [ 55 , 93 , 94 ] provide extensive API documentation, several sample applications and video tutorials to learn how to use these frameworks. These FL frameworks receive the full score on the criterion Documentation. However, FedLearner [ 60 ], PaddleFL [ 57 ], FLSim [ 87 ], and FLUTE [ 69 , 88 ] provide only little and mostly outdated documentation. Therefore, this group of FL frameworks receive zero points here. For FATE AI [ 56 , 74 ], FedML [ 46 , 75 , 76 ], OpenFL [ 49 , 81 ] IBM FL [ 48 , 59 , 83 ], FederatedScope [ 53 , 89 , 90 ] and FedLab [ 54 , 91 , 92 ], the available documentation is less extensive and at times outdated. These FL frameworks receive a score of 0.5 for this criterion.
When performing the test experiments with the FL framework candidates, there were also differences in the model Training Speed . With TFF, OpenFL, FLSim, FedLab and EasyFL, the federated training was completed in less than a minute, giving these frameworks a full score. FL Frameworks with a training speed between one and three minutes (FedML, Flower, FLARE, FLUTE, FederatedScope) received half of the score, while training on PySyft and IBM FL took longer than three minutes, resulting in a score of zero for these two frameworks. Since FLUTE can only be used on Windows [ 88 ], the training speed measurement may not be directly comparable to the measurements of the other FL frameworks which were computed on another computer running MacOS with a different hardware specification. The exact training speeds for the tested frameworks can be found in Table 6 on page 13.
For the assessment of the Data Preparation effort, we considered the effort required to transform proxy training datasets such as MNIST [ 112 ] into the required data format of the FL frameworks. Here, PySyft, Flower, FLARE, FLUTE and FedLab required only minor adjustments (e.g., reshaping the input data) and therefore received full scores, while TFF and IBM FL required more preparation, so both FL frameworks received no scores. FedML, OpenFL, FLSim, FederatedScope and EasyFL received a score of 0.5.
For the Evaluation criterion, TFF, OpenFL, IBM FL, FLSim, FederatedScope, FedLab and EasyFL provide built-in evaluation methods that display test set loss and accuracy metrics for the federated training of a global model, resulting in a full score for these FL frameworks in the Model Evaluation criterion. Since the main category is User Friendliness, PySyft receives a score of zero here because in PySyft all evaluation metrics must be implemented manually, which may include the requirements of additional libraries (e.g., TensorBoard). FedML, Flower, OpenFL and FLUTE provided evaluation methods with incomplete or convoluted output and thus received a score of 0.5.
For the Pricing System criterion, all FL framework candidates except FLUTE and IBM FL receive full marks because their features are freely accessible. FLUTE is integrated with Azure ML Studio [ 69 ]. Microsoft touts a faster and easier federated development process by leveraging its cloud service and proclaiming FLUTE’s integration with Azure ML as one of its key benefits, as the federated application can be used directly in the Azure ecosystem [ 69 ]. On the other hand, IBM FL is part of IBM Watson Studio cloud service, where additional features such as a UI-based monitoring and configuration are available that cannot be used in the open-source community edtion [ 59 ]. Therefore, FLUTE and IBM FL do not score on this criterion.
5.3 Discussion
Considering the scores at the category level, there are some FL frameworks that received notable scores in certain categories. FederatedScope received the highest score in the Features category with 100%, offering differential privacy and homomorphic encryption as security mechanisms, support for different ML libraries and many FL algorithms like FedAvg, FedOpt and FedProx. Meanwhile, EasyFL received only 25% of the score, offering no security mechanisms, FedAvg as the only implemented FL algorithm and one ML library, while only horizontal FL is available as a paradigm.
The FL frameworks PySyft, FedML, Flower, IBM FL and FLARE earned a perfect score of 100% in the Interoperability category, while FedLearner and FLSim performed joint-worst, receiving 25% of the category score (see Table 5 on page 12). FedLearner does not offer a rollout on edge devices and is not available for installation on either Windows or MacOS, limiting its potential user base. FLSim is available for both Windows and MacOS, but does not support a rollout on edge devices, GPU-based computation, or a Docker containerization.
Remarkably, EasyFL received the highest score of 95% in the User Friendliness category, fullfilling the most important criteria: Development Effort, Model Accuracy Documentation and Training Speed. The FL frameworks for which no test application could be created received the lowest scores, with FedLearner and PaddleFL receiving the lowest score in this category with 5%, and FATE AI receiving 15%. These low scores are noteworthy, since these three FL frameworks all have a long development history and are popular within the community (see Table 3 on page 9).
Based on the conducted comparison and evaluation, a ranking of FL frameworks can be constructed, which is visualized in Fig. 4 on page 15. It can be concluded that in terms of the overall score, Flower performed best with 84.75%, followed by FLARE with 80.5% and FederatedScope with 78.75% (see Table 5 on page 12). PySyft, FedML, OpenFL, EasyFL, IBM FL, TFF and FedLab all received scores at or above 60% overall. FLSim received a score of 54.25% and FLUTE scored 43.25%, while FATE AI, PaddleFL and FedLearner all scored below 40% in total, with FedLearner’s 24.75% marking the lowest score of the frameworks in this comparison.
The graphical representation of the scores on the bar plot further shows that the top ten FL frameworks, although with big differences in the category scores, all achieved relatively high total scores (at or above 60%). This suggests that a number of FL frameworks could already offer a satisfying solution for practitioners. The total score for the final five FL frameworks on the bar plot decreases sharply, indicating significant shortcomings in categories or specific criteria. FLSim and FLUTE scored low in the Interoperability category at 25% and 27.5% respectively, while FATE AI, PaddleFL and FedLearner received low User Friendliness scores (15%, 5%, and 5%).

Total scores (in percentage) of the compared frameworks
Generally, the difference in score between the FL frameworks in the Features category is small compared to the other categories. Only two frameworks score below 50%. Most variance in this category is introduced by the security and paradigm criteria. Should secure computation and communication be the focal point of development, then PySyft, PaddleFL, FLARE, FLSim and FederatedScope would provide the most extensive features for this use case.
In the Interoperability category, it is observable that only five of the FL frameworks (PySyft, FedML, Flower, IBM FL, FLARE) support a rollout on edge devices without strong limitations. This explains the high fluctuation of scores for this category, as the Rollout criterion was weighted heavily. Should the development of a fully realized, distributed FL application be central to a project, these five FL frameworks offer the best conditions and are most suitable for communication and real-time computing with IoT edge devices.
Examining the User Friendliness category, the Development Effort and Documentation criteria explain a lot of variability, while most FL frameworks generally perform well when tested for model test accuracy and federated training speed. An unexpectedly large variance was observed in the Training Speed criterion, with times ranging from under one minute to over three minutes. This may be explained by the different architecture of the FL frameworks and sequential and parallel computing approaches in simulation mode. Overall, the three FL frameworks (FATE AI, FedLearner, PaddleFL) for which no test application could be created are big outliers in this category. These three frameworks consequently also received the lowest total score, as displayed in Fig. 4 on page 15.
Furthermore, there are specific use cases for which some frameworks may be particularly suitable. FLARE is being developed by the same company (NVIDIA) which released Clara, which is an artificial intelligence suite focused on medical use cases. It may therefore be argued that FLARE profits from experiences made during the development of Clara. Meanwhile, FedML provides a website with an FL dashboard, where projects can be tracked and shared with collaborators, allowing for easy deployment, and sharing of applications. This may be advantageous when developing an FL applications across organizations. Furthermore, an extension for FATE called FATE-LLM has been released, targeting development of large language models in a federated setting, giving FATE a strong foundation in this area [ 127 ].
It can be concluded that the evaluated FL frameworks are relatively homogeneous regarding the criteria in the Features category. Support for a rollout on edge devices in the Interoperability category and differences in the availability and quality of documentation in the User Friendliness category are the major reasons for the variance in total score between the FL frameworks. To attract practitioners to their FL frameworks, these two aspects need to be most urgently improved by the underperforming FL frameworks.
5.4 Result summary
Based on the literature-driven comparison and analysis results, the RQs posed at the beginning of this paper (see Subection 1 on page 1) can be answered as follows:
RQ 1: Which relevant frameworks for FL exist and are open-source? 15 relevant FL frameworks were selected, reduced from a total of 18 identified FL frameworks after applying the inclusion criteria defined in SubSect. 4.1 on page 7. Table 3 on page 9 gives an overview of the selected FL frameworks. These filtered frameworks are all available as open-source software and have community and industry support. The FL frameworks are used as objects of study in the FL framework comparative analysis (see Sect. 5 on page 8).
RQ 2: Which criteria enable a qualitative and quantitative comparison of FL frameworks? The criteria, weights and evaluation schema introduced in Sect. 5.1 , summarized in Table 7 on page 20, are used in the comparison in SubSect. 5.2 . The criteria include quantitative measures such as Model Accuracy and Training Speed as well as qualitative measures such as the included Security Mechanisms and the quality and scope of the available Documentation. The evaluation schema based on these criteria creates a versatile and comprehensive comparison of FL frameworks.
RQ 3: Which FL framework offers the most added value to practitioners and researchers? Different FL frameworks received the highest scores in each of the three formulated categories (FederatedScope in Features, PySyft, FedML, Flower, IBM FL and FLARE in Interoperability and EasyFL in User Friendliness). This indicates that one of several FL Frameworks might provide the most added value depending on one’s preferences and needs regarding a particular project. The criteria, their weights and the presented result can in this case act as guidelines for FL framework selection. However, based on the comparative results (see SubSect. 5.2 on page 11), the FL framework Flower currently offers the most overall added value to practitioners and researchers.
6 Limitations and outlook
In this study, not all currently available FL frameworks are represented, since we formulated inclusion criteria to limit the number of FL framework candidates (see SubSect. 4.1 on page 7). The field of FL frameworks for the proposed comparison suite can be extended to include, for example, proprietary framework candidates that have not been considered in this study. A comparison of these with open-source FL frameworks could provide further interesting insights into the alignment and target audience of each FL framework. Additional experiments with FL frameworks in different FL settings could lead to more comprehensive benchmarking results. The vertical FL and federated transfer learning settings would be possible additions, should more frameworks support these paradigms in the future. Depending on the use case, an adjustment of the criteria weighting might also be required. Therefore, the comparison evaluation schema proposed in this paper can be adapted as desired to reflect the priorities of practitioners and researchers for particular FL projects.
FL is still a niche research field, but the number of scientific papers published each year is steadily increasing (see Fig. 3 on page 6) [ 128 , 129 , 130 , 131 , 132 ]. Based on this trend, we also expect a large number of new FL frameworks to be released in the near future. These emerging FL frameworks can be evaluated and compared to other FL frameworks upon release using the comparison methodology proposed in this paper.
7 Conclusion
In this study, a comparison suite to evaluate open-source Federated Learning (FL) frameworks was introduced. For this, a literature review was conducted following the guidelines set by Webster and Watson. The review method involved identifying relevant literature and organizing it based on the most significant concepts discovered through the use of a Latent Dirichlet Allocation (LDA) applied on identified publications relevant to FL. Based on filtered relevant literature, comparison criteria were formulated, and a weighted scoring system has been proposed. The criteria were categorized into the overarching categories of Features, Interoperability, and User Friendliness. Additionally, two inclusion criteria, namely the open-source availability and community popularity were established to narrow down the number of FL frameworks under consideration. This enabled us to conduct a more detailed comparison and evaluation of 15 relevant open-source FL frameworks as the study subjects. Both qualitative and quantitative aspects of the FL frameworks were compared, and a detailed score was calculated for each FL framework as a percentage. The conducted comparison analysis demonstrated that among the investigated FL frameworks, Flower performed the best, achieving a total score of 84.75%. Other FL framework candidates such as FLARE, FederatedScope, PySyft, FedML, OpenFL, EasyFL, IBM FL, TFF and FedLab also achieved a high total score (at or above 60%) but could not beat Flower in all aspects. Additionally, we observed that FederatedScope performed best in the Features category. PySyft, FedML, Flower, IBM FL and FLARE all received highest scores in the Interoperability category, while EasyFL performed best in the User Friendliness category. The worst performing FL frameworks were FATE AI, PaddleFL and FedLearner with a total score of 38.5%, 35% and 24.75% respectively, because they lacked in the Interoperability and particularily in the User Friendliness category. Due to their limitations, test experiments could not be conducted to accurately measure criteria such as Model Accuracy or Training Speed. While this study demonstrated the superior performance of FL frameworks such as Flower, FLARE or FederatedScope in most baseline scenarios, it is important to note that the priorities and requirements of practitioners and researchers may vary. Therefore, the results of this study can be used primarily as a guiding tool in the FL framework selection process for federated-driven analyses.
Data availability
The MNIST [ 111 , 112 ] proxy dataset that supports the findings of this study is openly available in http://yann.lecun.com/exdb/mnist/
McMahan HB, Moore E, Ramage D, Hampson S, Arcas BA (2017) Communication-efficient learning of deep networks from decentralized data. J Mach Learn Res 54:1273–1282
Google Scholar
Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, Zhang L (2016) Deep learning with differential privacy. 23rd ACM conference on computer and communications security (CCS 2016), 308–318. https://doi.org/10.1145/2976749.2978318
Hard A, Rao K, Mathews R, Beaufays F, Augenstein S, Eichner H, Kiddon C, Ramage D (2018) Federated learning for mobile keyboard prediction arXiv:1811.03604
Li T, Sahu AK, Talwalkar A, Smith V (2020) Federated learning: challenges, methods, and future directions. IEEE Signal Process Mag 37:50–60. https://doi.org/10.1109/MSP.2020.2975749
Article Google Scholar
Kairouz P, McMahan HB, Avent B, Bellet A, Bennis M, Bhagoji AN, Bonawitz KA, Charles Z, Cormode G, Cummings R, D’Oliveira RGL, Rouayheb SE, Evans D, Gardner J, Garrett Z, Gascon A, Ghazi B, Gibbons PB, Gruteser M, Harchaoui Z, He C, He L, Huo Z, Hutchinson B, Hsu J, Jaggi M, Javidi T, Joshi G, Khodak M, Konecny J, Korolova A, Koushanfar F, Koyejo S, Lepoint T, Liu Y, Mittal P, Mohri M, Nock R, Ozgur A, Pagh R, Raykova M, Qi H, Ramage D, Raskar R, Song D, Song W, Stich SU, Sun Z, Suresh AT, Tramer F, Vepakomma P, Wang J, Xiong L, Xu Z, Yang Q, Yu FX, Yu H, Zhao S (2021) Advances and open problems in federated learning. Found Trends Mac Learn 14:1–121. https://doi.org/10.1561/2200000083
Zhang L, Zhu T, Xiong P, Zhou W, Yu P (2023) A robust game-theoretical federated learning framework with joint differential privacy. IEEE Trans Knowl Data Eng 35:3333–3346. https://doi.org/10.1109/TKDE.2021.3140131
Jin H, Bai D, Yao D, Dai Y, Gu L, Yu C, Sun L (2023) Personalized edge intelligence via federated self-knowledge distillation. IEEE Trans Parallel Distrib Syst 34:567–580. https://doi.org/10.1109/TPDS.2022.3225185
Nguyen DC, Pham Q-V, Pathirana PN, Ding M, Seneviratne A, Lin Z, Dobre O, Hwang W-J (2022) Federated learning for smart healthcare: a survey. ACM Comput Surv 55:1–37
Antunes RS, da Costa CA, Küderle A, Yari IA, Eskofier B (2022) Federated learning for healthcare: systematic review and architecture proposal. ACM Trans Intell Syst Technol 13:1–23
Xing H, Xiao Z, Qu R, Zhu Z, Zhao B (2022) An efficient federated distillation learning system for multi-task time series classification. IEEE Trans Instrum Meas 71:1–12. https://doi.org/10.1109/TIM.2022.3201203
Riedel P, von Schwerin R, Schaudt D, Hafner A, Resnetfed S (2023) Federated deep learning architecture for privacy-preserving pneumonia detection from covid-19 chest radiographs. J Healthcare Inf Res 7:203–224
Rahman A, Hossain MS, Muhammad G, Kundu D, Debnath T, Rahman M, Khan MSI, Tiwari P, Band SS (2023) Federated learning-based ai approaches in smart healthcare: concepts, taxonomies, challenges and open issues. Clust Comput 26:2271–2311. https://doi.org/10.1007/s10586-022-03658-4
Bharati S, Mondal MRH, Podder P, Prasath VBS (2022) Federated learning: applications, challenges and future directions. Int J Hybrid Intell Syst 18:19–35
Witt L, Heyer M, Toyoda K, Samek W, Li D (2023) Decentral and incentivized federated learning frameworks: a systematic literature review. IEEE Internet Things J 10:3642–3663
Xiao Z, Xu X, Xing H, Song F, Wang X, Zhao B (2021) A federated learning system with enhanced feature extraction for human activity recognition. Knowl-Based Syst. https://doi.org/10.1016/j.knosys.2021.107338
Boobalan P, Ramu SP, Pham QV, Dev K, Pandya S, Maddikunta PKR, Gadekallu TR, Huynh-The T (2022) Fusion of federated learning and industrial internet of things: a survey. Comput Netw 212
Pandya S, Srivastava G, Jhaveri R, Babu MR, Bhattacharya S, Maddikunta PKR, Mastorakis S, Thippa MJP, Gadekallu R (2023) Federated learning for smart cities: a comprehensive survey. Sustain Energy Technol Assess 55:2–13
Zhang T, Gao L, He C, Zhang M, Krishnamachari B, Avestimehr AS (2022) Federated learning for the internet of things: applications, challenges, and opportunities. IEEE Internet Things Mag 5:24–29
Zhang K, Song X, Zhang C, Yu S (2021) Challenges and future directions of secure federated learning: a survey. Front Comput Sci 16:1–8
Li C, Zeng X, Zhang M, Cao Z (2022) Pyramidfl: a fine-grained client selection framework for efficient federated learning. Proceedings of the 28th annual international conference on mobile computing and networking 28, 158–171
Huang W, Ye M, Du B (2022) Learn from others and be yourself in heterogeneous federated learning. 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Wen J, Zhang Z, Lan Y, Cui Z, Cai J, Zhang W (2023) A survey on federated learning: challenges and applications. Int J Mach Learn Cybern 14:513–535. https://doi.org/10.1007/s13042-022-01647-y
Guendouzi BS, Ouchani S, Assaad HE, Zaher ME (2023) A systematic review of federated learning: challenges, aggregation methods, and development tools. J Netw Comput Appl. https://doi.org/10.1016/j.jnca.2023.103714
Zhao Y, Li M, Lai L, Suda N, Civin D, Chandra V (2018) Federated learning with non-iid data arXiv:1806.00582
Almanifi ORA, Chow C-O, Tham M-L, Chuah JH, Kanesan J (2023) Communication and computation efficiency in federated learning: a survey. Internet Things 22:100742
Xu C, Qu Y, Xiang Y, Gao L (2023) Asynchronous federated learning on heterogeneous devices: a survey. Comput Sci Rev. https://doi.org/10.1016/j.cosrev.2023.100595
Qi P, Chiaro D, Guzzo A, Ianni M, Fortino G, Piccialli F (2023) Model aggregation techniques in federated learning: a comprehensive survey. Futur Gener Comput Syst 150:272–293. https://doi.org/10.1016/j.future.2023.09.008
Li Q, Diao Y, Chen Q, He B (2022) Federated learning on non-iid data silos: an experimental study. 2022 IEEE 38th iInternational conference on data engineering (ICDE)
Wang Z, Xu H-Z, Xu Y, Jiang Z, Liu J, Chen S (2024) Fast: enhancing federated learning through adaptive data sampling and local training. IEEE Trans Parallel Distrib Syst 35:221–236. https://doi.org/10.1109/TPDS.2023.3334398
Abreha HG, Hayajneh M, Serhani MA (2022) Federated learning in edge computing: a systematic survey. Sensors 22:450
Ticao Zhang SM (2021) An introduction to the federated learning standard. GetMobile Mobile Comput Commun 25:18–22
Beltrán ETM, Pérez MQ, Sánchez PMS, Bernal SL, Bovet G, Pérez MG, Pérez GM, Celdrán AH (2023) Decentralized federated learning: fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun Surv Tutorials 25:2983–3013. https://doi.org/10.1109/COMST.2023.3315746
Yang Q, Liu Y, Chen T, Tong Y (2019) Federated machine learning: concept and applications. ACM Trans Intell Syst Technol 10:1–19. https://doi.org/10.1145/3298981
Gong X, Chen Y, Wang Q, Kong W (2023) Backdoor attacks and defenses in federated learning: state-of-the-art, taxonomy, and future directions. IEEE Wirel Commun 30:114–121. https://doi.org/10.1109/MWC.017.2100714
Dwork C, Roth A (2014) The algorithmic foundations of differential privacy. Found Trends Theor Comput Sci 9:211–407. https://doi.org/10.1561/0400000042
Article MathSciNet Google Scholar
McMahan HB, Ramage D, Talwar K, Zhang L (2018) Learning differencially private recurrent language models. International Conference on Learning Representations
Shaheen M, Farooq MS, Umer T, Kim B-S (2022) Applications of federated learning; taxonomy, challenges, and research trends. Electronics 11:670
Rodríguez-Barroso N, Jiménez-López D, Luzón MV, Herrera F, Martínez-Cámara E (2023) Survey on federated learning threats: concepts, taxonomy on attacks and defences, experimental study and challenges. Inf Fusion 90:148–173
Cummings R, Gupta V, Kimpara D, Morgenstern JH (2019) On the compatibility of privacy and fairness. Adjunct publication of the 27th conference on user modeling, adaptation and personalization, 309–315 https://doi.org/10.1145/3314183.3323847
Kusner MJ, Loftus JR, Russell C, Silva R (2017) Counterfactual fairness. 31st conference on neural iInformation processing systems 30, 4069–4079
Ding J, Tramel E, Sahu AK, Wu S, Avestimehr S, Zhang T (2022) Federated learning challenges and opportunities: an outlook. ICASSP 2022 - 2022 IEEE iInternational conference on acoustics, speech and signal processing (ICASSP)
Buolamwini J, Gebru T (2018) Gender shades: intersectional accuracy disparities in commercial gender classification. Proc Mach Learn Res 81:1–15
Zhang X, Kang Y, Chen K, Fan L, Yang Q (2023) Trading off privacy, utility, and efficiency in federated learning. ACM Trans Intell Syst Technol 14:98–18931. https://doi.org/10.1145/3595185
Khan M, Glavin FG, Nickles M (2023) Federated learning as a privacy solution - an overview. Procedia Comput Sci 217:316–325. https://doi.org/10.1016/j.procs.2022.12.227
Webster J, Watson RT (2002) Analyzing the past to prepare for the future: writing a literature review. MIS Q 26(2),
He C, Li S, So J, Zhang M, Wang H, Wang X, Vepakomma P, Singh A, Qiu H, Shen L, Zhao P, Kang Y, Liu Y, Raskar R, Yang Q, Annavaram M, Avestimehr S (2020) Fedml: a research library and benchmark for federated machine learning arXiv:2007.13518
Barroso NR, Stipcich G, Jimenez-Lopez D, Ruiz-Millan JA, Martinez-Camara E, Gonzalez-Seco G, Luzon MV, Veganzones MA, Herrera F (2020) Federated learning and differential privacy: software tools analysis, the sherpa.ai fl framework and methodological guidelines for preserving data privacy. Inf Fusion 64:270–292
Ludwig H, Baracaldo N, Thomas G, Zhou Y, Anwar A, Rajamoni S, Ong YJ, Radhakrishnan J, Verma A, Sinn M, Purcell M, Rawat A, Minh TN, Holohan N, Chakraborty S, Witherspoon S, Steuer D, Wynter L, Hassan H, Laguna S, Yurochkin M, Agarwal M, Chuba E, Abay A (2020) Ibm federated learning: an enterprise framework white paper v0.1 arXiv:2007.10987
Reina GA, Gruzdev A, Foley P, Perepelkina O, Sharma M, Davidyuk I, Trushkin I, Radionov M, Mokrov A, Agapov D, Martin J, Edwards B, Sheller MJ, Pati S, Moorthy PN, Wang HS, Shah P, Bakas S (2021) Openfl: an open-source framework for federated learning arXiv:2105.06413
Liu Y, Fan T, Qian Xu TC, Yang Q (2021) Fate: an industrial grade platform for collaborative learning with data protection. J Mach Learn Res 22:1–6
MathSciNet Google Scholar
Beutel DJ, Topal T, Mathur A, Qiu X, Parcollet T, Lane ND (2020) Flower: a friendly federated learning research framework arXiv:2007.14390
Dimitriadis D, Garcia MH, Diaz DM, Manoel A, Sim R (2022) Flute: a scalable, extensible framework for high-performance federated learning simulations arXiv:2203.13789
Xie Y, Wang Z, Gao D, Chen D, Yao L, Kuang W, Li Y, Ding B, Zhou J (2023) Federatedscope: a flexible federated learning platform for heterogeneity. Proc VLDB Endowment 16: 1000–1012. https://doi.org/10.14778/3579075.3579076
Zeng D, Liang S, Hu X, Wang H, Xu Z (2023) Fedlab: a flexible federated learning framework. J Mach Learn Res 24:1–7
Zhuang W, Gan X, Wen Y, Zhang S (2022) Easyfl: a low-code federated learning platform for dummies. IEEE Internet Things J 9:13740–13754. https://doi.org/10.1109/JIOT.2022.3143842
FedAI: what is FATE? https://fate.fedai.org/overview/ Accessed 20 Feb 2024
PaddlePaddle: GitHub Repository PaddlePaddle/PaddleFL. https://github.com/PaddlePaddle/PaddleFL Accessed 20 Feb 2024
NVIDIA: NVIDIA Clara: an application framework optimized for healthcare and life sciences developers. https://developer.nvidia.com/clara Accessed 30 May 2023
IBM Research: IBM Federated Learning. https://ibmfl.res.ibm.com Accessed 20 Feb 2024
ByteDance: GitHub Repository FedLearner. https://github.com/bytedance/fedlearner Accessed 20 Feb 2024
Liu J, Huang J, Zhou Y, Li X, Ji S, Xiong H, Dou D (2022) From distributed machine learning to federated learning: a survey. Knowl Inf Syst 64:885–917
Kholod I, Yanaki E, Fomichev D, Shalugin ED, Novikova E, Filippov E, Nordlund M (2021) Open-source federated learning frameworks for iot: a comparative review and analysis. Sensors 21:167–189. https://doi.org/10.3390/s21010167
TensorFlow: TensorFlow Federated: Machine Learning on Decentralized Data. https://www.tensorflow.org/federated Accessed 20 Feb 2024
OpenMined: OpenMined. https://www.openmined.org Accessed 20 Feb 2024
Sherpa.ai: Sherpa.ai: Privacy-Preserving Artificial Intelligence. https://www.sherpa.ai Accessed 20 Feb 2024
Liu X, Shi T, Xie C, Li Q, Hu K, Kim H, Xu X, Li B, Song D (2022) Unifed: a benchmark for federated learning frameworks arXiv:2207.10308
SciKitLearn: Latent Dirichlet Allocation. https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.LatentDirichletAllocation.html Accessed 24 April 2023
OpenAI: OpenAI: Pricing. https://openai.com/pricing Accessed 20 Feb 2024
Microsoft: FLUTE: a scalable federated learning simulation platform. https://bit.ly/3KnvugJ Accessed 20 Feb 2024
Caldas S, Duddu SMK, Wu P, Li T, Konečný J, McMahan HB, Smith V, Talwalkar A (2018) Leaf: a benchmark for federated settings
Lai F, Dai Y, Singapuram S, Liu J, Zhu X, Madhyastha H, Chowdhury M Fedscale: Benchmarking model and system performance of federated learning at scale. Proceedings of the 39th international conference on machine learning 162 (2022)
FederalLab: GitHub Repository OpenFed. https://github.com/FederalLab/OpenFed Accessed 20 Feb 2024
OpenMined: GitHub Repository OpenMined/PySyft. https://github.com/OpenMined Accessed 20 Feb 2024
FedAI: GitHub Repository FedAI/FATE. https://github.com/FederatedAI/FATE Accessed 20 Feb 2024
FedML: FedML: The Federated Learning/Analytics and Edge AI Platform. https://fedml.ai Accessed 20 Feb 2024
FedML: GitHub Repository FedML-AI. https://github.com/FedML-AI Accessed 20 Feb 2024
Adap: Adap: Fleet AI. https://adap.com/en Accessed 20 Feb 2024
Adap: GitHub Repository Adap/Flower. https://github.com/adap/flower Accessed 20 Feb 2024
TensorFlow: GitHub Repository TensorFlow/Federated. https://github.com/tensorflow/federated Accessed 20 Feb 2024
Baidu research: Baidu PaddlePaddle releases 21 new capabilities to accelerate industry-grade model development. http://research.baidu.com/Blog/index-view?id=126 Accessed 07 Aug 2023
Intel: GitHub Repository Intel/OpenFL. https://github.com/intel/openfl Accessed 20 Feb 2024
University of Pennsylvania: CBICA: The Federated Tumor Segmentation (FeTS) Initiative. https://www.med.upenn.edu/cbica/fets/ Accessed 24 Aug 2022
IBM: GitHub Repository IBM Federated Learning. https://github.com/IBM/federated-learning-lib Accessed 20 Feb 2024
NVIDIA: GitHub Repository NVIDIA FLARE. https://github.com/NVIDIA/NVFlare Accessed 20 Feb 2024
Dogra, P.: Federated learning with FLARE: NVIDIA brings collaborative AI to healthcare and beyond. https://blogs.nvidia.com/blog/2021/11/29/federated-learning-ai-nvidia-flare/ Accessed 02 Aug 2023
NVIDIA: NVIDIA FLARE Documentation. https://nvflare.readthedocs.io/en/2.1.1/index.html Accessed 20 Feb 2024
Meta Research: GitHub Repository FLSim. https://github.com/facebookresearch/FLSim Accessed 20 Feb 2024
Microsoft: GitHub Repository Microsoft FLUTE. https://github.com/microsoft/msrflute Accessed 20 Feb 2024
FederatedScope: FederatedScope. https://federatedscope.io Accessed 20 Feb 2024
FederatedScope: GitHub FederatedScope. https://github.com/alibaba/FederatedScope Accessed 20 Feb 2024
FedLab: GitHub FedLab. https://github.com/SMILELab-FL/FedLab Accessed 20 Feb 2024
FedLab: ReadTheDocs FedLab. https://fedlab.readthedocs.io/en/master/ Accessed 20 Feb 2024
EasyFL: GitHub EasyFL. https://github.com/EasyFL-AI/EasyFL/tree/master Accessed 20 Feb 2024
EasyFL: ReadTheDocs EasyFL. https://easyfl.readthedocs.io/en/latest/ Accessed 20 Feb 2024
Bonawitz K, Eichner H, Grieskamp W, Huba D, Ingerman A, Ivanov V, Kiddon C, Koneny J, Mazzocchi S, McMahan B, Overveldt TV, Petrou D, Ramage D, Roselander J (2019) Towards federated learning at scale: system design. Proc Mach Learn Syst 1:374–388
Mansour Y, Mohri M, Ro J, Suresh AT (2020) Three approaches for personalization with applications to federated learning arXiv:2002.10619
Silva PR, Vinagre J, Gama J (2023) Towards federated learning: an overview of methods and applications. WIREs Data Min Knowl Discov 13:1–23
Zhu H, Xu J, Liu S, Jin Y (2021) Federated learning on non-iid data: a survey. Neurocomputing 465:371–390. https://doi.org/10.1016/j.neucom.2021.07.098
Nilsson A, Smith S, Ulm G, Gustavsson E, Jirstrand M (2018) A performance evaluation of federated learning algorithms. DIDL ’18: Proceedings of the second workshop on distributed infrastructures for deep learning 2, 1–8 . https://doi.org/10.1145/3286490.3286559
Asad M, Moustafa A, Ito T, Aslam M (2020) Evaluating the communication efficiency in federated learning algorithms. Proceedings of the 27th ACM symposium on operating systems principles. https://doi.org/10.1109/CSCWD49262.2021.9437738
Smith V, Chiang C-K, Sanjabi M, Talwalkar A (2017) Federated multi-task learning. 31st conference on neural information processing systems (NIPS 2017), 4427–4437
Lo SK, Lu Q, Wang C, Paik H, Zhu L (2021) A systematic literature review on federated machine learning: from a software engineering perspective. ACM Comput Surv 54(5):1–39. https://doi.org/10.1145/3450288
Lyu L, Yu H, Zhao J, Yang Q (2020) Threats to federated learning. Lecture Notes Artif Intell 12500:3–16. https://doi.org/10.1007/978-3-030-63076-8_1
Bagdasaryan E, Veit A, Hua Y, Estrin D, Shmatikov V (2020) How to backdoor federated learning. Proceedings of the 23rd international conference on artificial intelligence and statistics, 2938–2948
Shejwalkar V, Houmansadr A, Kairouz P, Ramage D (2022) Back to the drawing board: a critical evaluation of poisoning attacks on production federated learning. 2022 IEEE symposium on security and privacy (SP)
Fu J, Zhang X, Ji S, Chen J, Wu J, Guo S, Zhou J, Liu AX, Wang T (2022) Label inference attacks against vertical federated learning. Proceedings of the 31st USENIX security symposium 31
Feng S, Yu H (2020) Multi-participant multi-class vertical federated learning arXiv:2001.11154
Liu Y, Kang Y, Xing C, Chen T, Yang Q (2020) A secure federated transfer learning framework. IEEE Intell Syst 35(4):70–82. https://doi.org/10.1109/MIS.2020.2988525
Docker Inc.: The industry-leading container runtime. https://www.docker.com/products/container-runtime/ Accessed 07 June 2023
Fayad M, Schmidt D (1997) Object-oriented application frameworks. Commun ACM 40(10):32–38. https://doi.org/10.1145/262793.262798
Ge D-Y, Yao X-F, Xiang W-J, Wen, X-J, Liu, E-C (2019) Design of high accuracy detector for mnist handwritten digit recognition based on convolutional neural network. 2019 12th international conference on intelligent computation technology and automation (ICICTA), 658–662 . https://doi.org/10.1109/ICICTA49267.2019.00145
Deng L (2012) The mnist database of handwritten digit images for machine learning research. IEEE Signals Process Mag 29(6):141–142. https://doi.org/10.1109/MSP.2012.2211477
Avent B, Korolova A, Zeber D, Hovden T, Livshits B (2017) Blender enabling local search with a hybrid differential privacy model. J Privacy Confid 9, 747–764. DOIurlhttps://doi.org/10.29012/jpc.680
Cheu A, Smith AD, Ullman J, Zeber D, Zhilyaev M (2019) Distributed differential privacy via shuffling. IACR Cryptol. ePrint Arch, 375–403 . https://doi.org/10.1007/978-3-030-17653-2_13
Roth E, Noble D, Falk BH, Haeberlen A (2019) Honeycrisp: large-scale differentially private aggregation without a trusted core. Proceedings of the 27th ACM Symposium on Operating Systems Principles, 196–210. https://doi.org/10.1145/3341301.3359660
Song S, Chaudhuri K, Sarwate AD (2013) Stochastic gradient descent with differentially private updates. 2013 IEEE global conference on signal and information processing, 245–248. https://doi.org/10.1109/GlobalSIP.2013.6736861
Masters O, Hunt H, Steffinlongo E, Crawford J, Bergamaschi F (2019) Towards a homomorphic machine learning big data pipeline for the financial services sector. IACR Cryptol. ePrint Arch, 1–21
Yao AC-C (1986) How to generate and exchange secrets. Proceedings of the 27th annual symposium on foundations of computer science, 162–167
Kaissis G, Ziller A, Passerat-Palmbach J, Ryffel T, Usynin D, Trask A, Lima I, Mancuso J, Jungmann F, Steinborn M-M, Saleh A, Makowski M, Rueckert D, Braren R (2021) End-to-end privacy preserving deep learning on multi-institutional medical imaging. Nat Mach Intell 3(6):473–484. https://doi.org/10.1038/s42256-021-00337-8
Subramanyan P, Sinha R, Lebedev IA, Devadas S, Seshia SA (2017) A formal foundation for secure remote execution of enclaves. Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, 2435–2450. https://doi.org/10.1145/3133956.3134098
Hardy S, Henecka W, Ivey-Law H, Nock R, Patrini G, Smith G, Thorne B (2017) Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption arXiv:1711.10677
Nikolaenko V, Weinsberg U, Ioannidis S, Joye M, Boneh D, Taft N (2013) Privacy-preserving ridge regression on hundreds of millions of records. 2013 IEEE symposium on security and privacy, 334–348. https://doi.org/10.1109/SP.2013.30
So J, He C, Yang C-S, Li S, Yu Q, Ali RE, Guler B, Avestimehr S (2022) Lightsecagg: a lightweight and versatile design for secure aggregation in federated learning. Proc Mach Learn Syst 4:694–720
Li T, Sahu AK, Zaheer M, Sanjabi M, Talwalkar A, Smith V (2020) Federated optimization in heterogeneous networks. Proc Mach Learn Syst 2:429–450
Reddi SJ, Charles Z, Zaheer M, Garrett Z, Rush K, Konečný J, Kumar S, McMahan HB (2021) Adaptive federated optimization. International conference on learning representations ICLR 2021
Romanini D, Hall AJ, Papadopoulos P, Titcombe T, Ismail A, Cebere T, Sandmann R, Roehm R, Hoeh MA (2021) Pyvertical: a vertical federated learning framework for multi-headed splitnn. ICLR 2021 Workshop on distributed and private machine learning
Fan T, Kang Y, Ma G, Chen W, Wei W, Fan L, Yang Q (2023) Fate-llm: a industrial grade federated learning framework for large language models. Arxiv Preprint
Velez-Esteveza A, Ducangeb P, Perezc IJ, Coboc MJ (2022) Conceptual structure of federated learning research field. Procedia Comput Sci 214:1374–1381
Farooq A, Feizollah A, Rehman MH (2021) Federated learning research trends and bibliometric analysis. Stud Comput Intell 965:1–19. https://doi.org/10.1007/978-3-030-70604-3_1
Gong M, Zhang Y, Gao Y, Qin AK, Wu Y, Wang S, Zhang Y (2024) A multi-modal vertical federated learning framework based on homomorphic encryption. IEEE Trans Inf Forensics Secur 19:1826–1839. https://doi.org/10.1109/TIFS.2023.3340994
Caramalau R, Bhattarai B, Stoyanov D (2023) Federated active learning for target domain generalisation. ArXiv abs/2312.02247 . https://doi.org/10.48550/arXiv.2312.02247
Matsuda K, Sasaki Y, Xiao C, Onizuka M (2024) Benchmark for personalized federated learning. IEEE Open J Comput Soc 5:2–13. https://doi.org/10.1109/OJCS.2023.3332351
Download references
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and affiliations.
University of Applied Sciences Ulm, Prittwitzstraße 10, 89075, Ulm, Baden-Württemberg, Germany
Pascal Riedel, Reinhold von Schwerin, Daniel Schaudt & Alexander Hafner
University of Tübingen, Geschwister-Scholl-Platz, 72074, Tübingen, Baden-Württemberg, Germany
Lukas Schick
University of Ulm, Helmholzstraße 16, 89081, Ulm, Baden-Württemberg, Germany
Pascal Riedel & Manfred Reichert
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Pascal Riedel .
Ethics declarations
Conflict of interest.
The authors have no Conflict of interest to declare that are relevant to the content of this article and there are no financial interests
Ethical approval
The data and models used are purely for scientific purposes and do not replace a clinical COVID-19 diagnosis by medical specialists
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Supplemental Material
See Figs. 5 , 6 and Table 7 .

List of topics, words and frequencies using LDA

Graphical representation of the most common words used in the identified literature
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Riedel, P., Schick, L., von Schwerin, R. et al. Comparative analysis of open-source federated learning frameworks - a literature-based survey and review. Int. J. Mach. Learn. & Cyber. (2024). https://doi.org/10.1007/s13042-024-02234-z
Download citation
Received : 13 August 2023
Accepted : 28 May 2024
Published : 28 June 2024
DOI : https://doi.org/10.1007/s13042-024-02234-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Federated learning
- Machine learning
- Open source
- Framework comparison
- Find a journal
- Publish with us
- Track your research
Title: Service quality in religious tourism: a review of literature
Authors : Ana Lúcia da Cunha; Alamir Costa Louro
Addresses : Federal Institute of Maranhão, Carolina Campus, Technical Education Division – Brazil, Rua Imperatriz, 602-736, Carolina-MA, 65980-000, Brazil ' Federal University of Espírito Santo, PPGADM – Brazil, Rua Bias Fortes, 68, Faria Lemos-MG, 36840-000, Brazil
Abstract : Religious tourism involves religion, culture, and the economy, making it a complex subject. This study focuses on service quality. It analyses the current state of service quality in global religious tourism using a Scopus and Web of Science database review. Key findings include trends in Muslim religion-related tourism, concepts like experience, satisfaction, and loyalty in religious tourism service quality, and the strong link between trip attraction satisfaction and repeat intention. The paper also discusses quantitative analysis methodology and future research directions.
Keywords : religious tourism; pilgrimage; service quality; bibliometric; foundations; trends.
DOI : 10.1504/IJTP.2024.139738
International Journal of Tourism Policy, 2024 Vol.14 No.4, pp.402 - 420
Received: 12 Jul 2023 Accepted: 10 Nov 2023 Published online: 05 Jul 2024 *
Keep up-to-date
- Our Newsletter ( subscribe for free )
- New issue alerts
- Inderscience is a member of publishing organisations including:
IMAGES
VIDEO
COMMENTS
As mentioned previously, there are a number of existing guidelines for literature reviews. Depending on the methodology needed to achieve the purpose of the review, all types can be helpful and appropriate to reach a specific goal (for examples, please see Table 1).These approaches can be qualitative, quantitative, or have a mixed design depending on the phase of the review.
This article is organized as follows: The next section presents the methodology adopted by this research, followed by a section that discusses the typology of literature reviews and provides empirical examples; the subsequent section summarizes the process of literature review; and the last section concludes the paper with suggestions on how to improve the quality and rigor of literature ...
Mixed studies review/mixed methods review: Refers to any combination of methods where one significant component is a literature review (usually systematic). Within a review context, it refers to a combination of review approaches, for example, combining quantitative with qualitative research or outcome with process studies.
1. INTRODUCTION. Evidence synthesis is a prerequisite for knowledge translation. 1 A well conducted systematic review (SR), often in conjunction with meta‐analyses (MA) when appropriate, is considered the "gold standard" of methods for synthesizing evidence related to a topic of interest. 2 The central strength of an SR is the transparency of the methods used to systematically search ...
9.3. Types of Review Articles and Brief Illustrations. EHealth researchers have at their disposal a number of approaches and methods for making sense out of existing literature, all with the purpose of casting current research findings into historical contexts or explaining contradictions that might exist among a set of primary research studies conducted on a particular topic.
Overview. A Systematic Literature Review (SLR) is a research methodology to collect, identify, and critically analyze the available research studies (e.g., articles, conference proceedings, books, dissertations) through a systematic procedure .An SLR updates the reader with current literature about a subject .The goal is to review critical points of current knowledge on a topic about research ...
The best reviews synthesize studies to draw broad theoretical conclusions about what a literature means, linking theory to evidence and evidence to theory. This guide describes how to plan, conduct, organize, and present a systematic review of quantitative (meta-analysis) or qualitative (narrative review, meta-synthesis) information.
quantitative literature review? 1. Systematic = methods to survey literature and select papers to include are explicit and reproducible 2. Quantitative = measure of the amount (number of papers) of research within different sections of topic 3. Comprehensive = assesses different combinations of
Examples of literature reviews. Step 1 - Search for relevant literature. Step 2 - Evaluate and select sources. Step 3 - Identify themes, debates, and gaps. Step 4 - Outline your literature review's structure. Step 5 - Write your literature review.
The conventional focus of rigorous literature reviews (i.e., review types for which systematic methods have been codified, including the various approaches to quantitative systematic reviews [2-4], and the numerous forms of qualitative and mixed methods literature synthesis [5-10]) is to synthesize empirical research findings from multiple ...
In the field of research, the term method represents the specific approaches and procedures that the researcher systematically utilizes that are manifested in the research design, sampling design, data collec-tion, data analysis, data interpretation, and so forth. The literature review represents a method because the literature reviewer chooses ...
In The Literature Review: A Step-by-Step Guide for Students, Ridley presents that literature reviews serve several purposes (2008, p. 16-17). Included are the following points: Historical background for the research; Overview of current field provided by "contemporary debates, issues, and questions;" Theories and concepts related to your research;
A systematic review aims to bring evidence together to answer a pre-defined research question. This involves the identification of all primary research relevant to the defined review question, the critical appraisal of this research, and the synthesis of the findings.13 Systematic reviews may combine data from different.
Comprehensive Literature Reviews: Involve supplementing electronic searches with a review of references in identified literature, manual searches of references and journals, and consulting experts for both unpublished and published studies and reports. Reporting Standards: Checking for Research Writing and Reviewing.
This article is a practical guide to conducting data analysis in general literature reviews. The general literature review is a synthesis and analysis of published research on a relevant clinical issue, and is a common format for academic theses at the bachelor's and master's levels in nursing, physiotherapy, occupational therapy, public health and other related fields.
Mixed studies review/mixed methods review: Refers to any combination of methods where one significant component is a literature review (usually systematic). Within a review context it refers to a combination of review approaches for example combining quantitative with qualitative research or outcome with process studies
Systematic review vs. literature review. A literature review is a type of review that uses a less systematic and formal approach than a systematic review. Typically, an expert in a topic will qualitatively summarize and evaluate previous work, without using a formal, explicit method. ... Quantitative: Use statistical methods to summarize and ...
Quantitative Research (an operational definition) Quantitative research: an operational description. Purpose: explain, predict or control phenomena through focused collection and analysis of numberical data. Approach: deductive; tries to be value-free/has objectives/ is outcome-oriented. Hypotheses: Specific, testable, and stated prior to study.
This short video introduces viewers to a powerful 15 step method for undertaking and publishing literature reviews including by those new to the discipline. It is the first in a series of four videos on the Systematic Quantitative Literature Review providing an overview of the method in outlined in: Pickering, C.M. and Byrne, J. (2014).
Method details Overview. A Systematic Literature Review (SLR) is a research methodology to collect, identify, and critically analyze the available research studies (e.g., articles, conference proceedings, books, dissertations) through a systematic procedure [12].An SLR updates the reader with current literature about a subject [6].The goal is to review critical points of current knowledge on a ...
The systematic quantitative literature review (SQLR) is a method for undertaking literature reviews, based on the key principles of rigour, comprehensiveness, and repeatability. The method has 15 steps that begin with ideation and conceptualisation, proceeding to searching databases, coding papers, analysing patterns and trends, and then ...
Systematic = methods to survey literature and select papers to include are explicit and reproducible. 2. Quantitative = measure of the amount (number of papers) of research within different sections of topic. 3. Comprehensive = assesses different combinations of locations, subjects, variables and responses. 4.
Literature reviews are comprehensive summaries and syntheses of the previous research on a given topic. While narrative reviews are common across all academic disciplines, reviews that focus on appraising and synthesizing research evidence are increasingly important in the health and social sciences.. Most evidence synthesis methods use formal and explicit methods to identify, select and ...
Design/methodology/approach. Using a systematic literature review (SLR) method, pertinent journal articles published over the past 3 decades were retrieved and analyzed. Based on the review process, 44 papers were identified and analyzed by publication year, journal distribution, research method, and lead author.
Chapter 2 Quantitative review methods. A systematic review and meta-analysis was conducted based upon a protocol published on the PROSPERO ... and Medical Literature Analysis and Retrieval System Online (MEDLINE) (January 2012 to July 2013). The breadth of the literature identified meant we took a pragmatic approach and limited our search ...
Virtual patients (VPs) are widely used in health professions education. When they are well integrated into curricula, they are considered to be more effective than loosely coupled add-ons. However, it is unclear what constitutes their successful integration. The aim of this study was to identify and synthesise the themes found in the literature that stakeholders perceive as important for ...
It evaluates literature quality, explores research theories, and identifies trends. Findings indicate that most museum visitors hold positive attitudes towards VR, necessitating further research on generational perspectives. Quantitative research methods dominate (77.8%), with 38.9% employing the Technology Acceptance Model (TAM) or its extensions.
The current study followed an explanatory sequential mixed-methods design (Ivankova et al., 2006) in which the quantitative data was analyzed first and then followed by the analysis of qualitative data. The purpose of the study was to investigate the effect of electronic portfolio-based writing portfolios on the writing performance and self ...
Leveraging the structured literature review methodology by Webster and Watson, this comparative study identifies the most pertinent quantitative and qualitative criteria for FL framework users, ensuring a selection of comparison criteria that is both comprehensive and methodically sound, surpassing the scope of similar studies.
Key findings include trends in Muslim religion-related tourism, concepts like experience, satisfaction, and loyalty in religious tourism service quality, and the strong link between trip attraction satisfaction and repeat intention. The paper also discusses quantitative analysis methodology and future research directions.