Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is a Case-Control Study? | Definition & Examples

What Is a Case-Control Study? | Definition & Examples
Published on February 4, 2023 by Tegan George . Revised on June 22, 2023.
A case-control study is an experimental design that compares a group of participants possessing a condition of interest to a very similar group lacking that condition. Here, the participants possessing the attribute of study, such as a disease, are called the “case,” and those without it are the “control.”
It’s important to remember that the case group is chosen because they already possess the attribute of interest. The point of the control group is to facilitate investigation, e.g., studying whether the case group systematically exhibits that attribute more than the control group does.
Table of contents
When to use a case-control study, examples of case-control studies, advantages and disadvantages of case-control studies, other interesting articles, frequently asked questions.
Case-control studies are a type of observational study often used in fields like medical research, environmental health, or epidemiology. While most observational studies are qualitative in nature, case-control studies can also be quantitative , and they often are in healthcare settings. Case-control studies can be used for both exploratory and explanatory research , and they are a good choice for studying research topics like disease exposure and health outcomes.
A case-control study may be a good fit for your research if it meets the following criteria.
- Data on exposure (e.g., to a chemical or a pesticide) are difficult to obtain or expensive.
- The disease associated with the exposure you’re studying has a long incubation period or is rare or under-studied (e.g., AIDS in the early 1980s).
- The population you are studying is difficult to contact for follow-up questions (e.g., asylum seekers).
Retrospective cohort studies use existing secondary research data, such as medical records or databases, to identify a group of people with a common exposure or risk factor and to observe their outcomes over time. Case-control studies conduct primary research , comparing a group of participants possessing a condition of interest to a very similar group lacking that condition in real time.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Case-control studies are common in fields like epidemiology, healthcare, and psychology.
You would then collect data on your participants’ exposure to contaminated drinking water, focusing on variables such as the source of said water and the duration of exposure, for both groups. You could then compare the two to determine if there is a relationship between drinking water contamination and the risk of developing a gastrointestinal illness. Example: Healthcare case-control study You are interested in the relationship between the dietary intake of a particular vitamin (e.g., vitamin D) and the risk of developing osteoporosis later in life. Here, the case group would be individuals who have been diagnosed with osteoporosis, while the control group would be individuals without osteoporosis.
You would then collect information on dietary intake of vitamin D for both the cases and controls and compare the two groups to determine if there is a relationship between vitamin D intake and the risk of developing osteoporosis. Example: Psychology case-control study You are studying the relationship between early-childhood stress and the likelihood of later developing post-traumatic stress disorder (PTSD). Here, the case group would be individuals who have been diagnosed with PTSD, while the control group would be individuals without PTSD.
Case-control studies are a solid research method choice, but they come with distinct advantages and disadvantages.
Advantages of case-control studies
- Case-control studies are a great choice if you have any ethical considerations about your participants that could preclude you from using a traditional experimental design .
- Case-control studies are time efficient and fairly inexpensive to conduct because they require fewer subjects than other research methods .
- If there were multiple exposures leading to a single outcome, case-control studies can incorporate that. As such, they truly shine when used to study rare outcomes or outbreaks of a particular disease .
Disadvantages of case-control studies
- Case-control studies, similarly to observational studies, run a high risk of research biases . They are particularly susceptible to observer bias , recall bias , and interviewer bias.
- In the case of very rare exposures of the outcome studied, attempting to conduct a case-control study can be very time consuming and inefficient .
- Case-control studies in general have low internal validity and are not always credible.
Case-control studies by design focus on one singular outcome. This makes them very rigid and not generalizable , as no extrapolation can be made about other outcomes like risk recurrence or future exposure threat. This leads to less satisfying results than other methodological choices.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
Prevent plagiarism. Run a free check.
A case-control study differs from a cohort study because cohort studies are more longitudinal in nature and do not necessarily require a control group .
While one may be added if the investigator so chooses, members of the cohort are primarily selected because of a shared characteristic among them. In particular, retrospective cohort studies are designed to follow a group of people with a common exposure or risk factor over time and observe their outcomes.
Case-control studies, in contrast, require both a case group and a control group, as suggested by their name, and usually are used to identify risk factors for a disease by comparing cases and controls.
A case-control study differs from a cross-sectional study because case-control studies are naturally retrospective in nature, looking backward in time to identify exposures that may have occurred before the development of the disease.
On the other hand, cross-sectional studies collect data on a population at a single point in time. The goal here is to describe the characteristics of the population, such as their age, gender identity, or health status, and understand the distribution and relationships of these characteristics.
Cases and controls are selected for a case-control study based on their inherent characteristics. Participants already possessing the condition of interest form the “case,” while those without form the “control.”
Keep in mind that by definition the case group is chosen because they already possess the attribute of interest. The point of the control group is to facilitate investigation, e.g., studying whether the case group systematically exhibits that attribute more than the control group does.
The strength of the association between an exposure and a disease in a case-control study can be measured using a few different statistical measures , such as odds ratios (ORs) and relative risk (RR).
No, case-control studies cannot establish causality as a standalone measure.
As observational studies , they can suggest associations between an exposure and a disease, but they cannot prove without a doubt that the exposure causes the disease. In particular, issues arising from timing, research biases like recall bias , and the selection of variables lead to low internal validity and the inability to determine causality.
Sources in this article
We strongly encourage students to use sources in their work. You can cite our article (APA Style) or take a deep dive into the articles below.
George, T. (2023, June 22). What Is a Case-Control Study? | Definition & Examples. Scribbr. Retrieved June 24, 2024, from https://www.scribbr.com/methodology/case-control-study/
Schlesselman, J. J. (1982). Case-Control Studies: Design, Conduct, Analysis (Monographs in Epidemiology and Biostatistics, 2) (Illustrated). Oxford University Press.
Is this article helpful?

Tegan George
Other students also liked, what is an observational study | guide & examples, control groups and treatment groups | uses & examples, cross-sectional study | definition, uses & examples, what is your plagiarism score.
What Is A Case Control Study?
Julia Simkus
Editor at Simply Psychology
BA (Hons) Psychology, Princeton University
Julia Simkus is a graduate of Princeton University with a Bachelor of Arts in Psychology. She is currently studying for a Master's Degree in Counseling for Mental Health and Wellness in September 2023. Julia's research has been published in peer reviewed journals.
Learn about our Editorial Process
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A case-control study is a research method where two groups of people are compared – those with the condition (cases) and those without (controls). By looking at their past, researchers try to identify what factors might have contributed to the condition in the ‘case’ group.
Explanation
A case-control study looks at people who already have a certain condition (cases) and people who don’t (controls). By comparing these two groups, researchers try to figure out what might have caused the condition. They look into the past to find clues, like habits or experiences, that are different between the two groups.
The “cases” are the individuals with the disease or condition under study, and the “controls” are similar individuals without the disease or condition of interest.
The controls should have similar characteristics (i.e., age, sex, demographic, health status) to the cases to mitigate the effects of confounding variables .
Case-control studies identify any associations between an exposure and an outcome and help researchers form hypotheses about a particular population.
Researchers will first identify the two groups, and then look back in time to investigate which subjects in each group were exposed to the condition.
If the exposure is found more commonly in the cases than the controls, the researcher can hypothesize that the exposure may be linked to the outcome of interest.

Figure: Schematic diagram of case-control study design. Kenneth F. Schulz and David A. Grimes (2002) Case-control studies: research in reverse . The Lancet Volume 359, Issue 9304, 431 – 434
Quick, inexpensive, and simple
Because these studies use already existing data and do not require any follow-up with subjects, they tend to be quicker and cheaper than other types of research. Case-control studies also do not require large sample sizes.
Beneficial for studying rare diseases
Researchers in case-control studies start with a population of people known to have the target disease instead of following a population and waiting to see who develops it. This enables researchers to identify current cases and enroll a sufficient number of patients with a particular rare disease.
Useful for preliminary research
Case-control studies are beneficial for an initial investigation of a suspected risk factor for a condition. The information obtained from cross-sectional studies then enables researchers to conduct further data analyses to explore any relationships in more depth.
Limitations
Subject to recall bias.
Participants might be unable to remember when they were exposed or omit other details that are important for the study. In addition, those with the outcome are more likely to recall and report exposures more clearly than those without the outcome.
Difficulty finding a suitable control group
It is important that the case group and the control group have almost the same characteristics, such as age, gender, demographics, and health status.
Forming an accurate control group can be challenging, so sometimes researchers enroll multiple control groups to bolster the strength of the case-control study.
Do not demonstrate causation
Case-control studies may prove an association between exposures and outcomes, but they can not demonstrate causation.
A case-control study is an observational study where researchers analyzed two groups of people (cases and controls) to look at factors associated with particular diseases or outcomes.
Below are some examples of case-control studies:
- Investigating the impact of exposure to daylight on the health of office workers (Boubekri et al., 2014).
- Comparing serum vitamin D levels in individuals who experience migraine headaches with their matched controls (Togha et al., 2018).
- Analyzing correlations between parental smoking and childhood asthma (Strachan and Cook, 1998).
- Studying the relationship between elevated concentrations of homocysteine and an increased risk of vascular diseases (Ford et al., 2002).
- Assessing the magnitude of the association between Helicobacter pylori and the incidence of gastric cancer (Helicobacter and Cancer Collaborative Group, 2001).
- Evaluating the association between breast cancer risk and saturated fat intake in postmenopausal women (Howe et al., 1990).
Frequently asked questions
1. what’s the difference between a case-control study and a cross-sectional study.
Case-control studies are different from cross-sectional studies in that case-control studies compare groups retrospectively while cross-sectional studies analyze information about a population at a specific point in time.
In cross-sectional studies , researchers are simply examining a group of participants and depicting what already exists in the population.
2. What’s the difference between a case-control study and a longitudinal study?
Case-control studies compare groups retrospectively, while longitudinal studies can compare groups either retrospectively or prospectively.
In a longitudinal study , researchers monitor a population over an extended period of time, and they can be used to study developmental shifts and understand how certain things change as we age.
In addition, case-control studies look at a single subject or a single case, whereas longitudinal studies can be conducted on a large group of subjects.
3. What’s the difference between a case-control study and a retrospective cohort study?
Case-control studies are retrospective as researchers begin with an outcome and trace backward to investigate exposure; however, they differ from retrospective cohort studies.
In a retrospective cohort study , researchers examine a group before any of the subjects have developed the disease, then examine any factors that differed between the individuals who developed the condition and those who did not.
Thus, the outcome is measured after exposure in retrospective cohort studies, whereas the outcome is measured before the exposure in case-control studies.
Boubekri, M., Cheung, I., Reid, K., Wang, C., & Zee, P. (2014). Impact of windows and daylight exposure on overall health and sleep quality of office workers: a case-control pilot study. Journal of Clinical Sleep Medicine: JCSM: Official Publication of the American Academy of Sleep Medicine, 10 (6), 603-611.
Ford, E. S., Smith, S. J., Stroup, D. F., Steinberg, K. K., Mueller, P. W., & Thacker, S. B. (2002). Homocyst (e) ine and cardiovascular disease: a systematic review of the evidence with special emphasis on case-control studies and nested case-control studies. International journal of epidemiology, 31 (1), 59-70.
Helicobacter and Cancer Collaborative Group. (2001). Gastric cancer and Helicobacter pylori: a combined analysis of 12 case control studies nested within prospective cohorts. Gut, 49 (3), 347-353.
Howe, G. R., Hirohata, T., Hislop, T. G., Iscovich, J. M., Yuan, J. M., Katsouyanni, K., … & Shunzhang, Y. (1990). Dietary factors and risk of breast cancer: combined analysis of 12 case—control studies. JNCI: Journal of the National Cancer Institute, 82 (7), 561-569.
Lewallen, S., & Courtright, P. (1998). Epidemiology in practice: case-control studies. Community eye health, 11 (28), 57–58.
Strachan, D. P., & Cook, D. G. (1998). Parental smoking and childhood asthma: longitudinal and case-control studies. Thorax, 53 (3), 204-212.
Tenny, S., Kerndt, C. C., & Hoffman, M. R. (2021). Case Control Studies. In StatPearls . StatPearls Publishing.
Togha, M., Razeghi Jahromi, S., Ghorbani, Z., Martami, F., & Seifishahpar, M. (2018). Serum Vitamin D Status in a Group of Migraine Patients Compared With Healthy Controls: A Case-Control Study. Headache, 58 (10), 1530-1540.
Further Information
- Schulz, K. F., & Grimes, D. A. (2002). Case-control studies: research in reverse. The Lancet, 359(9304), 431-434.
- What is a case-control study?
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Case Control Study: Definition, Benefits & Examples
By Jim Frost 2 Comments
What is a Case Control Study?
A case control study is a retrospective, observational study that compares two existing groups. Researchers form these groups based on the existence of a condition in the case group and the lack of that condition in the control group. They evaluate the differences in the histories between these two groups looking for factors that might cause a disease.

By evaluating differences in exposure to risk factors between the case and control groups, researchers can learn which factors are associated with the medical condition.
For example, medical researchers study disease X and use a case-control study design to identify risk factors. They create two groups using available medical records from hospitals. Individuals with disease X are in the case group, while those without it are in the control group. If the case group has more exposure to a risk factor than the control group, that exposure is a potential cause for disease X. However, case-control studies establish only correlation and not causation. Be aware of spurious correlations!
Case-control studies are observational studies because researchers do not control the risk factors—they only observe them. They are retrospective studies because the scientists create the case and control groups after the outcomes for the subjects (e.g., disease vs. no disease) are known.
This post explains the benefits and limitations of case-control studies, controlling confounders, and analyzing and interpreting the results. I close with an example case control study showing how to calculate and interpret the results.
Learn more about Experimental Design: Definition, Types, and Examples .
Related posts : Observational Studies Explained and Control Groups in Experiments
Benefits of a Case Control Study
A case control study is a relatively quick and simple design. They frequently use existing patient data, and the experimenters form the groups after the outcomes are known. Researchers do not conduct an experiment. Instead, they look for differences between the case and control groups that are potential risk factors for the condition. Small groups and individual facilities can conduct case-control studies, unlike other more intensive types of experiments.
Case-control studies are perfect for evaluating outbreaks and rare conditions. Researchers simply need to let a sufficient number of known cases accumulate in an established database. The alternative would be to select a large random sample and hope that the condition afflicts it eventually.
A case control study can provide rapid results during outbreaks where the researchers need quick answers. They are ideal for the preliminary investigation phase, where scientists screen potential risk factors. As such, they can point the way for more thorough, time-consuming, and expensive studies. They are especially beneficial when the current state of science knows little about the connection between risk factors and the medical condition. And when you need to identify potential risk factors quickly!
Cohort studies are another type of observational study that are similar to case-control studies, but there are some important differences. To learn more, read my post about Cohort Studies .
Limitations of a Case Control Study
Because case-control studies are observational, they cannot establish causality and provide lower quality evidence than other experimental designs, such as randomized controlled trials . Additionally, as you’ll see in the next section, this type of study is susceptible to confounding variables unless experimenters correctly match traits between the two groups.
A case-control study typically depends on health records. If the necessary data exist in sources available to the researchers, all is good. However, the investigation becomes more complicated if the data are not readily available.
Case-control studies can incorporate biases from the underlying data sources. For example, researchers frequently obtain patient data from hospital records. The population of hospital patients is likely to differ from the general population. Even the control patients are in the hospital for some reason—they likely have serious health problems. Consequently, the subjects in case-control studies are likely to differ from the general population, which reduces the generalizability of the results.
A case-control study cannot estimate incidence or prevalence rates for the disease. The data from these studies do not allow you to calculate the probability of a new person contracting the condition in a given period nor how common it is in the population. This limitation occurs because case-control studies do not use a representative sample.
Case-control studies cannot determine the time between exposure and onset of the medical condition. In fact, case-control studies cannot reliably assess each subject’s exposure to risk factors over time. Longitudinal studies, such as prospective cohort studies, can better make those types of assessment.
Related post : Causation versus Correlation in Statistics
Use Matching to Control Confounders
Because case-control studies are observational studies, they are particularly vulnerable to confounding variables and spurious correlations . A confounder correlates with both the risk factor and the outcome variable. Because observational studies don’t use random assignment to equalize confounders between the case and control groups, they can become unbalanced and affect the results.
Unfortunately, confounders can be the actual cause of the medical condition rather than the risk factor that the researchers identify. If a case-control study does not account for confounding variables, it can bias the results and make them untrustworthy.
Case-control studies typically use trait matching to control confounders. This technique involves selecting study participants for the case and control groups with similar characteristics, which helps equalize the groups for potential confounders. Equalizing confounders limits their impact on the results.
Ultimately, the goal is to create case and control groups that have equal risks for developing the condition/disease outside the risk factors the researchers are explicitly assessing. Matching facilitates valid comparisons between the two groups because the controls are similar to cases. The researchers use subject-area knowledge to identify characteristics that are critical to match.
Note that you cannot assess matching variables as potential risk factors. You’ve intentionally equalized them across the case and control groups and, consequently, they do not correlate with the condition. Hence, do not use the risk factors you want to evaluate as trait matching variables.
Learn more about confounding variables .
Statistical Analysis of a Case Control Study
Researchers frequently include two controls for each case to increase statistical power for a case-control study. Adding even more controls per case provides few statistical benefits, so studies usually do not use more than a 2:1 control to case ratio.
For statistical results, case-control studies typically produce an odds ratio for each potential risk factor. The equation below shows how to calculate an odds ratio for a case-control study.

Notice how this ratio takes the exposure odds in the case group and divides it by the exposure odds in the control group. Consequently, it quantifies how much higher the odds of exposure are among cases than the controls.
In general, odds ratios greater than one flag potential risk factors because they indicate that exposure was higher in the case group than in the control group. Furthermore, higher ratios signify stronger associations between exposure and the medical condition.
An odds ratio of one indicates that exposure was the same in the case and control groups. Nothing to see here!
Ratios less than one might identify protective factors.
Learn more about Understanding Ratios .
Now, let’s bring this to life with an example!
Example Odds Ratio in a Case-Control Study
The Kent County Health Department in Michigan conducted a case-control study in 2005 for a company lunch that produced an outbreak of vomiting and diarrhea. Out of multiple lunch ingredients, researchers found the following exposure rates for lettuce consumption.
| 53 | 33 | |
| 1 | 7 |
By plugging these numbers into the equation, we can calculate the odds ratio for lettuce in this case-control study.

The study determined that the odds ratio for lettuce is 11.2.
This ratio indicates that those with symptoms were 11.2 times more likely to have eaten lettuce than those without symptoms. These results raise a big red flag for contaminated lettuce being the culprit!
Learn more about Odds Ratios.
Epidemiology in Practice: Case-Control Studies (NIH)
Interpreting Results of Case-Control Studies (CDC)
Share this:

Reader Interactions

January 18, 2022 at 7:56 am
Great post, thanks for writing it!
Is it possible to test an odds ration for statistical significance?

January 18, 2022 at 7:41 pm
Hi Michael,
Thanks! And yes, you can test for significance. To learn more about that, read my post about odds ratios , where I discuss p-values and confidence intervals.
Comments and Questions Cancel reply
Study Design 101: Case Control Study
- Case Report
- Case Control Study
- Cohort Study
- Randomized Controlled Trial
- Practice Guideline
- Systematic Review
- Meta-Analysis
- Helpful Formulas
- Finding Specific Study Types
A study that compares patients who have a disease or outcome of interest (cases) with patients who do not have the disease or outcome (controls), and looks back retrospectively to compare how frequently the exposure to a risk factor is present in each group to determine the relationship between the risk factor and the disease.
Case control studies are observational because no intervention is attempted and no attempt is made to alter the course of the disease. The goal is to retrospectively determine the exposure to the risk factor of interest from each of the two groups of individuals: cases and controls. These studies are designed to estimate odds.
Case control studies are also known as "retrospective studies" and "case-referent studies."
- Good for studying rare conditions or diseases
- Less time needed to conduct the study because the condition or disease has already occurred
- Lets you simultaneously look at multiple risk factors
- Useful as initial studies to establish an association
- Can answer questions that could not be answered through other study designs
Disadvantages
- Retrospective studies have more problems with data quality because they rely on memory and people with a condition will be more motivated to recall risk factors (also called recall bias).
- Not good for evaluating diagnostic tests because it's already clear that the cases have the condition and the controls do not
- It can be difficult to find a suitable control group
Design pitfalls to look out for
Care should be taken to avoid confounding, which arises when an exposure and an outcome are both strongly associated with a third variable. Controls should be subjects who might have been cases in the study but are selected independent of the exposure. Cases and controls should also not be "over-matched."
Is the control group appropriate for the population? Does the study use matching or pairing appropriately to avoid the effects of a confounding variable? Does it use appropriate inclusion and exclusion criteria?
Fictitious Example
There is a suspicion that zinc oxide, the white non-absorbent sunscreen traditionally worn by lifeguards is more effective at preventing sunburns that lead to skin cancer than absorbent sunscreen lotions. A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure. The study involved comparing a group of former lifeguards that had developed cancer on their cheeks and noses (cases) to a group of lifeguards without this type of cancer (controls) and assess their prior exposure to zinc oxide or absorbent sunscreen lotions.
This study would be retrospective in that the former lifeguards would be asked to recall which type of sunscreen they used on their face and approximately how often. This could be either a matched or unmatched study, but efforts would need to be made to ensure that the former lifeguards are of the same average age, and lifeguarded for a similar number of seasons and amount of time per season.
Real-life Examples
Boubekri, M., Cheung, I., Reid, K., Wang, C., & Zee, P. (2014). Impact of windows and daylight exposure on overall health and sleep quality of office workers: a case-control pilot study. Journal of Clinical Sleep Medicine : JCSM : Official Publication of the American Academy of Sleep Medicine, 10 (6), 603-611. https://doi.org/10.5664/jcsm.3780
This pilot study explored the impact of exposure to daylight on the health of office workers (measuring well-being and sleep quality subjectively, and light exposure, activity level and sleep-wake patterns via actigraphy). Individuals with windows in their workplaces had more light exposure, longer sleep duration, and more physical activity. They also reported a better scores in the areas of vitality and role limitations due to physical problems, better sleep quality and less sleep disturbances.
Togha, M., Razeghi Jahromi, S., Ghorbani, Z., Martami, F., & Seifishahpar, M. (2018). Serum Vitamin D Status in a Group of Migraine Patients Compared With Healthy Controls: A Case-Control Study. Headache, 58 (10), 1530-1540. https://doi.org/10.1111/head.13423
This case-control study compared serum vitamin D levels in individuals who experience migraine headaches with their matched controls. Studied over a period of thirty days, individuals with higher levels of serum Vitamin D was associated with lower odds of migraine headache.
Related Formulas
- Odds ratio in an unmatched study
- Odds ratio in a matched study
Related Terms
A patient with the disease or outcome of interest.
Confounding
When an exposure and an outcome are both strongly associated with a third variable.
A patient who does not have the disease or outcome.
Matched Design
Each case is matched individually with a control according to certain characteristics such as age and gender. It is important to remember that the concordant pairs (pairs in which the case and control are either both exposed or both not exposed) tell us nothing about the risk of exposure separately for cases or controls.
Observed Assignment
The method of assignment of individuals to study and control groups in observational studies when the investigator does not intervene to perform the assignment.
Unmatched Design
The controls are a sample from a suitable non-affected population.
Now test yourself!
1. Case Control Studies are prospective in that they follow the cases and controls over time and observe what occurs.
a) True b) False
2. Which of the following is an advantage of Case Control Studies?
a) They can simultaneously look at multiple risk factors. b) They are useful to initially establish an association between a risk factor and a disease or outcome. c) They take less time to complete because the condition or disease has already occurred. d) b and c only e) a, b, and c
Evidence Pyramid - Navigation
- Meta- Analysis
- Case Reports
- << Previous: Case Report
- Next: Cohort Study >>

- Last Updated: Sep 25, 2023 10:59 AM
- URL: https://guides.himmelfarb.gwu.edu/studydesign101

- Himmelfarb Intranet
- Privacy Notice
- Terms of Use
- GW is committed to digital accessibility. If you experience a barrier that affects your ability to access content on this page, let us know via the Accessibility Feedback Form .
- Himmelfarb Health Sciences Library
- 2300 Eye St., NW, Washington, DC 20037
- Phone: (202) 994-2850
- [email protected]
- https://himmelfarb.gwu.edu

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed, case control studies, affiliations.
- 1 University of Nebraska Medical Center
- 2 Spectrum Health/Michigan State University College of Human Medicine
- PMID: 28846237
- Bookshelf ID: NBK448143
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes. The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to the case individuals but do not have the outcome of interest. The researcher then looks at historical factors to identify if some exposure(s) is/are found more commonly in the cases than the controls. If the exposure is found more commonly in the cases than in the controls, the researcher can hypothesize that the exposure may be linked to the outcome of interest.
For example, a researcher may want to look at the rare cancer Kaposi's sarcoma. The researcher would find a group of individuals with Kaposi's sarcoma (the cases) and compare them to a group of patients who are similar to the cases in most ways but do not have Kaposi's sarcoma (controls). The researcher could then ask about various exposures to see if any exposure is more common in those with Kaposi's sarcoma (the cases) than those without Kaposi's sarcoma (the controls). The researcher might find that those with Kaposi's sarcoma are more likely to have HIV, and thus conclude that HIV may be a risk factor for the development of Kaposi's sarcoma.
There are many advantages to case-control studies. First, the case-control approach allows for the study of rare diseases. If a disease occurs very infrequently, one would have to follow a large group of people for a long period of time to accrue enough incident cases to study. Such use of resources may be impractical, so a case-control study can be useful for identifying current cases and evaluating historical associated factors. For example, if a disease developed in 1 in 1000 people per year (0.001/year) then in ten years one would expect about 10 cases of a disease to exist in a group of 1000 people. If the disease is much rarer, say 1 in 1,000,0000 per year (0.0000001/year) this would require either having to follow 1,000,0000 people for ten years or 1000 people for 1000 years to accrue ten total cases. As it may be impractical to follow 1,000,000 for ten years or to wait 1000 years for recruitment, a case-control study allows for a more feasible approach.
Second, the case-control study design makes it possible to look at multiple risk factors at once. In the example above about Kaposi's sarcoma, the researcher could ask both the cases and controls about exposures to HIV, asbestos, smoking, lead, sunburns, aniline dye, alcohol, herpes, human papillomavirus, or any number of possible exposures to identify those most likely associated with Kaposi's sarcoma.
Case-control studies can also be very helpful when disease outbreaks occur, and potential links and exposures need to be identified. This study mechanism can be commonly seen in food-related disease outbreaks associated with contaminated products, or when rare diseases start to increase in frequency, as has been seen with measles in recent years.
Because of these advantages, case-control studies are commonly used as one of the first studies to build evidence of an association between exposure and an event or disease.
In a case-control study, the investigator can include unequal numbers of cases with controls such as 2:1 or 4:1 to increase the power of the study.
Disadvantages and Limitations
The most commonly cited disadvantage in case-control studies is the potential for recall bias. Recall bias in a case-control study is the increased likelihood that those with the outcome will recall and report exposures compared to those without the outcome. In other words, even if both groups had exactly the same exposures, the participants in the cases group may report the exposure more often than the controls do. Recall bias may lead to concluding that there are associations between exposure and disease that do not, in fact, exist. It is due to subjects' imperfect memories of past exposures. If people with Kaposi's sarcoma are asked about exposure and history (e.g., HIV, asbestos, smoking, lead, sunburn, aniline dye, alcohol, herpes, human papillomavirus), the individuals with the disease are more likely to think harder about these exposures and recall having some of the exposures that the healthy controls.
Case-control studies, due to their typically retrospective nature, can be used to establish a correlation between exposures and outcomes, but cannot establish causation . These studies simply attempt to find correlations between past events and the current state.
When designing a case-control study, the researcher must find an appropriate control group. Ideally, the case group (those with the outcome) and the control group (those without the outcome) will have almost the same characteristics, such as age, gender, overall health status, and other factors. The two groups should have similar histories and live in similar environments. If, for example, our cases of Kaposi's sarcoma came from across the country but our controls were only chosen from a small community in northern latitudes where people rarely go outside or get sunburns, asking about sunburn may not be a valid exposure to investigate. Similarly, if all of the cases of Kaposi's sarcoma were found to come from a small community outside a battery factory with high levels of lead in the environment, then controls from across the country with minimal lead exposure would not provide an appropriate control group. The investigator must put a great deal of effort into creating a proper control group to bolster the strength of the case-control study as well as enhance their ability to find true and valid potential correlations between exposures and disease states.
Similarly, the researcher must recognize the potential for failing to identify confounding variables or exposures, introducing the possibility of confounding bias, which occurs when a variable that is not being accounted for that has a relationship with both the exposure and outcome. This can cause us to accidentally be studying something we are not accounting for but that may be systematically different between the groups.
Copyright © 2024, StatPearls Publishing LLC.
PubMed Disclaimer
Conflict of interest statement
Disclosure: Steven Tenny declares no relevant financial relationships with ineligible companies.
Disclosure: Connor Kerndt declares no relevant financial relationships with ineligible companies.
Disclosure: Mary Hoffman declares no relevant financial relationships with ineligible companies.
- Introduction
- Issues of Concern
- Clinical Significance
- Enhancing Healthcare Team Outcomes
- Review Questions
Similar articles
- Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas. Crider K, Williams J, Qi YP, Gutman J, Yeung L, Mai C, Finkelstain J, Mehta S, Pons-Duran C, Menéndez C, Moraleda C, Rogers L, Daniels K, Green P. Crider K, et al. Cochrane Database Syst Rev. 2022 Feb 1;2(2022):CD014217. doi: 10.1002/14651858.CD014217. Cochrane Database Syst Rev. 2022. PMID: 36321557 Free PMC article.
- Epidemiology Of Study Design. Munnangi S, Boktor SW. Munnangi S, et al. 2023 Apr 24. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. 2023 Apr 24. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. PMID: 29262004 Free Books & Documents.
- Risk factors for Kaposi's sarcoma in HIV-positive subjects in Uganda. Ziegler JL, Newton R, Katongole-Mbidde E, Mbulataiye S, De Cock K, Wabinga H, Mugerwa J, Katabira E, Jaffe H, Parkin DM, Reeves G, Weiss R, Beral V. Ziegler JL, et al. AIDS. 1997 Nov;11(13):1619-26. doi: 10.1097/00002030-199713000-00011. AIDS. 1997. PMID: 9365767
- Epidemiology of Kaposi's sarcoma. Beral V. Beral V. Cancer Surv. 1991;10:5-22. Cancer Surv. 1991. PMID: 1821323 Review.
- The epidemiology of classic, African, and immunosuppressed Kaposi's sarcoma. Wahman A, Melnick SL, Rhame FS, Potter JD. Wahman A, et al. Epidemiol Rev. 1991;13:178-99. doi: 10.1093/oxfordjournals.epirev.a036068. Epidemiol Rev. 1991. PMID: 1765111 Review.
- Setia MS. Methodology Series Module 2: Case-control Studies. Indian J Dermatol. 2016 Mar-Apr;61(2):146-51. - PMC - PubMed
- Sedgwick P. Bias in observational study designs: case-control studies. BMJ. 2015 Jan 30;350:h560. - PubMed
- Groenwold RHH, van Smeden M. Efficient Sampling in Unmatched Case-Control Studies When the Total Number of Cases and Controls Is Fixed. Epidemiology. 2017 Nov;28(6):834-837. - PubMed
Publication types
- Search in PubMed
- Search in MeSH
- Add to Search
Related information
Linkout - more resources, full text sources.
- NCBI Bookshelf
Research Materials
- NCI CPTC Antibody Characterization Program
Miscellaneous
- NCI CPTAC Assay Portal

- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
- Search Menu
- Sign in through your institution
- Supplements
- Cohort Profiles
- Education Corner
- Author Guidelines
- Submission Site
- Open Access
- About the International Journal of Epidemiology
- About the International Epidemiological Association
- Editorial Team
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Self-Archiving Policy
- Dispatch Dates
- Contact the IEA
- Journals on Oxford Academic
- Books on Oxford Academic
Article Contents
Introduction, case–control studies in dynamic populations, case–control studies within cohorts, unity of the concept of density sampling from dynamic populations and sampling from cohorts, discussion: differences with classic case–control teaching, and consequences.
- < Previous
Case–control studies: basic concepts
- Article contents
- Figures & tables
- Supplementary Data
Jan P Vandenbroucke, Neil Pearce, Case–control studies: basic concepts, International Journal of Epidemiology , Volume 41, Issue 5, October 2012, Pages 1480–1489, https://doi.org/10.1093/ije/dys147
- Permissions Icon Permissions
The purpose of this article is to present in elementary mathematical and statistical terms a simple way to quickly and effectively teach and understand case–control studies, as they are commonly done in dynamic populations—without using the rare disease assumption. Our focus is on case–control studies of disease incidence (‘incident case–control studies’); we will not consider the situation of case–control studies of prevalent disease, which are published much less frequently.
Readers of the medical literature were once taught that case–control studies are ‘cohort studies in reverse’, in which persons who developed disease during follow-up are compared with persons who did not. In addition, they were told that the odds ratio calculated from case–control studies is an approximation of the risk ratio or rate ratio, but only if the disease is ‘rare’ (say, if <5% of the population develops disease). These notions are no longer compatible with present-day epidemiological theory of case–control studies which is based on ‘density sampling’. Moreover, a recent survey found that the large majority of case–control studies do not sample cases and control subjects from a cohort with fixed membership; rather, they sample from dynamic populations with variable membership. 1 Of all case–control studies involving incident cases, 82% sampled from a dynamic population; only 18% of studies sampled from a cohort, and only some of these may need the ‘rare disease assumption’ (depending on how the control subjects were sampled). Thus, the ‘rare disease assumption’ is not needed for the large majority of published case–control studies. In addition, different assumptions are needed for case–control studies in dynamic populations and those in cohorts to ensure that the odds ratios are estimates of ratios of incidence rates.
The underlying theory for case–control studies in dynamic populations has been developed in epidemiological and statistical journals and textbooks over several decades, 2–19 and its history has been described. 20 Still, the theory is not well known or well understood outside professional epidemiological and statistical circles. Introductory textbooks of epidemiology often fall back on methods of control sampling, which involve the ‘rare disease assumption’ as it was proposed by Cornfield in 1951, 3 because it seems easier to explain. 1 Moreover, several advanced textbooks or articles depict the different ways of sampling cases and control subjects from the point of view of a cohort with fixed membership. 13 , 18 This reinforces the view of case–control studies as constructed within a cohort, even though this applies to only a small minority of published case–control studies.
The purpose of this article is to present in elementary mathematical and statistical terms a simple way to quickly and effectively teach and understand case–control studies as they are commonly done in dynamic populations––without using the rare disease assumption. Our focus is on case–control studies of disease incidence (‘incident case–control studies’); we will not consider the situation of case–control studies of prevalent disease, which are published much less frequently, 1 except in certain situations as discussed by Pearce 21 (e.g. for diseases such as asthma in which it is difficult to identify incident cases).
The theory of case–control studies in dynamic populations cannot be explained before first going back to the calculation of incidence rates and risks in dynamic populations. In a previous article, we have reviewed the demographic concepts that underpin these calculations. 22 In the current article, these concepts will first be applied to case–control studies involving sampling from dynamic populations. Second, we discuss how to teach the theory in the situation of sampling from a cohort. In the third part, it is explained how these two distinct ways of sampling cases and control subjects can be unified conceptually in the proportional hazards model (Cox regression). Finally, we discuss the consequences of this way of teaching case–control studies for understanding the assumptions behind these studies, and for appropriately designing studies. We propose that the explanation of case–control studies within dynamic populations should become the basis for teaching case–control studies, in both introductory and more advanced courses.
Basic teaching
To understand the application of the basic concepts of incidence rate calculations to case–control studies, we start with the demographic perspective of a dynamic population in which we calculate and compare incidence rates of disease. 22
Suppose that investigators are interested in the effect of oral contraceptive use on the incidence of myocardial infarction among women of reproductive age. They might investigate this in a large town in a particular calendar year (we base this example loosely on one of the first case–control studies that investigated this association 23 ). The time-population structure of the study is depicted in Figure 1 .
The underlying dynamic ‘source’ population of a study of myocardial infarction (MI) and oral contraceptive use. The bold undulating lines show the fluctuating number of users and non-users of oral contraceptives in a population that is in a steady state. The finer lines below it depict individuals who enter and leave the populations of users and non-users. Closed circles indicate cases of MI emanating from the population. For users and non-users separately, an incidence rate (IR) of MI can be calculated. The incidence rate ratio (IRR) can be used to compare the incidence of MI between users and non-users. In the description of the example in the text, the time t was set to one calendar year. Figure adapted from Miettinen 9
In Figure 1 , for the sake of simplicity, imagine that, on average, 120 000 young women of reproductive age (between ages 15 and 45 years) who have never had coronary heart disease (CHD), are living in the town, on each day during the calendar year of investigation. This is a dynamic population: each day, new young women will become 15 years old, others will turn 46, some will leave town and others will come to live in the town, some will develop CHD and be replaced by others who do not have the disease and so forth. Such a population can be safely regarded as being ‘in steady state’. The demographic principle of a steady-state population was explained in our previous article; 22 in brief, it assumes that over a small period, e.g. a calendar year, the number of people in a population is approximately constant from day to day because the population is constantly depleted and replenished at about the same rate. It was also explained why this assumption holds, even if the population is not perfectly in a steady state. 22 Thus, we take it that each day of the year, ∼120 000 women of reproductive age, free of clinically recognized CHD, live in the town. Suppose that, on average, 40 000 women use oral contraceptives and 80 000 do not. Again, these are two dynamic subpopulations that can be regarded as being in a steady state. Women start and stop using oral contraceptives for various reasons and switch from use to non-use and back again. As such, in one calendar year, we have 40 000 woman-years of pill use and 80 000 woman-years of non-use, free of CHD.
Suppose that a group of investigators surveys all coronary care units in the town each week to identify all women, aged 15–45 years, admitted with acute myocardial infarction during that period. When a young woman is admitted, the investigators enquire whether she was on the pill––and whether she had previously had a coronary event (if she had, she is excluded from the study). Suppose that, in total, 12 women were admitted for first myocardial infarction during the year of study: eight pill users and four non-users. That produces an incidence rate of 8/40 000 woman-years among pill users and 4/80 000 woman-years among non-users. The ratio of these incidence rates becomes (8/40 000 woman-years)/(4/80 000 woman-years), which is a rate ratio of 4, indicating that women on the pill have an incidence rate of myocardial infarction that is four times that of those not on the pill.
Transformation to a case–control study
In total, 12 cases arise from the population: eight users and four non-users. Those are the potential cases for a case–control study in which the investigators would survey all coronary care units each week of the year. Suppose that the investigators, as their next step, would take a random sample of 600 control subjects from the total source population of the cases (the total of 120 000), by asking 600 women aged 15–45 years, without previous CHD, whether they are ‘on the pill’ at the time the question is asked. Then, on whatever day of the year, this sample of control subjects will include, on average, 200 users and 400 non-users of oral contraceptives. These numbers represent the underlying distribution of woman-years of users and non-users. Together with the cases, this is the complete case–control study (see Table 1 ).
Layout of case-control data sampled from dynamic population: study of occurrence of myocardial infarction in users vs non-users of oral contraceptives, corresponding to Figure 1
| . | Myocardial infarction . | Control subjects . |
|---|---|---|
| Oral contraceptive use | ||
| Yes | 8 | 200 |
| No | 4 | 400 |
| Odds ratio | 4 | |
| . | Myocardial infarction . | Control subjects . |
|---|---|---|
| Oral contraceptive use | ||
| Yes | 8 | 200 |
| No | 4 | 400 |
| Odds ratio | 4 | |
From Table 1 , an odds ratio can be calculated as (8 × 400)/(4 × 200). This exactly equals the ratio of the incidence rates in the underlying population. Algebraically: the incidence rate ratio from the complete dynamic population, which we calculated earlier, can be easily rewritten as (8/4)/(40 000 woman-years/80 000 woman-years). Between parentheses in the numerator of this formula is the number of pill users divided by the number of non-users among all women newly admitted with CHD (= cases in the case–control study). In the denominator, we find the proportion of woman-years on the pill divided by the proportion of woman-years of non-use. It is immediately obvious that—if the steady-state assumption holds—we can estimate the latter proportion directly from the sample of 600 women (= control subjects in case–control study). Among the 600 control subjects, the ratio of exposed to unexposed is expected to be the same as the ratio of the woman-years—except for sampling fluctuations. Thus, what we do in a case–control study is to replace the denominator ratio (40 000 woman-years /80 000 woman-years) by a sample (200/400). We still obtain, on average, the same rate ratio of 4. It follows that to estimate the rate ratio, we do not have to measure, nor to estimate, all the person-years of pill-using and non-using women in town; we can simply determine the ratio of those woman-years by asking a representative sample of women free of CHD from the population from which the cases arise, about their pill use. The complete dynamic population is called the ‘source population’ from which we identify the cases and the sample of control subjects, and the period over which cases and control subjects are identified is the ‘time window’ of observation, also called the ‘risk period’.
The ‘odds ratio’ which is calculated from Table 1 is technically also known as the ‘exposure odds ratio’, as it is the ‘odds of exposure’ in the cases divided by the ‘odds of exposure’ in the controls: (8/4)/(200/400) = 4, the same as the ratio of incidence rates in the whole source population. The great advantage of case–control studies is that we can calculate relative incidences of disease in a population, by collecting all the data for the numerator (by collecting cases in hospitals or registries where they naturally come together), and sampling control subjects from the denominator, i.e. sampling ‘control subjects’ to estimate the relative proportions (exposed vs non-exposed) of the person-years of the exposure of interest in the source population. Thus, one achieves the same result as in a comprehensive population follow-up, at much less expense of time and money. Just imagine the effort of having to do a follow-up study of all 120 000 women of reproductive age in town, also keeping track of when they move in and out of town and constantly updating their oral contraceptive use in a particular calendar year!
Advanced teaching
Cohorts vs dynamic populations.
For researchers who are used to think in terms of clinical cohorts, it can be difficult to understand that populations are not depleted: is it not true that the people with a particular risk factor will develop some disease more often, and thus in the course of time, there will be less of them who are still candidates for developing the disease? That will be true in cohorts because their membership is fixed, but not in dynamic populations. One way to understand this is to think of genetic exposures. People with blood group O develop clotting disorders more frequently, whereas people with blood group A develop more often gastric cancer. However, in a dynamic population, the numbers of people with blood group O or A are not constantly depleted—blood group distribution is fairly constant over time, as new people are born with these blood groups so that an equilibrium is maintained. 22
Another way to understand this concept is to think about an imaginary town and the cases of myocardial infarction that are enrolled in a study. For the aforementioned discussion, we assumed that we were studying all women living in a town during some time over the course of one calendar year (this could be the whole year or a few months). The situation would be entirely different if we restricted our study to all women who lived in the town on the 1 January of that year: then we would only count the myocardial infarctions that happened during this year in women who had been living in town on the 1 January; indeed, the number of women on the pill might decline more than the number of women not on the pill because the myocardial infarctions predominantly occur in the users. That situation would be akin to a clinical cohort study, i.e a study with fixed membership defined by a single common event. 22 However, in a dynamic population, a myocardial infarction that happens in a woman who moved into town during the year also counts in the numerator; she and the other women who move into town replenish the denominator because other women move out. By and large, as with blood groups, the population denominator remains constant in terms of its exposure distributions: the woman-years of oral contraceptive use vs non-use. If the population is truly in steady state, it does not matter when the control subjects are sampled—at the beginning, at the end or at the halfway point of the calendar period (the time window or ‘risk period’).
To refine the concept, the members of a dynamic population do not necessarily have to be present for long periods in the population—as might be surmised from the examples about towns and countries of which one is either an inhabitant or not, and usually for several years. Members of a dynamic population may also switch continuously between being in and out of the population. 22 Take a study on car accidents and mobile phone use by the driver. The risk periods of interest are the periods when people drive. The exposure of interest is phone use. In a case–control study, car accidents are sampled, and it is ascertained (say, via mobile phone operators) whether the driver was phoning at the time of the accident. Control moments might be sampled from the same driver (say, in the previous week) or from other drivers, by sampling other moments of time when they were driving; for each of these control moments, it might be ascertained, via the same mechanism as for the cases, whether they were phoning while driving. These control moments are contrasted with the moment of the accident (the case). If the same driver is used as his or her own control, this type of case–control study is called a ‘case–crossover study’. 24 From the example, it can be understood readily that such a case–control study compares the incidence rate of accidents while driving and phoning vs the incidence rate of accidents while driving and not phoning. 25
What if the exposure distribution of the population is not in steady state?
But what if the exposure distribution in the population is not in steady state? For example, suppose that one wants to investigate in a case–control study whether two different types of oral contraceptives give a different risk of venous thrombosis: ‘third-generation oral contraceptives’ vs ‘second-generation oral contraceptives’ (this was once a real and hotly debated question 26 ). Suppose further that the newer ‘third-generation oral contraceptives’ are strongly marketed, and that their market share clearly increases in the course of the calendar year. That situation is depicted in Figure 2 .
Sampling from the middle of the ‘risk period’ when the exposure distribution is not in steady state. The bold undulating lines show the increasing use of one type of oral contraceptives and the decreasing use of the other type during the time period (risk period). The finer lines below it depict individuals who enter and leave the populations of users of these types of oral contraceptives. Closed circles indicate cases of deep venous thrombosis (DVT) emanating from the population. B and D represent the numbers of users of one type or the other contraceptive at a cross-section in the middle of the time period. Incidence rates (IRs) of DVT can be calculated for both populations separately, and an incidence rate ratio (IRR) can be used to compare these two incidence rates. In a case–control study, B and D are estimated by ‘b’ and ‘d’, the numbers of users of one type or the other type of oral contraceptives in a sample from the source population taken in the middle of the period. The algebraic redrafting of the IRR shows that a ratio of IRs is algebraically equivalent to an ‘exposure odds ratio’ or the ‘cross-product’ that is obtained in a case–control study
There are two solutions:
Sample the control subjects in the middle of the period when the cases accrued, and thereby use the additional assumption that the rise (or fall) of the use of a particular brand of pill is roughly linear over the risk period. Then the control subjects will still represent the average proportion of person-years over the risk period. This is depicted in Figure 2 and is the same solution as is used to calculate person-years (i.e. the denominator) when populations are not in steady state [see previous article on the calculation of incidence rates for explanation]. 22 Alternatively, if one assumes that the incident cases in the dynamic population are evenly spread over time, one might sample control subjects evenly over time.
The more sophisticated solution is the one that researchers often use spontaneously: they sample a (number of) control subject(s) each time there is a case, which amounts to ‘matching on calendar time’. Then the control subject(s) will reflect the underlying population distribution of exposure at each point in time a case occurs, and any assumption about linearity is not needed. This is the most exact solution and is represented in Figure 3 . Matching on calendar time can be done in two ways: (i) invite the control subject(s) around the same calendar date as the case and ask them about their exposure (at that time or at previous times if exposure has a lag time to produce disease); or (ii) if control subjects are invited at a later point in time, present them with an ‘index date’, which is the date as the event of the matching case, and question them and/or measure their exposures for that index date. If control subjects are matched on calendar time, then it is appropriate to take the time matching (and, of course, any other matching factors) into account in the analysis, or at least to check whether it is necessary to control for them.
Case–control sampling in dynamic populations when a control is sampled each time a case occurs: matching on calendar time. Persons move in or out of the population by mechanisms such as birth or death, or move in or out from this population to another. Person-time is indicated by horizontal lines. The time axis is calendar time. The sampling of the control subjects is ‘matched on calendar time’: each time a case occurs, one or more control subjects are sampled. Cases and control subjects can be either exposed or unexposed (not shown here). A person who will become a case can be a control subject earlier, and multiple control subjects or even a variable number of control subjects can be drawn for each case
Hospital-based case–control studies
In most examples presented earlier, the patients are assumed to be sampled from a defined geographical population (via disease registries or by having access to all hospitals of some region), and control subjects are sampled from the underlying dynamic population of this geographical area. If cases from a case–control investigation are sampled from one or more hospitals that do not reflect a well-defined geographic population, still each hospital has a ‘catchment population’, consisting of the patients who will be admitted to that hospital when they develop a particular disease. Such a catchment population can be seen as a dynamic population, with inflow and outflow depending on patient and referring doctor preferences, religious or insurance affiliations, or on the reputation of a particular hospital for particular diseases and so forth. To obtain control subjects for such cases, the investigator should consider patients who are admitted to the same hospital and come from the same catchment population—meaning that if they had developed the case disease, they would have been admitted to that same hospital. This approach obviously has some risks in that the control disease may be associated with the exposure that one wants to study; that risk can (it is hoped) be minimized by using a mix of control diseases, none of which is known to be associated with the exposure under study. 27 Still, the principle of sampling control subjects from a dynamic population remains the same, whether the controls are population-based or hospital-based.
The early case–control study on oral contraceptives and myocardial infarction, which inspired the example presented earlier, sampled cases from a number of coronary care units that were surveyed in one geographically defined hospital area in the UK; for each case interviewed, three women of the same age who were discharged after some acute or elective medical or surgical condition were similarly interviewed about their use of oral contraceptives. 23 Likewise, the first case–control studies on smoking and lung cancer were hospital-based, and control subjects were non-cancer patients being present in the same wards or the same hospital as the lung cancer patients. 2 , 28
Doing a case–control study by sampling from a cohort with fixed membership is relatively rare—a recent survey found that it only occurs in 18% of published case–control studies. 1 It is mostly done when investigators have data available from a cohort, and when it is too expensive to go back and assess the exposures of everybody in the cohort. For example, in an occupational cohort study, personnel records may be available for all cohort members from date of employment, but it may take a considerable amount of work to assess these work histories and estimate cumulative exposures to particular chemicals, whether by using a job-exposure matrix or by an expert panel assessment. 29
Another example is the ‘re-use’ of data or samples from a randomized controlled trial (RCT) for a subsequent investigation. For example, the data from the ‘Physician’s Health Study’ 30 were re-used several years after the trial was finished for a new genetic case–control study; baseline blood samples of participants who developed cardiovascular end points in the trial were used, as were blood samples of matched participants in the trial who remained free of those diseases, and the frequency of one genetic factor (Factor V Leiden) was compared between these cases and control subjects. This investigation thereby considered the trial data as a single cohort in which new exposures were assessed, irrespective of the original randomization.
Figure 4 depicts a cohort with fixed membership from time 0. The cases accrue in the course of the follow-up in the exposed and unexposed part of the cohort. The available cohort data may only relate to exposure status at baseline (as in the aforementioned RCT example), but may also indicate changes in exposure over time, for example, if repeated measurements were done in the cohort study, or if time-related exposure information can be assessed from personnel records, prescribing records or other sources (as in the occupational example).
| Measure . | Definition . | Alternative formulation . |
|---|---|---|
| Odds ratio under exclusive sampling | ||
| Risk ratio under inclusive sampling |
Figure refers to methods 1 and 2 in text under subheading ‘Case–control studies within cohorts’, and is adapted from Rodrigues et al. [13] and Szklo and Nieto [18]
For each case, one or more control subjects are selected from the overall cohort, and the exposure statuses of the case and control subjects are determined at the time they are sampled. There are three options to sample control subjects: 12 , 13 , 18
As in the aforementioned RCT example, investigators often sample control subjects from the people who have still not developed the disease of interest at the end of follow-up (this is termed ‘cumulative incidence sampling’ or ‘exclusive sampling’), and exposure status at beginning of follow-up is used for these cases and controls. As shown algebraically in many textbooks, in that situation, the odds ratio is exactly the same (on average) as the corresponding odds ratio from the full cohort study, and this will approximate the risk ratio or rate ratio (in the full cohort study) only if the disease is rare (say, <5% of exposed and non-exposed develop the disease). This is the ‘rare disease assumption’, as historically first proposed by Cornfield in 1951. 3 It can be seen from Figure 4 that if the disease is rare, even in the exposed (sub)cohort, the ratio of people with and without exposure among those without disease at the end of the follow-up will remain about the same as at the beginning of the follow-up, which is why the ‘rare disease assumption’ works.
An imaginative solution, first proposed by Kupper et al. , 8 is to sample control subjects from all those in the cohort at the beginning of follow-up instead of at the end (‘case-cohort’ or ‘inclusive sampling’). At the beginning of the follow-up, all persons are still disease free (if they are not, then they would not have been included in the cohort). Then, the control subjects reflect the proportion exposed among the source population at the start of follow-up. Some of the control subjects who are sampled at baseline may become cases during follow-up. This seems strange at first sight, but it is not: if in a cohort study or an RCT, the risk is calculated, one uses all persons developing a disease outcome in the numerator, and divides by the denominator, which consists of all people who were present at start of follow-up, including those who will later turn up in the numerator. As can be seen from Figure 4 , sampling from the persons present at the beginning of the follow-up makes the odds ratio from the case–control study exactly the same (on average) as the risk ratio from the full cohort study. This can be understood most easily if one imagines taking a control sample of 100%, that is, all persons present at the beginning: then the odds ratio in the case–control study will be exactly the same as the risk ratio from the cohort study. Next, if one imagines taking a 50% sample for the control subjects, the odds ratio will remain the same (on average). One complication with this method is the calculation of the standard error of the odds ratio, as some persons are both cases and control subjects; different solutions exist. 31 A further complication is that, just as with the estimation of risks (which this sampling scheme corresponds to), losses to follow-up for other reasons than developing the disease that is studied are not easily taken into account; such losses to follow-up may produce bias if they are substantial and differ between exposed and unexposed.
The third option is to sample control subjects longitudinally throughout the risk period (i.e. not just at the beginning or just at the end). Throughout the follow-up of a cohort, the numbers of both exposed and unexposed persons who are free of disease will decrease, and people may be lost to follow-up for other reasons. Moreover, persons may move between exposure categories. The ‘royal road’ is to sample one or more control subjects at each point in time when a case occurs (‘density sampling’, ‘risk-set sampling’ or ‘concurrent sampling’) and determine the exposure status of cases and control subjects at that point in time. This is depicted in Figure 5 . By this sampling approach, the odds ratio from the case–control study will estimate the rate ratio from the cohort study. This is the equivalent of ‘matching on time’ in dynamic populations. This approach is most correct theoretically, but can only be used for cohorts when one has information about disease status of all persons at regular intervals during follow-up (e.g. when cancer incidence or mortality data are available over time).
Third method of sampling from a cohort: longitudinal sampling, also called concurrent sampling, density sampling or risk-set sampling. Persons start follow-up at inclusion in the cohort (e.g. date of surgery) and are followed until either end point occurs (person becomes a case), or the last calendar day of the study. Persons are indicated by fine lines from start of follow-up onwards. The time axis is follow-up time from inclusion (time 0). The longest period of follow-up is by persons who enter the cohort on the calendar day that the study starts; persons entering later will have shorter follow-up because they will be withdrawn from the study at the last calendar day of the study. Cases and control subjects can be either exposed or non-exposed (not shown here). A person who will become a case can be a control subject earlier, and multiple control subjects, or even a variable number of control subjects, can be drawn for each case. In text, see method 3, under subheading ‘Case–control studies within cohorts’
The first solution corresponds to the original theory proposed by Cornfield, 3 and requires the ‘rare disease assumption’ if the goal is to estimate rate ratio or risk ratios; it was the most frequently used method in case–control studies within cohorts in the past—and that approach was used in almost all case–control studies based on cohorts that were identified in the review by Knol et al. 1 Solution 2 still pertains to cohort thinking, but has an imaginative solution to calculate risk ratios; it is often called a ‘case–cohort’ study, and is particularly useful in studies in which a single control sample can be used for multiple case–control studies of various outcomes. Solution 3 is the more sophisticated development in case–control theory, in which the case–control odds ratio estimates the rate ratio from the cohort population over the follow-up period without the need for any rare disease assumption. 10 , 11 However, it is used relatively rarely. 1
A note about terminology: the term ‘nested case–control studies’ seems to be mostly used to denote case–control studies within cohorts which use the third sampling option. However, it is sometimes loosely used to denote all types of case–control sampling within a cohort.
The last method of sampling (method 3) immediately points to a conceptual unity of ‘incidence density sampling’ or ‘density sampling’ in cohorts and in dynamic populations. This was described by Prentice and Breslow in 1978 10 and expanded by Greenland and Thomas in 1982. 11 It can be grasped intuitively by comparing Figures 3 and 5 . The basis of the conceptual unity is that person-years can be calculated from cohorts and from dynamic populations, as was explained in our earlier article. 22
In a case–control study in a dynamic population, investigators often use matching on calendar time spontaneously (a control is chosen each time a case occurs), which is an ideal way of sampling, as it produces an odds ratio that directly estimates the incidence rate ratio, as in Figure 3 . In cohorts, however, one has to use sampling strategy 3, presented earlier, to estimate the incidence rate ratio, as in Figure 5 . The latter necessitates advanced insight and is used infrequently. In advanced textbooks, the ‘matching on time’ in dynamic populations and the ‘concurrent sampling’ in cohorts are often mentioned together as ‘density sampling’. This is theoretically correct, although it obscures the practicalities of the different sampling options.
‘Density sampling’ or ‘risk-set sampling’ from a cohort (i.e. the purer form of sampling of aforementioned strategy 3) involves sampling control subjects from the risk sets that are used in the corresponding Cox proportional hazards model. 10 , 11 A ‘hazard’ or ‘hazard rate’ is the name used in statistics for a peculiar form of ‘incidence rate’, wherein the duration of the follow-up approaches the limit of zero and becomes infinitesimally small; it is also called an ‘instantaneous hazard’. 22 When follow-up time is small, there is no numerical difference between risks and incidence rates. 22 Intuitively, a proportional hazards model in a follow-up analysis of a cohort can be understood as comparing the exposure odds of all successive cases at each point in time with those of the non-cases who are still at risk at that point in time (some of whom may become cases later), that is, the ‘risk set’. The exposure odds ratio or hazard ratio is then averaged over all of these comparisons, assuming it to be constant. Thus, a Cox proportional hazards model in a cohort becomes conceptually similar to a study that is ‘matched’ on time with a ‘variable control-to-case-ratio’ in a dynamic population. The estimation of the proportional hazard in a Cox model can be seen as an average of odds ratios over several risk sets; as the follow-up time in each risk set is small (say, the day of occurrence of the case disease), the odds ratios directly translate to relative risks and incidence rates, for reasons explained in the article on incidence calculations in dynamic populations. 21 , 22
The main difference between the approach we have described in this paper and the classic view of case–control studies as a ‘cohort study in reverse’ is that the dynamic population view reflects how the large majority of case–control studies are actually done. They are not done within cohorts, neither real nor imaginary. Rather, most case–control studies have an underlying population that is dynamic: for example, the geographically defined source population of a disease registry, the catchment areas of a hospital region or people who are driving.
The first case–control studies on smoking and lung cancer were done using cases and control subjects admitted to hospital from vaguely defined catchment areas. 2 , 28 Doll and Hill showed in the discussion of their original case–control study on smoking and lung cancer how one might calculate back to the general population, 2 as they assumed that they had sampled from that population—an insight that was far ahead of their time because it did not need the ‘rare disease assumption’. Although it originated during the period when Cornfield proposed his ‘rare disease assumption’, Doll and Hill’s solution was largely forgotten. Only occasionally does one read back-calculations from case–control studies to the background or source population, perhaps because such back-calculations have intricacies of their own, for example, in the case of matching. 32
An important consequence of primarily teaching case–control studies in dynamic populations, without the rare disease assumption, is that the real assumptions that are necessary for the majority of case–control studies become clear: either the exposure distribution should be in steady state in the dynamic population, or sampling of control subjects should be matched on time in a dynamic population (or equivalently, concurrent in the follow-up of a cohort).
An often-heard precept to guide the design of case–control studies is ‘Think of an imaginary randomized trial when planning your case–control study’. This gives the impression of automatically assuming a cohort, as all randomized trials are cohorts with a fixed membership. However, randomized trials can be done equally well on dynamic populations—public health interventions are often on dynamic populations. When the intervention or the exposure is studied in a case–control study with an underlying dynamic population, design features can be construed that are impossible or difficult in cohorts. For example, a dynamic population free of other key risk factors can be proposed: in a case–control study of the risk of oral contraceptives and venous thrombosis, an investigator might stipulate a dynamic population that has neither major surgery nor plaster casts after breaking legs and so forth—thus limiting the study to ‘idiopathic cases’. That would be difficult in a cohort; for example, in an imaginary randomized trial on oral contraceptives, wherein the outcome would be venous thrombosis, it would seem strange to truncate follow-up at the time of major surgery or plaster cast. In a dynamic population, however, the population is constantly renewed, and this exclusion comes naturally and may have advantages in attributing causality because other major risk factors for the outcome are excluded.
It should be emphasized that when cases and control subjects are selected from a dynamic population (or by risk-set sampling from a cohort), exposures do not need to be assessed solely at the time cases and control subjects are selected (e.g. ‘current use’ of oral contraceptives). In many circumstances, investigators need information on the duration of exposure and/or cumulative exposure. For example, in studies of smoking, the effect on lung cancer only becomes clear after several years. In contrast, the cardiovascular adverse effects of hormone replacement therapy may be limited to the first year of use, so recent exposure is most relevant. Recent and historical exposures can be assessed by a variety of methods in case–control studies, ranging from subjective (e.g. questionnaires) to more objective methods (e.g. birth records, pharmacy records and work histories combined with historical exposure monitoring data). The exposure definition can be easily adapted, by defining as many time windows of exposure as is deemed necessary, for recent and for long-term exposure, because there is a continuous turnover between these categories over time in the underlying population.
In summary, case–control studies with incident cases can be conducted in two contexts—dynamic populations and cohorts—of which the first is the most commonly used 1 because it comes naturally to most investigations. This method should become the basis of teaching case–control studies—in both introductory and more advanced courses:
Case–control studies can be conducted in a dynamic population, and the resulting odds ratio directly estimates the rate ratio from this dynamic population, provided that the control subjects represent the source population’s distribution of person-time of exposure over the risk period. This can be achieved either by matching on time or by selecting control subjects more loosely from the same period, if the population is judged to be in steady state for the exposure(s) and other variables of interest.
Case–control studies can also be conducted within a cohort; in this situation, control subjects can be sampled in three different ways, and the resulting odds ratio can estimate the odds ratio, risk ratio or rate ratio from the corresponding full cohort analysis. 21 Because such case–control studies are a minority, and the need for the rare disease assumption only applies for one method of sampling in such studies, they should not be made central to the basic teaching of case–control studies.
Jan P Vandenbroucke is an Academy Professor of the Royal Netherlands Academy of Arts and Sciences. The center for Public Health research is supported by a Programme Grant from the Health Research Council of New Zealand.
Conflict of interest: None declared.
Google Scholar
Google Preview
- steady state
- oral contraceptives
- mathematics
- rare diseases
| Month: | Total Views: |
|---|---|
| January 2017 | 94 |
| February 2017 | 445 |
| March 2017 | 229 |
| April 2017 | 56 |
| May 2017 | 246 |
| June 2017 | 145 |
| July 2017 | 112 |
| August 2017 | 113 |
| September 2017 | 191 |
| October 2017 | 254 |
| November 2017 | 237 |
| December 2017 | 642 |
| January 2018 | 808 |
| February 2018 | 822 |
| March 2018 | 1,019 |
| April 2018 | 1,157 |
| May 2018 | 980 |
| June 2018 | 798 |
| July 2018 | 560 |
| August 2018 | 1,048 |
| September 2018 | 1,034 |
| October 2018 | 970 |
| November 2018 | 878 |
| December 2018 | 564 |
| January 2019 | 580 |
| February 2019 | 817 |
| March 2019 | 952 |
| April 2019 | 947 |
| May 2019 | 980 |
| June 2019 | 583 |
| July 2019 | 531 |
| August 2019 | 460 |
| September 2019 | 710 |
| October 2019 | 704 |
| November 2019 | 560 |
| December 2019 | 446 |
| January 2020 | 485 |
| February 2020 | 580 |
| March 2020 | 489 |
| April 2020 | 405 |
| May 2020 | 395 |
| June 2020 | 532 |
| July 2020 | 404 |
| August 2020 | 442 |
| September 2020 | 561 |
| October 2020 | 660 |
| November 2020 | 483 |
| December 2020 | 422 |
| January 2021 | 453 |
| February 2021 | 443 |
| March 2021 | 565 |
| April 2021 | 503 |
| May 2021 | 465 |
| June 2021 | 330 |
| July 2021 | 310 |
| August 2021 | 321 |
| September 2021 | 574 |
| October 2021 | 564 |
| November 2021 | 387 |
| December 2021 | 344 |
| January 2022 | 427 |
| February 2022 | 501 |
| March 2022 | 500 |
| April 2022 | 451 |
| May 2022 | 488 |
| June 2022 | 319 |
| July 2022 | 291 |
| August 2022 | 289 |
| September 2022 | 440 |
| October 2022 | 571 |
| November 2022 | 461 |
| December 2022 | 377 |
| January 2023 | 380 |
| February 2023 | 359 |
| March 2023 | 415 |
| April 2023 | 460 |
| May 2023 | 414 |
| June 2023 | 329 |
| July 2023 | 325 |
| August 2023 | 332 |
| September 2023 | 483 |
| October 2023 | 647 |
| November 2023 | 475 |
| December 2023 | 370 |
| January 2024 | 673 |
| February 2024 | 502 |
| March 2024 | 708 |
| April 2024 | 530 |
| May 2024 | 563 |
| June 2024 | 360 |
Email alerts
Citing articles via, looking for your next opportunity.
- About International Journal of Epidemiology
- Recommend to your Library
Affiliations
- Online ISSN 1464-3685
- Copyright © 2024 International Epidemiological Association
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Quantitative study designs: Case Control
Quantitative study designs.
- Introduction
- Cohort Studies
- Randomised Controlled Trial
Case Control
- Cross-Sectional Studies
- Study Designs Home
In a Case-Control study there are two groups of people: one has a health issue (Case group), and this group is “matched” to a Control group without the health issue based on characteristics like age, gender, occupation. In this study type, we can look back in the patient’s histories to look for exposure to risk factors that are common to the Case group, but not the Control group. It was a case-control study that demonstrated a link between carcinoma of the lung and smoking tobacco . These studies estimate the odds between the exposure and the health outcome, however they cannot prove causality. Case-Control studies might also be referred to as retrospective or case-referent studies.
Stages of a Case-Control study
This diagram represents taking both the case (disease) and the control (no disease) groups and looking back at their histories to determine their exposure to possible contributing factors. The researchers then determine the likelihood of those factors contributing to the disease.
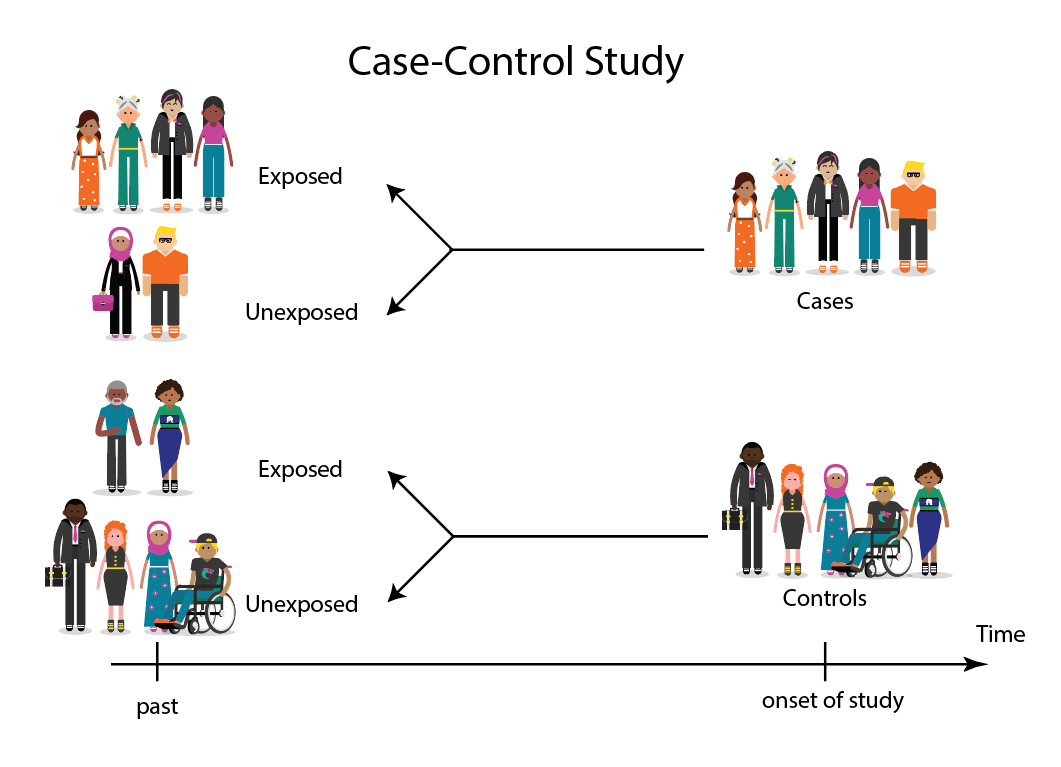
(FOR ACCESSIBILITY: A case control study is likely to show that most, but not all exposed people end up with the health issue, and some unexposed people may also develop the health issue)
Which Clinical Questions does Case-Control best answer?
Case-Control studies are best used for Prognosis questions.
For example: Do anticholinergic drugs increase the risk of dementia in later life? (See BMJ Case-Control study Anticholinergic drugs and risk of dementia: case-control study )
What are the advantages and disadvantages to consider when using Case-Control?
* Confounding occurs when the elements of the study design invalidate the result. It is usually unintentional. It is important to avoid confounding, which can happen in a few ways within Case-Control studies. This explains why it is lower in the hierarchy of evidence, superior only to Case Studies.
What does a strong Case-Control study look like?
A strong study will have:
- Well-matched controls, similar background without being so similar that they are likely to end up with the same health issue (this can be easier said than done since the risk factors are unknown).
- Detailed medical histories are available, reducing the emphasis on a patient’s unreliable recall of their potential exposures.
What are the pitfalls to look for?
- Poorly matched or over-matched controls. Poorly matched means that not enough factors are similar between the Case and Control. E.g. age, gender, geography. Over-matched conversely means that so many things match (age, occupation, geography, health habits) that in all likelihood the Control group will also end up with the same health issue! Either of these situations could cause the study to become ineffective.
- Selection bias: Selection of Controls is biased. E.g. All Controls are in the hospital, so they’re likely already sick, they’re not a true sample of the wider population.
- Cases include persons showing early symptoms who never ended up having the illness.
Critical appraisal tools
To assist with critically appraising case control studies there are some tools / checklists you can use.
CASP - Case Control Checklist
JBI – Critical appraisal checklist for case control studies
CEBMA – Centre for Evidence Based Management – Critical appraisal questions (focus on leadership and management)
STROBE - Observational Studies checklists includes Case control
SIGN - Case-Control Studies Checklist
Real World Examples
Smoking and carcinoma of the lung; preliminary report
- Doll, R., & Hill, A. B. (1950). Smoking and carcinoma of the lung; preliminary report. British Medical Journal , 2 (4682), 739–748. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2038856/
- Key Case-Control study linking tobacco smoking with lung cancer
- Notes a marked increase in incidence of Lung Cancer disproportionate to population growth.
- 20 London Hospitals contributed current Cases of lung, stomach, colon and rectum cancer via admissions, house-physician and radiotherapy diagnosis, non-cancer Controls were selected at each hospital of the same-sex and within 5 year age group of each.
- 1732 Cases and 743 Controls were interviewed for social class, gender, age, exposure to urban pollution, occupation and smoking habits.
- It was found that continued smoking from a younger age and smoking a greater number of cigarettes correlated with incidence of lung cancer.
Anticholinergic drugs and risk of dementia: case-control study
- Richardson, K., Fox, C., Maidment, I., Steel, N., Loke, Y. K., Arthur, A., . . . Savva, G. M. (2018). Anticholinergic drugs and risk of dementia: case-control study. BMJ , 361, k1315. Retrieved from http://www.bmj.com/content/361/bmj.k1315.abstract .
- A recent study linking the duration and level of exposure to Anticholinergic drugs and subsequent onset of dementia.
- Anticholinergic Cognitive Burden (ACB) was estimated in various drugs, the higher the exposure (measured as the ACB score) the greater likeliness of onset of dementia later in life.
- Antidepressant, urological, and antiparkinson drugs with an ACB score of 3 increased the risk of dementia. Gastrointestinal drugs with an ACB score of 3 were not strongly linked with onset of dementia.
- Tricyclic antidepressants such as Amitriptyline have an ACB score of 3 and are an example of a common area of concern.
Omega-3 deficiency associated with perinatal depression: Case-Control study
- Rees, A.-M., Austin, M.-P., Owen, C., & Parker, G. (2009). Omega-3 deficiency associated with perinatal depression: Case control study. Psychiatry Research , 166(2), 254-259. Retrieved from http://www.sciencedirect.com/science/article/pii/S0165178107004398 .
- During pregnancy women lose Omega-3 polyunsaturated fatty acids to the developing foetus.
- There is a known link between Omgea-3 depletion and depression
- Sixteen depressed and 22 non-depressed women were recruited during their third trimester
- High levels of Omega-3 were associated with significantly lower levels of depression.
- Women with low levels of Omega-3 were six times more likely to be depressed during pregnancy.
References and Further Reading
Doll, R., & Hill, A. B. (1950). Smoking and carcinoma of the lung; preliminary report. British Medical Journal, 2(4682), 739–748. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2038856/
Greenhalgh, Trisha. How to Read a Paper: the Basics of Evidence-Based Medicine, John Wiley & Sons, Incorporated, 2014. ProQuest Ebook Central, http://ebookcentral.proquest.com/lib/deakin/detail.action?docID=1642418 .
Himmelfarb Health Sciences Library. (2019). Study Design 101: Case-Control Study. Retrieved from https://himmelfarb.gwu.edu/tutorials/studydesign101/casecontrols.cfm
Hoffmann, T., Bennett, S., & Del Mar, C. (2017). Evidence-Based Practice Across the Health Professions (Third edition. ed.): Elsevier.
Lewallen, S., & Courtright, P. (1998). Epidemiology in practice: case-control studies. Community Eye Health, 11(28), 57. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1706071/
Pelham, B. W. a., & Blanton, H. (2013). Conducting research in psychology : measuring the weight of smoke /Brett W. Pelham, Hart Blanton (Fourth edition. ed.): Wadsworth Cengage Learning.
Rees, A.-M., Austin, M.-P., Owen, C., & Parker, G. (2009). Omega-3 deficiency associated with perinatal depression: Case control study. Psychiatry Research, 166(2), 254-259. Retrieved from http://www.sciencedirect.com/science/article/pii/S0165178107004398
Richardson, K., Fox, C., Maidment, I., Steel, N., Loke, Y. K., Arthur, A., … Savva, G. M. (2018). Anticholinergic drugs and risk of dementia: case-control study. BMJ, 361, k1315. Retrieved from http://www.bmj.com/content/361/bmj.k1315.abstract
Statistics How To. (2019). Case-Control Study: Definition, Real Life Examples. Retrieved from https://www.statisticshowto.com/case-control-study/
- << Previous: Randomised Controlled Trial
- Next: Cross-Sectional Studies >>
- Last Updated: Jun 13, 2024 10:34 AM
- URL: https://deakin.libguides.com/quantitative-study-designs
- En español – ExME
- Em português – EME
Case-control and Cohort studies: A brief overview
Posted on 6th December 2017 by Saul Crandon

Introduction
Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence . These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as randomised controlled trials, they can provide strong evidence if designed appropriately.
Case-control studies
Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups. See Figure 1 for a pictorial representation of a case-control study design. This can suggest associations between the risk factor and development of the disease in question, although no definitive causality can be drawn. The main outcome measure in case-control studies is odds ratio (OR) .
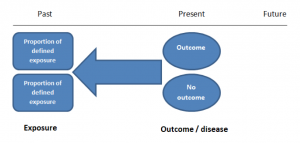
Figure 1. Case-control study design.
Cases should be selected based on objective inclusion and exclusion criteria from a reliable source such as a disease registry. An inherent issue with selecting cases is that a certain proportion of those with the disease would not have a formal diagnosis, may not present for medical care, may be misdiagnosed or may have died before getting a diagnosis. Regardless of how the cases are selected, they should be representative of the broader disease population that you are investigating to ensure generalisability.
Case-control studies should include two groups that are identical EXCEPT for their outcome / disease status.
As such, controls should also be selected carefully. It is possible to match controls to the cases selected on the basis of various factors (e.g. age, sex) to ensure these do not confound the study results. It may even increase statistical power and study precision by choosing up to three or four controls per case (2).
Case-controls can provide fast results and they are cheaper to perform than most other studies. The fact that the analysis is retrospective, allows rare diseases or diseases with long latency periods to be investigated. Furthermore, you can assess multiple exposures to get a better understanding of possible risk factors for the defined outcome / disease.
Nevertheless, as case-controls are retrospective, they are more prone to bias. One of the main examples is recall bias. Often case-control studies require the participants to self-report their exposure to a certain factor. Recall bias is the systematic difference in how the two groups may recall past events e.g. in a study investigating stillbirth, a mother who experienced this may recall the possible contributing factors a lot more vividly than a mother who had a healthy birth.
A summary of the pros and cons of case-control studies are provided in Table 1.
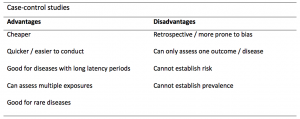
Table 1. Advantages and disadvantages of case-control studies.
Cohort studies
Cohort studies can be retrospective or prospective. Retrospective cohort studies are NOT the same as case-control studies.
In retrospective cohort studies, the exposure and outcomes have already happened. They are usually conducted on data that already exists (from prospective studies) and the exposures are defined before looking at the existing outcome data to see whether exposure to a risk factor is associated with a statistically significant difference in the outcome development rate.
Prospective cohort studies are more common. People are recruited into cohort studies regardless of their exposure or outcome status. This is one of their important strengths. People are often recruited because of their geographical area or occupation, for example, and researchers can then measure and analyse a range of exposures and outcomes.
The study then follows these participants for a defined period to assess the proportion that develop the outcome/disease of interest. See Figure 2 for a pictorial representation of a cohort study design. Therefore, cohort studies are good for assessing prognosis, risk factors and harm. The outcome measure in cohort studies is usually a risk ratio / relative risk (RR).
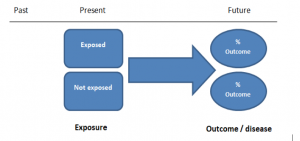
Figure 2. Cohort study design.
Cohort studies should include two groups that are identical EXCEPT for their exposure status.
As a result, both exposed and unexposed groups should be recruited from the same source population. Another important consideration is attrition. If a significant number of participants are not followed up (lost, death, dropped out) then this may impact the validity of the study. Not only does it decrease the study’s power, but there may be attrition bias – a significant difference between the groups of those that did not complete the study.
Cohort studies can assess a range of outcomes allowing an exposure to be rigorously assessed for its impact in developing disease. Additionally, they are good for rare exposures, e.g. contact with a chemical radiation blast.
Whilst cohort studies are useful, they can be expensive and time-consuming, especially if a long follow-up period is chosen or the disease itself is rare or has a long latency.
A summary of the pros and cons of cohort studies are provided in Table 2.
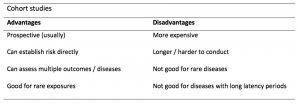
The Strengthening of Reporting of Observational Studies in Epidemiology Statement (STROBE)
STROBE provides a checklist of important steps for conducting these types of studies, as well as acting as best-practice reporting guidelines (3). Both case-control and cohort studies are observational, with varying advantages and disadvantages. However, the most important factor to the quality of evidence these studies provide, is their methodological quality.
- Song, J. and Chung, K. Observational Studies: Cohort and Case-Control Studies . Plastic and Reconstructive Surgery.  2010 Dec;126(6):2234-2242.
- Ury HK. Efficiency of case-control studies with multiple controls per case: Continuous or dichotomous data . Biometrics . 1975 Sep;31(3):643–649.
- von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP; STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies.  Lancet 2007 Oct;370(9596):1453-14577. PMID: 18064739.

Saul Crandon
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on Case-control and Cohort studies: A brief overview

Very well presented, excellent clarifications. Has put me right back into class, literally!

Very clear and informative! Thank you.

very informative article.

Thank you for the easy to understand blog in cohort studies. I want to follow a group of people with and without a disease to see what health outcomes occurs to them in future such as hospitalisations, diagnoses, procedures etc, as I have many health outcomes to consider, my questions is how to make sure these outcomes has not occurred before the “exposure disease”. As, in cohort studies we are looking at incidence (new) cases, so if an outcome have occurred before the exposure, I can leave them out of the analysis. But because I am not looking at a single outcome which can be checked easily and if happened before exposure can be left out. I have EHR data, so all the exposure and outcome have occurred. my aim is to check the rates of different health outcomes between the exposed)dementia) and unexposed(non-dementia) individuals.

Very helpful information

Thanks for making this subject student friendly and easier to understand. A great help.

Thanks a lot. It really helped me to understand the topic. I am taking epidemiology class this winter, and your paper really saved me.
Happy new year.

Wow its amazing n simple way of briefing ,which i was enjoyed to learn this.its very easy n quick to pick ideas .. Thanks n stay connected

Saul you absolute melt! Really good work man

am a student of public health. This information is simple and well presented to the point. Thank you so much.

very helpful information provided here

really thanks for wonderful information because i doing my bachelor degree research by survival model

Quite informative thank you so much for the info please continue posting. An mph student with Africa university Zimbabwe.

Thank you this was so helpful amazing

Apreciated the information provided above.

So clear and perfect. The language is simple and superb.I am recommending this to all budding epidemiology students. Thanks a lot.

Great to hear, thank you AJ!

I have recently completed an investigational study where evidence of phlebitis was determined in a control cohort by data mining from electronic medical records. We then introduced an intervention in an attempt to reduce incidence of phlebitis in a second cohort. Again, results were determined by data mining. This was an expedited study, so there subjects were enrolled in a specific cohort based on date(s) of the drug infused. How do I define this study? Thanks so much.

thanks for the information and knowledge about observational studies. am a masters student in public health/epidemilogy of the faculty of medicines and pharmaceutical sciences , University of Dschang. this information is very explicit and straight to the point

Very much helpful
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Expertise-based Randomized Controlled Trials
This blog summarizes the concepts of Expertise-based randomized controlled trials with a focus on the advantages and challenges associated with this type of study.

An introduction to different types of study design
Conducting successful research requires choosing the appropriate study design. This article describes the most common types of designs conducted by researchers.
Case-Control Study: Definition, Real Life Examples
Design of Experiments > Case-Control Study
What is a Case-Control Study?
A case-control study is a retrospective study that looks back in time to find the relative risk between a specific exposure (e.g. second hand tobacco smoke) and an outcome (e.g. cancer). A control group of people who do not have the disease or who did not experience the event is used for comparison. The goal is figure out the relationship between risk factors and disease or outcome and estimate the odds of an individual getting a disease or experiencing an event.
Case-control studies have four main steps:
- The study begins by enrolling people who already have a certain disease or outcome.
- A second control group of similar size is sampled, preferably from a population identical in every way except that they don’t have the disease or condition being studied. They should not be selected because of an exposure status.
- People are asked about their exposure to risk factors.
- Finally, an odds ratio is calculated.
- Non-matched case-control study: this is the simplest form. Find a person with the disease and enroll them in the study. Then enroll a control and determine their exposure status.
- Matched case-control: Find a person with the disease and enroll them in the study. Match the person for some characteristic (e.g. sex, age, weight) with a control. This can eliminate or minimize confounding variables . However, it generally results in a longer study; the more characteristics being “matched”, the longer the study takes.
Advantages and Disadvantages
Advantages A case-control study is often the best choice for rare conditions or diseases . Let’s say 10 people in Duval county in Florida had a particularly rare disease. Random sampling for a cohort study would involve large numbers of people and may not pick up any of the diseased people at all. With a case-control study, all 10 people who have the disease can be identified (assuming they are in a medical database) and enrolled in the study. Random sampling could then be used on the non-diseased population to form the control group. Other Advantages :
- Short term study that doesn’t require waiting for events to happen, as they have already occurred.
- Inexpensive.
- Multiple risk factors can be studied at the same time.
- Quickly establishes associations between risk factors and disease. This can be especially useful with disease outbreaks, as causes can be identified with small sample sizes.
- Stronger than cross-sectional studies for establishing causation.
Disadvantages :
- Control groups can be difficult to find.
- Results can easily be tainted by recall bias , where people with the disease or condition are more likely to remember past details compared to people who don’t have the disease or condition.
- Is weaker than a cohort study for establishing causation.
- Usually not generalizable .
Examples from Real Life
- This study for non-Hodgkin lymphoma found a connection between the disease and inflammatory disorders like Sjögrens, Celiac and rheumatoid arthritis.
- This study investigated how increased consumption of fruits and vegetables protects against Cervical Intraepithelial Neoplasia.
- This INTERHEART study looked at second hand tobacco smoke and increased risk of myocardial infarction.
Case-Control Studies

Introduction
Cohort studies have an intuitive logic to them, but they can be very problematic when one is investigating outcomes that only occur in a small fraction of exposed and unexposed individuals. They can also be problematic when it is expensive or very difficult to obtain exposure information from a cohort. In these situations a case-control design offers an alternative that is much more efficient. The goal of a case-control study is the same as that of cohort studies, i.e., to estimate the magnitude of association between an exposure and an outcome. However, case-control studies employ a different sampling strategy that gives them greater efficiency.
Learning Objectives
After completing this module, the student will be able to:
- Define and explain the distinguishing features of a case-control study
- Describe and identify the types of epidemiologic questions that can be addressed by case-control studies
- Define what is meant by the term "source population"
- Describe the purpose of controls in a case-control study
- Describe differences between hospital-based and population-based case-control studies
- Describe the principles of valid control selection
- Explain the importance of using specific diagnostic criteria and explicit case definitions in case-control studies
- Estimate and interpret the odds ratio from a case-control study
- Identify the potential strengths and limitations of case-control studies
Overview of Case-Control Design
In the module entitled Overview of Analytic Studies it was noted that Rothman describes the case-control strategy as follows:
"Case-control studies are best understood by considering as the starting point a source population , which represents a hypothetical study population in which a cohort study might have been conducted. The source population is the population that gives rise to the cases included in the study. If a cohort study were undertaken, we would define the exposed and unexposed cohorts (or several cohorts) and from these populations obtain denominators for the incidence rates or risks that would be calculated for each cohort. We would then identify the number of cases occurring in each cohort and calculate the risk or incidence rate for each. In a case-control study the same cases are identified and classified as to whether they belong to the exposed or unexposed cohort. Instead of obtaining the denominators for the rates or risks, however, a control group is sampled from the entire source population that gives rise to the cases. Individuals in the control group are then classified into exposed and unexposed categories. The purpose of the control group is to determine the relative size of the exposed and unexposed components of the source population. Because the control group is used to estimate the distribution of exposure in the source population, the cardinal requirement of control selection is that the controls be sampled independently of exposure status."
To illustrate this consider the following hypothetical scenario in which the source population is the state of Massachusetts. Diseased individuals are red, and non-diseased individuals are blue. Exposed individuals are indicated by a whitish midsection. Note the following aspects of the depicted scenario:
- The disease is rare.
- There is a fairly large number of exposed individuals in the state, but most of these are not diseased.
If we somehow had exposure and outcome information on all of the subjects in the source population and looked at the association using a cohort design, we might find the data summarized in the contingency table below.
|
| Diseased | Non-diseased | Total |
|---|---|---|---|
| Exposed | 700 | 999,300 | 1,000,000 |
| Non-exposed | 600 | 4,999,400 | 5,000,000 |
In this hypothetical example, we have data on all 6,000,000 people in the source population, and we could compute the probability of disease (i.e., the risk or incidence) in both the exposed group and the non-exposed group, because we have the denominators for both the exposed and non-exposed groups.
The table above summarizes all of the necessary information regarding exposure and outcome status for the population and enables us to compute a risk ratio as a measure of the strength of the association. Intuitively, we compute the probability of disease (the risk) in each exposure group and then compute the risk ratio as follows:
The problem , of course, is that we usually don't have the resources to get the data on all subjects in the population. If we took a random sample of even 5-10% of the population, we would have few diseased people in our sample, certainly not enough to produce a reasonably precise measure of association. Moreover, we would expend an inordinate amount of effort and money collecting exposure and outcome data on a large number of people who would not develop the outcome.
We need a method that allows us to retain all the people in the numerator of disease frequency (diseased people or "cases") but allows us to collect information from only a small proportion of the people that make up the denominator (population, or "controls"), most of whom do not have the disease of interest. The case-control design allows us to accomplish this. We identify and collect exposure information on all the cases, but identify and collect exposure information on only a sample of the population. Once we have the exposure information, we can assign subjects to the numerator and denominator of the exposed and unexposed groups. This is what Rothman means when he says,
"The purpose of the control group is to determine the relative size of the exposed and unexposed components of the source population."
In the above example, we would have identified all 1,300 cases, determined their exposure status, and ended up categorizing 700 as exposed and 600 as unexposed. We might have ransomly sampled 6,000 members of the population (instead of 6 million) in order to determine the exposure distribution in the total population. If our sampling method was random, we would expect that about 1,000 would be exposed and 5,000 unexposed (the same ratio as in the overall population). We calculate a similar measure as the risk ratio above, but substituting in the denominator a sample of the population ("controls") instead of the whole population:
Note that when we take a sample of the population, we no longer have a measure of disease frequency, because the denominator no longer represents the population. Therefore, we can no longer compute the probability or rate of disease incidence in each exposure group. We also can't calculate a risk or rate difference measure for the same reason. However, as we have seen, we can compute the relative probability of disease in the exposed vs. unexposed group. The term generally used for this measure is an odds ratio , described in more detail later in the module.
Consequently, when the outcome is uncommon, as in this case, the risk ratio can be estimated much more efficiently by using a case-control design. One would focus first on finding an adequate number of cases in order to determine the ratio of exposed to unexposed cases. Then, one only needs to take a sample of the population in order to estimate the relative size of the exposed and unexposed components of the source population. Note that if one can identify all of the cases that were reported to a registry or other database within a defined period of time, then it is possible to compute an estimate of the incidence of disease if the size of the population is known from census data. While this is conceptually possible, it is rarely done, and we will not discuss it further in this course.

A Nested Case-Control Study
Suppose a prospective cohort study were conducted among almost 90,000 women for the purpose of studying the determinants of cancer and cardiovascular disease. After enrollment, the women provide baseline information on a host of exposures, and they also provide baseline blood and urine samples that are frozen for possible future use. The women are then followed, and, after about eight years, the investigators want to test the hypothesis that past exposure to pesticides such as DDT is a risk factor for breast cancer. Eight years have passed since the beginning of the study, and 1.439 women in the cohort have developed breast cancer. Since they froze blood samples at baseline, they have the option of analyzing all of the blood samples in order to ascertain exposure to DDT at the beginning of the study before any cancers occurred. The problem is that there are almost 90,000 women and it would cost $20 to analyze each of the blood samples. If the investigators could have analyzed all 90,000 samples this is what they would have found the results in the table below.
Table of Breast Cancer Occurrence Among Women With or Without DDT Exposure
|
| Breast Cancer | No Breast Cancer | Total |
|---|---|---|---|
| DDT exposed | 360 | 13,276 | 13,636 |
| Unexposed | 1,079 | 75,234 | 76,313 |
|
| 1,439 | 88,510 | 89,949 |
If they had been able to afford analyzing all of the baseline blood specimens in order to categorize the women as having had DDT exposure or not, they would have found a risk ratio = 1.87 (95% confidence interval: 1.66-2.10). The problem is that this would have cost almost $1.8 million, and the investigators did not have the funding to do this.
While 1,439 breast cancers is a disturbing number, it is only 1.6% of the entire cohort, so the outcome is relatively rare, and it is costing a lot of money to analyze the blood specimens obtained from all of the non-diseased women. There is, however, another more efficient alternative, i.e., to use a case-control sampling strategy. One could analyze all of the blood samples from women who had developed breast cancer, but only a sample of the whole cohort in order to estimate the exposure distribution in the population that produced the cases.
If one were to analyze the blood samples of 2,878 of the non-diseased women (twice as many as the number of cases), one would obtain results that would look something like those in the next table.
|
| Breast Cancer | No Breast Cancer |
|---|---|---|
| DDT exposed | 360 | 432 |
| Unexposed | 1,079 | 2,446 |
|
| 1,439 | 2,878 |
Odds of Exposure: 360/1079 in the cases versus 432/2,446 in the non-diseased controls.
Totals Samples analyzed = 1,438+2,878 = 4,316
Total Cost = 4,316 x $20 = $86,320
With this approach a similar estimate of risk was obtained after analyzing blood samples from only a small sample of the entire population at a fraction of the cost with hardly any loss in precision. In essence, a case-control strategy was used, but it was conducted within the context of a prospective cohort study. This is referred to as a case-control study "nested" within a cohort study.
Rothman states that one should look upon all case-control studies as being "nested" within a cohort. In other words the cohort represents the source population that gave rise to the cases. With a case-control sampling strategy one simply takes a sample of the population in order to obtain an estimate of the exposure distribution within the population that gave rise to the cases. Obviously, this is a much more efficient design.
It is important to note that, unlike cohort studies, case-control studies do not follow subjects through time. Cases are enrolled at the time they develop disease and controls are enrolled at the same time. The exposure status of each is determined, but they are not followed into the future for further development of disease.
As with cohort studies, case-control studies can be prospective or retrospective. At the start of the study, all cases might have already occurred and then this would be a retrospective case-control study. Alternatively, none of the cases might have already occurred, and new cases will be enrolled prospectively. Epidemiologists generally prefer the prospective approach because it has fewer biases, but it is more expensive and sometimes not possible. When conducted prospectively, or when nested in a prospective cohort study, it is straightforward to select controls from the population at risk. However, in retrospective case-control studies, it can be difficult to select from the population at risk, and controls are then selected from those in the population who didn't develop disease. Using only the non-diseased to select controls as opposed to the whole population means the denominator is not really a measure of disease frequency, but when the disease is rare , the odds ratio using the non-diseased will be very similar to the estimate obtained when the entire population is used to sample for controls. This phenomenon is known as the r are-disease assumption . When case-control studies were first developed, most were conducted retrospectively, and it is sometimes assumed that the rare-disease assumption applies to all case-control studies. However, it actually only applies to those case-control studies in which controls are sampled only from the non-diseased rather than the whole population.
The difference between sampling from the whole population and only the non-diseased is that the whole population contains people both with and without the disease of interest. This means that a sampling strategy that uses the whole population as its source must allow for the fact that people who develop the disease of interest can be selected as controls. Students often have a difficult time with this concept. It is helpful to remember that it seems natural that the population denominator includes people who develop the disease in a cohort study. If a case-control study is a more efficient way to obtain the information from a cohort study, then perhaps it is not so strange that the denominator in a case-control study also can include people who develop the disease. This topic is covered in more detail in EP813 Intermediate Epidemiology.
Retrospective and Prospective Case-Control Studies
Students usually think of case-control studies as being only retrospective, since the investigators enroll subjects who have developed the outcome of interest. However, case-control studies, like cohort studies, can be either retrospective or prospective. In a prospective case-control study, the investigator still enrolls based on outcome status, but the investigator must wait to the cases to occur.
When is a Case-Control Study Desirable?
Given the greater efficiency of case-control studies, they are particularly advantageous in the following situations:
- When the disease or outcome being studied is rare.
- When the disease or outcome has a long induction and latent period (i.e., a long time between exposure and the eventual causal manifestation of disease).
- When exposure data is difficult or expensive to obtain.
- When the study population is dynamic.
- When little is known about the risk factors for the disease, case-control studies provide a way of testing associations with multiple potential risk factors. (This isn't really a unique advantage to case-control studies, however, since cohort studies can also assess multiple exposures.)
Another advantage of their greater efficiency, of course, is that they are less time-consuming and much less costly than prospective cohort studies.
The DES Case-Control Study
A classic example of the efficiency of the case-control approach is the study (Herbst et al.: N. Engl. J. Med. Herbst et al. (1971;284:878-81) that linked in-utero exposure to diethylstilbesterol (DES) with subsequent development of vaginal cancer 15-22 years later. In the late 1960s, physicians at MGH identified a very unusual cancer cluster. Eight young woman between the ages of 15-22 were found to have cancer of the vagina, an uncommon cancer even in elderly women. The cluster of cases in young women was initially reported as a case series, but there were no strong hypotheses about the cause.
In retrospect, the cause was in-utero exposure to DES. After World War II, DES started being prescribed for women who were having troubles with a pregnancy -- if there were signs suggesting the possibility of a miscarriage, DES was frequently prescribed. It has been estimated that between 1945-1950 DES was prescribed for about 20% of all pregnancies in the Boston area. Thus, the unborn fetus was exposed to DES in utero, and in a very small percentage of cases this resulted in development of vaginal cancer when the child was 15-22 years old (a very long latent period). There were several reasons why a case-control study was the only feasible way to identify this association: the disease was extremely rare (even in subjects who had been exposed to DES), there was a very long latent period between exposure and development of disease, and initially they had no idea what was responsible, so there were many possible exposures to consider.
In this situation, a case-control study was the only reasonable approach to identify the causative agent. Given how uncommon the outcome was, even a large prospective study would have been unlikely to have more than one or two cases, even after 15-20 years of follow-up. Similarly, a retrospective cohort study might have been successful in enrolling a large number of subjects, but the outcome of interest was so uncommon that few, if any, subjects would have had it. In contrast, a case-control study was conducted in which eight known cases and 32 age-matched controls provided information on many potential exposures. This strategy ultimately allowed the investigators to identify a highly significant association between the mother's treatment with DES during pregnancy and the eventual development of adenocarcinoma of the vagina in their daughters (in-utero at the time of exposure) 15 to 22 years later.
For more information see the DES Fact Sheet from the National Cancer Institute.
An excellent summary of this landmark study and the long-range effects of DES can be found in a Perspective article in the New England Journal of Medicine. A cohort of both mothers who took DES and their children (daughters and sons) was later formed to look for more common outcomes. Members of the faculty at BUSPH are on the team of investigators that follow this cohort for a variety of outcomes, particularly reproductive consequences and other cancers.
Selecting & Defining Cases and Controls
The "case" definition.
Careful thought should be given to the case definition to be used. If the definition is too broad or vague, it is easier to capture people with the outcome of interest, but a loose case definition will also capture people who do not have the disease. On the other hand, an overly restrictive case definition is employed, fewer cases will be captured, and the sample size may be limited. Investigators frequently wrestle with this problem during outbreak investigations. Initially, they will often use a somewhat broad definition in order to identify potential cases. However, as an outbreak investigation progresses, there is a tendency to narrow the case definition to make it more precise and specific, for example by requiring confirmation of the diagnosis by laboratory testing. In general, investigators conducting case-control studies should thoughtfully construct a definition that is as clear and specific as possible without being overly restrictive.
Investigators studying chronic diseases generally prefer newly diagnosed cases, because they tend to be more motivated to participate, may remember relevant exposures more accurately, and because it avoids complicating factors related to selection of longer duration (i.e., prevalent) cases. However, it is sometimes impossible to have an adequate sample size if only recent cases are enrolled.
Sources of Cases
Typical sources for cases include:
- Patient rosters at medical facilities
- Death certificates
- Disease registries (e.g., cancer or birth defect registries; the SEER Program [Surveillance, Epidemiology and End Results] is a federally funded program that identifies newly diagnosed cases of cancer in population-based registries across the US )
- Cross-sectional surveys (e.g., NHANES, the National Health and Nutrition Examination Survey)
Selection of the Controls
As noted above, it is always useful to think of a case-control study as being nested within some sort of a cohort, i.e., a source population that produced the cases that were identified and enrolled. In view of this there are two key principles that should be followed in selecting controls:
- The comparison group ("controls") should be representative of the source population that produced the cases.
- The "controls" must be sampled in a way that is independent of the exposure, meaning that their selection should not be more (or less) likely if they have the exposure of interest.
If either of these principles are not adhered to, selection bias can result (as discussed in detail in the module on Bias).
Note that in the earlier example of a case-control study conducted in the Massachusetts population, we specified that our sampling method was random so that exposed and unexposed members of the population had an equal chance of being selected. Therefore, we would expect that about 1,000 would be exposed and 5,000 unexposed (the same ratio as in the whole population), and came up with an odds ratio that was same as the hypothetical risk ratio we would have had if we had collected exposure information from the whole population of six million:
What if we had instead been more likely to sample those who were exposed, so that we instead found 1,500 exposed and 4,500 unexposed among the 6,000 controls? Then the odds ratio would have been:
This odds ratio is biased because it differs from the true odds ratio. In this case, the bias stemmed from the fact that we violated the second principle in selection of controls. Depending on which category is over or under-sampled, this type of bias can result in either an underestimate or an overestimate of the true association.
A hypothetical case-control study was conducted to determine whether lower socioeconomic status (the exposure) is associated with a higher risk of cervical cancer (the outcome). The "cases" consisted of 250 women with cervical cancer who were referred to Massachusetts General Hospital for treatment for cervical cancer. They were referred from all over the state. The cases were asked a series of questions relating to socioeconomic status (household income, employment, education, etc.). The investigators identified control subjects by going door-to-door in the community around MGH from 9:00 AM to 5:00 PM. Many residents are not home, but they persist and eventually enroll enough controls. The problem is that the controls were selected by a different mechanism than the cases, AND the selection mechanism may have tended to select individuals of different socioeconomic status, since women who were at home may have been somewhat more likely to be unemployed. In other words, the controls were more likely to be enrolled (selected) if they had the exposure of interest (lower socioeconomic status).

Sources for "Controls"
Population controls:.
A population-based case-control study is one in which the cases come from a precisely defined population, such as a fixed geographic area, and the controls are sampled directly from the same population. In this situation cases might be identified from a state cancer registry, for example, and the comparison group would logically be selected at random from the same source population. Population controls can be identified from voter registration lists, tax rolls, drivers license lists, and telephone directories or by "random digit dialing". Population controls may also be more difficult to obtain, however, because of lack of interest in participating, and there may be recall bias, since population controls are generally healthy and may remember past exposures less accurately.
|
Random Digit Dialing Random digit dialing has been popular in the past, but it is becoming less useful because of the use of caller ID, answer machines, and a greater reliance on cell phones instead of land lines. Ken Rothman points out several that random digit dialing provides an equal probability that any given phone will be dialed, but not an equal probability of reaching eligible control subjects, because households vary in the number of residents and the likelihood that someone will be home. In addition, random digit dialing doesn't make any distinction between residential and business phones.
|
Example of a Population-based Case-Control Study: Rollison et al. reported on a "Population-based Case-Control Study of Diabetes and Breast Cancer Risk in Hispanic and Non-Hispanic White Women Living in US Southwestern States". (ALink to the article - Citation: Am J Epidemiol 2008;167:447–456).
"Briefly, a population-based case-control study of breast cancer was conducted in Colorado, New Mexico, Utah, and selected counties of Arizona. For investigation of differences in the breast cancer risk profiles of non-Hispanic Whites and Hispanics, sampling was stratified by race/ethnicity, and only women who self-reported their race as non-Hispanic White, Hispanic, or American Indian were eligible, with the exception of American Indian women living on reservations. Women diagnosed with histologically confirmed breast cancer between October 1999 and May 2004 (International Classification of Diseases for Oncology codes C50.0–C50.6 and C50.8–C50.9) were identified as cases through population-based cancer registries in each state."
"Population-based controls were frequency-matched to cases in 5-year age groups. In New Mexico and Utah, control participants under age 65 years were randomly selected from driver's license lists; in Arizona and Colorado, controls were randomly selected from commercial mailing lists, since driver's license lists were unavailable. In all states, women aged 65 years or older were randomly selected from the lists of the Centers for Medicare and Medicaid Services (Social Security lists). Of all women contacted, 68 percent of cases and 42 percent of controls participated in the study."
"Odds ratios and 95% confidence intervals were calculated using logistic regression, adjusting for age, body mass index at age 15 years, and parity. Having any type of diabetes was not associated with breast cancer overall (odds ratio = 0.94, 95% confidence interval: 0.78, 1.12). Type 2 diabetes was observed among 19% of Hispanics and 9% of non-Hispanic Whites but was not associated with breast cancer in either group."
In this example, it is clear that the controls were selected from the source population (principle 1), but less clear that they were enrolled independent of exposure status (principle 2), both because drivers' licenses were used for selection and because the participation rate among controls was low. These factors would only matter if they impacted on the estimate of the proportion of the population who had diabetes.
Hospital or Clinic Controls:

- They have diseases that are unrelated to the exposure being studied. For example, for a study examining the association between smoking and lung cancer, it would not be appropriate to include patients with cardiovascular disease as control, since smoking is a risk factor for cardiovascular disease. To include such patients as controls would result in an underestimate of the true association.
- Second, control patients in the comparison should have diseases with similar referral patterns as the cases, in order to minimize selection bias. For example, if the cases are women with cervical cancer who have been referred from all over the state, it would be inappropriate to use controls consisting of women with diabetes who had been referred primarily from local health centers in the immediate vicinity of the hospital. Similarly, it would be inappropriate to use patients from the emergency room, because the selection of a hospital for an emergency is different than for cancer, and this difference might be related to the exposure of interest.
The advantages of using controls who are patients from the same facility are:
- They are easier to identify
- They are more likely to participate than general population controls.
- They minimize selection bias because they generally come from the same source population (provided referral patterns are similar).
- Recall bias would be minimized, because they are sick, but with a different diagnosis.
Example: Several years ago the vascular surgeons at Boston Medical Center wanted to study risk factors for severe atherosclerosis of the lower extremities. The cases were patients who were referred to the hospital for elective surgery to bypass severe atherosclerotic blockages in the arteries to the legs. The controls consisted of patients who were admitted to the same hospital for elective joint replacement of the hip or knee. The patients undergoing joint replacement were similar in age and they also were following the same referral pathways. In other words, they met the "would" criterion: if one of the joint replacement surgery patients had developed severe atherosclerosis in their leg arteries, they would have been referred to the same hospital.
Friend, Neighbor, Spouse, and Relative Controls:
Occasionally investigators will ask cases to nominate controls who are in one of these categories, because they have similar characteristics, such as genotype, socioeconomic status, or environment, i.e., factors that can cause confounding, but are hard to measure and adjust for. By matching cases and controls on these factors, confounding by these factors will be controlled. However, one must be careful that the controls satisfy the two fundamental principles. Often, they do not.
How Many Controls?
Since case-control studies are often used for uncommon outcomes, investigators often have a limited number of cases but a plentiful supply of potential controls. In this situation the statistical power of the study can be increased somewhat by enrolling more controls than cases. However, the additional power that is achieved diminishes as the ratio of controls to cases increases, and ratios greater than 4:1 have little additional impact on power. Consequently, if it is time-consuming or expensive to collect data on controls, the ratio of controls to cases should be no more than 4:1. However, if the data on controls is easily obtained, there is no reason to limit the number of controls.
Methods of Control Sampling
There are three strategies for selecting controls that are best explained by considering the nested case-control study described on page 3 of this module:
- Survivor sampling: This is the most common method. Controls consist of individuals from the source population who do not have the outcome of interest.
- Case-base sampling (also known as "case-cohort" sampling): Controls are selected from the population at risk at the beginning of the follow-up period in the cohort study within which the case-control study was nested.
- Risk Set Sampling: In the nested case-control study a control would be selected from the population at risk at the point in time when a case was diagnosed.
The Rare Outcome Assumption
It is often said that an odds ratio provides a good estimate of the risk ratio only when the outcome of interest is rare, but this is only true when survivor sampling is used. With case-base sampling or risk set sampling, the odds ratio will provide a good estimate of the risk ratio regardless of the frequency of the outcome, because the controls will provide an accurate estimate of the distribution in the source population (i.e., not just in non-diseased people).
More on Selection Bias
Always consider the source population for case-control studies, i.e. the "population" that generated the cases. The cases are always identified and enrolled by some method or a set of procedures or circumstances. For example, cases with a certain disease might be referred to a particular tertiary hospital for specialized treatment. Alternatively, if there is a database or a disease registry for a geographic area, cases might be selected at random from the database. The key to avoiding selection bias is to select the controls by a similar, if not identical, mechanism in order to ensure that the controls provide an accurate representation of the exposure status of the source population.
Example 1: In the first example above, in which cases were randomly selected from a geographically defined database, the source population is also defined geographically, so it would make sense to select population controls by some random method. In contrast, if one enrolled controls from a particular hospital within the geographic area, one would have to at least consider whether the controls were inherently more or less likely to have the exposure of interest. If so, they would not provide an accurate estimate of the exposure distribution of the source population, and selection bias would result.
Example 2: In the second example above, the source population was defined by the patterns of referral to a particular hospital for a particular disease. In order for the controls to be representative of the "population" that produced those cases, the controls should be selected by a similar mechanism, e.g., by contacting the referring health care providers and asking them to provide the names of potential controls. By this mechanism, one can ensure that the controls are representative of the source population, because if they had had the disease of interest they would have been just as likely as the cases to have been included in the case group (thus fulfilling the "would" criterion).
Example 3: A food handler at a delicatessen who is infected with hepatitis A virus is responsible for an outbreak of hepatitis which is largely confined to the surrounding community from which most of the customers come. Many (but not all) of the infected cases are identified by passive and active surveillance. How should controls be selected? In this situation, one might guess that the likelihood of people going to the delicatessen would be heavily influenced by their proximity to it, and this would to a large extent define the source population. In a case-control study undertaken to identify the source, the delicatessen is one of the exposures being tested. Consequently, even if the cases were reported to the state-wide surveillance system, it would not be appropriate to randomly select controls from the state, the county, or even the town where the delicatessen is located. In other words, the "would" criterion doesn't work here, because anyone in the state with clinical hepatitis would end up in the surveillance system, but someone who lived far from the deli would have a much lower likelihood of having the exposure. A better approach would be to select controls who were matched to the cases by neighborhood, age, and gender. These controls would have similar access to go to the deli if they chose to, and they would therefore be more representative of the source population.
Analysis of Case-Control Studies
The computation and interpretation of the odds ratio in a case-control study has already been discussed in the modules on Overview of Analytic Studies and Measures of Association. Additionally, one can compute the confidence interval for the odds ratio, and statistical significance can also be evaluated by using a chi-square test (or a Fisher's Exact Test if the sample size is small) to compute a p-value. These calculations can be done using the Case-Control worksheet in the Excel file called EpiTools.XLS.

Advantages and Disadvantages of Case-Control Studies
Advantages:
- They are efficient for rare diseases or diseases with a long latency period between exposure and disease manifestation.
- They are less costly and less time-consuming; they are advantageous when exposure data is expensive or hard to obtain.
- They are advantageous when studying dynamic populations in which follow-up is difficult.
Disadvantages:
- They are subject to selection bias.
- They are inefficient for rare exposures.
- Information on exposure is subject to observation bias.
- They generally do not allow calculation of incidence (absolute risk).
- Free Case Studies
- Business Essays
Write My Case Study
Buy Case Study
Case Study Help
- Case Study For Sale
- Case Study Services
- Hire Writer
Case-Control Study: Definition, Types and Examples
During forming a group of cases, it is necessary to apply strict, objective criteria for the result. You should be sure of the homogeneity of the result because similar illness or effects may have different risk factors, for example not all diseases of the intestinal infections that are detected in the population under study only in the presence of diabetic syndrome can be selected for the study. It should be sought to use, if possible, “incident” cases (again diagnosed) than “prevalent” (already existing at the given time).During using “superior” cases, the effect of the disease on potential risk factors can lead to complications in the interpretation of data. For example, in a study on the impact of coffee consumption on the risk of peptic ulcer disease, “prevalent” cases (long suffering from ulcers and precautionary coffee drinkers) will differ in relation to the exposure from “incident” cases, in which the disease has occurred relatively recently and what else have not had time to change their attitude to drinking this soda.Observational studies proved, that case-control studies have less reliability than cohort studies.
This is not entirely true: a well-organized case-control study in a number of situations can provide much more reliable results than cohort studies. The main stages are:
- Formation of a sample (cohort) from the general population, taking into account the features of inclusion and exclusion.
- Collecting information on the prevalence of risk factors and illnesses.
What is a Case-Control Study?
The case-control study is one of the very important types of studies, that has a number of obvious benefits. First of all, this scheme of analytical research is excellent for rare diseases (co-study in such a situation, the population of the study may be excessively high). The case-control study allows you to get an answer quickly and, therefore,it is the method of choice during investigating flashes.
In the case-control study, you can study simultaneously (and quickly) a multitude of factors for studying one result. However, only one output can be studied.Problems, encountered in the case-control study vs. cohort study , are related to the fact that interest in the data on the impact of the factor may be inaccessible or inaccurate. Sometimes, it’s just not possible to choose a sufficient number of controls that satisfy the requirements set.
The choice of a scheme for analytical research depends, first of all, on specific tasks and main steps, but largely determined by the available resources and timing for it. Knowing the possibilities of different approaches, their advantages and disadvantages allow the epidemiologist to plan research optimally.In the case-control study, it is virtually impossible to identify the rare causes of the disease. In such cases, scanty data does not allow us to assess the validity of the differences in the incidence of risk factors in the comparison groups and, therefore, to draw conclusions about the presence or absence of a causal relationship.
Advantages and Disadvantages of a Case-Control Study, Types of Case-Control Studies
In the case-control study, the search for causal relationships goes in the direction of the investigation to the foreseeable cause.
Case-control study examples can only be retrospective, as it is conducted on the basis of archival data. Often, the source of information in the case-control studies is the history of the disease, which is in the archives of medical institutions, the memories of patients or their relatives in the context of an interview or by the results of the questionnaire.This retrospective study can be done as a preliminary study of the causal relationship between the predicted risk factor and the specific disease. In the future, this problem can be studied in cohort studies.Positive aspects of the case-control study are the possibility of conducting them regardless of the prevalence of the disease under study.
Relatively small expenditures of time, forces and means are needed to create a basic group of patients (even rarely encountered diseases), to pick up a control group for them, to question and make at least indicative conclusions. In the study of such diseases, you have to pick up a cohort of hundreds of thousands of people, to watch them for a long time. This would entail considerable time, material and moral costs.Case-control studies have a relatively short duration. The duration of the research depends directly on the productivity of the personnel involved in the study. In order to obtain conclusions, it is not necessary, as in the cohort study, to conduct observations for a period that exceeds the latent period of disease development.
There is a possibility to identify several risk factors for one disease simultaneously.The main disadvantage is the inability to quantify the risk of a disease (death) from an alleged cause.The case-control study is characterized by relatively small economic costs. This makes them attractive when the researcher is limited in funding. However, you should not forget that each study has its own indications and limitations.
Related posts:
- Research Design: Definition, Types and How to Write
- Quantitative Research Design: Definition, Methods and Types
- Exploratory Research Design: Definition, Types and Ways to Implement
- Case Study: Definition, How to Write, Format and Examples
- What Is Cohort Study: Types, Study Design and Examples
- Explanation of three types Examples
- Descriptive Research Design: Definition, Methods and Examples

Quick Links
Privacy Policy
Terms and Conditions
Testimonials
Our Services
Case Study Writing Services
Case Studies For Sale
Our Company
Welcome to the world of case studies that can bring you high grades! Here, at ACaseStudy.com, we deliver professionally written papers, and the best grades for you from your professors are guaranteed!
[email protected] 804-506-0782 350 5th Ave, New York, NY 10118, USA
Acasestudy.com © 2007-2019 All rights reserved.

Hi! I'm Anna
Would you like to get a custom case study? How about receiving a customized one?
Haven't Found The Case Study You Want?
For Only $13.90/page
- Essay Editor
Types of Case Studies: a Comprehensive Guide

The art of writing involves multiple types of materials, which makes both writing and reading a pleasure that is informative and conducive to conveying knowledge and experience. However, when it comes to academic writing, there is a need to distinguish between the many types of materials based on their appropriateness to a certain kind of information.
Each type of material with its own structure and manner of writing is best suited for certain types of topics. The latter can range from anything like scientific articles or presentations of projects to various informative materials that tell the reader about new releases of products or services. In the given material, we shall identify the examples of a case study that can be used to great extent in a variety of topics. We shall also include examples of case study research to better illustrate how such a material can benefit the writer to effectively convey information, and the reader to better understand the key takeaways and evaluate value.
What is a case study?
The most common question that arises among new entrants into the art of writing when confronted with the need to write a case study is “ what are case studies ”? There is a wide variety of case studies meaning definitions available in the Internet, but all of them converge on a single one that essentially defines case studies as an in-depth analysis of a certain case, occurrence, story, or subject, with a detailed explanation of the impact thereof in the context of the real world.
Just as in hard science there are case study methods , so too in writing, there are numerous ways in which a case study can be written, elaborated, and explored to better divulge its value and meaning to the reader. The general concept of a case study is to better explain how that particular case arose, evolved, developed, and concluded, with well-defined and analyzed expressions of the consequences for the parties involved and even a statistical analysis.
The most common areas in which case studies are employed as a means of convening informational value are storytelling in business and scientific settings. As both areas are dominated by various cases of precedents and success or failure, the need to examine each in detail and allow readers to draw conclusions makes case studies an ideal go-to type of material for such purposes.
Types of subjects in a case study
The subjects that case studies can encompass are as numerous as there are topics to explore. Most commonly, case studies are used in science, legislative matters, technology-related areas, business, and other domains.
Most common subjects explored in case studies include success stories, certain technological, medical, or scientific breakthroughs, historical studies, and even academic writing.
What are the case study benefits?
The case study can provide a number of considerable advantages to writers as a type of material, which can help clearly define a relationship between the subject involved in the case and its context. The flexibility with which the data included in the material can be presented helps achieve both clarity and the necessary effect on the reader. Most importantly, case studies provide a clear outline of events in extensive detail and help establish a cause-effect relationship.
Essential types of case studies
There are many types of case studies available to writers that they choose from in their strive to elaborate a certain instance and tailor the material for better digestibility by readers. The following is a short overview of the main types of case studies and their purposes:
Illustrative
As the name implies, an illustrative case study serves the purpose of illustrating a certain case. This type of material is used to describe a certain event in greater detail and delves into the circumstances of the underlying situation, with an emphasis on the causes and effects thereof.
Illustrative case studies are ideal for describing medical cases and patient illness histories, especially in the case of rare diseases. By exploring the course of the case and the circumstances that took place during it, the reader will have a clear picture of the situation and will be able to relate it to their own real-world standing to either replicate the case or avoid any pitfalls that might have been described in the material.
Such materials are also used to great effect in the business world, whereby companies describe their success stories and thus highlight their competencies to attract new clients and inspire awe in customers.
Exploratory
An exploratory case study is a very specific type of material that has the aim of encompassing a set of data as an initial research attempt for the purpose of identifying possible patterns. Such patterns, if any exist, can help create a model based on the data and then extrapolate it for further analysis, application, or research.
Exploratory case studies are primarily used in the scientific community by researchers who conduct experiments, or data analysts tasked with sifting through large arrays of data. The point of an exploratory case study is basically to make sense of a large buildup of information.
Cumulative case studies, as the name might suggest, accumulate information from various sources and compile it in a single material for the purpose of analysis, comparison, or evaluation. The data can be collected from different time periods, sources, or even places and combined for analysis in the search for patterns or other purposes.
As a rule, every cumulative case study must start with a founding question that will act as a hypothesis for further exploration of the compiled data.
Critical instance
As in critical thinking, which seeks to find relations between cause and effect, a critical instance case study is used to answer questions pertaining to the causes and consequences of a certain case. Such materials are ideal for making certain points about established concepts, placing emphasis on certain topics of interest within a larger framework of questions as outliers, and diving into the reasons for certain events.
Critical instance case studies are used extensively in criminalistics, legal proceedings, and experimental science, where a fresh look on certain questions is sometimes in order to identify a potential cause, or cause-effect relationship.
Intrinsic case studies perfectly leverage the term to explain the value of a certain question, rather than its relevance. Such materials are ideal for delving into the finer details of a case, explaining its uniqueness, qualities, characteristics, and other aspects.
Such materials are perfectly suited for focusing on certain topics, or highlighting previously unnoticed qualities about them.
Descriptive
As the term implies, descriptive case studies simply describe a certain case without any additional emphasis on questions, qualities, or effects. Such materials offer an objective look on a case and provide a hard, fact-based overview of the event.
A descriptive case study is commonly used in government-related materials, scientific research, medical records, and other areas, where there is no need to appeal to a reader, or to “sell” them a certain concept, company, or product.
Related articles
Essay format tips from an english teacher.
Writing a solid and well-crafted essay is crucial for students and researchers, as it involves presenting arguments clearly and succinctly. Whether you are writing a paper for an assignment, a scientific journal, or a personal statement, understanding the correct essay format is pivotal. This meticulously collated guide covers key features of essay formatting and provides tips to refine your writing. What is an Essay Format? An essay format is a blueprint for shaping your written assignment, ...
How to Conclude an Essay: A Guide for Academic Writing
Every essay requires a proper conclusion. It is particularly important in academic writing where texts can be several dozen pages long. A conclusion helps the audience remember the contents of your essay and retain important information. In this article, you will learn how to write a conclusion for an essay. Why the conclusion matters When writing essays, we always strive to conduct a comprehensive analysis of the topic. We do our research, present different perspectives, and provide examples ...
How to Write Essay Thesis Statement: A Comprehensive Analysis
In academic writing, creating an impactful text that can deftly relay your opinion and persuade your audience is one of the key skills. That’s why it is essential to learn how to write a strong thesis statement. In this article, you will find all you need to know for creating a persuasive thesis statement. What is an essay thesis? In academic essays, a thesis is a part of the introduction that expresses the main idea and purpose of the essay. It aims to give the audience a brief overview of t ...
The Basics of Crafting an Outstanding Persuasive Essay Outline
When writing a persuasive essay, having a well-structured outline is critical to effectively presenting your argument and convincing your audience. An outline serves as a roadmap for your essay, organizing your thoughts and supporting evidence in a logical sequence that flows cohesively. In this guide, we will explore the essential components of a persuasive essay outline and provide tips on how to craft a compelling structure for your writing. Whether you are a beginner or a seasoned writer, ma ...
What is an Appendix in a Research Paper? | Aithor
What is an appendix in a research paper? An appendix is a supplementary section at the end of a research paper after the list of references. It contains more information that helps explain the main ideas in the paper. It's not needed in the main part because it would make the paper too long or go “off-topic." The appendix gives readers more details to help them understand the research better without making the main argument hard to follow. The length of an appendix can differ depending on what ...
Diagnostic Essay Writing Guide and Outline Sample
Imagine stepping into a classroom on the first day and being asked to write an essay. This exercise, commonly referred to as a diagnostic essay, is a common tool used by instructors to gauge their students' writing proficiency. Interestingly, in a study exploring the effectiveness of evaluation papers, over 70% of participants reported that these tasks significantly improved their understanding of their writing strengths and challenges. This finding underscores the assessment assignment's role i ...
Expository Essay Examples: Developing Skills in Informative Writing
Is your assignment to prepare a fine and well-structured expository essay but you don't know what point to start with? This material lends a helping hand to you. Here we discuss how to begin an expository essay, what parts should be in the text, and what linguistic means a person should use when creating a project mentioned above. We also introduce you a few tips on how to sharpen your skills in informative writing. So be ready to read and learn, the adventure to the land of expository papers ge ...
How to Make an Essay Longer: 7 Useful Tips
Are you having trouble getting your essay to the right length? Do you look at your essay and think, "It's too short!" but don't know what to do? Don't worry, we've got some great ideas on how to make an essay longer without making it worse. Why is it Important to Make an Essay Longer? When you're writing an essay, it's important to make sure it's long enough. If your essay isn't as long as required, you might get a lower grade, even if the content of your essay is exceptional. By making your ...

What is CRM?
Manage, track, and store information related to potential customers using a centralized, data-driven software solution.
Defining CRM
Customer relationship management (CRM) is a set of integrated, data-driven software solutions that help manage, track, and store information related to your company’s current and potential customers. By keeping this information in a centralized system, business teams have access to the insights they need, the moment they need them.
Without the support of an integrated CRM solution, your company may miss growth opportunities and lose potential revenue because it’s not optimizing operating processes or making the most of customer relationships and sales leads.
What does a CRM do?
Not too long ago, companies tracked customer-related data with spreadsheets, email, address books, and other siloed, often paper-based CRM solutions. A lack of integration and automation prevented people within and across teams from quickly finding and sharing up-to-date information, slowing their ability to create marketing campaigns, pursue new sales leads, and service customers.
Fast forward to today. CRM systems automatically collect a wealth of information about existing and prospective customers. This data includes email addresses, phone numbers, company websites, social media posts, purchase histories, and service and support tickets. The system next integrates the data and generates consolidated profiles to be shared with appropriate teams.
CRM systems also connect with other business tools, including online chat and document sharing apps. In addition, they have built-in business intelligence and artificial intelligence (AI) capabilities that accelerate administrative tasks and provide actionable insights.
In other words, modern CRM tools give sales, marketing, commerce, field service, and customer service teams immediate visibility into—and access to—everything crucial to developing, improving, and retaining customer relationships.
Some ways you can use CRM capabilities to benefit your company are to:
- Monitor each opportunity through the sales funnel for better sales. CRM solutions help track lead-related data, accompanied with insights, so sales and marketing teams can stay organized, understand where each lead is in the sales process, and know who has worked on each opportunity.
- Use sales monitoring to get real-time performance data. Link sales data into your CRM solution to provide an immediate, accurate picture of sales. With a real-time view of your pipeline, you’ll be aware of any slowdowns and bottlenecks—or if your team won a major deal.
- Plan your next step with insight generation. Focus on what matters most using AI and built-in intelligence to identify the top priorities and how your team can make the most of their time and efforts. For example, sales teams can identify which leads are ready to hand off and which need follow-up.
- Optimize workflows with automation. Build sales quotes, gather customer feedback, and send email campaigns with task automation, which helps streamline marketing, sales, and customer service. Thus, helping eliminate repetitive tasks so your team can focus on high-impact activities.
- Track customer interactions for greater impact. CRM solutions include features that tap into customer behavior and surface opportunities for optimization to help you better understand engagement across various customer touchpoints.
- Connect across multiple platforms for superior customer engagement. Whether through live chat, calls, email, or social interactions, CRM solutions help you connect with customers where they are, helping build the trust and loyalty that keeps your customers coming back.
- Grow with agility and gain a competitive advantage. A scalable, integrated CRM solution built on a security-rich platform helps meet the ever-changing needs of your business and the marketplace. Quickly launch new marketing, e-commerce, and other initiatives and deliver rapid responses to consumer demands and marketplace conditions.
Why implement a CRM solution?
As you define your CRM strategy and evaluate customer relationship management solutions , look for one that provides a complete view of each customer relationship. You also need a solution that collects relevant data at every customer touchpoint, analyzes it, and surfaces the insights intelligently.
Learn how to choose the right CRM for your needs in The CRM Buyer’s Guide for Today’s Business . With the right CRM system, your company helps enhance communications and ensure excellent experiences at each stage of the customer journey, as outlined below:
- Identify and engage the right customers. Predictive insight and data-driven buyer behavior helps you learn how to identify, target, and attract the right leads—and then turn them into customers.
- Improve customer interaction. With a complete view of the customer, every member of the sales team will know a customer’s history, purchasing patterns, and any specific data that’ll help your team provide the most attentive service to each individual customer.
- Track progress across the customer journey. Knowing where a customer is in your overall sales lifecycle helps you target campaigns and opportunities for the highest engagement.
- Increase team productivity. Improved visibility and streamlined processes help increase productivity, helping your team focus on what matters most.
How can a CRM help your company?
Companies of all sizes benefit from CRM software. For small businesses seeking to grow, CRM helps automate business processes, freeing employees to focus on higher-value activities. For enterprises, CRM helps simplify and improve even the most complex customer engagements.
Take a closer look at how a CRM system helps benefit your individual business teams.
Marketing teams
Improve your customers’ journey. With the ability to generate multichannel marketing campaigns, nurture sales-ready leads with targeted buyer experiences, and align your teams with planning and real-time tracking tools, you’re able to present curated marketing strategies that’ll resonate with your customers.
As you gain insights into your brand reputation and market through customized dashboards of data analysis, you’re able to prioritize the leads that matter most to your business and adapt quickly with insights and business decisions fueled by the results of targeted, automated processes.
Sales teams
Empower sellers to engage with customers to truly understand their needs, and effectively win more deals. As the business grows, finding the right prospects and customers with targeted sales strategies becomes easier, resulting in a successful plan of action for the next step in your pipeline.
Building a smarter selling strategy with embedded insights helps foster relationships, boost productivity, accelerate sales performances, and innovate with a modern and adaptable platform. And by using AI capabilities that can measure past and present leading indicators, you can track customer relationships from start to finish and automate sales execution with contextual prompts that delivers a personalized experience and aligns with the buyer’s journey anytime, anywhere.
Customer service teams
Provide customers with an effortless omnichannel experience. With the use of service bots, your customer service teams will have the tools to be able to deliver value and improve engagement with every interaction. Offering personalized services, agents can upsell or cross-sell using relevant, contextual data, and based on feedback, surveys, and social listening, optimize their resources based on real-time service trends.
In delivering a guided, intelligent service supported on all channels, customers can connect with agents easily and quickly resolve their issues, resulting in a first-class customer experience.
Field service teams
Empower your agents to create a better in-person experience. By implementing the Internet of Things (IoT) into your operations, you’re able to detect problems faster—automate work orders, schedule, and dispatch technicians in just a few clicks. By streamlining scheduling and inventory management , you can boost onsite efficiency, deliver a more personalized service, and reduce costs.
By providing transparent communications with real-time technician location tracking, appointment reminders, quotes, contracts, and scheduling information, customers stay connected to your field agents and build trust with your business.
Project service automation teams
Improve your profitability with integrated planning tools and analytics that help build your customer-centric delivery model. By gaining transparency into costs and revenue using robust project planning capabilities and intuitive dashboards, you’re able to anticipate demands, determine resources capacity, and forecast project profitability.
And with the ability to measure utilization with real-time dashboards, you can empower your service professionals to apply those insights to their own workflows and optimize resources at any given time. With visibility into those insights, teams are more likely to simplify processes internally, seamlessly collaborate, and increase productivity.
Why use Dynamics 365 for your CRM solution?
With Dynamics 365 , you get a flexible and customizable solution suited to your business requirements. Choose a standalone application to meet the needs of a specific line of business or use multiple CRM applications that work together as a powerful, comprehensive solution.
Chat with Sales
Available Monday to Friday
8 AM to 5 PM Central Time.
Request we contact you
Have a Dynamics 365 sales expert contact you.
Chat with a Microsoft sales specialist for answers to your Dynamics 365 questions.
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
Observational Studies: Cohort and Case-Control Studies
Jae w. song.
1 Research Fellow, Section of Plastic Surgery, Department of Surgery The University of Michigan Health System; Ann Arbor, MI
Kevin C. Chung
2 Professor of Surgery, Section of Plastic Surgery, Department of Surgery The University of Michigan Health System; Ann Arbor, MI
Observational studies are an important category of study designs. To address some investigative questions in plastic surgery, randomized controlled trials are not always indicated or ethical to conduct. Instead, observational studies may be the next best method to address these types of questions. Well-designed observational studies have been shown to provide results similar to randomized controlled trials, challenging the belief that observational studies are second-rate. Cohort studies and case-control studies are two primary types of observational studies that aid in evaluating associations between diseases and exposures. In this review article, we describe these study designs, methodological issues, and provide examples from the plastic surgery literature.
Because of the innovative nature of the specialty, plastic surgeons are frequently confronted with a spectrum of clinical questions by patients who inquire about “best practices.” It is thus essential that plastic surgeons know how to critically appraise the literature to understand and practice evidence-based medicine (EBM) and also contribute to the effort by carrying out high-quality investigations. 1 Well-designed randomized controlled trials (RCTs) have held the pre-eminent position in the hierarchy of EBM as level I evidence ( Table 1 ). However, RCT methodology, which was first developed for drug trials, can be difficult to conduct for surgical investigations. 3 Instead, well-designed observational studies, recognized as level II or III evidence, can play an important role in deriving evidence for plastic surgery. Results from observational studies are often criticized for being vulnerable to influences by unpredictable confounding factors. However, recent work has challenged this notion, showing comparable results between observational studies and RCTs. 4 , 5 Observational studies can also complement RCTs in hypothesis generation, establishing questions for future RCTs, and defining clinical conditions.
Levels of Evidence Based Medicine
| Level of Evidence | Qualifying Studies |
|---|---|
| I | High-quality, multicenter or single-center, randomized controlled trial with adequate power; or systematic review of these studies |
| II | Lesser quality, randomized controlled trial; prospective cohort study; or systematic review of these studies |
| III | Retrospective comparative study; case-control study; or systematic review of these studies |
| IV | Case-series |
| V | Expert opinion; case report or clinical example; or evidence based on physiology, bench research, or “first principles” |
From REF 1 .
Observational studies fall under the category of analytic study designs and are further sub-classified as observational or experimental study designs ( Figure 1 ). The goal of analytic studies is to identify and evaluate causes or risk factors of diseases or health-related events. The differentiating characteristic between observational and experimental study designs is that in the latter, the presence or absence of undergoing an intervention defines the groups. By contrast, in an observational study, the investigator does not intervene and rather simply “observes” and assesses the strength of the relationship between an exposure and disease variable. 6 Three types of observational studies include cohort studies, case-control studies, and cross-sectional studies ( Figure 1 ). Case-control and cohort studies offer specific advantages by measuring disease occurrence and its association with an exposure by offering a temporal dimension (i.e. prospective or retrospective study design). Cross-sectional studies, also known as prevalence studies, examine the data on disease and exposure at one particular time point ( Figure 2 ). 6 Because the temporal relationship between disease occurrence and exposure cannot be established, cross-sectional studies cannot assess the cause and effect relationship. In this review, we will primarily discuss cohort and case-control study designs and related methodologic issues.

Analytic Study Designs. Adapted with permission from Joseph Eisenberg, Ph.D.

Temporal Design of Observational Studies: Cross-sectional studies are known as prevalence studies and do not have an inherent temporal dimension. These studies evaluate subjects at one point in time, the present time. By contrast, cohort studies can be either retrospective (latin derived prefix, “retro” meaning “back, behind”) or prospective (greek derived prefix, “pro” meaning “before, in front of”). Retrospective studies “look back” in time contrasting with prospective studies, which “look ahead” to examine causal associations. Case-control study designs are also retrospective and assess the history of the subject for the presence or absence of an exposure.
COHORT STUDY
The term “cohort” is derived from the Latin word cohors . Roman legions were composed of ten cohorts. During battle each cohort, or military unit, consisting of a specific number of warriors and commanding centurions, were traceable. The word “cohort” has been adopted into epidemiology to define a set of people followed over a period of time. W.H. Frost, an epidemiologist from the early 1900s, was the first to use the word “cohort” in his 1935 publication assessing age-specific mortality rates and tuberculosis. 7 The modern epidemiological definition of the word now means a “group of people with defined characteristics who are followed up to determine incidence of, or mortality from, some specific disease, all causes of death, or some other outcome.” 7
Study Design
A well-designed cohort study can provide powerful results. In a cohort study, an outcome or disease-free study population is first identified by the exposure or event of interest and followed in time until the disease or outcome of interest occurs ( Figure 3A ). Because exposure is identified before the outcome, cohort studies have a temporal framework to assess causality and thus have the potential to provide the strongest scientific evidence. 8 Advantages and disadvantages of a cohort study are listed in Table 2 . 2 , 9 Cohort studies are particularly advantageous for examining rare exposures because subjects are selected by their exposure status. Additionally, the investigator can examine multiple outcomes simultaneously. Disadvantages include the need for a large sample size and the potentially long follow-up duration of the study design resulting in a costly endeavor.

Cohort and Case-Control Study Designs
Advantages and Disadvantages of the Cohort Study
| Gather data regarding sequence of events; can assess causality |
| Examine multiple outcomes for a given exposure |
| Good for investigating rare exposures |
| Can calculate rates of disease in exposed and unexposed individuals over time (e.g. incidence, relative risk) |
| Large numbers of subjects are required to study rare exposures |
| Susceptible to selection bias |
| May be expensive to conduct |
| May require long durations for follow-up |
| Maintaining follow-up may be difficult |
| Susceptible to loss to follow-up or withdrawals |
| Susceptible to recall bias or information bias |
| Less control over variables |
Cohort studies can be prospective or retrospective ( Figure 2 ). Prospective studies are carried out from the present time into the future. Because prospective studies are designed with specific data collection methods, it has the advantage of being tailored to collect specific exposure data and may be more complete. The disadvantage of a prospective cohort study may be the long follow-up period while waiting for events or diseases to occur. Thus, this study design is inefficient for investigating diseases with long latency periods and is vulnerable to a high loss to follow-up rate. Although prospective cohort studies are invaluable as exemplified by the landmark Framingham Heart Study, started in 1948 and still ongoing, 10 in the plastic surgery literature this study design is generally seen to be inefficient and impractical. Instead, retrospective cohort studies are better indicated given the timeliness and inexpensive nature of the study design.
Retrospective cohort studies, also known as historical cohort studies, are carried out at the present time and look to the past to examine medical events or outcomes. In other words, a cohort of subjects selected based on exposure status is chosen at the present time, and outcome data (i.e. disease status, event status), which was measured in the past, are reconstructed for analysis. The primary disadvantage of this study design is the limited control the investigator has over data collection. The existing data may be incomplete, inaccurate, or inconsistently measured between subjects. 2 However, because of the immediate availability of the data, this study design is comparatively less costly and shorter than prospective cohort studies. For example, Spear and colleagues examined the effect of obesity and complication rates after undergoing the pedicled TRAM flap reconstruction by retrospectively reviewing 224 pedicled TRAM flaps in 200 patients over a 10-year period. 11 In this example, subjects who underwent the pedicled TRAM flap reconstruction were selected and categorized into cohorts by their exposure status: normal/underweight, overweight, or obese. The outcomes of interest were various flap and donor site complications. The findings revealed that obese patients had a significantly higher incidence of donor site complications, multiple flap complications, and partial flap necrosis than normal or overweight patients. An advantage of the retrospective study design analysis is the immediate access to the data. A disadvantage is the limited control over the data collection because data was gathered retrospectively over 10-years; for example, a limitation reported by the authors is that mastectomy flap necrosis was not uniformly recorded for all subjects. 11
An important distinction lies between cohort studies and case-series. The distinguishing feature between these two types of studies is the presence of a control, or unexposed, group. Contrasting with epidemiological cohort studies, case-series are descriptive studies following one small group of subjects. In essence, they are extensions of case reports. Usually the cases are obtained from the authors' experiences, generally involve a small number of patients, and more importantly, lack a control group. 12 There is often confusion in designating studies as “cohort studies” when only one group of subjects is examined. Yet, unless a second comparative group serving as a control is present, these studies are defined as case-series. The next step in strengthening an observation from a case-series is selecting appropriate control groups to conduct a cohort or case-control study, the latter which is discussed in the following section about case-control studies. 9
Methodological Issues
Selection of subjects in cohort studies.
The hallmark of a cohort study is defining the selected group of subjects by exposure status at the start of the investigation. A critical characteristic of subject selection is to have both the exposed and unexposed groups be selected from the same source population ( Figure 4 ). 9 Subjects who are not at risk for developing the outcome should be excluded from the study. The source population is determined by practical considerations, such as sampling. Subjects may be effectively sampled from the hospital, be members of a community, or from a doctor's individual practice. A subset of these subjects will be eligible for the study.

Levels of Subject Selection. Adapted from Ref 9 .
Attrition Bias (Loss to follow-up)
Because prospective cohort studies may require long follow-up periods, it is important to minimize loss to follow-up. Loss to follow-up is a situation in which the investigator loses contact with the subject, resulting in missing data. If too many subjects are loss to follow-up, the internal validity of the study is reduced. A general rule of thumb requires that the loss to follow-up rate not exceed 20% of the sample. 6 Any systematic differences related to the outcome or exposure of risk factors between those who drop out and those who stay in the study must be examined, if possible, by comparing individuals who remain in the study and those who were loss to follow-up or dropped out. It is therefore important to select subjects who can be followed for the entire duration of the cohort study. Methods to minimize loss to follow-up are listed in Table 3 .
Methods to Minimize Loss to Follow-Up
| Exclude subjects likely to be lost |
| Planning to move |
| Non-committal |
| Obtain information to allow future tracking |
| Collect subject's contact information (e.g. mailing addresses, telephone numbers, and email addresses) |
| Collect social security and/or Medicare numbers |
| Maintain periodic contact |
| By telephone: may require calls during the weekends and/or evenings |
| By mail: repeated mailings by e-mail or with stamped, self-addressed return envelopes |
| Other: newsletters or token gifts with study logo |
Adapted from REF 2 .
CASE-CONTROL STUDIES
Case-control studies were historically borne out of interest in disease etiology. The conceptual basis of the case-control study is similar to taking a history and physical; the diseased patient is questioned and examined, and elements from this history taking are knitted together to reveal characteristics or factors that predisposed the patient to the disease. In fact, the practice of interviewing patients about behaviors and conditions preceding illness dates back to the Hippocratic writings of the 4 th century B.C. 7
Reasons of practicality and feasibility inherent in the study design typically dictate whether a cohort study or case-control study is appropriate. This study design was first recognized in Janet Lane-Claypon's study of breast cancer in 1926, revealing the finding that low fertility rate raises the risk of breast cancer. 13 , 14 In the ensuing decades, case-control study methodology crystallized with the landmark publication linking smoking and lung cancer in the 1950s. 15 Since that time, retrospective case-control studies have become more prominent in the biomedical literature with more rigorous methodological advances in design, execution, and analysis.
Case-control studies identify subjects by outcome status at the outset of the investigation. Outcomes of interest may be whether the subject has undergone a specific type of surgery, experienced a complication, or is diagnosed with a disease ( Figure 3B ). Once outcome status is identified and subjects are categorized as cases, controls (subjects without the outcome but from the same source population) are selected. Data about exposure to a risk factor or several risk factors are then collected retrospectively, typically by interview, abstraction from records, or survey. Case-control studies are well suited to investigate rare outcomes or outcomes with a long latency period because subjects are selected from the outset by their outcome status. Thus in comparison to cohort studies, case-control studies are quick, relatively inexpensive to implement, require comparatively fewer subjects, and allow for multiple exposures or risk factors to be assessed for one outcome ( Table 4 ). 2 , 9
Advantages and Disadvantages of the Case-Control Study
| Good for examining rare outcomes or outcomes with long latency |
| Relatively quick to conduct |
| Relatively inexpensive |
| Requires comparatively few subjects |
| Existing records can be used |
| Multiple exposures or risk factors can be examined |
| Susceptible to recall bias or information bias |
| Difficult to validate information |
| Control of extraneous variables may be incomplete |
| Selection of an appropriate comparison group may be difficult |
| Rates of disease in exposed and unexposed individuals cannot be determined |
An example of a case-control investigation is by Zhang and colleagues who examined the association of environmental and genetic factors associated with rare congenital microtia, 16 which has an estimated prevalence of 0.83 to 17.4 in 10,000. 17 They selected 121 congenital microtia cases based on clinical phenotype, and 152 unaffected controls, matched by age and sex in the same hospital and same period. Controls were of Hans Chinese origin from Jiangsu, China, the same area from where the cases were selected. This allowed both the controls and cases to have the same genetic background, important to note given the investigated association between genetic factors and congenital microtia. To examine environmental factors, a questionnaire was administered to the mothers of both cases and controls. The authors concluded that adverse maternal health was among the main risk factors for congenital microtia, specifically maternal disease during pregnancy (OR 5.89, 95% CI 2.36-14.72), maternal toxicity exposure during pregnancy (OR 4.76, 95% CI 1.66-13.68), and resident area, such as living near industries associated with air pollution (OR 7.00, 95% CI 2.09-23.47). 16 A case-control study design is most efficient for this investigation, given the rarity of the disease outcome. Because congenital microtia is thought to have multifactorial causes, an additional advantage of the case-control study design in this example is the ability to examine multiple exposures and risk factors.
Selection of Cases
Sampling in a case-control study design begins with selecting the cases. In a case-control study, it is imperative that the investigator has explicitly defined inclusion and exclusion criteria prior to the selection of cases. For example, if the outcome is having a disease, specific diagnostic criteria, disease subtype, stage of disease, or degree of severity should be defined. Such criteria ensure that all the cases are homogenous. Second, cases may be selected from a variety of sources, including hospital patients, clinic patients, or community subjects. Many communities maintain registries of patients with certain diseases and can serve as a valuable source of cases. However, despite the methodologic convenience of this method, validity issues may arise. For example, if cases are selected from one hospital, identified risk factors may be unique to that single hospital. This methodological choice may weaken the generalizability of the study findings. Another example is choosing cases from the hospital versus the community; most likely cases from the hospital sample will represent a more severe form of the disease than those in the community. 2 Finally, it is also important to select cases that are representative of cases in the target population to strengthen the study's external validity ( Figure 4 ). Potential reasons why cases from the original target population eventually filter through and are available as cases (study participants) for a case-control study are illustrated in Figure 5 .

Levels of Case Selection. Adapted from Ref 2 .
Selection of Controls
Selecting the appropriate group of controls can be one of the most demanding aspects of a case-control study. An important principle is that the distribution of exposure should be the same among cases and controls; in other words, both cases and controls should stem from the same source population. The investigator may also consider the control group to be an at-risk population, with the potential to develop the outcome. Because the validity of the study depends upon the comparability of these two groups, cases and controls should otherwise meet the same inclusion criteria in the study.
A case-control study design that exemplifies this methodological feature is by Chung and colleagues, who examined maternal cigarette smoking during pregnancy and the risk of newborns developing cleft lip/palate. 18 A salient feature of this study is the use of the 1996 U.S. Natality database, a population database, from which both cases and controls were selected. This database provides a large sample size to assess newborn development of cleft lip/palate (outcome), which has a reported incidence of 1 in 1000 live births, 19 and also enabled the investigators to choose controls (i.e., healthy newborns) that were generalizable to the general population to strengthen the study's external validity. A significant relationship with maternal cigarette smoking and cleft lip/palate in the newborn was reported in this study (adjusted OR 1.34, 95% CI 1.36-1.76). 18
Matching is a method used in an attempt to ensure comparability between cases and controls and reduces variability and systematic differences due to background variables that are not of interest to the investigator. 8 Each case is typically individually paired with a control subject with respect to the background variables. The exposure to the risk factor of interest is then compared between the cases and the controls. This matching strategy is called individual matching. Age, sex, and race are often used to match cases and controls because they are typically strong confounders of disease. 20 Confounders are variables associated with the risk factor and may potentially be a cause of the outcome. 8 Table 5 lists several advantages and disadvantages with a matching design.
Advantages and Disadvantages for Using a Matching Strategy
| Advantages | Disadvantages |
|---|---|
| Eliminate influence of measurable confounders (e.g. age, sex) | May be time-consuming and expensive |
| Eliminate influence of confounders that are difficult to measure | Decision to match and confounding variables to match upon are decided at the outset of the study |
| May be a sampling convenience, making it easier to select the controls in a case-control study | Matched variables cannot be examined in the study |
| May improve study efficiency (i.e. smaller sample size) | Requires a matched analysis |
| Vulnerable to overmatching: when matching variable has some relationship with the outcome |
Multiple Controls
Investigations examining rare outcomes may have a limited number of cases to select from, whereas the source population from which controls can be selected is much larger. In such scenarios, the study may be able to provide more information if multiple controls per case are selected. This method increases the “statistical power” of the investigation by increasing the sample size. The precision of the findings may improve by having up to about three or four controls per case. 21 - 23
Bias in Case-Control Studies
Evaluating exposure status can be the Achilles heel of case-control studies. Because information about exposure is typically collected by self-report, interview, or from recorded information, it is susceptible to recall bias, interviewer bias, or will rely on the completeness or accuracy of recorded information, respectively. These biases decrease the internal validity of the investigation and should be carefully addressed and reduced in the study design. Recall bias occurs when a differential response between cases and controls occurs. The common scenario is when a subject with disease (case) will unconsciously recall and report an exposure with better clarity due to the disease experience. Interviewer bias occurs when the interviewer asks leading questions or has an inconsistent interview approach between cases and controls. A good study design will implement a standardized interview in a non-judgemental atmosphere with well-trained interviewers to reduce interviewer bias. 9
The STROBE Statement: The Strengthening the Reporting of Observational Studies in Epidemiology Statement
In 2004, the first meeting of the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) group took place in Bristol, UK. 24 The aim of the group was to establish guidelines on reporting observational research to improve the transparency of the methods, thereby facilitating the critical appraisal of a study's findings. A well-designed but poorly reported study is disadvantaged in contributing to the literature because the results and generalizability of the findings may be difficult to assess. Thus a 22-item checklist was generated to enhance the reporting of observational studies across disciplines. 25 , 26 This checklist is also located at the following website: www.strobe-statement.org . This statement is applicable to cohort studies, case-control studies, and cross-sectional studies. In fact, 18 of the checklist items are common to all three types of observational studies, and 4 items are specific to each of the 3 specific study designs. In an effort to provide specific guidance to go along with this checklist, an “explanation and elaboration” article was published for users to better appreciate each item on the checklist. 27 Plastic surgery investigators should peruse this checklist prior to designing their study and when they are writing up the report for publication. In fact, some journals now require authors to follow the STROBE Statement. A list of participating journals can be found on this website: http://www.strobe-statement.org./index.php?id=strobe-endorsement .
Due to the limitations in carrying out RCTs in surgical investigations, observational studies are becoming more popular to investigate the relationship between exposures, such as risk factors or surgical interventions, and outcomes, such as disease states or complications. Recognizing that well-designed observational studies can provide valid results is important among the plastic surgery community, so that investigators can both critically appraise and appropriately design observational studies to address important clinical research questions. The investigator planning an observational study can certainly use the STROBE statement as a tool to outline key features of a study as well as coming back to it again at the end to enhance transparency in methodology reporting.
Acknowledgments
Supported in part by a Midcareer Investigator Award in Patient-Oriented Research (K24 AR053120) from the National Institute of Arthritis and Musculoskeletal and Skin Diseases (to Dr. Kevin C. Chung).
None of the authors has a financial interest in any of the products, devices, or drugs mentioned in this manuscript.
This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
AI risk management is the process of systematically identifying, mitigating and addressing the potential risks associated with AI technologies. It involves a combination of tools, practices and principles, with a particular emphasis on deploying formal AI risk management frameworks.
Generally speaking, the goal of AI risk management is to minimize AI’s potential negative impacts while maximizing its benefits.
AI risk management and AI governance
AI risk management is part of the broader field of AI governance . AI governance refers to the guardrails that ensure AI tools and systems are safe and ethical and remain that way.
AI governance is a comprehensive discipline, while AI risk management is a process within that discipline. AI risk management focuses specifically on identifying and addressing vulnerabilities and threats to keep AI systems safe from harm. AI governance establishes the frameworks, rules and standards that direct AI research, development and application to ensure safety, fairness and respect for human rights.
Learn how IBM Consulting can help weave responsible AI governance into the fabric of your business.
Why risk management in AI systems matters
In recent years, the use of AI systems has surged across industries. McKinsey reports that 72% of organizations now use some form of artificial intelligence (AI), up 17% from 2023.
While organizations are chasing AI’s benefits—like innovation, efficiency and enhanced productivity—they do not always tackle its potential risks, such as privacy concerns, security threats and ethical and legal issues.
Leaders are well aware of this challenge. A recent IBM Institute for Business Value (IBM IBV) study found that 96% of leaders believe that adopting generative AI makes a security breach more likely. At the same time, the IBM IBV also found that only 24% of current generative AI projects are secured .
AI risk management can help close this gap and empower organizations to harness AI systems’ full potential without compromising AI ethics or security.
Understanding the risks associated with AI systems
Like other types of security risk, AI risk can be understood as a measure of how likely a potential AI-related threat is to affect an organization and how much damage that threat would do.
While each AI model and use case is different, the risks of AI generally fall into four buckets:
Model risks
Operational risks, ethical and legal risks.
If not managed correctly, these risks can expose AI systems and organizations to significant harm, including financial losses, reputational damage, regulatory penalties, erosion of public trust and data breaches .
AI systems rely on data sets that might be vulnerable to tampering, breaches, bias or cyberattacks . Organizations can mitigate these risks by protecting data integrity, security and availability throughout the entire AI lifecycle, from development to training and deployment.
Common data risks include:
- Data security : Data security is one of the biggest and most critical challenges facing AI systems. Threat actors can cause serious problems for organizations by breaching the data sets that power AI technologies, including unauthorized access, data loss and compromised confidentiality.
- Data privacy : AI systems often handle sensitive personal data, which can be vulnerable to privacy breaches, leading to regulatory and legal issues for organizations.
- Data integrity: AI models are only as reliable as their training data. Distorted or biased data can lead to false positives, inaccurate outputs or poor decision-making.
Threat actors can target AI models for theft, reverse engineering or unauthorized manipulation. Attackers might compromise a model’s integrity by tampering with its architecture, weights or parameters, the core components determining an AI model’s behavior and performance.
Some of the most common model risks include:
- Adversarial attacks: These attacks manipulate input data to deceive AI systems into making incorrect predictions or classifications. For instance, attackers might generate adversarial examples that they feed to AI algorithms to purposefully interfere with decision-making or produce bias.
- Prompt injections : These attacks target large language models (LLMs). Hackers disguise malicious inputs as legitimate prompts, manipulating generative AI systems into leaking sensitive data, spreading misinformation or worse. Even basic prompt injections can make AI chatbots like ChatGPT ignore system guardrails and say things that they shouldn’t.
- Model interpretability: Complex AI models are often difficult to interpret, making it hard for users to understand how they reach their decisions. This lack of transparency can ultimately impede bias detection and accountability while eroding trust in AI systems and their providers.
- Supply chain attacks: Supply chain attacks occur when threat actors target AI systems at the supply chain level, including at their development, deployment or maintenance stages. For instance, attackers might exploit vulnerabilities in third-party components used in AI development, leading to data breaches or unauthorized access.
Though AI models can seem like magic, they are fundamentally products of sophisticated code and machine learning algorithms. Like all technologies, they are susceptible to operational risks. Left unaddressed, these risks can lead to system failures and security vulnerabilities that threat actors can exploit.
Some of the most common operational risks include:
- Drift or decay: AI models can experience model drift , a process where changes in data or the relationships between data points can lead to degraded performance. For example, a fraud detection model might become less accurate over time and let fraudulent transactions slip through the cracks.
- Sustainability issues: AI systems are new and complex technologies that require proper scaling and support. Neglecting sustainability can lead to challenges in maintaining and updating these systems, causing inconsistent performance and increased operating costs and energy consumption.
- Integration challenges: Integrating AI systems with existing IT infrastructure can be complex and resource-intensive. Organizations often encounter issues with compatibility, data silos and system interoperability. Introducing AI systems can also create new vulnerabilities by expanding the attack surface for cyberthreats .
- Lack of accountability: With AI systems being relatively new technologies, many organizations don’t have the proper corporate governance structures in place. The result is that AI systems often lack oversight. McKinsey found that just 18 percent of organizations have a council or board with the authority to make decisions about responsible AI governance.
If organizations don’t prioritize safety and ethics when developing and deploying AI systems, they risk committing privacy violations and producing biased outcomes. For instance, biased training data used for hiring decisions might reinforce gender or racial stereotypes and create AI models that favor certain demographic groups over others.
Common ethical and legal risks include:
- Lack of transparency: Organizations that fail to be transparent and accountable with their AI systems risk losing public trust.
- Failure to comply with regulatory requirements: Noncompliance with government regulations such as the GDPR or sector-specific guidelines can lead to steep fines and legal penalties.
- Algorithmic biases: AI algorithms can inherit biases from training data, leading to potentially discriminatory outcomes such as biased hiring decisions and unequal access to financial services.
- Ethical dilemmas : AI decisions can raise ethical concerns related to privacy, autonomy and human rights. Mishandling these dilemmas can harm an organization’s reputation and erode public trust.
- Lack of explainability: Explainability in AI refers to the ability to understand and justify decisions made by AI systems. Lack of explainability can hinder trust and lead to legal scrutiny and reputational damage. For example, an organization’s CEO not knowing where their LLM gets its training data can result in bad press or regulatory investigations.
AI risk management frameworks
Many organizations address AI risks by adopting AI risk management frameworks, which are sets of guidelines and practices for managing risks across the entire AI lifecycle.
One can also think of these guidelines as playbooks that outline policies, procedures, roles and responsibilities regarding an organization’s use of AI. AI risk management frameworks help organizations develop, deploy and maintain AI systems in a way that minimizes risks, upholds ethical standards and achieves ongoing regulatory compliance.
Some of the most commonly used AI risk management frameworks include:
- The NIST AI Risk Management Framework
- The EU AI ACT
ISO/IEC standards
The us executive order on ai, the nist ai risk management framework (ai rmf) .
In January 2023, the National Institute of Standards and Technology (NIST) published the AI Risk Management Framework (AI RMF) to provide a structured approach to managing AI risks. The NIST AI RMF has since become a benchmark for AI risk management.
The AI RMF’s primary goal is to help organizations design, develop, deploy and use AI systems in a way that effectively manages risks and promotes trustworthy, responsible AI practices.
Developed in collaboration with the public and private sectors, the AI RMF is entirely voluntary and applicable across any company, industry or geography.
The framework is divided into two parts. Part 1 offers an overview of the risks and characteristics of trustworthy AI systems. Part 2, the AI RMF Core, outlines four functions to help organizations address AI system risks:
- Govern: Creating an organizational culture of AI risk management
- Map: Framing AI risks in specific business contexts
- Measure: Analyzing and assessing AI risks
- Manage: Addressing mapped and measured risks
The EU Artificial Intelligence Act (EU AI Act) is a law that governs the development and use of artificial intelligence in the European Union (EU). The act takes a risk-based approach to regulation, applying different rules to AI systems according to the threats they pose to human health, safety and rights. The act also creates rules for designing, training and deploying general-purpose artificial intelligence models, such as the foundation models that power ChatGPT and Google Gemini.
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) have developed standards that address various aspects of AI risk management.
ISO/IEC standards emphasize the importance of transparency, accountability and ethical considerations in AI risk management. They also provide actionable guidelines for managing AI risks across the AI lifecycle, from design and development to deployment and operation.
In late 2023, the Biden administration issued an executive order on ensuring AI safety and security. While not technically a risk management framework, this comprehensive directive does provide guidelines for establishing new standards to manage the risks of AI technology.
The executive order highlights several key concerns, including the promotion of trustworthy AI that is transparent, explainable and accountable. In many ways, the executive order helped set a precedent for the private sector, signaling the importance of comprehensive AI risk management practices.
How AI risk management helps organizations
While the AI risk management process necessarily varies from organization to organization, AI risk management practices can provide some common core benefits when implemented successfully.
Enhanced security
AI risk management can enhance an organization’s cybersecurity posture and use of AI security .
By conducting regular risk assessments and audits, organizations can identify potential risks and vulnerabilities throughout the AI lifecycle.
Following these assessments, they can implement mitigation strategies to reduce or eliminate the identified risks. This process might involve technical measures, such as enhancing data security and improving model robustness. The process might also involve organizational adjustments, such as developing ethical guidelines and strengthening access controls.
Taking this more proactive approach to threat detection and response can help organizations mitigate risks before they escalate, reducing the likelihood of data breaches and the potential impact of cyberattacks.
Improved decision-making
AI risk management can also help improve an organization’s overall decision-making.
By using a mix of qualitative and quantitative analyses, including statistical methods and expert opinions, organizations can gain a clear understanding of their potential risks. This full-picture view helps organizations prioritize high-risk threats and make more informed decisions around AI deployment, balancing the desire for innovation with the need for risk mitigation.
Regulatory compliance
An increasing global focus on protecting sensitive data has spurred the creation of major regulatory requirements and industry standards, including the General Data Protection Regulation (GDPR) , the California Consumer Privacy Act (CCPA) and the EU AI Act.
Noncompliance with these laws can result in hefty fines and significant legal penalties. AI risk management can help organizations achieve compliance and remain in good standing, especially as regulations surrounding AI evolve almost as quickly as the technology itself.
Operational resilience
AI risk management helps organizations minimize disruption and ensure business continuity by enabling them to address potential risks with AI systems in real time. AI risk management can also encourage greater accountability and long-term sustainability by enabling organizations to establish clear management practices and methodologies for AI use.
Increased trust and transparency
AI risk management encourages a more ethical approach to AI systems by prioritizing trust and transparency.
Most AI risk management processes involve a wide range of stakeholders, including executives, AI developers, data scientists, users, policymakers and even ethicists. This inclusive approach helps ensure that AI systems are developed and used responsibly, with every stakeholder in mind.
Ongoing testing, validation and monitoring
By conducting regular tests and monitoring processes, organizations can better track an AI system’s performance and detect emerging threats sooner. This monitoring helps organizations maintain ongoing regulatory compliance and remediate AI risks earlier, reducing the potential impact of threats.
Making AI risk management an enterprise priority
For all of their potential to streamline and optimize how work gets done, AI technologies are not without risk. Nearly every piece of enterprise IT can become a weapon in the wrong hands.
Organizations don’t need to avoid generative AI. They simply need to treat it like any other technology tool. That means understanding the risks and taking proactive steps to minimize the chance of a successful attack.
With IBM® watsonx.governance™, organizations can easily direct, manage and monitor AI activities in one integrated platform. IBM watsonx.governance can govern generative AI models from any vendor, evaluate model health and accuracy and automate key compliance workflows.
More from Security
Authentication vs. authorization: what’s the difference.
6 min read - Authentication and authorization are related but distinct processes in an organization’s identity and access management (IAM) system. Authentication verifies a user’s identity. Authorization gives the user the right level of access to system resources. The authentication process relies on credentials, such as passwords or fingerprint scans, that users present to prove they are who they claim to be. The authorization process relies on user permissions that outline what each user can do within a particular resource or network. For example,…
Top 7 risks to your identity security posture
5 min read - Detecting and remediating identity misconfigurations and blind spots is critical to an organization’s identity security posture especially as identity has become the new perimeter and a key pillar of an identity fabric. Let’s explore what identity blind spots and misconfigurations are, detail why finding them is essential, and lay out the top seven to avoid. What are the most critical risks to identity security? Identity misconfigurations and identity blind spots stand out as critical concerns that undermine an organization’s identity…
Intesa Sanpaolo and IBM secure digital transactions with fully homomorphic encryption
6 min read - This blog was made possible thanks to contributions from Nicola Bertoli, Sandra Grazia Tedesco, Alessio Di Michelangeli, Omri Soceanu, Akram Bitar, Allon Adir, Salvatore Sollami and Liam Chambers. Intesa Sanpaolo is one of the most trusted and profitable European banks. It offers commercial banking, corporate investment banking, asset management and insurance services. It is the leading bank in Italy with approximately 12 million customers served through its digital and traditional channels. The Cybersecurity Lab of Intesa Sanpaolo (ISP) needed to…
IBM Newsletters
COMMENTS
Revised on June 22, 2023. A case-control study is an experimental design that compares a group of participants possessing a condition of interest to a very similar group lacking that condition. Here, the participants possessing the attribute of study, such as a disease, are called the "case," and those without it are the "control.".
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes.[1] The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. ... For example, if a disease developed in 1 in 1000 people per year (0.001/year) then in ten years one ...
Examples. A case-control study is an observational study where researchers analyzed two groups of people (cases and controls) to look at factors associated with particular diseases or outcomes. Below are some examples of case-control studies: Investigating the impact of exposure to daylight on the health of office workers (Boubekri et al., 2014).
A case control study is a retrospective, observational study that compares two existing groups. Researchers form these groups based on the existence of a condition in the case group and the lack of that condition in the control group. They evaluate the differences in the histories between these two groups looking for factors that might cause a ...
A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure. The study involved comparing a group of former lifeguards that had developed cancer on their cheeks and noses (cases) to a group of lifeguards without this type of cancer (controls) and assess their prior exposure to ...
Case-Control study design is a type of observational study. In this design, participants are selected for the study based on their outcome status. ... 'Individual matching' is one common technique used in case-control study. For example, in the above mentioned metabolic syndrome and psoriasis, we can decide that for each case enrolled in ...
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes. The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. ... For example, if a disease developed in 1 in 1000 people per year (0.001/year) then in ten years one ...
Case-control studies are one of the major observational study designs for performing clinical research. The advantages of these study designs over other study designs are that they are relatively quick to perform, economical, and easy to design and implement. Case-control studies are particularly appropriate for studying disease outbreaks, rare diseases, or outcomes of interest. This article ...
Abstract. Case-control studies are observational studies in which cases are subjects who have a characteristic of interest, such as a clinical diagnosis, and controls are (usually) matched subjects who do not have that characteristic. After cases and controls are identified, researchers "look back" to determine what past events (exposures ...
Case-control studies are therefore placed low in the hierarchy of evidence. [citation needed] Examples. One of the most significant triumphs of the case-control study was the demonstration of the link between tobacco smoking and lung cancer, by Richard Doll and Bradford Hill.
Moreover, a recent survey found that the large majority of case-control studies do not sample cases and control subjects from a cohort with fixed membership; rather, they sample from dynamic populations with variable membership. 1 Of all case-control studies involving incident cases, 82% sampled from a dynamic population; only 18% of ...
Case Control. In a Case-Control study there are two groups of people: one has a health issue (Case group), and this group is "matched" to a Control group without the health issue based on characteristics like age, gender, occupation. In this study type, we can look back in the patient's histories to look for exposure to risk factors that ...
Case-control studies are a type of observational epidemiological study that involve comparing two groups of individuals; one group with a defined outcome and the other without (normal). ... Example 2. There is a subset of case-control studies known as "nested case-control" studies. In this study type, patients that will be assigned to case ...
Case-control studies. Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups.
A case-control study is a retrospective study that looks back in time to find the relative risk between a specific exposure (e.g. second hand tobacco smoke) and an outcome (e.g. cancer). A control group of people who do not have the disease or who did not experience the event is used for comparison. The goal is figure out the relationship ...
The DES Case-Control Study. A classic example of the efficiency of the case-control approach is the study (Herbst et al.: N. Engl. J. Med. Herbst et al. (1971;284:878-81) that linked in-utero exposure to diethylstilbesterol (DES) with subsequent development of vaginal cancer 15-22 years later. In the late 1960s, physicians at MGH identified a ...
Design. In a case-control study, a number of cases and noncases (controls) are identified, and the occurrence of one or more prior exposures is compared between groups to evaluate drug-outcome associations ( Figure 1 ). A case-control study runs in reverse relative to a cohort study. 21 As such, study inception occurs when a patient ...
Karin B. Yeatts, PhD, MS. Case-Control StudiesCase-control studies are used to determine if there is an association between an exposure and a spe. ific health outcome. These studies proceed from effect (e.g. health outcome, condition, disease) to cause (exposure). Case-control studies assess whether exposure is disproportionately distributed ...
A case-control study can help provide extra insight on data that has already been collected. A case-control study is a way of carrying out a medical investigation to confirm or indicate what is ...
Case control studies are observational because no intervention is attempted and no attempt is made to alter the course of the disease. The goal is to retrospectively determine the exposure to the risk factor of interest from each of the two groups of individuals: cases and controls. ... Fictitious Example There is a suspicion that zinc oxide ...
Case-control study examples can only be retrospective, as it is conducted on the basis of archival data. Often, the source of information in the case-control studies is the history of the disease, which is in the archives of medical institutions, the memories of patients or their relatives in the context of an interview or by the results of the ...
Essential types of case studies . There are many types of case studies available to writers that they choose from in their strive to elaborate a certain instance and tailor the material for better digestibility by readers. The following is a short overview of the main types of case studies and their purposes: Illustrative
A case-control study is designed to help determine if an exposure is associated with an outcome (i.e., disease or condition of interest). In theory, the case-control study can be described simply. ... An example of (2) would be a study of risk factors for uveal melanoma, or corneal ulcers. Since case-control studies start with people known to ...
For example, sales teams can identify which leads are ready to hand off and which need follow-up. Optimize workflows with automation. Build sales quotes, gather customer feedback, and send email campaigns with task automation, which helps streamline marketing, sales, and customer service. Thus, helping eliminate repetitive tasks so your team ...
Cohort studies and case-control studies are two primary types of observational studies that aid in evaluating associations between diseases and exposures. In this review article, we describe these study designs, methodological issues, and provide examples from the plastic surgery literature. Keywords: observational studies, case-control study ...
For example, a fraud detection model might become less accurate over time and let fraudulent transactions slip through the cracks. Sustainability issues: AI systems are new and complex technologies that require proper scaling and support. Neglecting sustainability can lead to challenges in maintaining and updating these systems, causing ...