Last updated 27/06/24: Online ordering is currently unavailable due to technical issues. We apologise for any delays responding to customers while we resolve this. For further updates please visit our website: https://www.cambridge.org/news-and-insights/technical-incident
We use cookies to distinguish you from other users and to provide you with a better experience on our websites. Close this message to accept cookies or find out how to manage your cookie settings .

Login Alert
- > Journals
- > Epidemiology & Infection
- > Volume 149
- > COVID-19 symptoms: a case–control study, Portugal,...

Article contents
Introduction, case definition, covid-19 suspected cases, covid-19 symptoms, data availability statement, covid-19 symptoms: a case–control study, portugal, march–april 2020.
Published online by Cambridge University Press: 19 February 2021
- Supplementary materials
COVID-19, although a respiratory illness, has been clinically associated with non-respiratory symptoms. We conducted a negative case–control study to identify the symptoms associated with SARS-CoV-2-positive results in Portugal. Twelve symptoms and signs included in the clinical notification of COVID-19 were selected as predictors, and the dependent variable was the RT-PCR test result. The χ 2 tests were used to compare notified cases on sex, age group, health region and presence of comorbidities. The best-fit prediction model was selected using a backward stepwise method with an unconditional logistic regression. General and gastrointestinal symptoms were strongly associated with a positive test ( P < 0.001). In this sense, the inclusion of general symptoms such as myalgia, headache and fatigue, as well as diarrhoea, together with actual clinical criteria for suspected cases, already updated and included in COVID-19 case definition, can lead to increased identification of cases and represent an effective strength for transmission control.
COVID-19, the illness caused by SARS-CoV-2 virus, has a range of flu-like clinical manifestations, including cough, fever, fatigue, myalgia and shortness of breath [ Reference Rothan and Byrareddy 1 ]. Although resembling a common cold, this infection can cause serious respiratory illness, such as pneumonia and acute respiratory distress syndrome, especially in high-risk individuals [ Reference Huang 2 ]. Diagnosis of COVID-19 is usually based on the detection of SARS-CoV-2 by a reverse transcription polymerase-chain reaction (RT-PCR) testing of oropharyngeal or nasopharyngeal swabs, tracheal aspirate or bronchoalveolar lavage samples [ Reference Pascarella 3 ]. Patients with moderate or severe COVID-19 are usually hospitalised for observation and supportive care, since there is currently no specific treatment [ Reference Sanders 4 ]. Early in the pandemic, the presence of non-respiratory symptoms, such as gastrointestinal and smell and taste disorders, was widely reported [ Reference Nobel 5 , Reference Beltrán-Corbellini 6 ]. Due to this, attention to COVID-19 patients with non-classic symptoms has been heightened, as well as their predictive value for test positivity [ Reference Nobel 5 , Reference Jin 7 , Reference Tostmann 8 ].
The Portuguese National Epidemiological Surveillance System (SINAVE) is an electronic epidemiological surveillance system of all nationally notifiable diseases [ 9 ]. Notification is exclusively and compulsorily online, where clinicians and laboratories report each suspect case in a clinical and laboratorial disease-specific form, respectively [ 10 ]. The COVID-19 case report form was created in January 2020, and includes a clinical section with symptoms and signs for inquiry, based on international guidelines. The first diagnosed case of COVID-19 in Portugal was on 1 March, a symptomatic male with fever, cough and myalgia, and a recent travel history to a country with an active COVID-19 outbreak [ 11 ].
This study aims to better understand the clinical presentation of COVID-19 cases at the time of notification in Portugal, in order to update surveillance components. We aimed to identify which symptoms, at the time of notification, were associated with a positive RT-PCR result for SARS-CoV-2 among suspected cases in mainland Portugal between 1 March and 1 April 2020.
For surveillance purposes, the national case definition aligned with guidance from the World Health Organization and the European Centre for Disease Control and Prevention (ECDC) [ 12 , 13 ]. The criteria for testing until 8 March were: the presence of fever and/or cough and/or shortness of breath, in addition to an epidemiological link with a confirmed case or recent travel history to an affected country (the list of countries was frequently updated by the Portuguese Directorate-General of Health (DGS), according to the COVID-19 risk of transmission). On 9 March, the criteria for SARS-CoV-2 testing were widened to include hospitalised cases with severe pneumonia and no other apparent cause. On 26 March, Portugal entered the mitigation phase, and the criteria for testing were further expanded to include all cases of acute respiratory distress syndrome with cough or fever [ 13 ].
We extracted retrospective surveillance data on all COVID-19 suspected cases notified to SINAVE until 1 April 2020. Socio-demographic data were collected from each case report form, being automatically fed by the National Patient Record System. Data on clinical symptoms and signs were reported by clinicians on each case report form. An automatised procedure using structured query language algorithm was used to clean and merge both clinical and laboratory SINAVE databases. Posteriorly, a team of clinicians and epidemiologists cleaned, deduplicated, reviewed and cross-checked the data on each suspect case notification. Because completeness of the symptom variables ranged from 33.7% to 46.6%, we selected only those notifications with complete information on symptom variables for analysis.
Cases were defined as individuals with an RT-PCR-positive test result for SARS-CoV-2 virus and compared to controls, defined as all notifications on individuals with an RT-PCR-negative test result for SARS-CoV-2. Controls were chosen as we wanted to better understand the clinical presentation of COVID-19 cases compared to those with similar clinical presentation. No matching methods were used. All suspected cases that met the test criteria and were in mainland Portugal during the study period were tested and included in this study, since COVID-19 suspected cases notification in SINAVE is compulsory nationally. All 12 symptoms and signs included in the clinical notification of COVID-19 were selected as predictors (fever as tympanic temperature equal or above 38 °C, cough, shortness of breath, headache, myalgia, joint pain, fatigue, sore throat, chest pain, diarrhoea, nausea and abdominal pain). The dependent variable was the RT-PCR test result. The χ 2 tests were used to compare notified cases on sex, age group, health region and presence of comorbidities, defined as a binary variable on having a prior diagnosed chronic medical condition. Symptoms were first analysed using unconditional univariate logistic regression, assessed by calculating odds ratios and 95% confidence intervals. For model selection, a backward stepwise method was performed. To correct for possible confounding, we started with all variables of the study, a multiple adjustment and carried out a multivariate logistic regression. Variables with a P -value <0.001 in univariate analysis were included in the initial model. The best-fit prediction model was selected by choosing the one with the lowest Bayesian Information Criterion (BIC) score. Analyses were performed using STATA v.16 (Statacorp, Texas, USA).
Aggregated data were collected in the scope of national epidemiological surveillance, requiring no supplementary ethical clearance. Confidentiality and anonymity were protected, as no individual cases are identifiable in this analysis.
From 51 726 COVID-19 suspected cases notifications, 11 442 had sufficiently complete symptom data for analysis: 2031 (15.96%) tested positive for SARS-CoV-2. Among all COVID-19 suspected cases, 56.98% were female ( Table 1 ), although this proportion was slightly lower among cases (52.1%, P < 0.001). Median age of controls was 43 years ( s.d. ± 22.6), while among cases was 50 years ( s.d. ± 19.8). The North region was the most affected area, with circa 50% of test-positive cases. A larger proportion of individuals in the SARS-CoV-2 test-positive group had comorbid conditions ( P < 0.001).
Table 1. Description of COVID-19 notifications with complete data, as of date of notification, by SARS-CoV-2 test result, Portugal, March–April 2020 ( n = 11 442)

Cases and controls differed significantly on age group, sex, health region and presence of comorbidities. Because cases and controls were not matched, we included these variables in further analysis of symptoms for multiple adjustment.
Among test-positive cases, cough (73.0%, n = 1483), fever (59.7%, n = 1212), myalgia (43.9%, n = 891), headache (40.0%, n = 812) and fatigue (38%, n = 771) were most frequently reported ( Table 2 ).
Table 2. Frequency and univariate association of COVID-19 symptoms with test outcome, among SINAVE notified cases, Portugal, March–April 2020 ( n = 11 442)

Bold significants P <0.05.
a Symptoms, age group, sex, health region and comorbidities adjusted.
At the time of notification, the presence of general symptoms such as fever, myalgia, arthralgia, headache and fatigue, as well as gastrointestinal symptoms (diarrhoea and nausea or vomiting) was positively associated with COVID-19. Symptoms of chest pain, shortness of breath and abdominal pain were not associated with a positive test result in the univariate analysis.
For symptoms included in the case definition (presence of fever or cough or shortness of breath), only cases presenting with fever (alone or in combination with other symptoms) were strongly associated with a positive test for SARS-CoV- 2 (crude odds ratio (OR) 2.29, 95% CI 2.08–2.53). Those presenting with cough, alone or in combination with other symptoms, were 20% less likely to test positive for SARS-CoV-2 virus (95% CI 0.72–0.89) and for those presenting only with shortness of breath, the association with positive test outcome was not statistically significant (crude OR 0.94, 95% CI 0.84–1.05).
After multiple adjustment for symptoms, as well as age group, sex and health region, the best-fit model did not retain nausea or vomiting, arthralgia and presence of comorbidities ( Table 3 ). In this multivariate model, the presence of fever, myalgia, headache, fatigue or diarrhoea was strongly associated with the outcome of positive SARS-CoV-2 test result.
Table 3. Multivariate model on COVID-19 symptoms among SINAVE notified cases, Portugal, March–April 2020 ( n = 11 442)

a Symptoms, age group, sex and health region adjusted.
General symptoms on this model were strongly associated with a positive test. Those who had fever were almost twice as likely to have a positive test as those presenting without fever (adjusted OR (aOR) 1.96, 95% CI 1.76–2.17). For respiratory symptoms, the presence of cough or sore throat was negatively associated with COVID-19 test positivity ( P < 0.001). Diarrhoea increased by 42% the odds of testing positive (aOR 1.42, 95% CI 1.22–1.65). Running the same model only with multiple adjustment for symptoms, without including age, sex, health region and presence of comorbidities (possible cofounders), led to the same conclusions within groups of symptoms (Supplementary Table S1).
Based on the results presented, symptoms most prevalent in SARS-CoV-2-positive cases were cough and fever, demonstrating testing criteria previously described in case definition. Nevertheless, we acknowledge also that myalgia, fatigue and headache, classified as general symptoms, were presented each in more than one-third of COVID-19 cases. Indeed, ECDC last updated case definition criteria on 29 May 2020, acknowledging additional less specific symptoms to be considered in clinical criteria. Headache, chills, myalgia, fatigue, vomiting and/or diarrhoea were described as to be considered [ 14 ].
In our study, non-respiratory symptoms, including general and gastrointestinal symptoms (diarrhoea), were strongly associated with a positive test for SARS-CoV-2. Based on 12 symptoms analysed, the most parsimonious model retained nine symptoms with the strongest association. Presence of fever, myalgia, headache, fatigue or diarrhoea was associated with a COVID-19 laboratory confirmation. Compared with other respiratory viruses, fatigue, headache and myalgia were more common among human coronavirus-infected patients [ Reference Friedman 15 ]. This study highlights the predictive value of general non-respiratory symptoms as a differential tool to distinguish COVID-19 cases in the universe of respiratory symptoms patients.
This is not the first study where respiratory symptoms in COVID-19 cases played a minor role in predicting laboratory test results for SARS-CoV-2 [ Reference Nobel 5 , Reference Tostmann 8 ]. Although respiratory symptoms, such as cough, are frequent among COVID-19 cases and other human coronavirus infections, in our study, COVID-19 cases report less cough comparing to other respiratory viruses and less shortness of breath than other human coronaviruses [ Reference Friedman 15 ]. Furthermore, some symptoms initially not diagnosed or not associated with this virus are being reported, such as smell and taste disorders [ Reference Beltrán-Corbellini 6 ]. In consequence, the addition of general and gastrointestinal symptoms proven to be strongly associated with a positive test for SARS-CoV-2 is an asset on cases identification and resource-saving. In fact, this study contributes to the evidence that supports last updates on COVID-19 case definitions, highlighting reported less specific symptoms [ 14 ].
This study has some limitations, as it reflects the clinical presentation of suspected and confirmed cases of COVID-19 at the time of notification. This means that we were assessing early symptoms in some cases, and several days of symptoms in others. Although methods exist to deal with missing data, completeness of data was a major issue in this analysis: due to poor completeness, we opted to analyse complete case reports to improve confidence in our results, though we cannot exclude the presence of a selection bias. In this sense, we compared our sample with all COVID-19 suspected cases regarding age, sex, presence of comorbidities and health region. Our sample was younger, had higher female proportion and reported less comorbidities at the time of notification ( P < 0.001) (further details in Supplementary material S2). Although there is evidence on sex differences regarding COVID-19 mortality, the effect of sex on disease presentation and diagnosis is still not clear [ Reference Gebhard 16 , Reference Palaiodimos 17 ]. There is also evidence on older age groups having a higher risk of atypical disease presentation (asthenia, delirium, fall), which is likely related to the higher prevalence of comorbidities, being one of the variables that we adjusted for in our analysis [ Reference Godaert 18 ]. Furthermore, due to the younger mean age in this sample, it is expected that the occurrence of SARS-CoV-2-positive test is higher in this group due to higher probability of typical clinical presentation, possibly overestimating the reported magnitude of the association. Individuals in our sample had a lower prevalence of comorbidities, leading to a likely underestimation of the association between having a prior medical precondition and a positive test result, since having the first increases the risk for SARS-CoV-2 infection [ Reference Jain and Yuan 19 ]. In this comparison, variables presented small statistically significant differences, in both directions, and not surprisingly due to correspondent population and sample sizes. Due to the study design, identification of symptoms was dependent on accurate clinical documentation on SINAVE predefined questionnaire. Moreover, we acknowledge that some symptom misclassification likely exists, but expect that it is non-differential, as test outcomes were unknown at the time of their documentation.
Our results can be compared with the settings using the same case definition and similar surveillance system, due to comprehensiveness of detection and reporting of patients.
These results highlight that general and gastrointestinal symptoms, at the time of notification, are strongly associated with a positive test for SARS-CoV-2. In contrast, the presence of respiratory symptoms was less likely to lead to a positive test for SARS-CoV-2. Based on our findings, respiratory symptoms, such as cough, although frequent among cases, are negatively associated with COVID-19 case status. In this sense, the inclusion of general symptoms such as myalgia, headache and fatigue, as well as diarrhoea, together with actual clinical criteria for suspected cases, already updated and included in COVID-19 case definition, can lead to increased identification of cases and represent an effective strength for transmission control.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S095026882100042X
The data that support the findings of this study are available from the Portuguese Directorate-General of Health (DGS). Restrictions apply to the availability of these data, which were used under licence for this study. Data are available from the authors with the permission of DGS.
Acknowledgements
As this is a collaborative work, we would like to thank all public health teams performing case and contact investigation at local and regional levels, the Directorate-General of Health COVID-19 Task-Force members. We also acknowledge the Porto Public Health Institute (ISPUP) COVID-19 Task-Force for criticizing study design and data analysis. This study relies on secondary data from the National Epidemiological Surveillance System and so, we would like to thank all medical notifiers. We also would like to acknowledge Dr Neil Saad for all inputs regarding overall study concept and data analysis.
Author contributions
MPD, RSM, HL, CC and RM conceived the study. MPD wrote the manuscript. RSM supervised the overall study. RM was responsible for data acquisition. MPD and CC did data cleaning and MPD analysed the data. RSM, DA and LH critically revised the manuscript.
Disclosures
The contents of this article are solely the responsibility of the authors and do not necessarily represent the views of the affiliated institutions. We declare that we received no funding.
Conflict of interest
Authors contributed equally to the manuscript.

Duque et al. supplementary material
This article has been cited by the following publications. This list is generated based on data provided by Crossref .
- Google Scholar
View all Google Scholar citations for this article.
Save article to Kindle
To save this article to your Kindle, first ensure [email protected] is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about saving to your Kindle .
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
Find out more about the Kindle Personal Document Service.
- M. Perez Duque (a1) (a2) (a3) , H. Lucaccioni (a1) (a2) , C. Costa (a1) , R. Marques (a1) , D. Antunes (a3) , L. Hansen (a4) and R. Sá Machado (a1)
- DOI: https://doi.org/10.1017/S095026882100042X
Save article to Dropbox
To save this article to your Dropbox account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your Dropbox account. Find out more about saving content to Dropbox .
Save article to Google Drive
To save this article to your Google Drive account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your Google Drive account. Find out more about saving content to Google Drive .
Reply to: Submit a response
- No HTML tags allowed - Web page URLs will display as text only - Lines and paragraphs break automatically - Attachments, images or tables are not permitted
Your details
Your email address will be used in order to notify you when your comment has been reviewed by the moderator and in case the author(s) of the article or the moderator need to contact you directly.
You have entered the maximum number of contributors
Conflicting interests.
Please list any fees and grants from, employment by, consultancy for, shared ownership in or any close relationship with, at any time over the preceding 36 months, any organisation whose interests may be affected by the publication of the response. Please also list any non-financial associations or interests (personal, professional, political, institutional, religious or other) that a reasonable reader would want to know about in relation to the submitted work. This pertains to all the authors of the piece, their spouses or partners.
Introduction
Materials and methods, acknowledgements, statement of ethics, conflict of interest statement, funding sources, author contribution, data availability statement, risk of covid-19 in health professionals: a case-control study, portugal.
- Split-Screen
- Article contents
- Figures & tables
- Supplementary Data
- Peer Review
- Open the PDF for in another window
- Get Permissions
- Cite Icon Cite
- Search Site
Héloïse Lucaccioni , Cristina Costa , Mariana Perez Duque , Sooria Balasegaram , Rita Sá Machado; Risk of COVID-19 in Health Professionals: A Case-Control Study, Portugal. Port J Public Health 28 December 2021; 39 (3): 137–144. https://doi.org/10.1159/000519472
Download citation file:
- Ris (Zotero)
- Reference Manager
Introduction: Health professionals face higher occupational exposure to SARS-CoV-2. We aimed to estimate the risk of COVID-19 test positivity in health professionals compared to non-health professionals. Methods: We conducted a test-negative case-control study using Portuguese national surveillance data (January to May 2020). Cases were suspected cases who tested positive for SARS-CoV-2; controls were suspected cases who tested negative. We used multivariable logistic regression modelling to estimate the odds ratio of a positive COVID-19 test (RT-PCR; primary outcome), comparing health professionals and non-health professionals (primary exposure), and adjusting for the confounding effect of demographic, clinical, and epidemiological characteristics, and the modification effect of the self-reported epidemiological link (i.e., self-reported contact with a COVID-19 case or person with COVID-19-like symptoms). Results: Health professionals had a 2-fold higher risk of a positive COVID-19 test result (aOR = 1.89, 95% CI 1.69–2.11). However, this association was strongly modified by the self-report of an epidemiological link such that, among cases who did report an epidemiological link, being a health professional was a protective factor (aOR = 0.90, 95% CI 0.82–0.98). Conclusion: Our findings suggest that health professionals might be primarily infected by unknown contacts, plausibly in the healthcare setting, but also that their occupational exposure does not systematically translate into a higher risk of transmission. We suggest that this could be interpreted in light of different types and timing of exposure, and variability in risk perception and associated preventive behaviours.
Introdução: Os profissionais de saúde têm uma maior exposição profissional à SARS-CoV-2. O objetivo era estimar o risco de testar positivo para SARS-CoV-2 em profissionais de saúde. Métodos: Foi realizado um estudo teste-negativo caso-controlo utilizando os dados de vigilância epidemiológica nacional (Janeiro–Maio 2020). Casos foram definidos como casos suspeitos que testaram positivo para SARS-CoV-2 (RTPCR), e os controlos como casos suspeitos que testaram negativo. Foi aplicado um modelo de regressão logística multivariável para estimar o odds ratio de teste positivo para SARS-CoV-2, comparando profissionais de saúde e não profissionais de saúde, ajustado para as características demográficas, clínicas e epidemiológicas, e a modificação de efeito com o autorrelato duma ligação epidemiológica (i.e., contacto auto-reportado com um caso COVID-19 ou uma pessoa com sintomas semelhantes aos da COVID-19). Resultados: Os profissionais de saúde tiveram um risco duas vezes maior de testar positivo para SARS-CoV-2 (aOR = 1.89, 95% CI 1.69–2.11). No entanto, esta associação era fortemente modificada pelo autorrelato de uma ligação epidemiológica, de tal forma que entre os casos que relataram uma ligação epidemiológica, ser profissional de saúde revelou-se fator de proteção (aOR = 0.90, 95% CI 0.82–0.98). Conclusão: Os nossos resultados sugerem que os profissionais de saúde podem estar infetados principalmente por contactos desconhecidos, plausivelmente em instituições de saúde, e a exposição profissional não se traduz sistematicamente num maior risco de transmissão. Isto poderá ser interpretado à luz de diferentes tipos e tempos de exposição, e da variabilidade na perceção do risco e dos comportamentos preventivos associados.
Palavras Chave COVID-19, SARS-CoV-2, Profissionais de saúde, Portugal
Health professionals are known to be disproportionally affected during public health emergencies [1-3]. In the COVID-19 pandemic, they represent a non-negligible proportion of all cases [4-8]. Particularly in the early phase of the pandemic, the risk of exposure and transmission to health professionals has been fuelled by uncertainty around the characteristics of this new virus, prolonged and close exposure to patients, inadequate use of personal protective equipment (PPE), sudden increased workload, and shortages of PPE [9- 15 ]. In Portugal, health professionals evaluated themselves at high risk and estimated to be poorly prepared to respond to the COVID-19 pandemic [ 16 ].
While studies that investigate the burden of the COVID-19 pandemic on health professionals and risk factors associated with SARS-CoV-2 infections in health professionals have multiplied over the past year of the pandemic, few have addressed the risk to health professionals compared to the general population. It was suggested that infections in health professionals followed the same trends as in patients [ 17 ]. Transmission probability in the primary care setting, characterized by short periods of contact with patients, was also estimated to be lower than transmission in household settings with prolonged close contacts, and to be efficiently addressed by adequate use of PPE [ 18 ]. Furthermore, despite a higher risk associated with specific care [ 19 ], various studies showed that the proportion of cases did not differ significantly between health professionals providing care and non-medical staff [ 17, 20 ]. Yet, in a cohort study conducted in the UK [ 21 ], healthcare workers were found to be at a 7-fold higher risk of severe COVID-19 compared to other occupational groups classified as non-essential workers.
In Portugal, the risk of COVID-19 in health professionals compared to those who are not health professionals have not been well described. We conducted a test-negative case-control study using national surveillance data to estimate the risk of COVID-19 in health professionals compared to non-health professionals.
Study Design
We conducted a test-negative case-control study to assess whether being a health professional was associated with a positive COVID-19 test. The test-negative case-control study design follows the same principle as a standard case-control study but differs in the way cases and controls are selected [ 22 ]. Indeed, cases are individuals who test positive for the outcome (i.e., SARS-CoV-2), whereas controls are individuals who are also tested but with a negative result. The study population is not necessarily representative of the whole population of cases (e.g., mild or asymptomatic cases are less likely to be tested), but both confirmed cases and negative cases belong to the same source population with similar factors and criteria leading them to be tested. Indeed, testing rates are expected to be similar among cases and controls, since the “selection forces” (i.e., testing criteria, access to test, etc.) apply consistently to all individuals who undergo testing. By its very nature, the test-negative case-control design provides relevant insights for the epidemiological knowledge and public health practice, while reducing the costs, data-collection efforts, and duration associated with other types of studies [ 23 ].
The first confirmed case of COVID-19 was reported in Portugal on March 2, 2020, and the first peak occurred on March 23–25, 2020. From January 2020, a case-report form was available through the electronic platform of the National Epidemiological Surveillance System (SINAVE). A confirmed case was an individual with a positive test (RT-PCR) for SARS-CoV-2, independently of clinical presentation.
Study Population
The study population comprised all notifications with a laboratory result reported through SINAVE between January 27 and June 6, 2020. We excluded notifications of individuals <18 years or >69 years old to retain the main working-age groups. Observations without information on the health professional status were excluded ( n = 11,264, 7%), as well as observations with missing data on any of the other variables of interest ( n = 82,885, 63%).
The variables of interest were those reported in the case-report form from SINAVE. The primary exposure was health professional/non-health professional status. Health professional designates any professionally active worker in the health sector, including medical and non-medical staff who provide care (e.g., doctors, nurses, auxiliaries, etc.) or not (e.g., pharmacists, health technicians, radiologists, etc.), and other professionals in healthcare settings (e.g., security guards, cleaners, receptionists, etc.).
The other variables of interest were demographic and geographical characteristics, clinical presentation, and epidemiological characteristics. Demographic and geographical characteristics were sex, age groups, and region. The clinical presentation referred to the clinical signs or symptoms at the time of notification, classified in two categories: “main symptoms” that designates any of the symptoms of the testing criteria (i.e., fever and/or cough and/or shortness of breath and/or acute respiratory distress), and “other symptoms” when none of the main symptoms was reported but any other symptoms from the list of symptoms available in the case-report form (e.g., runny nose, odynophagia, headache, abdominal pain, chest pain, joint pain, muscular pain, nausea/vomiting, diarrhoea) or no symptoms at all. The epidemiological characteristics were international travel history during the potential incubation period (i.e., 14 days before symptoms onset, or before testing if no symptoms), and self-reported epidemiological link (i.e., self-reported contact with a COVID-19 case or a person with COVID-19-like symptoms). The variables are further described in the online supplementary material 1 (for all online suppl. material, see www.karger.com/doi/10.1159/000519472 ).
Data Collection
Pre-processed data were extracted from SINAVE on June 22, 2020. They consisted of de-duplicated medical and laboratory notifications for each individual, such that only one record per individual was kept even if multiple tests were conducted during the study period. More precisely, the data contained the record associated with the first positive laboratory result (if any), or the most recent negative result (if no positive test result was ever reported). Consequently, an individual could only be counted once in the study as either a case (at least one positive test result) or a control (only a negative test result).
Statistical Analysis
We performed χ 2 tests to investigate the difference in the distribution of health professionals, demographics, and clinical and epidemiological characteristics among cases and controls ( p < 0.05). We used a multivariable logistic regression model to estimate the odds ratio and 95% confidence interval of a positive COVID-19 test (primary outcome) in health professionals compared to non-health professionals (primary exposure), adjusted for age, sex, region, symptoms, international travel history, and with an interaction term for the self-reported epidemiological link. The covariates included in the analysis were considered based on prior knowledge of COVID-19 epidemiology and potential confounders. We adopted a stepwise backward selection method, including all these relevant covariates at the start of the analysis, and removing successively the non-significant covariates, if any.
To further assess the robustness of our findings, we conducted a sensitivity analysis with different health professional groups (i.e., doctors, nurses, clinical support staff, health technicians [including first responders/paramedics], administrative staff, and unspecified occupation) compared to non-health professionals (see online suppl. material 2).
A total of 48,459 observations were included, of which 6,611 (13.64%) were confirmed cases. Health professionals represented 6,686 (13.80%) of all observations, and 20.27% of all confirmed cases (Table 1 ). The proportion of cases was higher in health professionals (20.04 vs. 12.62%, p < 0.001). The sex distribution was different between cases and controls ( p = 0.013), although the difference was negligible (cases were 14.10% among men and 13.32% among women). Age groups were unequally distributed ( p < 0.001), with the highest proportion of cases among 50–59 year olds. An epidemiological link and international travel history were associated with cases: 29.32% of individuals with an epidemiological link and 19.91% with travel history tested positive ( p < 0.001). The proportion of cases was slightly higher among individuals with symptoms other than the main symptoms (15.81 vs. 12.85%, p < 0.001).
Univariable associations between the health professional status and variables of interest, Portugal, January to May 2020

In the crude analysis, health professionals were significantly more likely to have had a positive COVID-19 test (OR = 1.74, 95% CI 1.62–1.86). The final model retained all covariates, controlling for the confounding effect of age, sex, region, travel history, symptoms, and the modification effect of the self-reported epidemiological link (Table 2 ). Health professionals were still strongly associated with a positive COVID-19 test (aOR = 1.89, 95% CI 1.69–2.11). However, this association was modified by the self-reported epidemiological link such that, among cases who did report an epidemiological link, being a health professional appeared significantly protective (aOR = 0.90, 95% CI 0.82–0.98). Findings from the sensitivity analyses were consistent with the previous observations, except results for administrative staff were non-significant due to the small strata sample size (<10% of health professionals; online suppl. material 2).
Results of the multivariable model measuring the association between health professional status and SARS-CoV-2 test positivity adjusted for age groups, sex, region, international travel history, symptoms, and with interaction between health professional status and self-reported epidemiological link, Portugal, January to May 2020 ( n = 48,459)

To further assess the impact of missing data in our analysis, we compared the proportion of observations with missing data between cases and controls, and between health professionals and non-health professionals. The variables with missing data were the self-reported epidemiological link (37.01% of observations), symptoms (30.29%), and international travel history (2.45%). However, the differences in the overall proportion of observations with missing data between cases and controls (62 vs. 67%) or between health professionals and non-health professionals (61 vs. 72%) were relatively small, although statistically significant ( p < 0.001), which is expected with such a large sample. The larger differences were observed for the “symptoms” variable, with a higher proportion of health professionals with missing data compared to non-health professionals (47 vs. 27%; online suppl. material 3).
To our knowledge, this is the first study assessing the risk of COVID-19 in health professionals compared to non-health professionals in Portugal. In this study, we found that the proportion of confirmed cases in health professionals was double that of non-health professionals. After controlling for demographics and clinical and epidemiological confounders, we found that health professionals had a 2-fold higher risk of a positive COVID-19 test result, but this association was strongly modified by the self-reported epidemiological link. Indeed, among cases that did report an epidemiological link, being a health professional was a protective factor.
The higher risk of COVID-19 test positivity in health professionals is consistent with findings from other settings that reported a higher risk in essential workers [ 21 ]. In this regard, it is worth noting that half of the health professionals reported an epidemiological link, whereas only 20% of non-health professionals did so. Considering that the proportion of self-reported epidemiological links could be a proxy for the opportunities of exposure, this supports the idea of a higher exposure of health professionals due to the nature of their profession.
However, the protective effect of the health professional status among cases who did report an epidemiological link appears counter-intuitive. Eventually, our results suggest that health professionals might be primarily infected by unknown contacts and that the occupational exposure of health professionals does not systematically translate into a higher risk of transmission. We discuss here some hypotheses to support the interpretation of these results.
First, the nature of contacts of health professionals might be different to that of non-health professionals and can yield different probabilities of transmission. In our study, the majority (87%) of health professionals reported an epidemiological link in healthcare settings, whereas half (47%) of non-health professionals referred to household contacts. Exposure in a household setting is likely to be characterized by a higher frequency, duration, and proximity with household contacts, which in turn might translate into a higher probability of transmission. In contrast, exposure of health professionals in healthcare settings might be of shorter duration and limited proximity with patients.
Most importantly, the timing of exposure might differ in household or healthcare settings. Indeed, exposure in household settings is likely to occur before knowing that the contact person is infected by COVID-19, and thus before any preventive measure can be taken (e.g., isolation, mask use, etc.). In contrast, exposure of health professionals in healthcare settings is likely to happen after a confirmed or suspected diagnosis of COVID-19 of the said contact person, and it is plausible to believe that the IPC (implementation of infection prevention and control) measures would explain the reduced risk in health professionals who reported an epidemiological link [ 24, 25 ]. These measures include the use of masks and respiratory etiquette, which was generalized to all health professionals in a hospital or primary care setting on March 29, 2020 [26], and the use of PPE, which followed recommendations by type of care (i.e., non-invasive or invasive care) and contact with patients [ 27, 28 ]. It is worth noting that during the study period no specific recommendations or legal obligations regulated the use of facemasks in the community.
Finally, the difference in risk for health professionals who did not report an epidemiological and those who did report an epidemiological link might also be interpreted as a proxy or as different risk perceptions and associated individual behaviours. In other words, health professionals who did not report an epidemiological link might have failed to identify a situation at risk of exposure and might have not used appropriate preventive measures, which would eventually translate into a higher risk of transmission.
This study has some limitations. The low completeness of the case-report forms, which lead to a high number of exclusions of observations, was an important issue. Complete case analysis was still preferred, based on the following considerations. First, due to the standardization of the reporting process and a large amount of data, we do not have any reasons to believe that there might be systematic differences in completeness or misclassifications of the variables of interest that would significantly affect the results. Additionally, medical case-report forms of suspected cases that contain information on the variables of interest (i.e., demographics, clinical presentation, travel history, and self-reported epidemiological link) are generally filled before knowing the laboratory result. Consequently, it is unlikely that the test outcome would have biased the reporting of the variables of interest leading to systematic differences between cases and controls. Despite this, one cannot completely exclude reporting bias between health professionals and non-health professionals. For instance, physicians could be more likely to report that a suspected case is a health professional or that a health professional has had contact with a COVID-19 case (self-reported epidemiological link). The analysis of the proportion of observations with missing data revealed minor differences between health professionals and non-health professionals. The larger differences observed for the “symptoms” variable, with health professionals having a higher proportion of missing data, could reflect a higher likelihood for health professionals to be reported as suspected cases, independently of symptoms or signs. Another hypothesis relates to the presence of lighter or atypical symptoms that were not included in the medical case-report forms in the early months of the epidemic, such as anosmia or ageusia. Such symptoms were also more prevalent in younger patients, and active health professionals being younger than non-health workers would have been more likely to experience those.
The validity of the test-negative case-control design relies on the assumption of a similar testing rate among participants [ 22, 23 ]. Here we present arguments in favour of such an assumption. First, Portugal rapidly developed a high testing capacity. Laboratories, including hospital laboratories, private laboratories at universities and research centres, and other laboratories, were subjected to an expedited process of central authorization to qualify for the diagnosis of SARS-CoV-2. Despite a relatively limited number of authorized sites at the beginning of the pandemic, the list of authorized laboratories quickly scaled up in the country. Additionally, access to testing was facilitated by the multiplication of testing points and the removal of financial barriers as tests for suspected cases were fully subsidized by the NHS. This led to an early increasing and sustained high testing rate per capita [ 29-31 ] (online suppl. material 4)
Health professionals were encouraged to perform a daily self-monitoring of a limited set of symptoms suggestive of COVID-19 (e.g., fever, odynophagia, cough, rhinorrhoea, shortness of breath) [ 27 ]. Thus, it is plausible that suspected and confirmed COVID-19 cases among health professionals would have been identified more promptly [ 32 ]. Additionally, it is reasonable to believe that testing was performed more frequently among health professionals to prevent and control outbreaks among a highly exposed and/or vulnerable population in healthcare settings (i.e., health workers, patients). As such, we cannot exclude that asymptomatic cases would be more likely detected among health professionals, which would tend to slightly overestimate the effect of the health professional status on a positive test result. Nevertheless, at that time, there were no mandatory requirements of testing, neither a national strategy nor framework for testing of health professionals. Moreover, similar punctual testing strategies would have also occurred in other settings (e.g., comprehensive testing of company staff where a COVID-19 cluster was detected).
Finally, such a study design based on surveillance data has some limitations and we do not pretend to replace research studies that are based on a random sampling of the population and provide robust population estimates. It does, however, contribute to the effort to use and disseminate surveillance data to improve the epidemiological understanding and public health practice in the context of the COVID-19 pandemic response.
To our knowledge, this is the first study estimating the risk of COVID-19 in health professionals in Portugal. Efforts should be pursued to better protect health professionals who are working at the frontline of the COVID-19 response. Future research is needed to further investigate the risk differences between various occupational groups of health professionals, and their evolution over time concerning the epidemic dynamics and changes in preventive measures and policies, both in healthcare settings and the general population.
We acknowledge the hard work of all frontline workers and public health professionals involved in the response to COVID-19 in Portugal at the national, regional, and local levels, particularly the physicians and laboratory workers who participate in the surveillance, and the Directorate-General of Health COVID-19 Task-Force members. We thank Dr. Rodrigo Marques for his contribution to data collection. We extend our appreciation to Porto Public Health Institute (ISPUP) COVID-19 Task-Force for constructively criticizing this study.
Pre-anonymized data were collected in the scope of national epidemiological surveillance, requiring no supplementary ethical approval by institutional bodies and preserving the confidentiality and anonymity of individuals. The study was in line with the World Medical Association Declaration of Helsinki.
The authors have no conflicts of interest to declare.
There were no sources of funding relating to this work.
H.L., M.P.D., and C.C. conceived the study. H.L., M.P.D., C.C., and R.S.M. collected and cleaned the data. H.L. conducted the analysis and wrote the manuscript. R.S.M. supervised the overall study. M.P.D., C.C., R.S.M., and S.B. critically revised the manuscript.
Restrictions apply to the availability of these data, which were used under licence for this study. Data are available from the authors with the permission of the Portuguese Directorate-General of Health (DGS).

Email alerts
Citing articles via, suggested reading.
- Online ISSN 2504-3145
- Print ISSN 2504-3137
INFORMATION
- Contact & Support
- Information & Downloads
- Rights & Permissions
- Terms & Conditions
- Catalogue & Pricing
- Policies & Information
- People & Organization
- Stay Up-to-Date
- Regional Offices
- Community Voice
SERVICES FOR
- Researchers
- Healthcare Professionals
- Patients & Supporters
- Health Sciences Industry
- Medical Societies
- Agents & Booksellers
Karger International
- S. Karger AG
- P.O Box, CH-4009 Basel (Switzerland)
- Allschwilerstrasse 10, CH-4055 Basel
- Tel: +41 61 306 11 11
- Fax: +41 61 306 12 34
- Contact: Front Office
- Experience Blog
- Privacy Policy
- Terms of Use
This Feature Is Available To Subscribers Only
Sign In or Create an Account
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Estudos Caso-Controle: Uma Breve Revisão Case-Control Studies: A Brief Review

Os estudos caso-controle têm tido utilização crescente nas últimas décadas, com variadas formas de aplicação no campo da Epidemiologia e da Saúde Pública. Até bem pouco tempo, eram vistos como estudos de segunda linha em função da susceptibilidade aos vieses. O objetivo desse trabalho é apresentar e discutir os principais aspectos associados ao delineamento desse tipo de estudo. Destacam-se os usos, para além do pressuposto da raridade da doença, a classificação, a adequada definição e seleção de casos e de controles, a avaliação da exposição utilizando situações da epidemiologia ocupacional, o procedimento analítico usual e as vantagens e desvantagens, incluindo breve discussão sobre vieses e confundimento. Conclui-se que se bem conduzidos, os estudos caso-controle são tão válidos quanto os estudos de coorte. Palavras-chave: estudo caso-controle, epidemiologia, doenças crônicas.
Related Papers
Cadernos de Saúde Pública
Marcos Rego
Este texto apresenta um relato da evolução dos estudos de caso-controle (ECC) até o final dos anos 80. A comparação de dois grupos quanto à exposição a um fator de risco é verificada desde o século XVII. A segunda metade do século XIX significou o declínio da Epidemiologia das "populações", e os primeiros ECC só foram realizados na década de 20. O avanço do método ocorreu na segunda metade do século, com destaque para as investigações sobre câncer de pulmão e hábito de fumar. As principais contribuições dos estudiosos do método foram o uso da odds ratio como estimativa do risco relativo; a definição dos aspectos estatísticos da análise de dados de estudos retrospectivos; o cálculo do risco atribuível e da fração etiológica para ECC; e a discussão da essência dos ECC. Os críticos referiam as fragilidades do método e a susceptibilidade aos bias. Conclui-se que os ECC tiveram aplicação crescente nas últimas décadas, sendo utilizados em diversas áreas da epidemiologia, constit...
Fah Gouveia
Cadernos de Pesquisa
Alda Judith Alves-Mazzotti
... porque o caso representa outros casos ou porque ilustra um traço ou problema particular, mas ... O objetivo não é vir a entender algum constructo abstrato ou fenômeno genérico, tal como ... Psicologia Clínica, na qual uma pessoa, devido a uma deficiência ou a condições de vida ...
raquel teixeira
Crizaldo Silva
maria do carmo figueiredo
Contexto: O estudo de caso tem interesse para a analise de projetos de desenvolvimento curricular. A compreensao dos fenomenos confere-lhe a particularidade, quando as fronteiras entre estes e o contexto sao indefinidas. Objetivos: disseminar a experiencia de utilizacao de estudo de caso na area da enfermagem. Metodo: Estudo de caso multiplo com pesquisa documental, observacao participante dos estudantes, entrevistas semiestruturadas. Tratamento dos dados por analise de conteudo; analise de dominios culturais e triangulacao. Resultados: colocamos em evidencia os resultados: categorias de analise e triangulacao, conferindo a validade do constructo. Conclusoes: O estudo de caso permitiu estudar em profundidade o fenomeno da Promocao da Saude em duas Escolas Superiores de Saude (casos), pelo envolvimento dos professores no curriculo na elaboracao de estrategias produtoras de inovacao e desenvolvimento de competencias dos estudantes. Os estudos de casos multiplos como metodo de investig...
Contextus – Revista Contemporânea de Economia e Gestão
Myriam Dornelas
Palmiere Lucas de Souza
Mayke Vieiro de Farias
Intercompany IC
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
Alcina Manuela
REVISTA ESCRITA
Roberta Pacheco
Alyne Vieira
Elizangela Nery
BASE-Revista de Administração e Contabilidade …
Antonio Carlos Gil
Alexandre Lopes
Estudo & Debate
Albino Alves Simione
Revista De Ciencias Medicas
Paulo Moacir Godoy Pozzebon
Caritas de Angola
Melanson Kanando
Monitoria Bagozzi
Revista Scientiarum História
Arthur A Leal Ferreira
journal of physical education
KARINA PEREIRA
Dalva Godoy
Gustavo Marchisotti
Ricardo Cordeiro
ANAIS DO VI SIMPOSIO BRASILEIRO DE QUALIDADE DO PROJETO NO AMBIENTE CONSTRUIDO
Jeferson Bunder
Alberto Matsumoto , Abdelkader Bourahli
Sociedade e Cultura
Natália Sátyro
Alana Natasha
Fernanda Mariana
Luisa Vilardi
Célia Cunha
Regina de Fátima Marcos da Silva
Cátia Correia
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Strengthening the reporting of observational studies in epidemiology
STROBE Checklists
- STROBE Checklist: cohort, case-control, and cross-sectional studies (combined) Download PDF | Word
- STROBE Checklist (fillable): cohort, case-control, and cross-sectional studies (combined) Download PDF | Word
- STROBE Checklist: cohort studies Download PDF | Word
- STROBE Checklist: case-control studies Download PDF | Word
- STROBE Checklist: cross-sectional studies Download PDF | Word
- STROBE Checklist: conference abstracts Download PDF
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is a Case-Control Study? | Definition & Examples
What Is a Case-Control Study? | Definition & Examples
Published on February 4, 2023 by Tegan George . Revised on June 22, 2023.
A case-control study is an experimental design that compares a group of participants possessing a condition of interest to a very similar group lacking that condition. Here, the participants possessing the attribute of study, such as a disease, are called the “case,” and those without it are the “control.”
It’s important to remember that the case group is chosen because they already possess the attribute of interest. The point of the control group is to facilitate investigation, e.g., studying whether the case group systematically exhibits that attribute more than the control group does.
Table of contents
When to use a case-control study, examples of case-control studies, advantages and disadvantages of case-control studies, other interesting articles, frequently asked questions.
Case-control studies are a type of observational study often used in fields like medical research, environmental health, or epidemiology. While most observational studies are qualitative in nature, case-control studies can also be quantitative , and they often are in healthcare settings. Case-control studies can be used for both exploratory and explanatory research , and they are a good choice for studying research topics like disease exposure and health outcomes.
A case-control study may be a good fit for your research if it meets the following criteria.
- Data on exposure (e.g., to a chemical or a pesticide) are difficult to obtain or expensive.
- The disease associated with the exposure you’re studying has a long incubation period or is rare or under-studied (e.g., AIDS in the early 1980s).
- The population you are studying is difficult to contact for follow-up questions (e.g., asylum seekers).
Retrospective cohort studies use existing secondary research data, such as medical records or databases, to identify a group of people with a common exposure or risk factor and to observe their outcomes over time. Case-control studies conduct primary research , comparing a group of participants possessing a condition of interest to a very similar group lacking that condition in real time.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Case-control studies are common in fields like epidemiology, healthcare, and psychology.
You would then collect data on your participants’ exposure to contaminated drinking water, focusing on variables such as the source of said water and the duration of exposure, for both groups. You could then compare the two to determine if there is a relationship between drinking water contamination and the risk of developing a gastrointestinal illness. Example: Healthcare case-control study You are interested in the relationship between the dietary intake of a particular vitamin (e.g., vitamin D) and the risk of developing osteoporosis later in life. Here, the case group would be individuals who have been diagnosed with osteoporosis, while the control group would be individuals without osteoporosis.
You would then collect information on dietary intake of vitamin D for both the cases and controls and compare the two groups to determine if there is a relationship between vitamin D intake and the risk of developing osteoporosis. Example: Psychology case-control study You are studying the relationship between early-childhood stress and the likelihood of later developing post-traumatic stress disorder (PTSD). Here, the case group would be individuals who have been diagnosed with PTSD, while the control group would be individuals without PTSD.
Case-control studies are a solid research method choice, but they come with distinct advantages and disadvantages.
Advantages of case-control studies
- Case-control studies are a great choice if you have any ethical considerations about your participants that could preclude you from using a traditional experimental design .
- Case-control studies are time efficient and fairly inexpensive to conduct because they require fewer subjects than other research methods .
- If there were multiple exposures leading to a single outcome, case-control studies can incorporate that. As such, they truly shine when used to study rare outcomes or outbreaks of a particular disease .
Disadvantages of case-control studies
- Case-control studies, similarly to observational studies, run a high risk of research biases . They are particularly susceptible to observer bias , recall bias , and interviewer bias.
- In the case of very rare exposures of the outcome studied, attempting to conduct a case-control study can be very time consuming and inefficient .
- Case-control studies in general have low internal validity and are not always credible.
Case-control studies by design focus on one singular outcome. This makes them very rigid and not generalizable , as no extrapolation can be made about other outcomes like risk recurrence or future exposure threat. This leads to less satisfying results than other methodological choices.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
Prevent plagiarism. Run a free check.
A case-control study differs from a cohort study because cohort studies are more longitudinal in nature and do not necessarily require a control group .
While one may be added if the investigator so chooses, members of the cohort are primarily selected because of a shared characteristic among them. In particular, retrospective cohort studies are designed to follow a group of people with a common exposure or risk factor over time and observe their outcomes.
Case-control studies, in contrast, require both a case group and a control group, as suggested by their name, and usually are used to identify risk factors for a disease by comparing cases and controls.
A case-control study differs from a cross-sectional study because case-control studies are naturally retrospective in nature, looking backward in time to identify exposures that may have occurred before the development of the disease.
On the other hand, cross-sectional studies collect data on a population at a single point in time. The goal here is to describe the characteristics of the population, such as their age, gender identity, or health status, and understand the distribution and relationships of these characteristics.
Cases and controls are selected for a case-control study based on their inherent characteristics. Participants already possessing the condition of interest form the “case,” while those without form the “control.”
Keep in mind that by definition the case group is chosen because they already possess the attribute of interest. The point of the control group is to facilitate investigation, e.g., studying whether the case group systematically exhibits that attribute more than the control group does.
The strength of the association between an exposure and a disease in a case-control study can be measured using a few different statistical measures , such as odds ratios (ORs) and relative risk (RR).
No, case-control studies cannot establish causality as a standalone measure.
As observational studies , they can suggest associations between an exposure and a disease, but they cannot prove without a doubt that the exposure causes the disease. In particular, issues arising from timing, research biases like recall bias , and the selection of variables lead to low internal validity and the inability to determine causality.
Sources in this article
We strongly encourage students to use sources in their work. You can cite our article (APA Style) or take a deep dive into the articles below.
George, T. (2023, June 22). What Is a Case-Control Study? | Definition & Examples. Scribbr. Retrieved June 24, 2024, from https://www.scribbr.com/methodology/case-control-study/
Schlesselman, J. J. (1982). Case-Control Studies: Design, Conduct, Analysis (Monographs in Epidemiology and Biostatistics, 2) (Illustrated). Oxford University Press.
Is this article helpful?

Tegan George
Other students also liked, what is an observational study | guide & examples, control groups and treatment groups | uses & examples, cross-sectional study | definition, uses & examples, what is your plagiarism score.
- En español – ExME
- Em português – EME
Case-control and Cohort studies: A brief overview
Posted on 6th December 2017 by Saul Crandon

Introduction
Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence . These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as randomised controlled trials, they can provide strong evidence if designed appropriately.
Case-control studies
Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups. See Figure 1 for a pictorial representation of a case-control study design. This can suggest associations between the risk factor and development of the disease in question, although no definitive causality can be drawn. The main outcome measure in case-control studies is odds ratio (OR) .
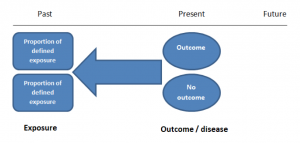
Figure 1. Case-control study design.
Cases should be selected based on objective inclusion and exclusion criteria from a reliable source such as a disease registry. An inherent issue with selecting cases is that a certain proportion of those with the disease would not have a formal diagnosis, may not present for medical care, may be misdiagnosed or may have died before getting a diagnosis. Regardless of how the cases are selected, they should be representative of the broader disease population that you are investigating to ensure generalisability.
Case-control studies should include two groups that are identical EXCEPT for their outcome / disease status.
As such, controls should also be selected carefully. It is possible to match controls to the cases selected on the basis of various factors (e.g. age, sex) to ensure these do not confound the study results. It may even increase statistical power and study precision by choosing up to three or four controls per case (2).
Case-controls can provide fast results and they are cheaper to perform than most other studies. The fact that the analysis is retrospective, allows rare diseases or diseases with long latency periods to be investigated. Furthermore, you can assess multiple exposures to get a better understanding of possible risk factors for the defined outcome / disease.
Nevertheless, as case-controls are retrospective, they are more prone to bias. One of the main examples is recall bias. Often case-control studies require the participants to self-report their exposure to a certain factor. Recall bias is the systematic difference in how the two groups may recall past events e.g. in a study investigating stillbirth, a mother who experienced this may recall the possible contributing factors a lot more vividly than a mother who had a healthy birth.
A summary of the pros and cons of case-control studies are provided in Table 1.
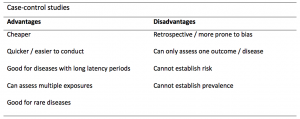
Table 1. Advantages and disadvantages of case-control studies.
Cohort studies
Cohort studies can be retrospective or prospective. Retrospective cohort studies are NOT the same as case-control studies.
In retrospective cohort studies, the exposure and outcomes have already happened. They are usually conducted on data that already exists (from prospective studies) and the exposures are defined before looking at the existing outcome data to see whether exposure to a risk factor is associated with a statistically significant difference in the outcome development rate.
Prospective cohort studies are more common. People are recruited into cohort studies regardless of their exposure or outcome status. This is one of their important strengths. People are often recruited because of their geographical area or occupation, for example, and researchers can then measure and analyse a range of exposures and outcomes.
The study then follows these participants for a defined period to assess the proportion that develop the outcome/disease of interest. See Figure 2 for a pictorial representation of a cohort study design. Therefore, cohort studies are good for assessing prognosis, risk factors and harm. The outcome measure in cohort studies is usually a risk ratio / relative risk (RR).
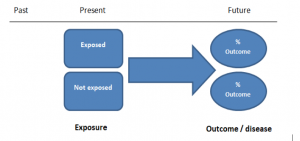
Figure 2. Cohort study design.
Cohort studies should include two groups that are identical EXCEPT for their exposure status.
As a result, both exposed and unexposed groups should be recruited from the same source population. Another important consideration is attrition. If a significant number of participants are not followed up (lost, death, dropped out) then this may impact the validity of the study. Not only does it decrease the study’s power, but there may be attrition bias – a significant difference between the groups of those that did not complete the study.
Cohort studies can assess a range of outcomes allowing an exposure to be rigorously assessed for its impact in developing disease. Additionally, they are good for rare exposures, e.g. contact with a chemical radiation blast.
Whilst cohort studies are useful, they can be expensive and time-consuming, especially if a long follow-up period is chosen or the disease itself is rare or has a long latency.
A summary of the pros and cons of cohort studies are provided in Table 2.
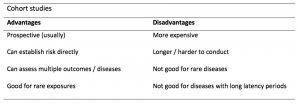
The Strengthening of Reporting of Observational Studies in Epidemiology Statement (STROBE)
STROBE provides a checklist of important steps for conducting these types of studies, as well as acting as best-practice reporting guidelines (3). Both case-control and cohort studies are observational, with varying advantages and disadvantages. However, the most important factor to the quality of evidence these studies provide, is their methodological quality.
- Song, J. and Chung, K. Observational Studies: Cohort and Case-Control Studies . Plastic and Reconstructive Surgery.  2010 Dec;126(6):2234-2242.
- Ury HK. Efficiency of case-control studies with multiple controls per case: Continuous or dichotomous data . Biometrics . 1975 Sep;31(3):643–649.
- von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP; STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies.  Lancet 2007 Oct;370(9596):1453-14577. PMID: 18064739.

Saul Crandon
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on Case-control and Cohort studies: A brief overview

Very well presented, excellent clarifications. Has put me right back into class, literally!

Very clear and informative! Thank you.

very informative article.

Thank you for the easy to understand blog in cohort studies. I want to follow a group of people with and without a disease to see what health outcomes occurs to them in future such as hospitalisations, diagnoses, procedures etc, as I have many health outcomes to consider, my questions is how to make sure these outcomes has not occurred before the “exposure disease”. As, in cohort studies we are looking at incidence (new) cases, so if an outcome have occurred before the exposure, I can leave them out of the analysis. But because I am not looking at a single outcome which can be checked easily and if happened before exposure can be left out. I have EHR data, so all the exposure and outcome have occurred. my aim is to check the rates of different health outcomes between the exposed)dementia) and unexposed(non-dementia) individuals.

Very helpful information

Thanks for making this subject student friendly and easier to understand. A great help.

Thanks a lot. It really helped me to understand the topic. I am taking epidemiology class this winter, and your paper really saved me.
Happy new year.

Wow its amazing n simple way of briefing ,which i was enjoyed to learn this.its very easy n quick to pick ideas .. Thanks n stay connected

Saul you absolute melt! Really good work man

am a student of public health. This information is simple and well presented to the point. Thank you so much.

very helpful information provided here

really thanks for wonderful information because i doing my bachelor degree research by survival model

Quite informative thank you so much for the info please continue posting. An mph student with Africa university Zimbabwe.

Thank you this was so helpful amazing

Apreciated the information provided above.

So clear and perfect. The language is simple and superb.I am recommending this to all budding epidemiology students. Thanks a lot.

Great to hear, thank you AJ!

I have recently completed an investigational study where evidence of phlebitis was determined in a control cohort by data mining from electronic medical records. We then introduced an intervention in an attempt to reduce incidence of phlebitis in a second cohort. Again, results were determined by data mining. This was an expedited study, so there subjects were enrolled in a specific cohort based on date(s) of the drug infused. How do I define this study? Thanks so much.

thanks for the information and knowledge about observational studies. am a masters student in public health/epidemilogy of the faculty of medicines and pharmaceutical sciences , University of Dschang. this information is very explicit and straight to the point

Very much helpful
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Expertise-based Randomized Controlled Trials
This blog summarizes the concepts of Expertise-based randomized controlled trials with a focus on the advantages and challenges associated with this type of study.

An introduction to different types of study design
Conducting successful research requires choosing the appropriate study design. This article describes the most common types of designs conducted by researchers.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed, case control studies, affiliations.
- 1 University of Nebraska Medical Center
- 2 Spectrum Health/Michigan State University College of Human Medicine
- PMID: 28846237
- Bookshelf ID: NBK448143
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes. The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to the case individuals but do not have the outcome of interest. The researcher then looks at historical factors to identify if some exposure(s) is/are found more commonly in the cases than the controls. If the exposure is found more commonly in the cases than in the controls, the researcher can hypothesize that the exposure may be linked to the outcome of interest.
For example, a researcher may want to look at the rare cancer Kaposi's sarcoma. The researcher would find a group of individuals with Kaposi's sarcoma (the cases) and compare them to a group of patients who are similar to the cases in most ways but do not have Kaposi's sarcoma (controls). The researcher could then ask about various exposures to see if any exposure is more common in those with Kaposi's sarcoma (the cases) than those without Kaposi's sarcoma (the controls). The researcher might find that those with Kaposi's sarcoma are more likely to have HIV, and thus conclude that HIV may be a risk factor for the development of Kaposi's sarcoma.
There are many advantages to case-control studies. First, the case-control approach allows for the study of rare diseases. If a disease occurs very infrequently, one would have to follow a large group of people for a long period of time to accrue enough incident cases to study. Such use of resources may be impractical, so a case-control study can be useful for identifying current cases and evaluating historical associated factors. For example, if a disease developed in 1 in 1000 people per year (0.001/year) then in ten years one would expect about 10 cases of a disease to exist in a group of 1000 people. If the disease is much rarer, say 1 in 1,000,0000 per year (0.0000001/year) this would require either having to follow 1,000,0000 people for ten years or 1000 people for 1000 years to accrue ten total cases. As it may be impractical to follow 1,000,000 for ten years or to wait 1000 years for recruitment, a case-control study allows for a more feasible approach.
Second, the case-control study design makes it possible to look at multiple risk factors at once. In the example above about Kaposi's sarcoma, the researcher could ask both the cases and controls about exposures to HIV, asbestos, smoking, lead, sunburns, aniline dye, alcohol, herpes, human papillomavirus, or any number of possible exposures to identify those most likely associated with Kaposi's sarcoma.
Case-control studies can also be very helpful when disease outbreaks occur, and potential links and exposures need to be identified. This study mechanism can be commonly seen in food-related disease outbreaks associated with contaminated products, or when rare diseases start to increase in frequency, as has been seen with measles in recent years.
Because of these advantages, case-control studies are commonly used as one of the first studies to build evidence of an association between exposure and an event or disease.
In a case-control study, the investigator can include unequal numbers of cases with controls such as 2:1 or 4:1 to increase the power of the study.
Disadvantages and Limitations
The most commonly cited disadvantage in case-control studies is the potential for recall bias. Recall bias in a case-control study is the increased likelihood that those with the outcome will recall and report exposures compared to those without the outcome. In other words, even if both groups had exactly the same exposures, the participants in the cases group may report the exposure more often than the controls do. Recall bias may lead to concluding that there are associations between exposure and disease that do not, in fact, exist. It is due to subjects' imperfect memories of past exposures. If people with Kaposi's sarcoma are asked about exposure and history (e.g., HIV, asbestos, smoking, lead, sunburn, aniline dye, alcohol, herpes, human papillomavirus), the individuals with the disease are more likely to think harder about these exposures and recall having some of the exposures that the healthy controls.
Case-control studies, due to their typically retrospective nature, can be used to establish a correlation between exposures and outcomes, but cannot establish causation . These studies simply attempt to find correlations between past events and the current state.
When designing a case-control study, the researcher must find an appropriate control group. Ideally, the case group (those with the outcome) and the control group (those without the outcome) will have almost the same characteristics, such as age, gender, overall health status, and other factors. The two groups should have similar histories and live in similar environments. If, for example, our cases of Kaposi's sarcoma came from across the country but our controls were only chosen from a small community in northern latitudes where people rarely go outside or get sunburns, asking about sunburn may not be a valid exposure to investigate. Similarly, if all of the cases of Kaposi's sarcoma were found to come from a small community outside a battery factory with high levels of lead in the environment, then controls from across the country with minimal lead exposure would not provide an appropriate control group. The investigator must put a great deal of effort into creating a proper control group to bolster the strength of the case-control study as well as enhance their ability to find true and valid potential correlations between exposures and disease states.
Similarly, the researcher must recognize the potential for failing to identify confounding variables or exposures, introducing the possibility of confounding bias, which occurs when a variable that is not being accounted for that has a relationship with both the exposure and outcome. This can cause us to accidentally be studying something we are not accounting for but that may be systematically different between the groups.
Copyright © 2024, StatPearls Publishing LLC.
PubMed Disclaimer
Conflict of interest statement
Disclosure: Steven Tenny declares no relevant financial relationships with ineligible companies.
Disclosure: Connor Kerndt declares no relevant financial relationships with ineligible companies.
Disclosure: Mary Hoffman declares no relevant financial relationships with ineligible companies.
- Introduction
- Issues of Concern
- Clinical Significance
- Enhancing Healthcare Team Outcomes
- Review Questions
Similar articles
- Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas. Crider K, Williams J, Qi YP, Gutman J, Yeung L, Mai C, Finkelstain J, Mehta S, Pons-Duran C, Menéndez C, Moraleda C, Rogers L, Daniels K, Green P. Crider K, et al. Cochrane Database Syst Rev. 2022 Feb 1;2(2022):CD014217. doi: 10.1002/14651858.CD014217. Cochrane Database Syst Rev. 2022. PMID: 36321557 Free PMC article.
- Epidemiology Of Study Design. Munnangi S, Boktor SW. Munnangi S, et al. 2023 Apr 24. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. 2023 Apr 24. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. PMID: 29262004 Free Books & Documents.
- Risk factors for Kaposi's sarcoma in HIV-positive subjects in Uganda. Ziegler JL, Newton R, Katongole-Mbidde E, Mbulataiye S, De Cock K, Wabinga H, Mugerwa J, Katabira E, Jaffe H, Parkin DM, Reeves G, Weiss R, Beral V. Ziegler JL, et al. AIDS. 1997 Nov;11(13):1619-26. doi: 10.1097/00002030-199713000-00011. AIDS. 1997. PMID: 9365767
- Epidemiology of Kaposi's sarcoma. Beral V. Beral V. Cancer Surv. 1991;10:5-22. Cancer Surv. 1991. PMID: 1821323 Review.
- The epidemiology of classic, African, and immunosuppressed Kaposi's sarcoma. Wahman A, Melnick SL, Rhame FS, Potter JD. Wahman A, et al. Epidemiol Rev. 1991;13:178-99. doi: 10.1093/oxfordjournals.epirev.a036068. Epidemiol Rev. 1991. PMID: 1765111 Review.
- Setia MS. Methodology Series Module 2: Case-control Studies. Indian J Dermatol. 2016 Mar-Apr;61(2):146-51. - PMC - PubMed
- Sedgwick P. Bias in observational study designs: case-control studies. BMJ. 2015 Jan 30;350:h560. - PubMed
- Groenwold RHH, van Smeden M. Efficient Sampling in Unmatched Case-Control Studies When the Total Number of Cases and Controls Is Fixed. Epidemiology. 2017 Nov;28(6):834-837. - PubMed
Publication types
- Search in PubMed
- Search in MeSH
- Add to Search
Related information
Linkout - more resources, full text sources.
- NCBI Bookshelf
Research Materials
- NCI CPTC Antibody Characterization Program
Miscellaneous
- NCI CPTAC Assay Portal

- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
- Search Menu
- Sign in through your institution
- Supplements
- Cohort Profiles
- Education Corner
- Author Guidelines
- Submission Site
- Open Access
- About the International Journal of Epidemiology
- About the International Epidemiological Association
- Editorial Team
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Self-Archiving Policy
- Dispatch Dates
- Contact the IEA
- Journals on Oxford Academic
- Books on Oxford Academic
Article Contents
Introduction, case–control studies in dynamic populations, case–control studies within cohorts, unity of the concept of density sampling from dynamic populations and sampling from cohorts, discussion: differences with classic case–control teaching, and consequences.
- < Previous
Case–control studies: basic concepts
- Article contents
- Figures & tables
- Supplementary Data
Jan P Vandenbroucke, Neil Pearce, Case–control studies: basic concepts, International Journal of Epidemiology , Volume 41, Issue 5, October 2012, Pages 1480–1489, https://doi.org/10.1093/ije/dys147
- Permissions Icon Permissions
The purpose of this article is to present in elementary mathematical and statistical terms a simple way to quickly and effectively teach and understand case–control studies, as they are commonly done in dynamic populations—without using the rare disease assumption. Our focus is on case–control studies of disease incidence (‘incident case–control studies’); we will not consider the situation of case–control studies of prevalent disease, which are published much less frequently.
Readers of the medical literature were once taught that case–control studies are ‘cohort studies in reverse’, in which persons who developed disease during follow-up are compared with persons who did not. In addition, they were told that the odds ratio calculated from case–control studies is an approximation of the risk ratio or rate ratio, but only if the disease is ‘rare’ (say, if <5% of the population develops disease). These notions are no longer compatible with present-day epidemiological theory of case–control studies which is based on ‘density sampling’. Moreover, a recent survey found that the large majority of case–control studies do not sample cases and control subjects from a cohort with fixed membership; rather, they sample from dynamic populations with variable membership. 1 Of all case–control studies involving incident cases, 82% sampled from a dynamic population; only 18% of studies sampled from a cohort, and only some of these may need the ‘rare disease assumption’ (depending on how the control subjects were sampled). Thus, the ‘rare disease assumption’ is not needed for the large majority of published case–control studies. In addition, different assumptions are needed for case–control studies in dynamic populations and those in cohorts to ensure that the odds ratios are estimates of ratios of incidence rates.
The underlying theory for case–control studies in dynamic populations has been developed in epidemiological and statistical journals and textbooks over several decades, 2–19 and its history has been described. 20 Still, the theory is not well known or well understood outside professional epidemiological and statistical circles. Introductory textbooks of epidemiology often fall back on methods of control sampling, which involve the ‘rare disease assumption’ as it was proposed by Cornfield in 1951, 3 because it seems easier to explain. 1 Moreover, several advanced textbooks or articles depict the different ways of sampling cases and control subjects from the point of view of a cohort with fixed membership. 13 , 18 This reinforces the view of case–control studies as constructed within a cohort, even though this applies to only a small minority of published case–control studies.
The purpose of this article is to present in elementary mathematical and statistical terms a simple way to quickly and effectively teach and understand case–control studies as they are commonly done in dynamic populations––without using the rare disease assumption. Our focus is on case–control studies of disease incidence (‘incident case–control studies’); we will not consider the situation of case–control studies of prevalent disease, which are published much less frequently, 1 except in certain situations as discussed by Pearce 21 (e.g. for diseases such as asthma in which it is difficult to identify incident cases).
The theory of case–control studies in dynamic populations cannot be explained before first going back to the calculation of incidence rates and risks in dynamic populations. In a previous article, we have reviewed the demographic concepts that underpin these calculations. 22 In the current article, these concepts will first be applied to case–control studies involving sampling from dynamic populations. Second, we discuss how to teach the theory in the situation of sampling from a cohort. In the third part, it is explained how these two distinct ways of sampling cases and control subjects can be unified conceptually in the proportional hazards model (Cox regression). Finally, we discuss the consequences of this way of teaching case–control studies for understanding the assumptions behind these studies, and for appropriately designing studies. We propose that the explanation of case–control studies within dynamic populations should become the basis for teaching case–control studies, in both introductory and more advanced courses.
Basic teaching
To understand the application of the basic concepts of incidence rate calculations to case–control studies, we start with the demographic perspective of a dynamic population in which we calculate and compare incidence rates of disease. 22
Suppose that investigators are interested in the effect of oral contraceptive use on the incidence of myocardial infarction among women of reproductive age. They might investigate this in a large town in a particular calendar year (we base this example loosely on one of the first case–control studies that investigated this association 23 ). The time-population structure of the study is depicted in Figure 1 .
The underlying dynamic ‘source’ population of a study of myocardial infarction (MI) and oral contraceptive use. The bold undulating lines show the fluctuating number of users and non-users of oral contraceptives in a population that is in a steady state. The finer lines below it depict individuals who enter and leave the populations of users and non-users. Closed circles indicate cases of MI emanating from the population. For users and non-users separately, an incidence rate (IR) of MI can be calculated. The incidence rate ratio (IRR) can be used to compare the incidence of MI between users and non-users. In the description of the example in the text, the time t was set to one calendar year. Figure adapted from Miettinen 9
In Figure 1 , for the sake of simplicity, imagine that, on average, 120 000 young women of reproductive age (between ages 15 and 45 years) who have never had coronary heart disease (CHD), are living in the town, on each day during the calendar year of investigation. This is a dynamic population: each day, new young women will become 15 years old, others will turn 46, some will leave town and others will come to live in the town, some will develop CHD and be replaced by others who do not have the disease and so forth. Such a population can be safely regarded as being ‘in steady state’. The demographic principle of a steady-state population was explained in our previous article; 22 in brief, it assumes that over a small period, e.g. a calendar year, the number of people in a population is approximately constant from day to day because the population is constantly depleted and replenished at about the same rate. It was also explained why this assumption holds, even if the population is not perfectly in a steady state. 22 Thus, we take it that each day of the year, ∼120 000 women of reproductive age, free of clinically recognized CHD, live in the town. Suppose that, on average, 40 000 women use oral contraceptives and 80 000 do not. Again, these are two dynamic subpopulations that can be regarded as being in a steady state. Women start and stop using oral contraceptives for various reasons and switch from use to non-use and back again. As such, in one calendar year, we have 40 000 woman-years of pill use and 80 000 woman-years of non-use, free of CHD.
Suppose that a group of investigators surveys all coronary care units in the town each week to identify all women, aged 15–45 years, admitted with acute myocardial infarction during that period. When a young woman is admitted, the investigators enquire whether she was on the pill––and whether she had previously had a coronary event (if she had, she is excluded from the study). Suppose that, in total, 12 women were admitted for first myocardial infarction during the year of study: eight pill users and four non-users. That produces an incidence rate of 8/40 000 woman-years among pill users and 4/80 000 woman-years among non-users. The ratio of these incidence rates becomes (8/40 000 woman-years)/(4/80 000 woman-years), which is a rate ratio of 4, indicating that women on the pill have an incidence rate of myocardial infarction that is four times that of those not on the pill.
Transformation to a case–control study
In total, 12 cases arise from the population: eight users and four non-users. Those are the potential cases for a case–control study in which the investigators would survey all coronary care units each week of the year. Suppose that the investigators, as their next step, would take a random sample of 600 control subjects from the total source population of the cases (the total of 120 000), by asking 600 women aged 15–45 years, without previous CHD, whether they are ‘on the pill’ at the time the question is asked. Then, on whatever day of the year, this sample of control subjects will include, on average, 200 users and 400 non-users of oral contraceptives. These numbers represent the underlying distribution of woman-years of users and non-users. Together with the cases, this is the complete case–control study (see Table 1 ).
Layout of case-control data sampled from dynamic population: study of occurrence of myocardial infarction in users vs non-users of oral contraceptives, corresponding to Figure 1
| . | Myocardial infarction . | Control subjects . |
|---|---|---|
| Oral contraceptive use | ||
| Yes | 8 | 200 |
| No | 4 | 400 |
| Odds ratio | 4 | |
| . | Myocardial infarction . | Control subjects . |
|---|---|---|
| Oral contraceptive use | ||
| Yes | 8 | 200 |
| No | 4 | 400 |
| Odds ratio | 4 | |
From Table 1 , an odds ratio can be calculated as (8 × 400)/(4 × 200). This exactly equals the ratio of the incidence rates in the underlying population. Algebraically: the incidence rate ratio from the complete dynamic population, which we calculated earlier, can be easily rewritten as (8/4)/(40 000 woman-years/80 000 woman-years). Between parentheses in the numerator of this formula is the number of pill users divided by the number of non-users among all women newly admitted with CHD (= cases in the case–control study). In the denominator, we find the proportion of woman-years on the pill divided by the proportion of woman-years of non-use. It is immediately obvious that—if the steady-state assumption holds—we can estimate the latter proportion directly from the sample of 600 women (= control subjects in case–control study). Among the 600 control subjects, the ratio of exposed to unexposed is expected to be the same as the ratio of the woman-years—except for sampling fluctuations. Thus, what we do in a case–control study is to replace the denominator ratio (40 000 woman-years /80 000 woman-years) by a sample (200/400). We still obtain, on average, the same rate ratio of 4. It follows that to estimate the rate ratio, we do not have to measure, nor to estimate, all the person-years of pill-using and non-using women in town; we can simply determine the ratio of those woman-years by asking a representative sample of women free of CHD from the population from which the cases arise, about their pill use. The complete dynamic population is called the ‘source population’ from which we identify the cases and the sample of control subjects, and the period over which cases and control subjects are identified is the ‘time window’ of observation, also called the ‘risk period’.
The ‘odds ratio’ which is calculated from Table 1 is technically also known as the ‘exposure odds ratio’, as it is the ‘odds of exposure’ in the cases divided by the ‘odds of exposure’ in the controls: (8/4)/(200/400) = 4, the same as the ratio of incidence rates in the whole source population. The great advantage of case–control studies is that we can calculate relative incidences of disease in a population, by collecting all the data for the numerator (by collecting cases in hospitals or registries where they naturally come together), and sampling control subjects from the denominator, i.e. sampling ‘control subjects’ to estimate the relative proportions (exposed vs non-exposed) of the person-years of the exposure of interest in the source population. Thus, one achieves the same result as in a comprehensive population follow-up, at much less expense of time and money. Just imagine the effort of having to do a follow-up study of all 120 000 women of reproductive age in town, also keeping track of when they move in and out of town and constantly updating their oral contraceptive use in a particular calendar year!
Advanced teaching
Cohorts vs dynamic populations.
For researchers who are used to think in terms of clinical cohorts, it can be difficult to understand that populations are not depleted: is it not true that the people with a particular risk factor will develop some disease more often, and thus in the course of time, there will be less of them who are still candidates for developing the disease? That will be true in cohorts because their membership is fixed, but not in dynamic populations. One way to understand this is to think of genetic exposures. People with blood group O develop clotting disorders more frequently, whereas people with blood group A develop more often gastric cancer. However, in a dynamic population, the numbers of people with blood group O or A are not constantly depleted—blood group distribution is fairly constant over time, as new people are born with these blood groups so that an equilibrium is maintained. 22
Another way to understand this concept is to think about an imaginary town and the cases of myocardial infarction that are enrolled in a study. For the aforementioned discussion, we assumed that we were studying all women living in a town during some time over the course of one calendar year (this could be the whole year or a few months). The situation would be entirely different if we restricted our study to all women who lived in the town on the 1 January of that year: then we would only count the myocardial infarctions that happened during this year in women who had been living in town on the 1 January; indeed, the number of women on the pill might decline more than the number of women not on the pill because the myocardial infarctions predominantly occur in the users. That situation would be akin to a clinical cohort study, i.e a study with fixed membership defined by a single common event. 22 However, in a dynamic population, a myocardial infarction that happens in a woman who moved into town during the year also counts in the numerator; she and the other women who move into town replenish the denominator because other women move out. By and large, as with blood groups, the population denominator remains constant in terms of its exposure distributions: the woman-years of oral contraceptive use vs non-use. If the population is truly in steady state, it does not matter when the control subjects are sampled—at the beginning, at the end or at the halfway point of the calendar period (the time window or ‘risk period’).
To refine the concept, the members of a dynamic population do not necessarily have to be present for long periods in the population—as might be surmised from the examples about towns and countries of which one is either an inhabitant or not, and usually for several years. Members of a dynamic population may also switch continuously between being in and out of the population. 22 Take a study on car accidents and mobile phone use by the driver. The risk periods of interest are the periods when people drive. The exposure of interest is phone use. In a case–control study, car accidents are sampled, and it is ascertained (say, via mobile phone operators) whether the driver was phoning at the time of the accident. Control moments might be sampled from the same driver (say, in the previous week) or from other drivers, by sampling other moments of time when they were driving; for each of these control moments, it might be ascertained, via the same mechanism as for the cases, whether they were phoning while driving. These control moments are contrasted with the moment of the accident (the case). If the same driver is used as his or her own control, this type of case–control study is called a ‘case–crossover study’. 24 From the example, it can be understood readily that such a case–control study compares the incidence rate of accidents while driving and phoning vs the incidence rate of accidents while driving and not phoning. 25
What if the exposure distribution of the population is not in steady state?
But what if the exposure distribution in the population is not in steady state? For example, suppose that one wants to investigate in a case–control study whether two different types of oral contraceptives give a different risk of venous thrombosis: ‘third-generation oral contraceptives’ vs ‘second-generation oral contraceptives’ (this was once a real and hotly debated question 26 ). Suppose further that the newer ‘third-generation oral contraceptives’ are strongly marketed, and that their market share clearly increases in the course of the calendar year. That situation is depicted in Figure 2 .
Sampling from the middle of the ‘risk period’ when the exposure distribution is not in steady state. The bold undulating lines show the increasing use of one type of oral contraceptives and the decreasing use of the other type during the time period (risk period). The finer lines below it depict individuals who enter and leave the populations of users of these types of oral contraceptives. Closed circles indicate cases of deep venous thrombosis (DVT) emanating from the population. B and D represent the numbers of users of one type or the other contraceptive at a cross-section in the middle of the time period. Incidence rates (IRs) of DVT can be calculated for both populations separately, and an incidence rate ratio (IRR) can be used to compare these two incidence rates. In a case–control study, B and D are estimated by ‘b’ and ‘d’, the numbers of users of one type or the other type of oral contraceptives in a sample from the source population taken in the middle of the period. The algebraic redrafting of the IRR shows that a ratio of IRs is algebraically equivalent to an ‘exposure odds ratio’ or the ‘cross-product’ that is obtained in a case–control study
There are two solutions:
Sample the control subjects in the middle of the period when the cases accrued, and thereby use the additional assumption that the rise (or fall) of the use of a particular brand of pill is roughly linear over the risk period. Then the control subjects will still represent the average proportion of person-years over the risk period. This is depicted in Figure 2 and is the same solution as is used to calculate person-years (i.e. the denominator) when populations are not in steady state [see previous article on the calculation of incidence rates for explanation]. 22 Alternatively, if one assumes that the incident cases in the dynamic population are evenly spread over time, one might sample control subjects evenly over time.
The more sophisticated solution is the one that researchers often use spontaneously: they sample a (number of) control subject(s) each time there is a case, which amounts to ‘matching on calendar time’. Then the control subject(s) will reflect the underlying population distribution of exposure at each point in time a case occurs, and any assumption about linearity is not needed. This is the most exact solution and is represented in Figure 3 . Matching on calendar time can be done in two ways: (i) invite the control subject(s) around the same calendar date as the case and ask them about their exposure (at that time or at previous times if exposure has a lag time to produce disease); or (ii) if control subjects are invited at a later point in time, present them with an ‘index date’, which is the date as the event of the matching case, and question them and/or measure their exposures for that index date. If control subjects are matched on calendar time, then it is appropriate to take the time matching (and, of course, any other matching factors) into account in the analysis, or at least to check whether it is necessary to control for them.
Case–control sampling in dynamic populations when a control is sampled each time a case occurs: matching on calendar time. Persons move in or out of the population by mechanisms such as birth or death, or move in or out from this population to another. Person-time is indicated by horizontal lines. The time axis is calendar time. The sampling of the control subjects is ‘matched on calendar time’: each time a case occurs, one or more control subjects are sampled. Cases and control subjects can be either exposed or unexposed (not shown here). A person who will become a case can be a control subject earlier, and multiple control subjects or even a variable number of control subjects can be drawn for each case
Hospital-based case–control studies
In most examples presented earlier, the patients are assumed to be sampled from a defined geographical population (via disease registries or by having access to all hospitals of some region), and control subjects are sampled from the underlying dynamic population of this geographical area. If cases from a case–control investigation are sampled from one or more hospitals that do not reflect a well-defined geographic population, still each hospital has a ‘catchment population’, consisting of the patients who will be admitted to that hospital when they develop a particular disease. Such a catchment population can be seen as a dynamic population, with inflow and outflow depending on patient and referring doctor preferences, religious or insurance affiliations, or on the reputation of a particular hospital for particular diseases and so forth. To obtain control subjects for such cases, the investigator should consider patients who are admitted to the same hospital and come from the same catchment population—meaning that if they had developed the case disease, they would have been admitted to that same hospital. This approach obviously has some risks in that the control disease may be associated with the exposure that one wants to study; that risk can (it is hoped) be minimized by using a mix of control diseases, none of which is known to be associated with the exposure under study. 27 Still, the principle of sampling control subjects from a dynamic population remains the same, whether the controls are population-based or hospital-based.
The early case–control study on oral contraceptives and myocardial infarction, which inspired the example presented earlier, sampled cases from a number of coronary care units that were surveyed in one geographically defined hospital area in the UK; for each case interviewed, three women of the same age who were discharged after some acute or elective medical or surgical condition were similarly interviewed about their use of oral contraceptives. 23 Likewise, the first case–control studies on smoking and lung cancer were hospital-based, and control subjects were non-cancer patients being present in the same wards or the same hospital as the lung cancer patients. 2 , 28
Doing a case–control study by sampling from a cohort with fixed membership is relatively rare—a recent survey found that it only occurs in 18% of published case–control studies. 1 It is mostly done when investigators have data available from a cohort, and when it is too expensive to go back and assess the exposures of everybody in the cohort. For example, in an occupational cohort study, personnel records may be available for all cohort members from date of employment, but it may take a considerable amount of work to assess these work histories and estimate cumulative exposures to particular chemicals, whether by using a job-exposure matrix or by an expert panel assessment. 29
Another example is the ‘re-use’ of data or samples from a randomized controlled trial (RCT) for a subsequent investigation. For example, the data from the ‘Physician’s Health Study’ 30 were re-used several years after the trial was finished for a new genetic case–control study; baseline blood samples of participants who developed cardiovascular end points in the trial were used, as were blood samples of matched participants in the trial who remained free of those diseases, and the frequency of one genetic factor (Factor V Leiden) was compared between these cases and control subjects. This investigation thereby considered the trial data as a single cohort in which new exposures were assessed, irrespective of the original randomization.
Figure 4 depicts a cohort with fixed membership from time 0. The cases accrue in the course of the follow-up in the exposed and unexposed part of the cohort. The available cohort data may only relate to exposure status at baseline (as in the aforementioned RCT example), but may also indicate changes in exposure over time, for example, if repeated measurements were done in the cohort study, or if time-related exposure information can be assessed from personnel records, prescribing records or other sources (as in the occupational example).
| Measure . | Definition . | Alternative formulation . |
|---|---|---|
| Odds ratio under exclusive sampling | ||
| Risk ratio under inclusive sampling |
Figure refers to methods 1 and 2 in text under subheading ‘Case–control studies within cohorts’, and is adapted from Rodrigues et al. [13] and Szklo and Nieto [18]
For each case, one or more control subjects are selected from the overall cohort, and the exposure statuses of the case and control subjects are determined at the time they are sampled. There are three options to sample control subjects: 12 , 13 , 18
As in the aforementioned RCT example, investigators often sample control subjects from the people who have still not developed the disease of interest at the end of follow-up (this is termed ‘cumulative incidence sampling’ or ‘exclusive sampling’), and exposure status at beginning of follow-up is used for these cases and controls. As shown algebraically in many textbooks, in that situation, the odds ratio is exactly the same (on average) as the corresponding odds ratio from the full cohort study, and this will approximate the risk ratio or rate ratio (in the full cohort study) only if the disease is rare (say, <5% of exposed and non-exposed develop the disease). This is the ‘rare disease assumption’, as historically first proposed by Cornfield in 1951. 3 It can be seen from Figure 4 that if the disease is rare, even in the exposed (sub)cohort, the ratio of people with and without exposure among those without disease at the end of the follow-up will remain about the same as at the beginning of the follow-up, which is why the ‘rare disease assumption’ works.
An imaginative solution, first proposed by Kupper et al. , 8 is to sample control subjects from all those in the cohort at the beginning of follow-up instead of at the end (‘case-cohort’ or ‘inclusive sampling’). At the beginning of the follow-up, all persons are still disease free (if they are not, then they would not have been included in the cohort). Then, the control subjects reflect the proportion exposed among the source population at the start of follow-up. Some of the control subjects who are sampled at baseline may become cases during follow-up. This seems strange at first sight, but it is not: if in a cohort study or an RCT, the risk is calculated, one uses all persons developing a disease outcome in the numerator, and divides by the denominator, which consists of all people who were present at start of follow-up, including those who will later turn up in the numerator. As can be seen from Figure 4 , sampling from the persons present at the beginning of the follow-up makes the odds ratio from the case–control study exactly the same (on average) as the risk ratio from the full cohort study. This can be understood most easily if one imagines taking a control sample of 100%, that is, all persons present at the beginning: then the odds ratio in the case–control study will be exactly the same as the risk ratio from the cohort study. Next, if one imagines taking a 50% sample for the control subjects, the odds ratio will remain the same (on average). One complication with this method is the calculation of the standard error of the odds ratio, as some persons are both cases and control subjects; different solutions exist. 31 A further complication is that, just as with the estimation of risks (which this sampling scheme corresponds to), losses to follow-up for other reasons than developing the disease that is studied are not easily taken into account; such losses to follow-up may produce bias if they are substantial and differ between exposed and unexposed.
The third option is to sample control subjects longitudinally throughout the risk period (i.e. not just at the beginning or just at the end). Throughout the follow-up of a cohort, the numbers of both exposed and unexposed persons who are free of disease will decrease, and people may be lost to follow-up for other reasons. Moreover, persons may move between exposure categories. The ‘royal road’ is to sample one or more control subjects at each point in time when a case occurs (‘density sampling’, ‘risk-set sampling’ or ‘concurrent sampling’) and determine the exposure status of cases and control subjects at that point in time. This is depicted in Figure 5 . By this sampling approach, the odds ratio from the case–control study will estimate the rate ratio from the cohort study. This is the equivalent of ‘matching on time’ in dynamic populations. This approach is most correct theoretically, but can only be used for cohorts when one has information about disease status of all persons at regular intervals during follow-up (e.g. when cancer incidence or mortality data are available over time).
Third method of sampling from a cohort: longitudinal sampling, also called concurrent sampling, density sampling or risk-set sampling. Persons start follow-up at inclusion in the cohort (e.g. date of surgery) and are followed until either end point occurs (person becomes a case), or the last calendar day of the study. Persons are indicated by fine lines from start of follow-up onwards. The time axis is follow-up time from inclusion (time 0). The longest period of follow-up is by persons who enter the cohort on the calendar day that the study starts; persons entering later will have shorter follow-up because they will be withdrawn from the study at the last calendar day of the study. Cases and control subjects can be either exposed or non-exposed (not shown here). A person who will become a case can be a control subject earlier, and multiple control subjects, or even a variable number of control subjects, can be drawn for each case. In text, see method 3, under subheading ‘Case–control studies within cohorts’
The first solution corresponds to the original theory proposed by Cornfield, 3 and requires the ‘rare disease assumption’ if the goal is to estimate rate ratio or risk ratios; it was the most frequently used method in case–control studies within cohorts in the past—and that approach was used in almost all case–control studies based on cohorts that were identified in the review by Knol et al. 1 Solution 2 still pertains to cohort thinking, but has an imaginative solution to calculate risk ratios; it is often called a ‘case–cohort’ study, and is particularly useful in studies in which a single control sample can be used for multiple case–control studies of various outcomes. Solution 3 is the more sophisticated development in case–control theory, in which the case–control odds ratio estimates the rate ratio from the cohort population over the follow-up period without the need for any rare disease assumption. 10 , 11 However, it is used relatively rarely. 1
A note about terminology: the term ‘nested case–control studies’ seems to be mostly used to denote case–control studies within cohorts which use the third sampling option. However, it is sometimes loosely used to denote all types of case–control sampling within a cohort.
The last method of sampling (method 3) immediately points to a conceptual unity of ‘incidence density sampling’ or ‘density sampling’ in cohorts and in dynamic populations. This was described by Prentice and Breslow in 1978 10 and expanded by Greenland and Thomas in 1982. 11 It can be grasped intuitively by comparing Figures 3 and 5 . The basis of the conceptual unity is that person-years can be calculated from cohorts and from dynamic populations, as was explained in our earlier article. 22
In a case–control study in a dynamic population, investigators often use matching on calendar time spontaneously (a control is chosen each time a case occurs), which is an ideal way of sampling, as it produces an odds ratio that directly estimates the incidence rate ratio, as in Figure 3 . In cohorts, however, one has to use sampling strategy 3, presented earlier, to estimate the incidence rate ratio, as in Figure 5 . The latter necessitates advanced insight and is used infrequently. In advanced textbooks, the ‘matching on time’ in dynamic populations and the ‘concurrent sampling’ in cohorts are often mentioned together as ‘density sampling’. This is theoretically correct, although it obscures the practicalities of the different sampling options.
‘Density sampling’ or ‘risk-set sampling’ from a cohort (i.e. the purer form of sampling of aforementioned strategy 3) involves sampling control subjects from the risk sets that are used in the corresponding Cox proportional hazards model. 10 , 11 A ‘hazard’ or ‘hazard rate’ is the name used in statistics for a peculiar form of ‘incidence rate’, wherein the duration of the follow-up approaches the limit of zero and becomes infinitesimally small; it is also called an ‘instantaneous hazard’. 22 When follow-up time is small, there is no numerical difference between risks and incidence rates. 22 Intuitively, a proportional hazards model in a follow-up analysis of a cohort can be understood as comparing the exposure odds of all successive cases at each point in time with those of the non-cases who are still at risk at that point in time (some of whom may become cases later), that is, the ‘risk set’. The exposure odds ratio or hazard ratio is then averaged over all of these comparisons, assuming it to be constant. Thus, a Cox proportional hazards model in a cohort becomes conceptually similar to a study that is ‘matched’ on time with a ‘variable control-to-case-ratio’ in a dynamic population. The estimation of the proportional hazard in a Cox model can be seen as an average of odds ratios over several risk sets; as the follow-up time in each risk set is small (say, the day of occurrence of the case disease), the odds ratios directly translate to relative risks and incidence rates, for reasons explained in the article on incidence calculations in dynamic populations. 21 , 22
The main difference between the approach we have described in this paper and the classic view of case–control studies as a ‘cohort study in reverse’ is that the dynamic population view reflects how the large majority of case–control studies are actually done. They are not done within cohorts, neither real nor imaginary. Rather, most case–control studies have an underlying population that is dynamic: for example, the geographically defined source population of a disease registry, the catchment areas of a hospital region or people who are driving.
The first case–control studies on smoking and lung cancer were done using cases and control subjects admitted to hospital from vaguely defined catchment areas. 2 , 28 Doll and Hill showed in the discussion of their original case–control study on smoking and lung cancer how one might calculate back to the general population, 2 as they assumed that they had sampled from that population—an insight that was far ahead of their time because it did not need the ‘rare disease assumption’. Although it originated during the period when Cornfield proposed his ‘rare disease assumption’, Doll and Hill’s solution was largely forgotten. Only occasionally does one read back-calculations from case–control studies to the background or source population, perhaps because such back-calculations have intricacies of their own, for example, in the case of matching. 32
An important consequence of primarily teaching case–control studies in dynamic populations, without the rare disease assumption, is that the real assumptions that are necessary for the majority of case–control studies become clear: either the exposure distribution should be in steady state in the dynamic population, or sampling of control subjects should be matched on time in a dynamic population (or equivalently, concurrent in the follow-up of a cohort).
An often-heard precept to guide the design of case–control studies is ‘Think of an imaginary randomized trial when planning your case–control study’. This gives the impression of automatically assuming a cohort, as all randomized trials are cohorts with a fixed membership. However, randomized trials can be done equally well on dynamic populations—public health interventions are often on dynamic populations. When the intervention or the exposure is studied in a case–control study with an underlying dynamic population, design features can be construed that are impossible or difficult in cohorts. For example, a dynamic population free of other key risk factors can be proposed: in a case–control study of the risk of oral contraceptives and venous thrombosis, an investigator might stipulate a dynamic population that has neither major surgery nor plaster casts after breaking legs and so forth—thus limiting the study to ‘idiopathic cases’. That would be difficult in a cohort; for example, in an imaginary randomized trial on oral contraceptives, wherein the outcome would be venous thrombosis, it would seem strange to truncate follow-up at the time of major surgery or plaster cast. In a dynamic population, however, the population is constantly renewed, and this exclusion comes naturally and may have advantages in attributing causality because other major risk factors for the outcome are excluded.
It should be emphasized that when cases and control subjects are selected from a dynamic population (or by risk-set sampling from a cohort), exposures do not need to be assessed solely at the time cases and control subjects are selected (e.g. ‘current use’ of oral contraceptives). In many circumstances, investigators need information on the duration of exposure and/or cumulative exposure. For example, in studies of smoking, the effect on lung cancer only becomes clear after several years. In contrast, the cardiovascular adverse effects of hormone replacement therapy may be limited to the first year of use, so recent exposure is most relevant. Recent and historical exposures can be assessed by a variety of methods in case–control studies, ranging from subjective (e.g. questionnaires) to more objective methods (e.g. birth records, pharmacy records and work histories combined with historical exposure monitoring data). The exposure definition can be easily adapted, by defining as many time windows of exposure as is deemed necessary, for recent and for long-term exposure, because there is a continuous turnover between these categories over time in the underlying population.
In summary, case–control studies with incident cases can be conducted in two contexts—dynamic populations and cohorts—of which the first is the most commonly used 1 because it comes naturally to most investigations. This method should become the basis of teaching case–control studies—in both introductory and more advanced courses:
Case–control studies can be conducted in a dynamic population, and the resulting odds ratio directly estimates the rate ratio from this dynamic population, provided that the control subjects represent the source population’s distribution of person-time of exposure over the risk period. This can be achieved either by matching on time or by selecting control subjects more loosely from the same period, if the population is judged to be in steady state for the exposure(s) and other variables of interest.
Case–control studies can also be conducted within a cohort; in this situation, control subjects can be sampled in three different ways, and the resulting odds ratio can estimate the odds ratio, risk ratio or rate ratio from the corresponding full cohort analysis. 21 Because such case–control studies are a minority, and the need for the rare disease assumption only applies for one method of sampling in such studies, they should not be made central to the basic teaching of case–control studies.
Jan P Vandenbroucke is an Academy Professor of the Royal Netherlands Academy of Arts and Sciences. The center for Public Health research is supported by a Programme Grant from the Health Research Council of New Zealand.
Conflict of interest: None declared.
Google Scholar
Google Preview
- steady state
- oral contraceptives
- mathematics
- rare diseases
| Month: | Total Views: |
|---|---|
| January 2017 | 94 |
| February 2017 | 445 |
| March 2017 | 229 |
| April 2017 | 56 |
| May 2017 | 246 |
| June 2017 | 145 |
| July 2017 | 112 |
| August 2017 | 113 |
| September 2017 | 191 |
| October 2017 | 254 |
| November 2017 | 237 |
| December 2017 | 642 |
| January 2018 | 808 |
| February 2018 | 822 |
| March 2018 | 1,019 |
| April 2018 | 1,157 |
| May 2018 | 980 |
| June 2018 | 798 |
| July 2018 | 560 |
| August 2018 | 1,048 |
| September 2018 | 1,034 |
| October 2018 | 970 |
| November 2018 | 878 |
| December 2018 | 564 |
| January 2019 | 580 |
| February 2019 | 817 |
| March 2019 | 952 |
| April 2019 | 947 |
| May 2019 | 980 |
| June 2019 | 583 |
| July 2019 | 531 |
| August 2019 | 460 |
| September 2019 | 710 |
| October 2019 | 704 |
| November 2019 | 560 |
| December 2019 | 446 |
| January 2020 | 485 |
| February 2020 | 580 |
| March 2020 | 489 |
| April 2020 | 405 |
| May 2020 | 395 |
| June 2020 | 532 |
| July 2020 | 404 |
| August 2020 | 442 |
| September 2020 | 561 |
| October 2020 | 660 |
| November 2020 | 483 |
| December 2020 | 422 |
| January 2021 | 453 |
| February 2021 | 443 |
| March 2021 | 565 |
| April 2021 | 503 |
| May 2021 | 465 |
| June 2021 | 330 |
| July 2021 | 310 |
| August 2021 | 321 |
| September 2021 | 574 |
| October 2021 | 564 |
| November 2021 | 387 |
| December 2021 | 344 |
| January 2022 | 427 |
| February 2022 | 501 |
| March 2022 | 500 |
| April 2022 | 451 |
| May 2022 | 488 |
| June 2022 | 319 |
| July 2022 | 291 |
| August 2022 | 289 |
| September 2022 | 440 |
| October 2022 | 571 |
| November 2022 | 461 |
| December 2022 | 377 |
| January 2023 | 380 |
| February 2023 | 359 |
| March 2023 | 415 |
| April 2023 | 460 |
| May 2023 | 414 |
| June 2023 | 329 |
| July 2023 | 325 |
| August 2023 | 332 |
| September 2023 | 483 |
| October 2023 | 647 |
| November 2023 | 475 |
| December 2023 | 370 |
| January 2024 | 673 |
| February 2024 | 502 |
| March 2024 | 708 |
| April 2024 | 530 |
| May 2024 | 563 |
| June 2024 | 377 |
Email alerts
Citing articles via, looking for your next opportunity.
- About International Journal of Epidemiology
- Recommend to your Library
Affiliations
- Online ISSN 1464-3685
- Copyright © 2024 International Epidemiological Association
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Pharmacoepidemiology
9. CASE CONTROL STUDIES
Case control studies are a vital research design in pharmacoepidemiology that allows researchers to examine the associations between medication use and health outcomes. These studies involve comparing individuals with a specific outcome (cases) to individuals without the outcome (controls) and assessing their prior exposure to medications or other factors of interest. By retrospectively analyzing data, case-control studies provide valuable insights into the potential causal relationships between medication use and adverse events. In this article, we will delve into the significance of case-control studies in pharmacoepidemiology, their methodology, strengths, limitations, and contributions to improving medication safety and patient outcomes.
PATH: PHARMD/ PHARMD NOTES/ PHARMD FIFTH YEAR NOTES/ PHARMACOEPIDEMIOLOGY AND PHARMACOECONOMICS/ CASE CONTROL STUDIES.
Leave a Reply Cancel Reply
Your email address will not be published. Required fields are marked *
Name *
Email *
Add Comment *
Save my name, email, and website in this browser for the next time I comment.
Post Comment
- Share full article
Advertisement
Supported by
C.D.C. Warns Doctors About Dengue as Virus Spreads to New Regions
The excruciating mosquito-borne disease is surging in much of the world. Federal health officials urged physicians to watch for new cases in the United States.

By Stephanie Nolen and Teddy Rosenbluth
Federal health officials warned that the risk of contracting dengue in the United States has increased this year, a worrying sign as global cases of the mosquito-borne disease hit record numbers.
In the first half of this year, countries in the Americas reported twice as many cases as were reported in all of 2023, the Centers for Disease Control and Prevention reported Thursday in an alert to health care providers.
The region has seen nearly 10 million cases of the virus so far in 2024, most of which originated in outbreaks in South American countries like Brazil and Argentina.
While the local transmission of the virus in the continental United States has been limited, Puerto Rico, which is classified as having “ frequent or continuous ” dengue risk, declared a public health emergency in March and has reported nearly 1,500 cases.
Cases of dengue fever, a mosquito-borne viral illness that can be fatal, are surging around the world. The increase is occurring both in places that have long struggled with the disease and in areas where its spread was unheard-of until the last year or two, including France, Italy and Chad , in Central Africa.
There have even been a few hundred cases of local transmission in the United States. Florida health officials urged the public to take precautions — like wearing bug spray and dumping out standing water — after reporting a locally acquired case of dengue this month.
We are having trouble retrieving the article content.
Please enable JavaScript in your browser settings.
Thank you for your patience while we verify access. If you are in Reader mode please exit and log into your Times account, or subscribe for all of The Times.
Thank you for your patience while we verify access.
Already a subscriber? Log in .
Want all of The Times? Subscribe .
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Community Eye Health
- v.11(28); 1998
Epidemiology in Practice: Case-Control Studies
Introduction.
A case-control study is designed to help determine if an exposure is associated with an outcome (i.e., disease or condition of interest). In theory, the case-control study can be described simply. First, identify the cases (a group known to have the outcome) and the controls (a group known to be free of the outcome). Then, look back in time to learn which subjects in each group had the exposure(s), comparing the frequency of the exposure in the case group to the control group.
By definition, a case-control study is always retrospective because it starts with an outcome then traces back to investigate exposures. When the subjects are enrolled in their respective groups, the outcome of each subject is already known by the investigator. This, and not the fact that the investigator usually makes use of previously collected data, is what makes case-control studies ‘retrospective’.
Advantages of Case-Control Studies
Case-control studies have specific advantages compared to other study designs. They are comparatively quick, inexpensive, and easy. They are particularly appropriate for (1) investigating outbreaks, and (2) studying rare diseases or outcomes. An example of (1) would be a study of endophthalmitis following ocular surgery. When an outbreak is in progress, answers must be obtained quickly. An example of (2) would be a study of risk factors for uveal melanoma, or corneal ulcers. Since case-control studies start with people known to have the outcome (rather than starting with a population free of disease and waiting to see who develops it) it is possible to enroll a sufficient number of patients with a rare disease. The practical value of producing rapid results or investigating rare outcomes may outweigh the limitations of case-control studies. Because of their efficiency, they may also be ideal for preliminary investigation of a suspected risk factor for a common condition; conclusions may be used to justify a more costly and time-consuming longitudinal study later.
Consider a situation in which a large number of cases of post-operative endophthalmitis have occurred in a few weeks. The case group would consist of all those patients at the hospital who developed post-operative endophthalmitis during a pre-defined period.
The definition of a case needs to be very specific:
- Within what period of time after operation will the development of endophthalmitis qualify as a case – one day, one week, or one month?
- Will endophthalmitis have to be proven microbiologically, or will a clinical diagnosis be acceptable?
- Clinical criteria must be identified in great detail. If microbiologic facilities are available, how will patients who have negative cultures be classified?
- How will sterile inflammation be differentiated from endophthalmitis?
There are not necessarily any ‘right’ answers to these questions but they must be answered before the study begins. At the end of the study, the conclusions will be valid only for patients who have the same sort of ‘endophthalmitis’ as in the case definition.
Controls should be chosen who are similar in many ways to the cases. The factors (e.g., age, sex, time of hospitalisation) chosen to define how controls are to be similar to the cases are the ‘matching criteria’. The selected control group must be at similar risk of developing the outcome; it would not be appropriate to compare a group of controls who had traumatic corneal lacerations with cases who underwent elective intraocular surgery. In our example, controls could be defined as patients who underwent elective intraocular surgery during the same period of time.
Matching Cases and Controls
Although controls must be like the cases in many ways, it is possible to over-match. Over-matching can make it difficult to find enough controls. Also, once a matching variable has been selected, it is not possible to analyse it as a risk factor. Matching for type of intraocular surgery (e.g., secondary IOL implantation) would mean including the same percentage of controls as cases who had surgery to implant a secondary IOL; if this were done, it would not be possible to analyse secondary IOL implantation as a potential risk factor for endophthalmitis.
An important technique for adding power to a study is to enroll more than one control for every case. For statistical reasons, however, there is little gained by including more than two controls per case.
Collecting Data
After clearly defining cases and controls, decide on data to be collected; the same data must be collected in the same way from both groups. Care must be taken to be objective in the search for past risk factors, especially since the outcome is already known, or the study may suffer from researcher bias. Although it may not always be possible, it is important to try to mask the outcome from the person who is collecting risk factor information or interviewing patients. Sometimes it will be necessary to interview patients about potential factors (such as history of smoking, diet, use of traditional eye medicines, etc.) in their past. It may be difficult for some people to recall all these details accurately. Furthermore, patients who have the outcome (cases) are likely to scrutinize the past, remembering details of negative exposures more clearly than controls. This is known as recall bias. Anything the researcher can do to minimize this type of bias will strengthen the study.
Analysis; Odds Ratios and Confidence Intervals
In the analysis stage, calculate the frequency of each of the measured variables in each of the two groups. As a measure of the strength of the association between an exposure and the outcome, case-control studies yield the odds ratio. An odds ratio is the ratio of the odds of an exposure in the case group to the odds of an exposure in the control group. It is important to calculate a confidence interval for each odds ratio. A confidence interval that includes 1.0 means that the association between the exposure and outcome could have been found by chance alone and that the association is not statistically significant. An odds ratio without a confidence interval is not very meaningful. These calculations are usually made with computer programmes (e.g., Epi-Info). Case-control studies cannot provide any information about the incidence or prevalence of a disease because no measurements are made in a population based sample.
Risk Factors and Sampling
Another use for case-control studies is investigating risk factors for a rare disease, such as uveal melanoma. In this example, cases might be recruited by using hospital records. Patients who present to hospital, however, may not be representative of the population who get melanoma. If, for example, women present less commonly at hospital, bias might occur in the selection of cases.
The selection of a proper control group may pose problems. A frequent source of controls is patients from the same hospital who do not have the outcome. However, hospitalised patients often do not represent the general population; they are likely to suffer health problems and they have access to the health care system. An alternative may be to enroll community controls, people from the same neighborhoods as the cases. Care must be taken with sampling to ensure that the controls represent a ‘normal’ risk profile. Sometimes researchers enroll multiple control groups . These could include a set of community controls and a set of hospital controls.
Confounders
Matching controls to cases will mitigate the effects of confounders . A confounding variable is one which is associated with the exposure and is a cause of the outcome. If exposure to toxin ‘X’ is associated with melanoma, but exposure to toxin ‘X’ is also associated with exposure to sunlight (assuming that sunlight is a risk factor for melanoma), then sunlight is a potential confounder of the association between toxin ‘X’ and melanoma.
Case-control studies may prove an association but they do not demonstrate causation. Consider a case-control study intended to establish an association between the use of traditional eye medicines (TEM) and corneal ulcers. TEM might cause corneal ulcers but it is also possible that the presence of a corneal ulcer leads some people to use TEM. The temporal relationship between the supposed cause and effect cannot be determined by a case-control study.
Be aware that the term ‘case-control study’ is frequently misused. All studies which contain ‘cases’ and ‘controls’ are not case-control studies. One may start with a group of people with a known exposure and a comparison group (‘control group’) without the exposure and follow them through time to see what outcomes result, but this does not constitute a case-control study.
Case-control studies are sometimes less valued for being retrospective. However, they can be a very efficient way of identifying an association between an exposure and an outcome. Sometimes they are the only ethical way to investigate an association. If care is taken with definitions, selection of controls, and reducing the potential for bias, case-control studies can generate valuable information.
Case-Control Studies: Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
Recommended Reading
COMMENTS
We conducted a negative case-control study to identify the symptoms associated with SARS-CoV-2-positive results in Portugal. Twelve symptoms and signs included in the clinical notification of COVID-19 were selected as predictors, and the dependent variable was the RT-PCR test result.
We conducted a test-negative case-control study to assess whether being a health professional was associated with a positive COVID-19 test. The test-negative case-control study design follows the same principle as a standard case-control study but differs in the way cases and controls are selected . Indeed, cases are individuals who test ...
We concluded that, if the case-control study is well conducted it is as valid as a cohort study. Key words: Case-control study, epidemiology, chronic diseases. Os estudos caso-controle (ECC) têm tido utilização crescente nas últimas décadas, com variadas formas de aplicação no campo da Epidemiologia e da Saúde Pública.
STROBE Checklists. STROBE Checklist: cohort, case-control, and cross-sectional studies (combined) Download PDF | Word; STROBE Checklist (fillable): cohort, case-control, and cross-sectional studies (combined)
Rev Port Cardiol. 2005 Jul-Aug;24(7-8):1017-23. [Article in English, Portuguese] ... the first of a series of articles defining types of clinical studies, we present case-control studies. This type of study is a valid research methodology, producing important data with less time, cost and effort than other types of research studies. ...
Case-control studies are one of the major observational study designs for performing clinical research. The advantages of these study designs over other study designs are that they are relatively quick to perform, economical, and easy to design and implement. Case-control studies are particularly appropriate for studying disease outbreaks, rare diseases, or outcomes of interest.
Abstract. Case-control studies are observational studies in which cases are subjects who have a characteristic of interest, such as a clinical diagnosis, and controls are (usually) matched subjects who do not have that characteristic. After cases and controls are identified, researchers "look back" to determine what past events (exposures ...
General Overview of Case-Control Studies. In observational studies, also called epidemiologic studies, the primary objective is to discover and quantify an association between exposures and the outcome of interest, in hopes of drawing causal inference. Observational studies can have a retrospective study design, a prospective design, a cross ...
Case-control studies are one of the major observational study designs for performing clinical research. The advantages of these study designs over other study designs are that they are relatively quick to perform, economical, and easy to design and implement. Case-control studies are particularly appropriate for studying disease outbreaks, rare ...
Revised on June 22, 2023. A case-control study is an experimental design that compares a group of participants possessing a condition of interest to a very similar group lacking that condition. Here, the participants possessing the attribute of study, such as a disease, are called the "case," and those without it are the "control.".
A case-control study (also known as case-referent study) is a type of observational study in which two existing groups differing in outcome are identified and compared on the basis of some supposed causal attribute. Case-control studies are often used to identify factors that may contribute to a medical condition by comparing subjects who have the condition with patients who do not have ...
Introduction. Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence. These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as ...
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes.[1] The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to the case individuals but do not have the ...
Case-Control study design is a type of observational study. In this design, participants are selected for the study based on their outcome status. Thus, some participants have the outcome of interest (referred to as cases), whereas others do not have the outcome of interest (referred to as controls). The investigator then assesses the exposure ...
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes. The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to ...
The main advantages of a nested case-control study are as follows: (1) cost reduction and effort minimization, as only a fraction of the parent cohort requires the necessary outcome assessment; (2) reduced selection bias, as both case and control subjects are sampled from the same population; and (3) flexibility in analysis by allowing testing of a hypotheses in the future that is not ...
1 Introduction to case-control studies 8 1.1 Defining a case-control study 8 1.2 Measuring association: the odds ratio 12 1.3 Methods for controlling confounding 13 1.4 Temporal aspects 16 1.5 Further details on the sampling of cases and controls 20 1.6 Bias in case-control studies 23 1.7 Use of case-control studies 26 Notes 29 2 The simplest ...
The purpose of this article is to present in elementary mathematical and statistical terms a simple way to quickly and effectively teach and understand case-control studies, as they are commonly done in dynamic populations—without using the rare disease assumption. Our focus is on case-control studies of disease incidence ('incident ...
Tradução de "case-control study" em português. This is a case-control study and, certainly, there are limitations. Trata-se de um estudo caso-controle e certamente há limitações. A hospital-based case-control study was conducted to investigate occupational risk factors for laryngeal cancer. Um estudo caso-controle de base hospitalar foi ...
Design. In a case-control study, a number of cases and noncases (controls) are identified, and the occurrence of one or more prior exposures is compared between groups to evaluate drug-outcome associations ( Figure 1 ). A case-control study runs in reverse relative to a cohort study. 21 As such, study inception occurs when a patient ...
Epidemiologists benefit greatly from having case-control study designs in their research armamentarium. Case-control studies can yield important scientific findings with relatively little time, money, and effort compared with other study designs. This seemingly quick road to research results entices many newly trained epidemiologists. Indeed, investigators implement case-control studies more ...
Case control studies are a vital research design in pharmacoepidemiology that allows researchers to examine the associations between medication use and health outcomes. These studies involve comparing individuals with a specific outcome (cases) to individuals without the outcome (controls) and assessing their prior exposure to medications or ...
The excruciating mosquito-borne disease is surging in much of the world. Federal health officials urged physicians to watch for new cases in the United States.
Introduction. A case-control study is designed to help determine if an exposure is associated with an outcome (i.e., disease or condition of interest). In theory, the case-control study can be described simply. First, identify the cases (a group known to have the outcome) and the controls (a group known to be free of the outcome).