JavaScript Speech Recognition Example (Speech to Text)
With the Web Speech API, we can recognize speech using JavaScript . It is super easy to recognize speech in a browser using JavaScript and then getting the text from the speech to use as user input. We have already covered How to convert Text to Speech in Javascript .
But the support for this API is limited to the Chrome browser only . So if you are viewing this example in some other browser, the live example below might not work.

This tutorial will cover a basic example where we will cover speech to text. We will ask the user to speak something and we will use the SpeechRecognition object to convert the speech into text and then display the text on the screen.
The Web Speech API of Javascript can be used for multiple other use cases. We can provide a list of rules for words or sentences as grammar using the SpeechGrammarList object, which will be used to recognize and validate user input from speech.
For example, consider that you have a webpage on which you show a Quiz, with a question and 4 available options and the user has to select the correct option. In this, we can set the grammar for speech recognition with only the options for the question, hence whatever the user speaks, if it is not one of the 4 options, it will not be recognized.
We can use grammar, to define rules for speech recognition, configuring what our app understands and what it doesn't understand.

JavaScript Speech to Text
In the code example below, we will use the SpeechRecognition object. We haven't used too many properties and are relying on the default values. We have a simple HTML webpage in the example, where we have a button to initiate the speech recognition.
The main JavaScript code which is listening to what user speaks and then converting it to text is this:
In the above code, we have used:
recognition.start() method is used to start the speech recognition.
Once we begin speech recognition, the onstart event handler can be used to inform the user that speech recognition has started and they should speak into the mocrophone.
When the user is done speaking, the onresult event handler will have the result. The SpeechRecognitionEvent results property returns a SpeechRecognitionResultList object. The SpeechRecognitionResultList object contains SpeechRecognitionResult objects. It has a getter so it can be accessed like an array. The first [0] returns the SpeechRecognitionResult at the last position. Each SpeechRecognitionResult object contains SpeechRecognitionAlternative objects that contain individual results. These also have getters so they can be accessed like arrays. The second [0] returns the SpeechRecognitionAlternative at position 0 . We then return the transcript property of the SpeechRecognitionAlternative object.
Same is done for the confidence property to get the accuracy of the result as evaluated by the API.
We have many event handlers, to handle the events surrounding the speech recognition process. One such event is onspeechend , which we have used in our code to call the stop() method of the SpeechRecognition object to stop the recognition process.
Now let's see the running code:
When you will run the code, the browser will ask for permission to use your Microphone , so please click on Allow and then speak anything to see the script in action.
Conclusion:
So in this tutorial we learned how we can use Javascript to write our own small application for converting speech into text and then displaying the text output on screen. We also made the whole process more interactive by using the various event handlers available in the SpeechRecognition interface. In future I will try to cover some simple web application ideas using this feature of Javascript to help you usnderstand where we can use this feature.
If you face any issue running the above script, post in the comment section below. Remember, only Chrome browser supports it .
You may also like:
- JavaScript Window Object
- JavaScript Number Object
- JavaScript Functions
- JavaScript Document Object

IF YOU LIKE IT, THEN SHARE IT
Related posts.
JavaScript Speech Recognition
Speech Recognition is a broad term that is often associated solely with Speech-to-Text technology. However, Speech Recognition can also include technologies such as Wake Word Detection , Voice Command Recognition , and Voice Activity Detection ( VAD ).
This article provides a thorough guide on integrating on-device Speech Recognition into JavaScript Web apps. We will be learning about the following technologies:
- Cobra Voice Activity Detection
Porcupine Wake Word
Rhino speech-to-intent, cheetah streaming speech-to-text, leopard speech-to-text.
In addition to plain JavaScript, Picovoice's Speech Recognition engines are also available in different UI frameworks such as React , Angular , and Vue .
Cobra Voice Activity Detection is a VAD engine that can be used to detect the presence of human speech within an audio signal.
- Install the Web Voice Processor and Cobra Voice Activity Detection Web SDK packages using npm :
Sign up for a free Picovoice Console account and copy your AccessKey from the main dashboard. The AccessKey is only required for authentication and authorization.
Create an instance of CobraWorker :
- Subscribe CobraWorker to WebVoiceProcessor to start processing audio frames:
For further details, visit the Cobra Voice Activity Detection product page or refer to the Cobra Web SDK quick start guide .
Porcupine Wake Word is a wake word detection engine that can be used to listen for user-specified keywords and activate dormant applications when a keyword is detected.
- Install the Web Voice Processor and Porcupine Wake Word Web SDK packages using npm :
Create and download a custom Wake Word model using Picovoice Console.
Add the Porcupine model ( .pv ) for your language of choice and your custom Wake Word model ( .ppn ) created in the previous step to the project's public directory:
- Create objects containing the Porcupine model and Wake Word model options:
- Create an instance of PorcupineWorker :
- Subscribe PorcupineWorker to WebVoiceProcessor to start processing audio frames:
For further details, visit the Porcupine Wake Word product page or refer to the Porcupine Web SDK quick start guide .
Rhino Speech-to-Intent is a voice command recognition engine that infers user intents from utterances, allowing users to interact with applications via voice.
- Install the Web Voice Processor and Rhino Speech-to-Intent Web SDK packages using npm :
Create your Context using Picovoice Console.
Add the Rhino Speech-to-Intent model ( .pv ) for your language of choice and the Context model ( .rhn ) created in the previous step to the project's public directory:
- Create an object containing the Rhino Speech-to-Intent model and Context model options:
- Create an instance of RhinoWorker :
- Subscribe RhinoWorker to WebVoiceProcessor to start processing audio frames:
For further details, visit the Rhino Speech-to-Intent product page or refer to the Rhino's Web SDK quick start guide .
Cheetah Streaming Speech-to-Text is a speech-to-text engine that transcribes voice data in real time, synchronously with audio generation.
- Install the Web Voice Processor and Cheetah Streaming Speech-to-Text Web SDK packages using npm :
Generate a custom Cheetah Streaming Speech-to-Text model from the Picovoice Console ( .pv ) or download the default model ( .pv ).
Add the model to the project's public directory:
- Create an object containing the model options:
- Create an instance of CheetahWorker :
- Subscribe CheetahWorker to WebVoiceProcessor to start processing audio frames:
For further details, visit the Cheetah Streaming Speech-to-Text product page or refer to the Cheetah Web SDK quick start guide .
In contrast to Cheetah Streaming Speech-to-Text , Leopard Speech-to-Text waits for the complete spoken phrase to complete before providing a transcription, enabling higher accuracy and runtime efficiency.
- Install the Leopard Speech-to-Text Web SDK package using npm :
Generate a custom Leopard Speech-to-Text model ( .pv ) from Picovoice Console or download a default model ( .pv ) for the language of your choice.
- Create an instance of LeopardWorker :
- Transcribe audio (sample rate of 16 kHz, 16-bit linearly encoded and 1 channel):
For further details, visit the Leopard Speech-to-Text product page or refer to Leopard's Web SDK quick start guide .
Subscribe to our newsletter
More from Picovoice

Learn how to perform Speech Recognition in iOS, including Speech-to-Text, Voice Commands, Wake Word Detection, and Voice Activity Detection.

Learn how to perform Speech Recognition in Android, including Speech-to-Text, Voice Commands, Wake Word Detection, and Voice Activity Detect...

Learn how to perform Speech Recognition in Python, including Speech-to-Text, Voice Commands, Wake Word Detection, and Voice Activity Detecti...

Learn about the Speech Recognition tools for Raspberry Pi: Wake Word Detection, Voice Commands, Speech-to-Text, and Voice Activity Detection...

ChatGPT has become one of the most popular AI algorithms since its release in November 2022. Developers and enterprises immediately started ...

Anyone with an email address or a GitHub account can use Picovoice to train voice models and deploy them, even commercially, for free.

Picovoice Console is the web-based platform to design and train on-device speech models for converting speech to text, keyword and intent de...

Synthesize text to speech using Picovoice Orca Text-to-Speech Web SDK. The SDK runs on all modern web browsers.
- Español – América Latina
- Português – Brasil
- Tiếng Việt
- Chrome for Developers
Voice driven web apps - Introduction to the Web Speech API
The new JavaScript Web Speech API makes it easy to add speech recognition to your web pages. This API allows fine control and flexibility over the speech recognition capabilities in Chrome version 25 and later. Here's an example with the recognized text appearing almost immediately while speaking.

DEMO / SOURCE
Let’s take a look under the hood. First, we check to see if the browser supports the Web Speech API by checking if the webkitSpeechRecognition object exists. If not, we suggest the user upgrades their browser. (Since the API is still experimental, it's currently vendor prefixed.) Lastly, we create the webkitSpeechRecognition object which provides the speech interface, and set some of its attributes and event handlers.
The default value for continuous is false, meaning that when the user stops talking, speech recognition will end. This mode is great for simple text like short input fields. In this demo , we set it to true, so that recognition will continue even if the user pauses while speaking.
The default value for interimResults is false, meaning that the only results returned by the recognizer are final and will not change. The demo sets it to true so we get early, interim results that may change. Watch the demo carefully, the grey text is the text that is interim and does sometimes change, whereas the black text are responses from the recognizer that are marked final and will not change.
To get started, the user clicks on the microphone button, which triggers this code:
We set the spoken language for the speech recognizer "lang" to the BCP-47 value that the user has selected via the selection drop-down list, for example “en-US” for English-United States. If this is not set, it defaults to the lang of the HTML document root element and hierarchy. Chrome speech recognition supports numerous languages (see the “ langs ” table in the demo source), as well as some right-to-left languages that are not included in this demo, such as he-IL and ar-EG.
After setting the language, we call recognition.start() to activate the speech recognizer. Once it begins capturing audio, it calls the onstart event handler, and then for each new set of results, it calls the onresult event handler.
This handler concatenates all the results received so far into two strings: final_transcript and interim_transcript . The resulting strings may include "\n", such as when the user speaks “new paragraph”, so we use the linebreak function to convert these to HTML tags <br> or <p> . Finally it sets these strings as the innerHTML of their corresponding <span> elements: final_span which is styled with black text, and interim_span which is styled with gray text.
interim_transcript is a local variable, and is completely rebuilt each time this event is called because it’s possible that all interim results have changed since the last onresult event. We could do the same for final_transcript simply by starting the for loop at 0. However, because final text never changes, we’ve made the code here a bit more efficient by making final_transcript a global, so that this event can start the for loop at event.resultIndex and only append any new final text.
That’s it! The rest of the code is there just to make everything look pretty. It maintains state, shows the user some informative messages, and swaps the GIF image on the microphone button between the static microphone, the mic-slash image, and mic-animate with the pulsating red dot.
The mic-slash image is shown when recognition.start() is called, and then replaced with mic-animate when onstart fires. Typically this happens so quickly that the slash is not noticeable, but the first time speech recognition is used, Chrome needs to ask the user for permission to use the microphone, in which case onstart only fires when and if the user allows permission. Pages hosted on HTTPS do not need to ask repeatedly for permission, whereas HTTP hosted pages do.
So make your web pages come alive by enabling them to listen to your users!
We’d love to hear your feedback...
- For comments on the W3C Web Speech API specification: email , mailing archive , community group
- For comments on Chrome’s implementation of this spec: email , mailing archive
Refer to the Chrome Privacy Whitepaper to learn how Google is handling voice data from this API.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2013-01-13 UTC.
Why Webscale
- The CloudFlow Supercloud Platform Orchestrate applications effortlessly across a multi-cloud network with CloudFlow’s user-friendly interface and AI-enhanced workload automation.
- Features CloudFlow Interface Adaptive Edge Engine Composable Edge Cloud

- By Organizational Need Cloud Cost Optimization Resource Utilization Cloud Observability Application Performance Security & Compliance Managed Kubernetes Multi-cloud
- By Organization Type Ecommerce and Digital Experience Independent Software Vendors (ISV) Enterprise Kubernetes

- What is Intelligent CloudOps?
- Performance
- Transition to Modern Commerce
- CloudOps Plans
- CloudEDGE Security
- VelocityEDGE
- Managed Performance
- What is a Supercloud?
- Supercloud vs. CDN
- Webscale CloudFlow Supercloud Platform
- Features and Benefits
- What is Kuberenetes Lifecycle Management?
- Kuberenetes Management Platform vs. DIY Kubernetes Management
- Webscale CloudFlow Kuberenetes Management Platform
- Webscale Partner Program Our partners Tools Engagement Models Best Practices
- Apply as a Partner
- Register an Opportunity
- Find a Partner

- Awards and Recognition
- Press Releases

- Resource Library
- Engineering Education
- WebscaleOne Docs
- CloudFlow Docs
- Webscale Portal
- Stratus Portal
- CloudFlow Portal
- The CloudFlow Supercloud Platform
- CloudFlow Interface
- Adaptive Edge Engine
- Composable Edge Cloud
- Ecommerce and Digital Experience
- Independent Software Vendors (ISV)
- Enterprise Kubernetes
- Partner Program
- Partner Application
Speech Recognition Using the Web Speech API in JavaScript
Jan 11, 2021
Topics: Languages
The Web Speech API is used to incorporate voice data into web apps. In this tutorial, we will build a simple webpage that uses the Web Speech API to implement speech recognition. You can check the browser compatibility for the Web Speech API here .
Prerequisites
To follow along with this tutorial, you should have:
- A basic understanding of HTML and JavaScript.
- A code editor. I’ll be using Visual Studio Code .
- A browser to view the webpage, preferably Google Chrome or Firefox .
Cloning the starter code
To focus more on speech recognition, I’ve prepared some starter code. You can clone it from this repository on GitHub. Follow the Repository’s README for instructions.
For the final code, you can look at this GitHub Repository .
In the starter code, I’ve set up a language and dialect select menu, two buttons to start/stop the speech recognition, and a box to display the transcript. I’ve used Bootstrap to style the webpage.

First, create a new JavaScript file and name it speechRecognition.js . Next, add the script to the HTML file using the script tag after the body tag.
Adding the script tag after the body tag will make sure that the script file is loaded after all the elements have been loaded to the DOM which aids performance.
Now, inside the script file, let’s check if the webkitSpeechRecognition class is available in the window object. If not, let’s console.log so that it’s not available.
Initialization
Everything we write from now on goes inside the if condition.
Let’s create a webkitSpeechRecognition object.
Now, let’s configure some properties on this speechRecognition object.
Continuous listening
The speech recognition object can either stop listening after the user stops speaking or it can keep listening until the user stops it. If you only want to recognize a phrase or a word, you can set this to false . For this tutorial, let’s set it to true .
Interim results
Interim results are results that are not yet final. If you enable this property, the speechRecognition object will also return the interim results along with the final results. Let’s set it to true .
This is the language that the user will speak in. You need to use locale codes to set this property. Please note that not all languages are available in this feature yet.
Let’s set the language that the user has chosen from the select menu. You need to select the Dialect select menu and use its value for the language property.
Events & callbacks
You can provide callbacks for events like onStart , onEnd , onResult , and onError .
This event is triggered when speech recognition is started by the user. Let’s pass a callback function that will display that the speech recognition instance is listening on the webpage.
In the starter code, there is a <p> element with an ID called status that says Listening... . It’s been hidden by setting the display property of the element to none using CSS.
Let’s set it to display: block when the speech recognition starts.
This event is triggered when the speech recognition is ended by the user. Let’s pass a callback function that will hide the status <p> element in the webpage.
Let’s set it to display: none when the speech recognition starts.
This event is triggered when there is some sort of error in speech recognition. Let’s pass a callback function that will hide the status <p> element in the webpage.
This event is triggered when the speechRecognition object has some results from the recognition. It will contain the final results and interim results. Let’s pass a callback function that will set the results to the respective <span> inside the transcript box.
This is the HTML code for the transcript box on the web page. The interim results span is colored in a different color to differentiate between the interim results and the final results.
We need to set the interim results to the span with the ID interim and the final results to the span with the ID final.
The result event will pass an event object to the callback function. This object will contain the results in the form of an array. Each element in the array will have a property called isFinal denoting whether that item is an interim result or a final result.
Let’s declare a variable for the final transcript outside the callback function and a variable for the interim transcript inside the callback function.
Now let’s build a string from the results array. We should run it through a loop and add the result item to the final transcript if the result item is final. If not, we should add it to the interim results string.
Finally, let’s update the DOM with the transcript values.
This is the complete code snippet for the onResult event.
Start/Stop recognition
Finally, let’s start and stop the recognition.
We need to set the onClick property of the start and stop buttons to start and stop the speech recognition.
Here is the final code for speechRecognition.js :
You can take a look at the deployed version of the project here .
Let’s Recap
- We cloned the starter code from the GitHub repository.
- We created a new JavaScript file and linked it to the HTML file.
- We checked whether the webkitSpeechRecognition class was available on the window object.
- We created a new instance of the webkitSpeechRecognition class.
- We set some properties like continuous , interimResults , and language on that speech recognition instance.
- We added callback methods for different events like onStart , onEnd , onError , and onResult .
- We set the onClick property of the start and stop buttons to start and stop the speech recognition.
Congratulations, 🥳 You did it.
Thanks for reading!

EngEd Author Bio
Mohan Raj is a Full Stack (MERN)/ React-Native developer and a last year CS Undergrad in Chennai, India. He wants to help other developers avoid some of the same challenges he faced while developing various features.1900Peer Reviewer
Table of contents
Try Launching a Free Project in CloudFlow Today!
Similar Articles

How to Create a Reusable React Form component
Prerequisites In this tutorial, one ought to have the following: Basic React and Javascript knowledge. Understanding of npm and how to install from npm Atom or Visual studio code and npm installed on a pc. Goal To create a reusable form which can...

Working with Bash Arrays
As a programmer, you may have come across or used the command line when building a tool, or for scripting. Bash is one of the most common command-line interpreters used for writing scripts. You can create variables, run for loops, work with arrays,...

How to Control Web Pages Visible to Different Users using PHP
Different categories of users access a website at any given time. However, some pages in a website are meant to be accessed by specific users. For instance, web pages accessed by the system administrator may not be the same as the pages which are...
- Advertise with us
- Explore by categories
- Free Online Developer Tools
- Privacy Policy
- Comment Policy
Getting started with the Speech Recognition API in Javascript

Carlos Delgado
- January 22, 2017
- 27.1K views
Learn how to use the speech recognition API with Javascript in Google Chrome
The JavaScript API Speech Recognition enables web developers to incorporate speech recognition into your web page. This API allows fine control and flexibility over the speech recognition capabilities in Chrome version 25 and later. This API is experimental, that means that it's not available on every browser. Even in Chrome, there are some attributes of the API that aren't supported. For more information visit Can I Use Speech Recognition .
In this article you will learn how to use the Speech Recognition API, in its most basic expression.
Implementation
To get started, you will need to know wheter the browser supports the API or not. To do this, you can verify if the window object in the browser has the webkitSpeechRecognition property using any of the following snippets:
Once you verify, you can start to work with this API. Create a new instance of the webkitSpeechRecognition class and set the basic properties:
Now that the basic options are set, you will need to add some event handlers. In this case we are going add the basic listeners as onerror , onstart , onend and onresult (event used to retrieve the recognized text).
The onresult event receives as first parameter a custom even object. The results are stored in the event.results property (an object of type SpeechRecognitionResultList that stores the SpeechRecognitionResult objects, this in turn contains instances of SpeechRecognitionAlternative with the transcript property that contains the text ).
As the final step, you need to start it by executing the start method of the recognition object or to stop it once it's running executing the stop method:
Now the entire functional snippet to use the speech recognition API should look like:
Once you execute the start method, the microphone permission dialog will be shown in the Browser.
Go ahead and test it in your web or local server. You can see a live demo of the Speech Recognition API working in the browser in all the available languages from the official Chrome Demos here .
Supported languages
Currently, the API supports 40 languages in Chrome. Some languages have specifical codes according to the region (the identifiers follow the BCP-47 format ):
You can use the following object if you need the previous table in Javascript and you can iterate it as shown in the example:
Whose output in the console will be:
Happy coding !
Senior Software Engineer at Software Medico . Interested in programming since he was 14 years old, Carlos is a self-taught programmer and founder and author of most of the articles at Our Code World.
Related Articles

How to switch the language of Artyom.js on the fly with a voice command
- December 10, 2017

Getting started with Optical Character Recognition (OCR) with Tesseract in Node.js
- January 02, 2017
- 34.3K views

Getting started with Optical Character Recognition (OCR) with Tesseract in Symfony 3
- 30.9K views

How to create your own voice assistant in ReactJS using Artyom.js
- August 07, 2017
- 18.8K views

How to add voice commands to your webpage with javascript
- February 15, 2016

Voice commands (speech recognition) and speech Synthesis with Electron Framework
- June 07, 2016
- 15.6K views
Advertising

All Rights Reserved © 2015 - 2024
- Skip to main content
- Select language
- Skip to search
Using the Web Speech API
Handling errors and unrecognised speech, updating the displayed pitch and rate values.
The Web Speech API provides two distinct areas of functionality — speech recognition, and speech synthesis (also know as text to speech, or tts) — which open up interesting new possibilities for accessibility, and control mechanisms. This article provides a simple introduction to both areas, along with demos.
Speech recognition
Speech recognition involves receiving speech through a device's microphone, which is then checked by a speech recognition service against a list of grammar (basically, the vocabulary you want to have recognised in a particular app.) When a word or phrase is successfully recognised, it is returned as a result (or list of results) as a text string, and further actions can be initiated as a result.
The Web Speech API has a main controller interface for this — SpeechRecognition — plus a number of closely-related interfaces for representing grammar, results, etc. Generally, the default speech recognition system available on the device will be used for the speech recognition — most modern OSes have a speech recognition system for issuing voice commands. Think about Dictation on Mac OS X, Siri on iOS, Cortana on Windows 10, Android Speech, etc.
To show simple usage of Web speech recognition, we've written a demo called Speech color changer . When the screen is tapped/clicked, you can say an HTML color keyword, and the app's background color will change to that color.

To run the demo, you can clone (or directly download ) the Github repo it is part of, open the HTML index file in a supporting desktop browser, navigate to the live demo URL in a supporting mobile browser like Chrome, or load it onto a Firefox OS phone as an app via WebIDE (permissions are required to run the API on Firefox OS, see below.)
Browser support
Support for Web Speech API speech recognition is still getting there across mainstream browsers, and is currently limited to the following:
Firefox desktop and mobile support it in Gecko 44+, without prefixes, and it can be turned on by flipping the media.webspeech.recognition.enable flag to true in about:config . The permissions settings/UI haven't yet been sorted out however, so permission can't be granted to use it by the user, so it can't be used. This will be fixed soon.
Firefox OS 2.5+ supports it, but as a privileged API that requires permissions. You therefore need to set the following in the manifest.webapp (and either install it via WebIDE, or get your app verified and made available on the Firefox Marketplace ):
Chrome for Desktop and Android have supported it since around version 33 but with prefixed interfaces, so you need to include prefixed versions of them, e.g. webkitSpeechRecognition .
HTML and CSS
The HTML and CSS for the app is really trivial. We simply have a title, instructions paragraph, and a div into which we output diagnostic messages.
The CSS provides a very simple responsive styling so that it looks ok across devices.
Let's look at the JavaScript in a bit more detail.
Chrome support
As mentioned earlier, Chrome currently supports speech recognition with prefixed properties, therefore at the start of our code we include these lines to feed the right objects to Chrome, and non-prefix browsers, like Firefox:
The grammar
The next part of our code defines the grammar we want our app to recognise. The following variable is defined to hold our grammar:
The grammar format used is JSpeech Grammar Format ( JSGF ) — you can find a lot more about it at the previous link to its spec. However, for now let's just run through it quickly:
- The lines are separated by semi-colons, just like in JavaScript.
- The first line — #JSGF V1.0; — states the format and version used. This always needs to be included first.
- The second line indicates a type of term that we want to recognise. public declares that it is a public rule, the string in angle brackets defines the recognised name for this term ( color ), and the list of items that follow the equals sign are the alternative values that will be recognised and accepted as appropriate values for the term. Note how each is separated by a pipe character.
- You can have as many terms defined as you want on separate lines following the above structure, and include fairly complex grammar definitions. For this basic demo, we are just keeping things simple.
Plugging the grammar into our speech recognition
The next thing to do is define a speech recogntion instance to control the recognition for our application. This is done using the SpeechRecognition() constructor. We also create a new speech grammar list to contain our grammar, using the SpeechGrammarList() constructor.
We add our grammar to the list using the SpeechGrammarList.addFromString() method. This accepts as parameters the string we want to add, plus optionally a weight value that specifies the importance of this grammar in relation of other grammars available in the list (can be from 0 to 1 inclusive.) The added grammar is available in the lst as a SpeechGrammar object instance.
We then add the SpeechGrammarList to the speech recognition instance by setting it to the value of the SpeechRecognition.grammars property. We also set a few other properties of the recognition instance before we move on:
- SpeechRecognition.lang : Sets the language of the recognition. Setting this is good practice, and therefore recommended.
- SpeechRecognition.interimResults : Defines whether the speech recognition system should return interim results, or just final results. Final results are good enough for this simple demo.
- SpeechRecognition.maxAlternatives : Sets the number of alternative potential matches that should be returned per result. This can sometimes be useful, say if a result is not completely clear and you want to display a list if alternatives for the user to choose the correct one from. But it is not needed for this simple demo, so we are just specifying one (which is actually the default anyway.)
Note : SpeechRecognition.continuous controls whether continuous results are captured, or just a single result each time recognition is started. It is commented out because currently it is not implemented in Gecko, so setting this was breaking the app. You can get a similar result by simply stopping the recognition after the first result is received, as you'll see later on.
Starting the speech recognition
After grabbing references to the output element (or HTML Document Division Element) is the generic container for flow content, which does not inherently represent anything. It can be used to group elements for styling purposes (using the class or id attributes), or because they share attribute values, such as lang. It should be used only when no other semantic element (such as <article> or <nav>) is appropriate." href="../../HTML/Element/div.html"> <div> and the HTML element (so we can output diagnostic messages and update the app background color later on), we implement an onclick handler so that when the screen is tapped/clicked, the speech recognition service will start. This is achieved by calling SpeechRecognition.start() . The forEach() method is used to output colored indicators showing what colors to try saying.
Receiving and handling results
Once the speech recognition is started, there are many event handlers than can be used to retrieve results, and other pieces of surrounding information (see the SpeechRecognition event handlers list .) The most common one you'll probably use is SpeechRecognition.onresult , which is fired once a successful result is received:
The third line here is a bit complex-looking, so let's explain it step by step. The SpeechRecognitionEvent.results property returns a SpeechRecognitionResultList object containing SpeechRecognitionResult objects. It has a getter so it can be accessed like an array — so the [last] returns the SpeechRecognitionResult at the last position. Each SpeechRecognitionResult object contains SpeechRecognitionAlternative objects that contain individual recognised words. These also have getters so they can be accessed like arrays — the [0] therefore returns the SpeechRecognitionAlternative at position 0. We then return its transcript property to get a string containing the individual recognised result as a string, set the background color to that color, and report the color recognised as a diagnostic message in the UI.
We also use a SpeechRecognition.onspeechend handler to stop the speech recognition service from running (using SpeechRecognition.stop() ) once a single word has been recognised and it has finished being spoken:
The last two handlers are there to handle cases where speech was recognised that wasn't in the defined grammar, or an error occured. SpeechRecognition.onnomatch seems to be supposed to handle the first case mentioned, although note that at the moment it doesn't seem to fire correctly in Firefox or Chrome; it just returns whatever was recognised anyway:
SpeechRecognition.onerror handles cases where there is an actual error with the recognition successfully — the SpeechRecognitionError.error property contains the actual error returned:
Speech synthesis
Speech synthesis (aka text-to-speech, or tts) involves receiving synthesising text contained within an app to speech, and broadcasting it out of a device's microphone.
The Web Speech API has a main controller interface for this — SpeechSynthesis — plus a number of closely-related interfaces for representing text to be synthesised (known as utterances), voices to be used for the utterance, etc. Again, most OSes have some kind of speech synthesis system, which will be used by the API for this task as available.
To show simple usage of Web speech synthesis, we've provided a demo called Speak easy synthesis . This includes a set of form controls for entering text to be synthesised, and setting the pitch, rate, and voice to use when the text is uttered. After you have entered your text, you can press Enter / Return to hear it spoken.

To run the demo, you can clone (or directly download ) the Github repo it is part of, open the HTML index file in a supporting desktop browser, or navigate to the live demo URL in a supporting mobile browser like Chrome, or Firefox OS.
Support for Web Speech API speech synthesis is still getting there across mainstream browsers, and is currently limited to the following:
Firefox desktop and mobile support it in Gecko 42+ (Windows)/44+, without prefixes, and it can be turned on by flipping the media.webspeech.synth.enabled flag to true in about:config .
Firefox OS 2.5+ supports it, by default, and without the need for any permissions.
Chrome for Desktop and Android have supported it since around version 33, without prefixes.
The HTML and CSS are again pretty trivial, simply containing a title, some instructions for use, and a form with some simple controls. The ) element represents a control that presents a menu of options. The options within the menu are represented by <option> elements, which can be grouped by <optgroup> elements. Options can be pre-selected for the user." href="../../HTML/Element/select.html"> <select> element is initially empty, but is populated with element is used to create a control representing an item within a <select>, an <optgroup> or a <datalist> HTML5 element." href="../../HTML/Element/option.html"> <option> s via JavaScript (see later on.)
Let's investigate the JavaScript that powers this app.
Setting variables
First of all, we capture references to all the DOM elements involved in the UI, but more interestingly, we capture a reference to Window.speechSynthesis . This is API's entry point — it returns an instance of SpeechSynthesis , the controller interface for web speech synthesis.
Populating the select element
To populate the ) element represents a control that presents a menu of options. The options within the menu are represented by <option> elements, which can be grouped by <optgroup> elements. Options can be pre-selected for the user." href="../../HTML/Element/select.html"> <select> element with the different voice options the device has available, we've written a populateVoiceList() function. We first invoke SpeechSynthesis.getVoices() , which returns a list of all the available voices, represented by SpeechSynthesisVoice objects. We then loop through this list — for each voice we create an element is used to create a control representing an item within a <select>, an <optgroup> or a <datalist> HTML5 element." href="../../HTML/Element/option.html"> <option> element, set its text content to display the name of the voice (grabbed from SpeechSynthesisVoice.name ), the language of the voice (grabbed from SpeechSynthesisVoice.lang ), and -- DEFAULT if the voice is the default voice for the synthesis engine (checked by seeing if SpeechSynthesisVoice.default returns true .)
We also create data- attributes for each option, containing the name and language of the associated voice, so we can grab them easily later on, and then append the options as children of the select.
When we come to run the function, we do the following. This is because Firefox doesn't support SpeechSynthesis.onvoiceschanged , and will just return a list of voices when SpeechSynthesis.getVoices() is fired. With Chrome however, you have to wait for the event to fire before populaitng the list, hence the if statement seen below.
Speaking the entered text
Next, we create an event handler to start speaking the text entered into the text field. We are using an onsubmit handler on the form so that the action happens when Enter / Return is pressed. We first create a new SpeechSynthesisUtterance() instance using its constructor — this is passed the text input's value as a parameter.
Next, we need to figure out which voice to use. We use the HTML Element. These elements also share all of the properties and methods of other HTML elements via the HTMLElement interface." href="../../../DOM/HTMLSelectElement.html"> HTMLSelectElement selectedOptions property to return the currently selected element is used to create a control representing an item within a <select>, an <optgroup> or a <datalist> HTML5 element." href="../../HTML/Element/option.html"> <option> element. We then use this element's data-name attribute, finding the SpeechSynthesisVoice object whose name matches this attribute's value. We set the matching voice object to be the value of the SpeechSynthesisUtterance.voice property.
Finally, we set the SpeechSynthesisUtterance.pitch and SpeechSynthesisUtterance.rate to the values of the relevant range form elements. Then, with all necessary preparations made, we start the utterance being spoken by invoking SpeechSynthesis.speak() , passing it the SpeechSynthesisUtterance instance as a parameter.
In the final part of the handler, we include an SpeechSynthesisUtterance.onpause handler to demonstrate how SpeechSynthesisEvent can be put to good use. When SpeechSynthesis.pause() is invoked, this returns a message reporting the character number and name that the speech was paused at.
Finally, we call blur() on the text input. This is mainly to hide the keyboard on Firefox OS.
The last part of the code simply updates the pitch / rate values displayed in the UI, each time the slider positions are moved.
Document Tags and Contributors
- recognition
- Web Speech API
- About AssemblyAI
JavaScript Text-to-Speech - The Easy Way
Learn how to build a simple JavaScript Text-to-Speech application using JavaScript's Web Speech API in this step-by-step beginner's guide.

Contributor
When building an app, you may want to implement a Text-to-Speech feature for accessibility, convenience, or some other reason. In this tutorial, we will learn how to build a very simple JavaScript Text-to-Speech application using JavaScript's built-in Web Speech API .
For your convenience, we have provided the code for this tutorial application ready for you to fork and play around with over at Replit , or ready for you to clone from Github . You can also view a live version of the app here .
Step 1 - Setting Up The App
First, we set up a very basic application using a simple HTML file called index.html and a JavaScript file called script.js .
We'll also use a CSS file called style.css to add some margins and to center things, but it’s entirely up to you if you want to include this styling file.
The HTML file index.html defines our application's structure which we will add functionality to with the JavaScript file. We add an <h1> element which acts as a title for the application, an <input> field in which we will enter the text we want spoken, and a <button> which we will use to submit this input text. We finally wrap all of these objects inside of a <form> . Remember, the input and the button have no functionality yet - we'll add that in later using JavaScript.
Inside of the <head> element, which contains metadata for our HTML file, we import style.css . This tells our application to style itself according to the contents of style.css . At the bottom of the <body> element, we import our script.js file. This tells our application the name of the JavaScript file that stores the functionality for the application.
Now that we have finished the index.html file, we can move on to creating the script.js JavaScript file.
Since we imported the script.js file to our index.html file above, we can test its functionality by simply sending an alert .
To add an alert to our code, we add the line of code below to our script.js file. Make sure to save the file and refresh your browser, you should now see a little window popping up with the text "It works!".
If everything went ok, you should be left with something like this:

Step 2 - Checking Browser Compatibility
To create our JavaScript Text-to-Speech application, we are going to utilize JavaScript's built-in Web Speech API. Since this API isn’t compatible with all browsers, we'll need to check for compatibility. We can perform this check in one of two ways.
The first way is by checking our operating system and version on caniuse.com .
The second way is by performing the check right inside of our code, which we can do with a simple conditional statement:
This is a shorthand if/else statement, and is equivalent to the following:
If you now run the app and check your browser console, you should see one of those messages. You can also choose to pass this information on to the user by rendering an HTML element.
Step 3 - Testing JavaScript Text-to-Speech
Next up, let’s write some static code to test if we can make the browser speak to us.
Add the following code to the script.js file.
Code Breakdown
Let’s look at a code breakdown to understand what's going on:
- With const synth = window.speechSynthesis we declare the synth variable to be an instance of the SpeechSynthesis object, which is the entry to point to using JavaScript's Web Speech API. The speak method of this object is what ultimately converts text into speech.
- let ourText = “Hey there what’s up!!!!” defines the ourText variable which holds the string of text that we want to be uttered.
- const utterThis = new SpeechSynthesisUtterance(ourText) defines the utterThis variable to be a SpeechSynthesisUtterance object, into which we pass ourText .
- Putting it all together, we call synth.speak(utterThis) , which utters the string inside ourText .
Save the code and refresh the browser window in which your app runs in order to hear a voice saying “ Hey there what’s up!!!! ”.
Step 4 - Making Our App Dynamic
Our code currently provides us with a good understanding of how the Text-to-Speech aspect of our application works under the hood, but the app at this point only converts the static text which we defined with ourText into speech. We want to be able to dynamically change what text is being converted to speech when using the application. Let’s do that now utilizing a <form> .
- First, we add the const textInputField = document.querySelector("#text-input") variable, which allows us to access the value of the <input> tag that we have defined in the index.html file in our JavaScript code. We select the <input> field by its id: #text-input .
- Secondly, we add the const form = document.querySelector("#form") variable, which selects our form by its id #form so we can later submit the <form> using the onsubmit function.
- We initialize ourText as an empty string instead of a static sentence.
- We wrap our browser compatibility logic in a function called checkBrowserCompatibility and then immediately call this function.
Finally, we create an onsubmit handler that executes when we submit our form. This handler does several things:
- event.preventDefault() prevents the browser from reloading after submitting the form.
- ourText = textInputField.value sets our ourText string to whatever we enter in the "input" field of our application.
- utterThis.text = ourText sets the text to be uttered to the value of ourText .
- synth.speak(utterThis) utters our text string.
- textInputField.value resets the value of our input field to an empty string after submitting the form.
Step 5 - Testing Our JavaScript Text-to-Speech App
To test our JavaScript Text-to-Speech application, simply enter some text in the input field and hit “Submit” in order to hear the text converted to speech.
Additional Features
There are a lot of properties that can be modified when working with the Web Speech API. For instance:
You can try playing around with these properties to tailor the application to your needs.
This simple example provides an outline of how to use the Web Speech API for JavaScript Text-to-Speech .
While Text-to-Speech is useful for accessibility, convenience, and other purposes, there are a lot of use-cases in which the opposite functionality, i.e. Speech-to-Text, is useful. We have built a couple of example projects using AssemblyAI’s Speech-to-Text API that you can check out for those who want to learn more.
Some of them are:
- React Speech Recognition with React Hooks
- How To Convert Voice To Text Using JavaScript
Popular posts

AI trends in 2024: Graph Neural Networks

Developer Educator at AssemblyAI

AI for Universal Audio Understanding: Qwen-Audio Explained

Combining Speech Recognition and Diarization in one model

How DALL-E 2 Actually Works

Your Much Needed Guide to Speech Recognition in Javascript with a Speech-To-Text API
Rev › Blog › Resources › Other Resources › Speech-to-Text APIs › Your Much Needed Guide to Speech Recognition in Javascript with a Speech-To-Text API
This article details a simple web application that works with the Rev.ai speech-to-text API using JavaScript. The web application will allow a user to submit an audio/video file to be transcribed by the Rev.ai API. The web app will also allow a user to stream audio to and receive real-time speech-to-text transcriptions using their microphone. Going forward the Rev.ai API will be referred to as the API.
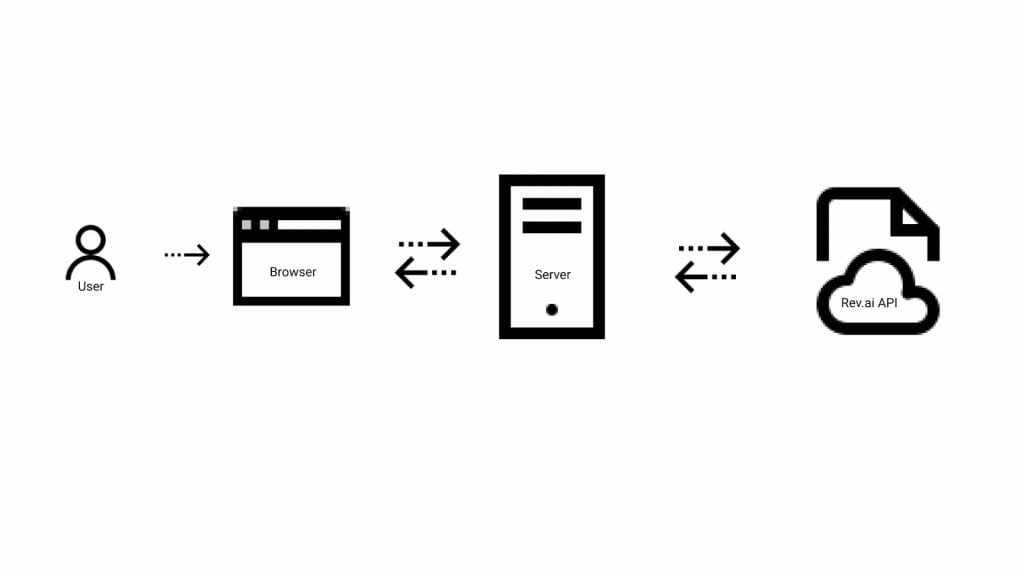
Architecture
Communication with the API is dependent on an individual’s access token which is also linked to payment information and can incur charges. For this reason, the access token should be kept secret to prevent unauthorized use. While it is technically possible to communicate with the APIs directly from the browser, browsers are not very good at keeping secrets. Using secrets and access tokens in the browser should be avoided.
A server written in Node.js using the Express framework is used to keep communication with the APIs secure while also facilitating communication between the browser and the APIs. The browser communicates with the server using a combination of HTTP requests and WebSocket messages. The Rev.ai NodeSDK is used to communicate with the API from the server. The server also provides a webhook endpoint that can be called by the API when an asynchronous job submission is completed.
Running the Web App
To run the web app first download or clone the following git repository:
Then run the following command to install the necessary dependencies: npm install
Next, create a new file named .env or rename the sample.env and update the Environment variables as follows:
access_token =<Rev.ai access token>
base_url = <url that Rev.ai can use to communicate with the server>
media_path = <relative path of where to store uploaded media files>
Then run the following command to start the server: npm start
In a browser navigate to either the value defined as the base_url or http://localhost:3000
Submit An Audio/Video File To Be Transcribed
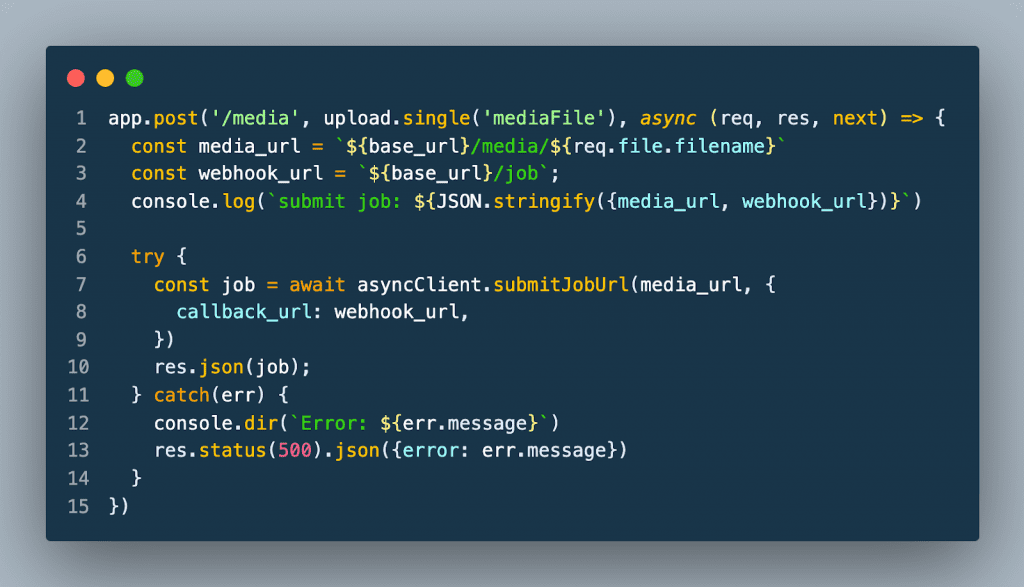
The submit an audio/video file functionality demonstrates the API’s asynchronous functionality. First, the user selects either an audio or video file to be processed by the API and whether they want to display the results as a caption or transcription. The file is then uploaded to the /media endpoint on the server as multi-part form data.
To handle the file upload on the server, a file upload handler middleware library name Multer is used. Multer stores the file in a specified location on the server. A job is submitted to the API with a URL that points to the uploaded media file along with the URL to the webhook defined at the /job endpoint.
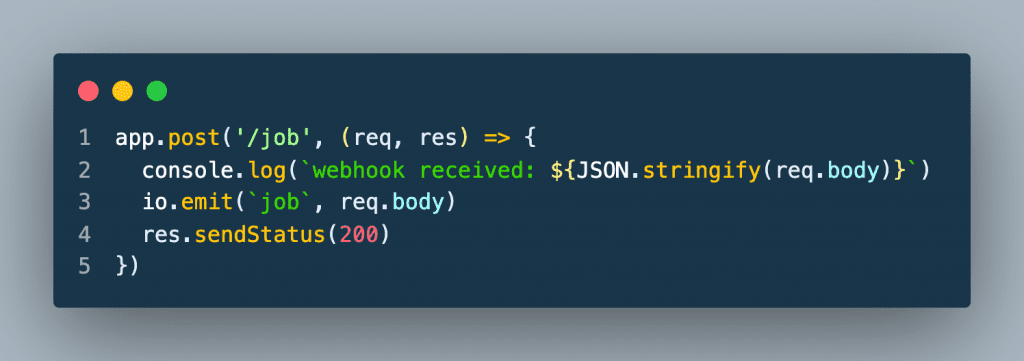
When the API has completed processing the job, the webhook endpoint is called. The server then sends the response from the API to the browser using the WebSocket connection. A status of 200 is returned to the API.
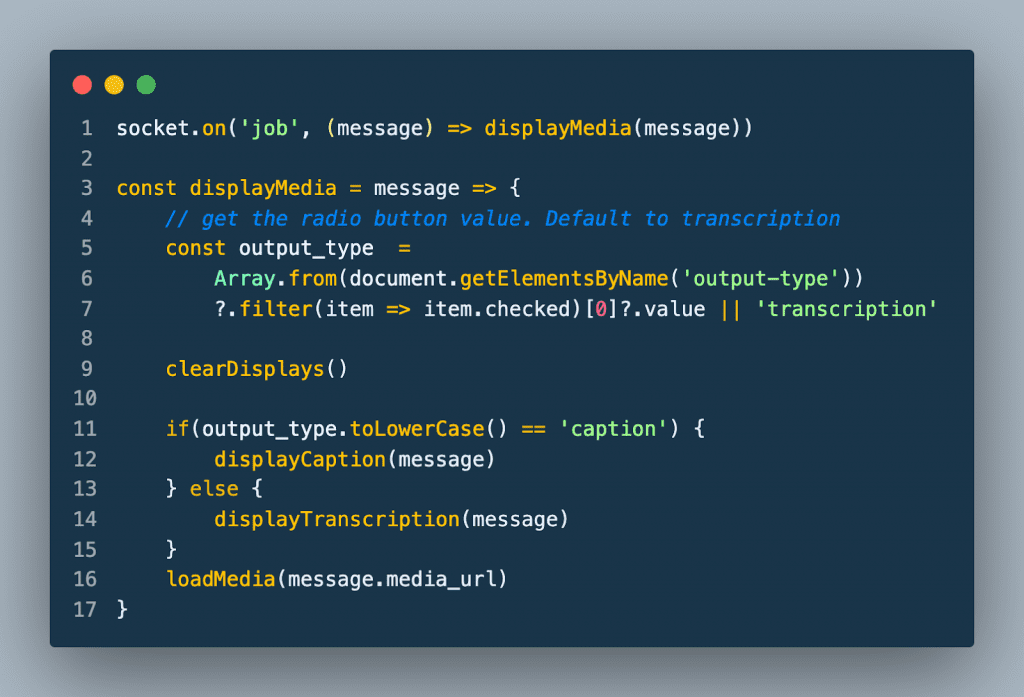
When the browser receives the job WebSocket message it sends an HTTP request to the server to retrieve either the transcription or caption from the API.
Streaming API
The stream microphone feature demonstrates the API’s streaming functionality. First, the user clicks the Start Recording button to start the streaming session. When the button is clicked the browser sends a request to the server to open a streaming connection with the API. The browser then captures the user’s audio and sends it to the RecordRTC library. The RecordRTC library is used to encode the audio to wav format. The output of the encoding is then streamed to the server over the WebSocket connection.
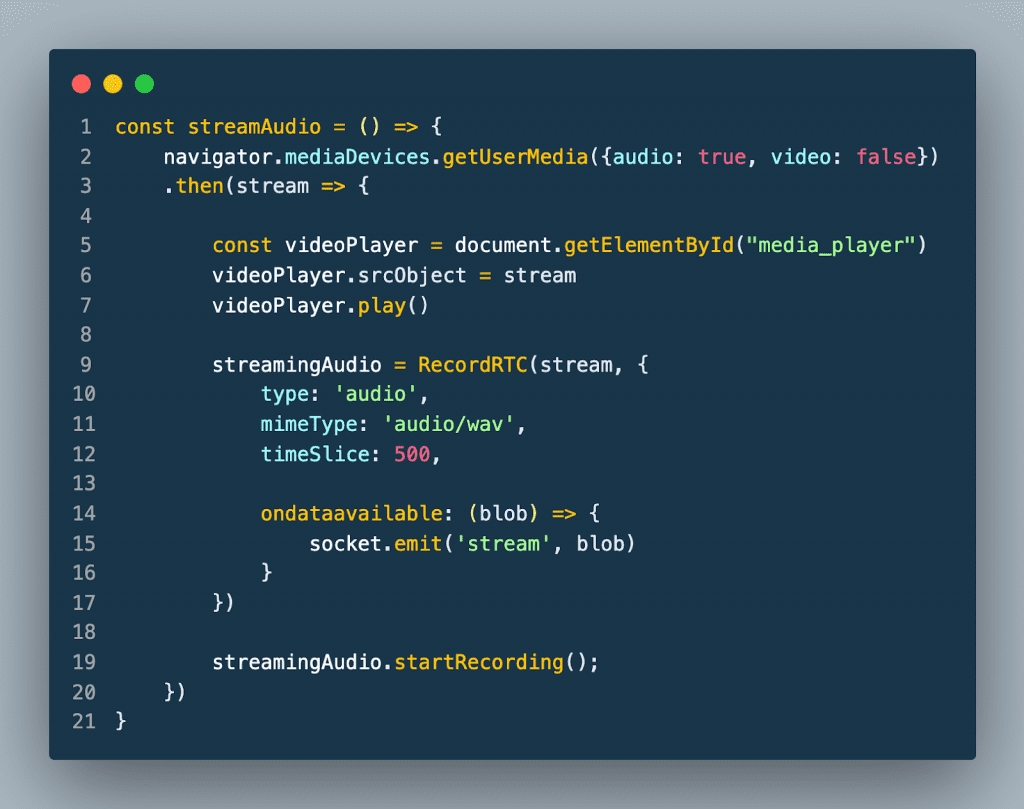
The server then sends that data to the API. The API then sends back transcription information in real-time as it is being processed. When the server receives data from the API and sends it to the browser over WebSocket. The browser then displays the transcription in real-time.

The Stop Recording button is clicked when the user is finished streaming. When the button is clicked the browser sends a request to the server. The server then closes the streaming connection with the API.
Why use Rev AI?
Accuracy is important when providing automated services. For ASRs a key measurement of accuracy is the Word Error Rate (WER). WER is measured by the number of errors divided by the total number of words. Errors include words incorrectly transcribed, additional words that were added, and words that were omitted. The lower the WER the more accurate an ASR is. Rev AI has the lowest WER among its competitors.

Ease of Use
There is no need to learn some new proprietary format. Interacting with the API is as simple as sending an HTTP request. The API responds with either plaintext or JSON.
Communication with the API is encrypted both in transit and at rest. You are also given control of your data. Data can be deleted through an API endpoint or deletion policies can be created from the web application. When tighter controls are necessary, the on-premise solution allows you to run the speech-to-text engine in your own private instance.
The first 5 hours of speech-to-text translation are free which is more than sufficient enough to test drive the API. After that, it’s $0.035 per minute of speech processed rounded to the nearest 15 seconds. An hour-long audio file would cost approximately $2.10.
More Caption & Subtitle Articles
Everybody’s favorite speech-to-text blog.
We combine AI and a huge community of freelancers to make speech-to-text greatness every day. Wanna hear more about it?
DEV Community
Posted on Aug 22, 2022 • Updated on Aug 25, 2022
Speech Recognition with JavaScript
Cover image credits: dribbble
Some time ago, speech recognition API was added to the specs and we got partial support on Chrome, Safari, Baidu, android webview, iOS safari, samsung internet and Kaios browsers ( see browser support in detail ).
Disclaimer: This implementation won't work in Opera (as it doesn't support the constructor) and also won't work in FireFox (because it doesn't support a single thing of it) so if you're using one of those, I suggest you to use Chrome -or any other compatible browser- if you want to take a try.
Speech recognition code and PoC
Edit: I realised that for any reason it won't work when embedded so here's the link to open it directly .
The implementation I made currently supports English and Spanish just to showcase.
Quick instructions and feature overview:
- Choose one of the languages from the drop down.
- Hit the mic icon and it will start recording (you'll notice a weird animation).
- Once you finish a sentence it will write it down in the box.
- When you want it to stop recording, simply press the mic again (animation stops).
- You can also hit the box to copy the text in your clipboard.
Speech Recognition in the Browser with JavaScript - key code blocks:
This implementation currently supports the following languages for speech recognition:
If you want me to add support for more languages tell me in the comment sections and I'm updating it in a blink so you can test it on your own language 😁
That's all for today, hope you enjoyed I sure did doing that
Top comments (20)
Templates let you quickly answer FAQs or store snippets for re-use.
- Location 3000
- Work Mr at StartUp
- Joined Aug 17, 2019
It's cool mate. Very good
- Location Spain
- Education Higher Level Education Certificate on Web Application Development
- Work Tech Lead/Lead Dev
- Joined Apr 19, 2019
Thank you! 🤖
Can u add Telugu a Indian language:)
I can try, do you know the IETF/ISO language code for it? 😁
- Location İstanbul, Turkey
- Joined Apr 28, 2022
This is really awesome. Could you please add the Turkish language? I would definitely like to try this in my native language and use it in my projects.
- Location Cyprus
- Work CTO at AINIRO AS
- Joined Mar 13, 2022
Cool. I once created a speech based speech recognition thing based upon MySQL and SoundEx allowing me to create code by speaking through my headphones. It was based upon creating a hierarchical “menu” where I could say “Create button”. Then the machine would respond with “what button”, etc. The thing of course produced Hyperlambda though. I doubt it can be done without meta programming.
One thing that bothers me is that this was 5 years ago, and speech support has basically stood 100% perfectly still in all browsers since then … 😕
Not in all of them, (e.g. Opera mini, FireFox mobile), it's a nice to have in browsers, specially targeting accessibility, but screen readers for blind people do the job and, on the other hand, most implementations for any other purpose send data to a backend using streams so they can process the incoming speech plus use the user feedback to train an IA among others and without hurting the performance.
...allowing me to create code by speaking through my headphones... ... I doubt it can be done without meta programming.
I agree on this. The concept "metaprogramming" is extense and covers different ways in which it can work (or be implemented) and from its own definition it is a building block for this kind of applications.
- Location Rio de Janeiro, RJ
- Work System Analist
- Joined May 18, 2021
Thank you 🙏. I'd like that you put in Brazilian Portuguse too.
Added both Portugal and Brazilian portuguese 😁
- Work Student
- Joined Jul 21, 2022
Thanks you 🙏. I'd like that you put in french too.
Thank you! 😁
- Work Technical Manager @ Gabrieli Media Group
- Joined Aug 29, 2022
Thank you very much for your useful article and implementation. Does it support Greek? Have a nice (programming) day
Hi Symeon, added support for Greek el-GR , try it out! 😃
- Education Cameroon
- Joined Aug 26, 2022
I added support for some extra languages in the mean time 😁
- Joined Jan 15, 2023
Can you please add urdu language
Hi @aheedkhan I'm not maintaining this anymore but feel free to fork the pen! 😄
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment's permalink .
Hide child comments as well
For further actions, you may consider blocking this person and/or reporting abuse

React Error Boundary: A Guide to Gracefully Handling Errors
Sachin Chaurasiya - May 13

Code Smell 251 - Collections Empty
Maxi Contieri - May 11

Carregando dados com Apache HOP & Postgres
DeadPunnk - May 9

Creating Your Own Scriptable Render Pipeline on Unity for Mobile Devices: Introduction to SRP
Devs Daddy - May 10

We're a place where coders share, stay up-to-date and grow their careers.
How to build a simple speech recognition app

“In this 10-year time frame, I believe that we’ll not only be using the keyboard and the mouse to interact but during that time we will have perfected speech recognition and speech output well enough that those will become a standard part of the interface.” — Bill Gates, 1 October 1997
Technology has come a long way, and with each new advancement, the human race becomes more attached to it and longs for these new cool features across all devices.
With the advent of Siri, Alexa, and Google Assistant, users of technology have yearned for speech recognition in their everyday use of the internet. In this post, I’ll be covering how to integrate native speech recognition and speech synthesis in the browser using the JavaScript WebSpeech API .
According to the Mozilla web docs:
The Web Speech API enables you to incorporate voice data into web apps. The Web Speech API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition.)
Requirements we will need to build our application
For this simple speech recognition app, we’ll be working with just three files which will all reside in the same directory:
- index.html containing the HTML for the app.
- style.css containing the CSS styles.
- index.js containing the JavaScript code.
Also, we need to have a few things in place. They are as follows:
- Basic knowledge of JavaScript.
- A web server for running the app. The Web Server for Chrome will be sufficient for this purpose.
Setting up our speech recognition app
Let’s get started by setting up the HTML and CSS for the app. Below is the HTML markup:
Here is its accompanying CSS style:
Copying the code above should result in something similar to this:

Powering up our speech recognition app with the WebSpeech API
As of the time of writing, the WebSpeech API is only available in Firefox and Chrome. Its speech synthesis interface lives on the browser’s window object as speechSynthesis while its speech recognition interface lives on the browser’s window object as SpeechRecognition in Firefox and as webkitSpeechRecognition in Chrome.
We are going to set the recognition interface to SpeechRecognition regardless of the browser we’re on:
Next we’ll instantiate the speech recognition interface:
In the code above, apart from instantiating speech recognition, we also selected the icon , text-box, and sound elements on the page. We also created a paragraph element which will hold the words we say, and we appended it to the text-box .
Whenever the microphone icon on the page is clicked, we want to play our sound and start the speech recognition service. To achieve this, we add a click event listener to the icon:
In the event listener, after playing the sound, we went ahead and created and called a dictate function. The dictate function starts the speech recognition service by calling the start method on the speech recognition instance.
To return a result for whatever a user says, we need to add a result event to our speech recognition instance. The dictate function will then look like this:
The resulting event returns a SpeechRecognitionEvent which contains a results object. This in turn contains the transcript property holding the recognized speech in text. We save the recognized text in a variable called speechToText and put it in the paragraph element on the page.
If we run the app at this point, click the icon and say something, it should pop up on the page.

Wrapping it up with text to speech
To add text to speech to our app, we’ll make use of the speechSynthesis interface of the WebSpeech API. We’ll start by instantiating it:
Next, we will create a function speak which we will call whenever we want the app to say something:
The speak function takes in a function called the action as a parameter. The function returns a string which is passed to SpeechSynthesisUtterance . SpeechSynthesisUtterance is the WebSpeech API interface that holds the content the speech recognition service should read. The speechSynthesis speak method is then called on its instance and passed the content to read.
To test this out, we need to know when the user is done speaking and says a keyword. Luckily there is a method to check that:
In the code above, we called the isFinal method on our event result which returns true or false depending on if the user is done speaking.
If the user is done speaking, we check if the transcript of what was said contains keywords such as what is the time , and so on. If it does, we call our speak function and pass it one of the three functions getTime , getDate or getTheWeather which all return a string for the browser to read.
Our index.js file should now look like this:
Let’s click the icon and try one of the following phrases:
- What is the time?
- What is today’s date?
- What is the weather in Lagos?
We should get a reply from the app.
In this article, we’ve been able to build a simple speech recognition app. There are a few more cool things we could do, like select a different voice to read to the users, but I’ll leave that for you to do.
If you have questions or feedback, please leave them as a comment below. I can’t wait to see what you build with this. You can hit me up on Twitter @developia_ .
God Lover! Lifelong Learner!! Software Engineer!!!
If you read this far, thank the author to show them you care. Say Thanks
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Simple Voice Commands Using Javascript Speech Recognition
Welcome to a quick tutorial on how to add voice commands to a website using Javascript speech recognition. Ever wonder if it is possible to drive a website using voice commands? Yes, we can use speech recognition and run commands with it… It is also surprisingly pretty easy to do. Read on for an example!
TLDR – QUICK SLIDES
[web_stories_embed url=”https://code-boxx.com/web-stories/voice-command-javascript/” title=”Javascript Voice Command” poster=”https://code-boxx.com/wp-content/uploads/2021/11/STORY-JS-20230518.webp” width=”360″ height=”600″ align=”center”]
Fullscreen Mode – Click Here
TABLE OF CONTENTS
Javascript voice command.
All right, let us now get into the example of a simple voice command script in Javascript.
Try “power on”, “power off”, or “say hello”.
PART 1) THE HTML
For this demo, we only have a simple <div id="vwrap"> and <input type="button"> .
PART 2) JAVASCRIPT VOICE COMMANDS
Right, this is probably intimidating to beginners. So I am not going to explain line-by-line, here are the essential parts:
- We run voice.init() on window load, section A2 is pretty much the “core engine”.
- First, we need to ask for permission to access the microphone – navigator.mediaDevices.getUserMedia({ audio: true })
- Only then, can we properly set up the speech recognition – voice.recog = new SpeechRecognition() . Change voice.recog.lang if you want to use other languages.
- let said = evt.results[0][0].transcript.toLowerCase() is a string of what the user spoke. For example, “power on”.
- Next, we create an object of functions. I.E. var cmd = { "power on" : () => {...} } .
- Lastly, we only need to map the user’s spoken command to the object – cmd[said]() .
PART 3) JAVASCRIPT COMMAND FUNCTIONS
Well, this is just a list of dummy commands for this example. Feel free to change and do actually useful stuff in your own project… For example, "save photo" : () => { UPLOAD IMAGE TO SERVER } .
DOWNLOAD & NOTES
Here is the download link to the example code, so you don’t have to copy-paste everything.
SORRY FOR THE ADS...
But someone has to pay the bills, and sponsors are paying for it. I insist on not turning Code Boxx into a "paid scripts" business, and I don't "block people with Adblock". Every little bit of support helps.
Buy Me A Coffee Code Boxx eBooks
EXAMPLE CODE DOWNLOAD
Click here for the source code on GitHub gist , just click on “download zip” or do a git clone. I have released it under the MIT license, so feel free to build on top of it or use it in your own project.
EXTRA BITS & LINKS
That’s all for the tutorial, and here is a small section on some extras and links that may be useful to you.
COMPATIBILITY CHECKS
- Speech Recognition – CanIUse
- Arrow Functions – CanIUse
Speech recognition is only available on Chrome, Edge, and Safari at the time of writing. You may want to do your own feature checks, I recommend using Modernizr .
LINKS & REFERENCES
- Using the Web Speech API – MDN
- Permission Query – MDN
- Example on CodePen – JS Voice Commands
INFOGRAPHIC CHEAT SHEET

Thank you for reading, and we have come to the end. I hope that it has helped you to better understand, and if you want to share anything with this guide, please feel free to comment below. Good luck and happy coding!
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *

Recognizing Speech with vanilla JavaScript

Aug 12, 2022 · 5 min read

Before we start our project, I’d like to discuss the concept of speech recognition. What is speech recognition? Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition, or speech-to-text, is a capability that enables a program to process human speech into a written format . In today’s world, big companies, especially big tech companies, use AI’s such as Alexa, Cortana, Google Assistant, and Siri, which all have the Speech recognition feature, a key component of their performance.
In this tutorial, we will learn how to use JavaScript to add a speech recognition feature to any web app. We will be using the speech recognition Webkit API to achieve this; the chat app should look and function like this:

The chat app will be able to access your microphone when the start listening button is clicked and will have a response to specific questions asked. The chat app is only available on a few browsers on Desktop and Android.
Web Speech API is used to incorporate voice data into web apps. It provides two distinct areas of functionality — speech recognition and speech synthesis (also known as text to speech, or TTS) — which open up interesting new possibilities for accessibility and control mechanisms. It receives speech through a device’s microphone, which is then checked by a speech recognition service against a list of grammar. When a word or phrase is successfully recognized, it returns a result or results as a text string, and other actions can be launched as a result or results.
So to get started, we need to create a chat section structure with HTML and style it with CSS. Our primary focus is on the functionality of the chat section so that you can get the HTML structure and CSS styling in my GitHub repository or for practice purposes, you can create and style a chat section of your choice and follow along for the functionalities in this article.
Setting Up our JavaScript file
Head straight into the JS section, the first thing to do is grab a text container where all messages and replies will be in and the buttons that start and stop the speech recognition process, and then we set up the window speech recognition WebKit API . After setting that up, we will create a variable that will store the speech recognition constructor and set the interim results to true.
The interim results seen on line 10 allow us to get the results when we speak, so it is something like real-time. If we set it to false, it will simply wait till we are done speaking and then return the result, but for this tutorial, we want to have our results while we speak.
After setting up the window WebKit above, we can create a new element. We will create a p tag, then create an event listener below for our recognition and pass in (e) as a parameter and log (e), so we can test what we have done so far.
We added recognition.start on line 9 to allow the web browser to start listening. When you head to the web browser and hit the refresh button, you should get a pop-up request to allow your microphone access. Click on the allow button and open your browser’s terminal while you speak. You will observe that while you speak, you’ll get some events in your terminal, and if you open any of them, you’ll see some options, including results, which we need. If you also look closely, you’d observe that most events have a length of 1 while some have a length of 2. If you open the results property with a length of 2, you’d see it contains two separate words like in the picture below.

Looking at the image above, it has a length of 2 because it contains two words that I highlighted. The words are meant to be in a single sentence, and to correct that we will need to map through each of our results and put them together in one sentence. For that to happen, we will make a variable; let’s call it texts. Then we need to make the results property an array. We’ll use Array. from and then insert (e.results), and that will give us an array.
Now we need to map through the results array and target the first speech recognition result, which has an index of zero. Then we target the transcript property that holds the words, map them through, and then join both transcripts to put both words together in a sentence. If you log text and head to the terminal in your browser and start speaking, you will see our words are forming sentences, although it is not 100% accurate yet.
Open Source Session Replay
OpenReplay is an open-source, session replay suite that lets you see what users do on your web app, helping you troubleshoot issues faster. OpenReplay is self-hosted for full control over your data.

Start enjoying your debugging experience - start using OpenReplay for free .
Adding our speech to our chat section
Now that we have successfully shown the sentences in our terminal, we need to add them to our chat section. To show them in the chat section, we need to add the text variable from above to the p tag we created earlier. Then we append it to a container div element that holds the p tag in our HTML. If you check your web browser, you’d see our results are now showing in the chat section, but there is a problem. If you start speaking again, it will keep adding the sentences to just one paragraph. This is because we need to start over a new session in a new paragraph when the first session ends.
To resolve this, we will need to create an event listener with an “end” event to stop the last session and a function containing a recognition start, to begin a new session. If you speak in your browser, you will still notice that new sentences or words are overriding the old sentences or words contained in the paragraph tag, and we don’t want that too. To handle this, we also need to create a new paragraph for a new session, but before we do that, we will need to change the isFinal value, as seen below.

The isFinal property is located in the speech recognition results as seen above. It is set to false by default, meaning we are in our current session, and whenever it is true, we have ended that session. So going back to our code, we will need to check the isFinal results with a conditional statement, as seen below. When we set the isFinal property to true, a new paragraph tag will be added below with the content of the new session, and that is all.
Adding some Custom replies to our Chat-app
We have successfully set up our chat app to listen with our browser’s microphone and display what was heard in written format. I will also show you how to set the buttons to start and stop the listening process below. We can also do something exciting and create custom replies based on the texts displayed. To do this, we will have to go into our last conditional statement before the p tag and add another conditional statement. This will check if the text variable we created earlier contains a particular word like “hello”. If true, we can create a p tag, give it a class name for styling and then add a custom reply to the p tag.
We can also perform specific tasks like opening another page and a lot more. I have added a couple of replies to my code below.
The window method , as seen above, is a JS method that tells the browser to open a certain path or link. Ensure you maintain the letter casing while setting your task if needed. Once all is done, if you head to your browser and speak, for instance, say “open a YouTube page”, you should be redirected to a random page on YouTube in your browser. If this doesn’t work, check your browser settings and allow page pop-ups, which should then work. So when the start button is clicked, the chat app starts the listening process, and when the stop button is clicked, it aborts the current session.
In this tutorial, we have successfully created a chat app that listens and translates what’s heard into text format. This can be used to perform different tasks like responding with custom replies and assisting in page redirections by implementing speech recognition using JavaScript. To improve on this, feel free to challenge yourself using the speech recognition API to perform complex tasks and projects like creating a translator or a mini Ai with custom replies.
GitHub repo: https://github.com/christofa/Speech-recognition-chat-app.git
A TIP FROM THE EDITOR: For solutions specific to React, don’t miss our Make your app speak with React-Speech-kit and Voice enabled forms in React with Speechly articles.
More articles from OpenReplay Blog

Jan 10, 2023, 3 min read
A Practical Guide to GitHub Actions
{post.frontmatter.excerpt}

Jul 17, 2020, 4 min read
A Practical Guide To Optimizing Performance On The Web
JavaScript Speech Synthesis - Web API Guide
Unreal Speech
Mastering javascript speech synthesis - a comprehensive api tutorial.
Mastering Javascript speech synthesis is a task that requires a deep understanding of the Javascript TTS API. This API, a powerful tool in the hands of developers, facilitates the conversion of text into audible speech, bridging the gap between the Javascript environment and the device's native speech synthesis capabilities. The Javascript TTS API, with its robust features, allows developers to manipulate various aspects of speech such as pitch, rate, and volume, providing a comprehensive solution for text-to-speech needs.
Delving deeper into the Javascript TTS API features , one finds a plethora of options that allow for nuanced control over speech output. For instance, the API supports the manipulation of voice characteristics, enabling developers to select from a range of voices available on the user's device. Additionally, the API provides the ability to adjust the speech rate, pitch, and volume, offering a high degree of customization to meet specific user needs and preferences.
Furthermore, the Javascript TTS API features extend beyond basic speech synthesis capabilities. The API also supports the queuing of multiple utterances, allowing developers to schedule a sequence of text-to-speech operations. This feature, coupled with the API's ability to handle interruptions and resume speech synthesis, makes the Javascript TTS API a versatile tool for creating engaging and interactive user experiences.

Exploring TTS Technology: An Essential Glossary of Terms
API (Application Programming Interface): An interface that allows software applications to communicate with each other. In the context of JavaScript Speech Synthesis, it refers to the set of commands, functions, and protocols provided by the Web Speech API for developers to use.
Speech Synthesis: A technology that converts written text into spoken words—often used in applications such as text-to-speech, voice-enabled services, and other language-based user interfaces.
Utterance: In the realm of speech synthesis, an utterance refers to a piece of text that is to be synthesized into speech. It is represented by the SpeechSynthesisUtterance interface in the Web Speech API.
Web Speech API: An API developed by the W3C that allows web applications to incorporate speech recognition and speech synthesis functionalities. The JavaScript Speech Synthesis is a part of this API.
W3C (World Wide Web Consortium): An international community that develops open standards to ensure the long-term growth of the Web. They are responsible for the development and maintenance of the Web Speech API.
Voices: In the context of JavaScript Speech Synthesis, voices refer to the different types of synthesized voices that can be used to read out the text. These can vary in accent, pitch, speed, and language.
Pitch: In speech synthesis, pitch refers to the perceived frequency of the sound produced. It can be adjusted to make the synthesized speech sound higher or lower.
Rate: The speed at which the synthesized speech is read out. It can be adjusted to make the speech faster or slower.
Volume: The loudness of the synthesized speech. It can be adjusted using the Web Speech API.
onstart and onend Events: These are event handlers in the Web Speech API that are triggered at the start and end of the speech synthesis respectively. They can be used to perform certain actions when the speech starts or ends.
Understanding Basics: A Closer Look at Javascript Speech Synthesis
Delving into the core of Javascript Speech Synthesis—a feature that enables TTS conversion in web applications—unveils a myriad of advantages. Its primary function, the SpeechSynthesisUtterance interface, allows developers to create speech requests, offering flexibility in voice selection, pitch, and volume. This versatility not only enhances user experience but also broadens accessibility, catering to users with visual impairments or literacy challenges. Furthermore, its compatibility with most modern browsers ensures seamless integration, making it a valuable tool in the realm of web development.
Unveiling Advantages of Implementing iOS Text to Speech API
Unveiling the iOS Text to Speech API reveals a plethora of technical features, each with its own distinct advantages and benefits. At its core, this API allows for the conversion of text into speech—a feature that is not only advantageous for developers seeking to enhance the auditory experience of their applications, but also beneficial for users with visual impairments or literacy challenges. Its compatibility with the iOS platform ensures seamless integration, while its flexibility in voice selection, pitch, and volume control offers a customizable user experience. Furthermore, its ability to function offline provides an added layer of convenience, making it an invaluable tool in the realm of mobile application development.
How finance and corporate management benefit from Javascript speech synthesis via iOS Text to Speech API
Recognizing the potential of Javascript speech synthesis via iOS Text to Speech API, finance and corporate management sectors are experiencing a transformative shift. This technology, with its robust features—offline functionality, voice selection, pitch, and volume control—provides a customizable auditory experience, enhancing user engagement. For visually impaired or literacy-challenged users, it's a game-changer. Moreover, its seamless integration with iOS platforms offers a streamlined solution for developers, making it a powerful tool in mobile application development. Thus, it's not just a technological advancement—it's a strategic asset for businesses.
Enhancing education and training with Javascript speech synthesis through iOS Text to Speech API
As awareness of Javascript speech synthesis through iOS Text to Speech API grows, its application in the realm of education and training is becoming increasingly apparent. This technology, with its ability to offer offline functionality, voice selection, pitch, and volume control, is revolutionizing the learning experience. It addresses the problem of accessibility for those with visual impairments or literacy challenges, offering a more inclusive learning environment. Furthermore, its seamless integration with iOS platforms positions it as a valuable tool for developers, enhancing the efficiency of educational app development. Thus, Javascript speech synthesis is not merely a technological innovation—it's a catalyst for educational transformation.
Law and paralegal sectors: Gaining edge with iOS Text to Speech API and Javascript speech synthesis
Recognizing the potential of iOS Text to Speech API and Javascript speech synthesis, law and paralegal sectors are leveraging these technologies to gain a competitive edge. These tools address the challenge of efficient document review and case preparation—providing offline functionality, voice selection, pitch, and volume control. Their integration with iOS platforms positions them as invaluable assets for legal professionals, streamlining workflow and enhancing productivity. Thus, these technologies are not just advancements—they are transforming the legal landscape.
Boosting business and ecommerce operations using iOS Text to Speech API and Javascript speech synthesis
Amplifying business and ecommerce operations through the strategic application of iOS Text to Speech API and Javascript speech synthesis is a game-changer. These technologies—offering offline capabilities, voice customization, and sound modulation—serve as powerful tools for diverse industries beyond the legal sector. Their seamless integration with iOS platforms optimizes workflow, boosts productivity, and provides a competitive edge. Hence, these advancements are not merely technological—they are catalysts for business transformation.
Driving social development: iOS Text to Speech API and Javascript speech synthesis integration
Driving social development, the integration of iOS Text to Speech API and Javascript speech synthesis—characterized by its offline functionality, voice personalization, and sound modulation—proffers a distinct advantage. Beyond its application in the legal sector, it permeates various industries, enhancing workflow efficiency and productivity. This amalgamation with iOS platforms not only provides a competitive edge but also acts as a catalyst for business metamorphosis, underscoring its transformative potential.
Industrial manufacturing and supply chains: Leveraging iOS Text to Speech API and Javascript speech synthesis
Industrial manufacturing and supply chains—once considered static entities—are now experiencing a paradigm shift, thanks to the integration of iOS Text to Speech API and Javascript speech synthesis. These technologies, renowned for their offline capabilities, voice customization, and sound modulation, are revolutionizing the sector. They are not just enhancing operational efficiency but also fostering a competitive advantage. By leveraging these technologies, businesses can catalyze their transformation, highlighting the transformative potential of this technological amalgamation.
Medical research and healthcare transformation via iOS Text to Speech API and Javascript speech synthesis
Medical research and healthcare sectors are witnessing a transformative shift, driven by the integration of iOS Text to Speech API and Javascript speech synthesis. These advanced technologies—known for their offline functionality, voice personalization, and sound modulation—are reshaping the landscape. They are not merely improving operational efficiency, but also creating a competitive edge. By harnessing these technologies, organizations can accelerate their transformation, underscoring the transformative potential of this technological fusion.
Scientific research and engineering: Advancing with iOS Text to Speech API and Javascript speech synthesis
Scientific research and engineering sectors are experiencing a paradigm shift, propelled by the amalgamation of iOS Text to Speech API and Javascript speech synthesis. These cutting-edge technologies—renowned for their offline capabilities, voice customization, and sound modulation—offer a new dimension to the field. They are not just enhancing operational effectiveness, but also providing a strategic advantage. By leveraging these technologies, entities can expedite their evolution, highlighting the transformative capacity of this technological convergence.
Government efficiency enhanced by iOS Text to Speech API and Javascript speech synthesis
Governmental efficiency is witnessing a significant uplift, driven by the integration of iOS Text to Speech API and Javascript speech synthesis—a technological fusion that is revolutionizing the public sector. These advanced tools, celebrated for their offline functionality, voice personalization, and acoustic modulation, are not merely improving operational efficiency—they are also delivering a competitive edge. By harnessing these technologies, organizations can accelerate their transformation, underscoring the disruptive potential of this tech synergy.
Most Salient Features of Javascript Speech Synthesis Technology
Despite the transformative potential of iOS Text to Speech API, a pressing issue persists—its limited compatibility with diverse platforms. This problem agitates many developers, hindering their ability to create universally accessible applications. However, the advent of Javascript Speech Synthesis technology offers a compelling solution. This technology, renowned for its platform-agnostic nature, offline functionality, and voice customization capabilities, empowers developers to create applications with enhanced accessibility and user experience. Furthermore, its acoustic modulation feature allows for nuanced voice outputs—providing a competitive edge in the rapidly evolving tech landscape.
Cost-effectiveness of implementing Javascript speech synthesis in modern tech platforms
Recognizing the escalating costs of platform-specific speech synthesis technologies, businesses are confronted with a significant challenge. Javascript Speech Synthesis, however, emerges as a cost-effective alternative—its platform-independent nature, offline capabilities, and voice customization options offer a robust solution. Notably, its unique acoustic modulation feature enables nuanced voice outputs, providing a competitive advantage in the dynamic tech industry. Thus, Javascript Speech Synthesis not only mitigates the compatibility issue but also enhances accessibility and user experience, all while ensuring cost-effectiveness.
Legal regulations compliance in Javascript speech synthesis technology
Compliance with legal regulations presents a formidable obstacle in the deployment of Javascript speech synthesis technology. This hurdle is further exacerbated by the intricate nature of these laws, which vary across different jurisdictions and are subject to frequent amendments. However, a solution lies in the implementation of a robust compliance management system—this system not only ensures adherence to current regulations but also anticipates future legislative changes, thereby safeguarding the technology from potential legal pitfalls. Consequently, businesses can confidently utilize Javascript speech synthesis technology, secure in the knowledge that they are operating within the confines of the law.
Deployment simplicity: A key advantage of Javascript speech synthesis technology
Deployment of Javascript speech synthesis technology often encounters a significant challenge—complex legal compliance. This issue is intensified by the labyrinthine nature of regulations, which differ across jurisdictions and are prone to frequent modifications. Yet, the simplicity of Javascript's deployment offers a solution. By integrating a robust compliance management system, businesses can navigate these legal intricacies with ease. This system not only ensures conformity with existing laws but also forecasts potential legislative shifts, thereby shielding the technology from potential legal complications. As a result, organizations can leverage Javascript speech synthesis technology with confidence, knowing they are operating within legal parameters.
Scalability in Javascript speech synthesis: A pivotal feature for tech growth
Scalability in Javascript speech synthesis presents a formidable obstacle—handling high-volume, real-time data processing. This problem is exacerbated by the unpredictable, exponential growth of user interactions, which can strain system resources and degrade performance. However, Javascript's inherent asynchronous nature provides a viable solution. By leveraging Javascript's event-driven, non-blocking I/O model, developers can efficiently manage large-scale, concurrent operations without compromising system responsiveness. This approach not only optimizes resource utilization but also enhances system resilience, enabling businesses to scale their speech synthesis applications seamlessly in response to fluctuating user demands. Consequently, Javascript speech synthesis technology becomes a pivotal tool for tech growth, empowering organizations to deliver superior user experiences, irrespective of scale.
User-friendliness: A defining characteristic of Javascript speech synthesis technology
One encounters a significant challenge when attempting to enhance user-friendliness in Javascript speech synthesis technology—complexity in the user interface. This issue is further intensified by the intricate, multifaceted nature of speech synthesis processes, which can overwhelm users and impede their interaction with the system. Nevertheless, Javascript's modular design offers a compelling resolution. By capitalizing on Javascript's component-based architecture, developers can construct intuitive, user-centric interfaces that simplify complex operations. This strategy not only improves user engagement but also bolsters system accessibility, enabling businesses to deliver high-quality, user-friendly speech synthesis applications. As a result, Javascript speech synthesis technology emerges as a critical asset for user experience enhancement, equipping organizations to meet diverse user needs effectively and efficiently.
Sustainability in Javascript speech synthesis: A cornerstone of modern tech evolution
Addressing sustainability in Javascript speech synthesis—this is a pivotal aspect of contemporary technological progression. It's not merely about enhancing user interfaces or simplifying complex operations. Rather, it's about creating a sustainable, scalable, and efficient system that can adapt to evolving user needs and technological advancements. Leveraging Javascript's modular design, developers can build robust, adaptable speech synthesis applications. This approach not only ensures system longevity but also promotes operational efficiency, thereby contributing to the overall sustainability of the technology. Consequently, Javascript speech synthesis emerges as a vital tool for fostering technological sustainability, empowering organizations to navigate the dynamic tech landscape with agility and resilience.
Wider market reach through Javascript speech synthesis technology's unique features
Expanding market reach becomes feasible with Javascript speech synthesis technology's unique features—its modular design and adaptability. These features, intrinsic to Javascript, enable the creation of robust, scalable speech synthesis applications. The advantage lies in the technology's ability to adapt to changing user needs and technological advancements, ensuring system longevity and operational efficiency. Consequently, businesses benefit from a sustainable, efficient system that can navigate the dynamic tech landscape, fostering resilience and agility, and ultimately broadening their market reach.
Practical Use Cases: Harnessing the Power of iOS Text to Speech API
As businesses become increasingly aware of the potential of iOS Text to Speech API, they encounter a common problem—how to effectively leverage this technology for practical applications. This API, with its advanced speech synthesis capabilities, offers a solution. It allows developers to create applications that can convert text into human-like speech, enhancing user experience and accessibility. For instance, ecommerce platforms can implement this API to read product descriptions aloud, improving customer engagement and potentially boosting sales. Furthermore, enterprise-level organizations can use it to develop assistive technologies for visually impaired employees, promoting inclusivity in the workplace. Thus, the iOS Text to Speech API positions businesses at the forefront of technological innovation, providing them with a competitive edge in today's digital landscape.
Industrial manufacturers and distributors: Streamlining processes with Javascript speech synthesis via iOS API
Industrial manufacturers and distributors are becoming increasingly aware of the transformative potential of Javascript speech synthesis via iOS API. However, a prevalent issue arises—how to harness this advanced technology to streamline processes effectively. This API, with its sophisticated speech synthesis capabilities, presents a viable solution. It empowers software engineers to develop applications that transmute text into lifelike speech, thereby augmenting user experience and accessibility. For instance, businesses can integrate this API to vocalize product specifications, enhancing customer engagement and potentially augmenting sales. Moreover, large-scale organizations can utilize it to devise assistive technologies for employees with visual impairments, fostering an inclusive work environment. Consequently, Javascript speech synthesis via iOS API positions industrial manufacturers and distributors at the vanguard of technological innovation, equipping them with a competitive advantage in the contemporary digital era.
Empowering businesses and ecommerce operators with iOS Text to Speech API and Javascript speech synthesis
As businesses and ecommerce platforms gain awareness of the transformative potential of iOS Text to Speech API and Javascript speech synthesis, they encounter a common challenge—effectively leveraging this advanced technology to optimize operations. This API, with its intricate speech synthesis capabilities, offers a robust solution. It enables AI developers and software engineers to create applications that convert text into realistic speech, thereby enhancing user interaction and accessibility. For example, ecommerce operators can incorporate this API to vocalize product details, boosting customer engagement and potentially increasing sales. Furthermore, enterprise-level organizations can employ it to develop assistive technologies for employees with visual impairments, promoting an inclusive workplace. Thus, iOS Text to Speech API and Javascript speech synthesis position businesses and ecommerce platforms at the forefront of technological innovation, providing them with a competitive edge in the modern digital landscape.
Public offices and government contractors: Streamlining services with Javascript speech synthesis and iOS Text to Speech API
Public offices and government contractors are recognizing the transformative potential of Javascript speech synthesis and iOS Text to Speech API—powerful tools that streamline services and enhance user interaction. By integrating these advanced technologies, AI developers and software engineers can create applications that convert text into realistic speech, thereby improving accessibility and efficiency. For instance, government contractors can utilize this API to vocalize contract details, fostering transparency and reducing misunderstandings. Moreover, public offices can leverage it to develop assistive technologies for employees with visual impairments, fostering an inclusive work environment. Thus, Javascript speech synthesis and iOS Text to Speech API are not just technological advancements—they are catalysts for operational optimization and inclusivity in public offices and government contracting.
Empowering educational institutions with Javascript speech synthesis via iOS Text to Speech API
Attention is drawn to the transformative power of Javascript speech synthesis when combined with iOS Text to Speech API—particularly within the realm of education. This potent amalgamation sparks interest among academic researchers and AI developers, as it offers a robust solution for creating applications that transmute text into lifelike speech. The desire for such technology is palpable in educational institutions, where it can be harnessed to enhance learning experiences, improve accessibility, and foster inclusivity. For instance, it can be utilized to vocalize complex academic texts, thereby reducing cognitive load and enhancing comprehension. Furthermore, it can be leveraged to develop assistive technologies for students with visual impairments, thereby promoting an inclusive learning environment. Hence, the integration of Javascript speech synthesis and iOS Text to Speech API is not merely a technological advancement—it is a catalyst for educational enhancement and inclusivity. The call to action for educational institutions is clear: embrace this technology to optimize learning experiences and foster an inclusive educational environment.
Optimizing banking operations: iOS Text to Speech API and Javascript speech synthesis in finance
Optimizing banking operations hinges on the strategic integration of iOS Text to Speech API and Javascript speech synthesis—a powerful combination that offers distinct features, advantages, and benefits. This fusion enables the conversion of text-based banking instructions into audible commands, thereby enhancing the user experience and streamlining operations. It provides an advantage by reducing the cognitive load on users, allowing them to process information more efficiently. The benefit is evident in the improved operational efficiency and customer satisfaction, as banking transactions become more intuitive and less time-consuming. This technology, therefore, serves as a catalyst for operational optimization in the finance sector.
Revolutionizing patient care in hospitals using Javascript speech synthesis and iOS Text to Speech API
Revolutionizing patient care in hospitals is achievable through the strategic deployment of Javascript speech synthesis and iOS Text to Speech API—an innovative blend that presents unique features, advantages, and benefits. This amalgamation facilitates the transformation of text-based medical instructions into audible directives, thereby augmenting patient care and streamlining hospital operations. It offers an advantage by lessening the cognitive burden on healthcare professionals, enabling them to assimilate information more effectively. The benefit manifests in the enhanced operational efficiency and patient satisfaction, as medical procedures become more intuitive and less time-consuming. Hence, this technology acts as a catalyst for operational revolution in the healthcare sector.
Social welfare organizations: Aiding communities with iOS Text to Speech API and Javascript speech synthesis
For social welfare organizations, the challenge lies in effectively communicating with diverse communities—a hurdle that can be surmounted with the integration of iOS Text to Speech API and Javascript speech synthesis. This technological fusion transforms written information into audible content, enhancing the accessibility of crucial community services. It alleviates the cognitive load on social workers, allowing them to process information more efficiently. The result is a significant improvement in service delivery, community engagement, and overall organizational efficiency. Thus, this technology serves as a powerful tool for social welfare organizations, fostering inclusivity and driving operational excellence.
Scientific research groups utilizing Javascript speech synthesis via iOS Text to Speech API
Scientific research groups are increasingly leveraging the power of Javascript speech synthesis in conjunction with iOS Text to Speech API—an innovative approach that enhances the accessibility and comprehension of complex data. This integration enables the transformation of intricate written research findings into audible content, thereby facilitating a more efficient data interpretation process. It also significantly reduces the cognitive burden on researchers, allowing them to focus on critical analysis and hypothesis testing. Consequently, this technological amalgamation is revolutionizing the way scientific research is conducted and communicated, fostering a more inclusive and efficient research environment.
Law firms and paralegal service providers: Streamlining tasks with Javascript speech synthesis
Attention is drawn to the transformative potential of Javascript speech synthesis for law firms and paralegal service providers—a technological leap that streamlines task execution. Interest is piqued by the integration of this technology with existing systems, enabling the conversion of complex legal documents into audible content. This fosters a desire for efficiency, as it alleviates the cognitive load on legal professionals, allowing them to concentrate on critical analysis and case strategy. Action is then prompted, as the adoption of this technology not only revolutionizes the way legal information is processed and communicated, but also cultivates a more inclusive and efficient work environment.
Recent R&D Innovations in Text to Speech Technology
Unveiling cutting-edge research in TTS synthesis—business, education, and social applications reap immense benefits. Knowledge of recent engineering case studies sparks interest, fuels desire for innovation, and prompts action towards adopting this transformative technology.
- Speech Synthesis: A Review
- Authors: Archana Balyan, S. S. Agrawal, Amita Dev
- Download URL: https://www.ijert.org/research/speech-synthesis-a-review-IJERTV2IS60087.pdf
- Subjects: Text-to-Speech synthesis, Machine Learning, Deep Learning
- Summary: This research paper reviews recent research advances in R&D of speech synthesis with focus on one of the key approaches i.e. statistical parametric approach to speech synthesis based on HMM, so as to provide a technological perspective. In this approach, spectrum, excitation, and duration of speech are simultaneously modeled by context-dependent HMMs, and speech waveforms are generated from the HMMs themselves. This paper aims to give an overview of what has been done in this field, summarize and compare the characteristics of various synthesis techniques used. It is expected that this study shall be a contribution in the field of speech synthesis and enable identification of research topic and applications which are at the forefront of this exciting and challenging field.
2. Novel NLP Methods for Improved Text-To-Speech Synthesis
- Author: Sevinj Yolchuyeva
- Download URL: https://www.researchgate.net/publication/353393158_Novel_NLP_Methods_for_Improved_Text-To-Speech_Synthesis
- Date of Publication: June 2021
- Subjects: Deep Learning, Machine Learning, Natural Language Processing (NLP), neural Text-To-Speech
- Summary: The goal of this dissertation is to introduce novel NLP methods, which have a relation directly or indirectly to serve in improving TTS synthesis. These methods are also useful for automatic speech recognition (ASR) and dialogue systems. In this dissertation, covered are three different tasks: Grapheme-to-phoneme Conversion (G2P), Text Normalization and Intent Detection. These tasks are important for any TTS system explicitly or implicitly. As the first approach, convolutional neural networks (CNN) is investigated for G2P conversion. Proposed is a novel CNN-based sequence-to-sequence (seq2seq) architecture. This approach includes an end-to-end CNN G2P conversion with residual connections, furthermore, a model, which utilizes a convolutional neural network (with and without residual connections) as encoder and Bi-LSTM as a decoder. As the second approach, the application of the transformer architecture is investigated for G2P conversion and compared its performance with recurrent and convolutional neural network-based state-of-the-art approaches. Beside TTS systems, G2P conversion has also been widely adopted for other systems, such as computer-assisted language learning, automatic speech recognition, speech-to-speech machine translation systems, spoken term detection, spoken document retrieval. When using a standard TTS system to read messages, many problems arise due to phenomena in messages, e.g., usage of abbreviations, emoticons, informal capitalization and punctuation. These problems also exist in other domains, such as blogs, forums, social network websites, chat rooms, message boards, and communication between players in online video game chat systems. Normalization of the text addresses this challenge. Developed is a novel CNN-based model, and this model is evaluated on an open dataset. The performance of CNNs is compared with a variety of different Long Short-Term Memory (LSTM) and bi-directional LSTM (Bi-LSTM) architectures on the same dataset. Intent detection forms an integral component of such dialogue systems. For intent detection, develop is a novel models, which utilize end-to-end CNN architecture with residual connections and the combination of Bi-LSTM and Self-attention Network (SAN). These are also evaluated on various datasets.
3. Text to Speech Synthesis: A Systematic Review, Deep Learning Based Architecture and Future Research Direction
- Authors: Fahima Khanam, Farha Akhter Munmun, Nadia Afrin Ritu, Muhammad Firoz Mridha, Aloke Kumar Saha
- Download URL: http://www.jait.us/uploadfile/2022/0831/20220831054604906.pdf
- Date of Publication: August 31, 2022
- Subject: Business and Technology
- Summary: In this research paper, a taxonomy is introduced which represents some of the Deep Learning-based architectures and models popularly used in speech synthesis. Different datasets that are used in TTS have also been discussed. Further, for evaluating the quality of the synthesized speech, some of the widely used evaluation matrices are described. Finally, the research paper concludes with the challenges and future directions of the TTS synthesis system.
Wrapping Up: Key Insights on Javascript Speech Synthesis
As the exploration of Text to Speech technology continues to evolve, a comprehensive glossary of terms becomes an invaluable resource. This glossary serves as a roadmap, guiding researchers, AI developers, and software engineers through the complex landscape of TTS technology. It provides clarity on key concepts, demystifies technical jargon, and fosters a deeper understanding of the field. Meanwhile, the basics of Javascript Speech Synthesis are being scrutinized, revealing its intricate workings. This closer look allows for a more profound comprehension of its mechanisms, enabling developers to leverage its capabilities more effectively.
On the other hand, the implementation of iOS Text to Speech API presents a myriad of advantages. It offers a robust solution for businesses and ecommerce platforms seeking to enhance their user experience. Coupled with the salient features of Javascript Speech Synthesis technology, these tools provide a powerful platform for creating interactive and engaging digital experiences. Practical use cases further illustrate the transformative potential of the iOS Text to Speech API, demonstrating its versatility across various industries and applications.
Javascript Speech Synthesis: Quick Python Example
Javascript speech synthesis: quick javascript example, unique unreal speech advantages for javascript speech synthesis.
Unreal Speech, a revolutionary TTS platform, is making waves in the industry with its cost-effective solutions. It has been proven to slash TTS costs by up to 95%, making it up to 20 times cheaper than competitors like Eleven Labs and Play.ht, and up to 4 times cheaper than tech giants such as Amazon, Microsoft, IBM, and Google. This cost efficiency is not at the expense of quality—Unreal Speech features a studio-quality voice over tool, Unreal Speech Studio, for creating professional podcasts, videos, and more. Users can also experience the technology firsthand through a simple, live web demo— Unreal Speech demo —where they can generate random text and listen to the human-like voices of Unreal Speech.
Not only does Unreal Speech offer a wide variety of professional-sounding, human-like voices, but it also allows users to customize playback speed and pitch to generate the desired intonation and style. The pricing structure of Unreal Speech is designed to scale with the needs of various businesses and organizations, from small to medium businesses, call centers, and telesales agencies, to podcast and audio book authors, content publishers, video marketers, and more. The pricing tiers range from a free tier offering 1 million characters or around 22 hours of audio, to an enterprise tier supporting up to 3 billion characters per month at discounted rates. This flexibility in pricing, coupled with the high-quality output and 99.9% uptime guarantee, has led to high praise from users, such as Derek Pankaew, CEO of Listening.io, who stated, "Unreal Speech saved us 75% on our TTS cost. It sounds better than Amazon Polly, and is much cheaper."
FAQs: Navigating the Complexities of Javascript Speech Synthesis
Understanding speech synthesis in JavaScript offers a distinct advantage—it enables the creation of dynamic, interactive user experiences. By mastering how to implement and control TTS, developers can enhance accessibility, improve user engagement, and provide real-time feedback. Utilizing speechRecognition further empowers applications, allowing for voice commands and dictation. While Google's TTS API isn't free, its robust features justify the investment, providing a comprehensive solution for diverse speech-related needs.
What is speech synthesis in JavaScript?
Speech synthesis in JavaScript, often referred to as TTS, is a complex process that involves the conversion of text input into audible speech. This is achieved through the use of an API, such as the Web Speech API, which provides a bridge between the JavaScript environment and the device's native speech synthesis capabilities. The API allows developers to control aspects of speech such as pitch, rate, and volume, and even supports SSML for more advanced speech synthesis needs. MS's Edge browser, for instance, has robust support for SSML in its TTS SDK, allowing for nuanced control over speech output.
How to make text to speech in JavaScript?
Creating TTS in JavaScript necessitates the utilization of the Web Speech API—an interface that facilitates the conversion of text into audible speech. This API, supported by most modern browsers, enables developers to manipulate speech characteristics such as pitch, rate, and volume. For more sophisticated TTS requirements, SSML is supported, providing enhanced control over speech synthesis. For instance, MS's Edge browser's TTS SDK offers comprehensive SSML support, enabling refined manipulation of speech output.
How to stop speech synthesis in JavaScript?
To halt speech synthesis in JavaScript, one employs the cancel() method from the SpeechSynthesis interface—an integral part of the Web Speech API. This method, when invoked, immediately ceases any ongoing TTS operations. It's crucial to note that the cancel() function doesn't just pause the speech, but completely stops it, discarding any remaining utterances in the queue. Therefore, developers must exercise caution when implementing this function in their TTS SDKs.
How to use speechRecognition JavaScript?
Implementing speech recognition in JavaScript involves leveraging the SpeechRecognition interface—a component of the Web Speech API. This interface enables the transcription of spoken language into written text. To initiate the process, an instance of the SpeechRecognition object is created. Event handlers, such as onresult and onspeechend, are then defined to capture and process the speech data. The start() method is invoked to begin the speech recognition, and the stop() method is used to end it. It's noteworthy that the recognition service is typically provided by the browser or the operating system, and not the JavaScript environment itself.
Is Google text to speech API free?
Google's TTS API is not offered free of charge—it operates on a pay-as-you-go pricing model. The cost is determined by the volume of characters processed by the API, with a specific rate applied per million characters. It's crucial to note that the API's usage is not limited to the English language; it supports a multitude of languages and dialects, providing businesses with a versatile tool for global communication. Furthermore, the API supports SSML, allowing developers to fine-tune the speech output for a more natural and engaging user experience.
Supplemental Resources: Enhancing Knowledge on Javascript Speech Synthesis
For developers and software engineers, SpeechSynthesis - Web APIs | MDN offers a wealth of knowledge. Dated March 3, 2023, this resource provides in-depth understanding of JavaScript Speech Synthesis, enhancing coding proficiency and application development capabilities.
Businesses and companies can leverage Experimenting With speechSynthesis , a resource dated February 14, 2017. This page offers insights into practical applications of speech synthesis, fostering innovation and competitive advantage in the digital marketplace.
Educational institutions, healthcare facilities, government offices, and social organizations can benefit from Web Speech Synthesis Demo . This basic demonstration of web speech synthesis supports learning, accessibility, and communication efforts across various sectors.
- HTML Tutorial
- HTML Exercises
- HTML Attributes
- Global Attributes
- Event Attributes
- HTML Interview Questions
- DOM Audio/Video
- HTML Examples
- Color Picker
- A to Z Guide
- HTML Formatter
How to convert speech into text using JavaScript ?
- Build a Text to Speech Converter using HTML, CSS & Javascript
- How to convert JSON results into a date using JavaScript ?
- How to make a text italic using JavaScript ?
- How to align text content into center using JavaScript ?
- How to convert text to speech in Node.js ?
- How to make a word count in textarea using JavaScript ?
- How to convert an object to string using JavaScript ?
- How to convert image into base64 string using JavaScript ?
- How to Convert JSON to string in JavaScript ?
- How to Convert a String to Uppercase in JavaScript ?
- How to change the shape of a textarea using JavaScript ?
- How to Convert Char to String in JavaScript ?
- How to Convert String of Objects to Array in JavaScript ?
- How to convert string into float in JavaScript?
- How to create Text Editor using Javascript and HTML ?
- Converting Text to Speech in Java
- How to Convert Text to Speech in Android using Kotlin?
- Convert Text to Speech in Python
- Text to speech GUI convertor using Tkinter in Python
In this article, we will learn to convert speech into text using HTML and JavaScript.
Approach: We added a content editable “div” by which we make any HTML element editable.
We use the SpeechRecognition object to convert the speech into text and then display the text on the screen.
We also added WebKit Speech Recognition to perform speech recognition in Google chrome and Apple safari.
InterimResults results should be returned true and the default value of this is false. So set interimResults= true
Use appendChild() method to append a node as the last child of a node.
Add eventListener, in this event listener, map() method is used to create a new array with the results of calling a function for every array element.
Note: This method does not change the original array.
Use join() method to return array as a string.
Final Code:
Output:
If the user tells “Hello World” after running the file, it shows the following on the screen.
Please Login to comment...
Similar reads.

- JavaScript-Misc
- Technical Scripter 2020
- Technical Scripter
- Web Technologies
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
GPT-4o text to speech and speech to text
It seems in the documentation that gpt-4o currently only takes text and image input. Are there any plans to allow it to take in audio data and return generated audio like we see in the demo videos? How would this be implemented, would they have to make websocket connections? What might the pricing look like?
I’m also interested in the roadmap for this functionality. Will the ability to stream audio to/from the model, as demonstrated in the demos, be available in the via API?
+100 me too I would love this. I want to stream audio as output please.
Audio support is coming in the future, but not available today.
Currently using Azure AI Speech API for speech/text interfacing to chat model. The Microsoft API supports streaming on-demand and continuous recognition. Will GPT-4o audio support still be file-based or will it be able to replace the Microsoft API?
I don’t think this information is public yet and it seems like OpenAI will announce this in the coming weeks.
Related Topics
IMAGES
VIDEO
COMMENTS
With the Web Speech API, we can recognize speech using JavaScript. It is super easy to recognize speech in a browser using JavaScript and then getting the text from the speech to use as user input. We have already covered How to convert Text to Speech in Javascript. But the support for this API is limited to the Chrome browser only. So if you ...
Speech recognition involves receiving speech through a device's microphone, which is then checked by a speech recognition service against a list of grammar (basically, the vocabulary you want to have recognized in a particular app.) When a word or phrase is successfully recognized, it is returned as a result (or list of results) as a text string, and further actions can be initiated as a result.
SpeechRecognition. The SpeechRecognition interface of the Web Speech API is the controller interface for the recognition service; this also handles the SpeechRecognitionEvent sent from the recognition service. Note: On some browsers, like Chrome, using Speech Recognition on a web page involves a server-based recognition engine.
The Web Speech API makes web apps able to handle voice data. There are two components to this API: Speech recognition is accessed via the SpeechRecognition interface, which provides the ability to recognize voice context from an audio input (normally via the device's default speech recognition service) and respond appropriately.
First, create a new JavaScript file and name it speechRecognition.js. Next, add the script to the HTML file using the script tag after the body tag. Adding the script tag after the body tag will make sure that the script file is loaded after all the elements have been loaded to the DOM which aids performance.
However, Speech Recognition can also include technologies such as Wake Word Detection, Voice Command Recognition, and Voice Activity Detection (VAD). This article provides a thorough guide on integrating on-device Speech Recognition into JavaScript Web apps. We will be learning about the following technologies:
The new JavaScript Web Speech API makes it easy to add speech recognition to your web pages. This API allows fine control and flexibility over the speech recognition capabilities in Chrome version 25 and later. Here's an example with the recognized text appearing almost immediately while speaking. DEMO / SOURCE.
Annyang is a JavaScript Speech Recognition library to control the Website with voice commands. It is built on top of SpeechRecognition Web APIs. In next section, we are going to give an example on how annyang works. 2. artyom.js. artyom.js is a JavaScript Speech Recognition and Speech Synthesis library. It is built on top of Web speech APIs.
This event is triggered when speech recognition is started by the user. Let's pass a callback function that will display that the speech recognition instance is listening on the webpage. In the starter code, there is a <p> element with an ID called status that says Listening.... It's been hidden by setting the display property of the ...
Once you verify, you can start to work with this API. Create a new instance of the webkitSpeechRecognition class and set the basic properties: // Create a new instance of SpeechRecognition. var recognition = new webkitSpeechRecognition(); // Define whether continuous results are returned for each recognition.
Using the Web. Speech API. In This Article. The Web Speech API provides two distinct areas of functionality — speech recognition, and speech synthesis (also know as text to speech, or tts) — which open up interesting new possibilities for accessibility, and control mechanisms. This article provides a simple introduction to both areas, along ...
Step 1 - Setting Up The App. First, we set up a very basic application using a simple HTML file called index.html and a JavaScript file called script.js . We'll also use a CSS file called style.css to add some margins and to center things, but it's entirely up to you if you want to include this styling file.
This article details a simple web application that works with the Rev.ai speech-to-text API using JavaScript. The web application will allow a user to submit an audio/video file to be transcribed by the Rev.ai API. The web app will also allow a user to stream audio to and receive real-time speech-to-text transcriptions using their microphone.
Speech Recognition in the Browser with JavaScript - key code blocks: /* Check whether the SpeechRecognition or the webkitSpeechRecognition API is available on window and reference it */ const recognitionSvc = window.SpeechRecognition || window.webkitSpeechRecognition; // Instantiate it const recognition = new recognitionSvc(); /* Set the speech ...
To achieve this, we add a click event listener to the icon: icon.addEventListener('click', () => {. sound.play(); dictate(); }); const dictate = () => {. recognition.start(); } In the event listener, after playing the sound, we went ahead and created and called a dictate function. The dictate function starts the speech recognition service by ...
Only then, can we properly set up the speech recognition - voice.recog = new SpeechRecognition(). Change voice.recog.lang if you want to use other languages. The magic happens in voice.recog.onresult . let said = evt.results[0][0].transcript.toLowerCase() is a string of what the user spoke. For example, "power on".
Setting Up our JavaScript file. Head straight into the JS section, the first thing to do is grab a text container where all messages and replies will be in and the buttons that start and stop the speech recognition process, and then we set up the window speech recognition WebKit API. After setting that up, we will create a variable that will ...
Initialisation: Make your own instance of SpeechRecognition. Add this following code to your main javascript file. window.SpeechRecognition = window.SpeechRecognition || window ...
Web Speech API: An API developed by the W3C that allows web applications to incorporate speech recognition and speech synthesis functionalities. The JavaScript Speech Synthesis is a part of this API. W3C (World Wide Web Consortium): An international community that develops open standards to ensure the long-term growth of the Web. They are ...
Add eventListener, in this event listener, map() method is used to create a new array with the results of calling a function for every array element. Note: This method does not change the original array. Use join() method to return array as a string.
This is the day-24 of #30days30submits. Today we are going to create a Speech Recognition App Using JavaScript web speech API. Hope you will like it. 🔔subs...
Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech computer, speech synthesizer, or text-to-speech (TTS) system. Speech synthesis organizes sentences by concatenating prerecorded words saved in a database. The following diagram is an overview of a typical TTS system: Image ...
Javascript / Browser Speech recognition of made up word. 0. Capture audio from JavaScript and recognize it with Google Speech API. 2. Speech Recognition in Firefox. 2. JavaScript SpeechSynthesisUtterance. Hot Network Questions How to create rows that are off-centered from others
The start() method of the Web Speech API starts the speech recognition service listening to incoming audio with intent to recognize grammars associated with the current SpeechRecognition. ... JavaScript. Learn to run scripts in the browser. Accessibility. Learn to make the web accessible to all. Plus Plus. Overview. A customized MDN experience.
I'm trying to create an HTML5-powered voice-controlled editor using the Speech Recognition API. Currently, the problem is when you start recording, it only lasts for a certain amount of time (basically until the user stops talking).
I have never used the SpeechRecognition API before but from what I read about it, perhaps creating multiple instances of the recognition object each initialised to a different language might help. Using a little bit of heuristics/brute force, you can always capture events from all instances, eliminate nomatch cases and compare their results ...
Today we announced our new flagship model that can reason across audio, vision, and text in real time—GPT-4o.We are happy to share that it is now available as a text and vision model in the Chat Completions API, Assistants API and Batch API!It includes: High intelligence GPT-4 Turbo-level performance on text, reasoning, and coding intelligence, while setting new high watermarks on ...
The Nvidia connection . SoundHound is a voice AI and speech recognition software company founded in 2005. Despite its initial public offering (IPO) -- a few months before the launch of OpenAI's ...